| 1 | Statistical Learning and Inverse Problems: A Stochastic Gradient Approach | 6.67 | | Accept
|
| 2 | Efficiency Ordering of Stochastic Gradient Descent | 6.25 | | Accept
|
| 3 | Self-Aware Personalized Federated Learning | 5.67 | | Accept
|
| 4 | Nonnegative Tensor Completion via Integer Optimization | 6.33 | | Accept
|
| 5 | TPU-KNN: K Nearest Neighbor Search at Peak FLOP/s | 5.75 | | Accept
|
| 6 | Equivariant Networks for Crystal Structures | 5.67 | | Accept
|
| 7 | Gradient Descent Is Optimal Under Lower Restricted Secant Inequality And Upper Error Bound | 6.50 | | Accept
|
| 8 | Decoupled Context Processing for Context Augmented Language Modeling | 5.67 | | Accept
|
| 9 | Planning to the Information Horizon of BAMDPs via Epistemic State Abstraction | 6.25 | | Accept
|
| 10 | Trust Region Policy Optimization with Optimal Transport Discrepancies: Duality and Algorithm for Continuous Actions | 6.00 | | Accept
|
| 11 | Modeling Transitivity and Cyclicity in Directed Graphs via Binary Code Box Embeddings | 5.33 | | Accept
|
| 12 | Simple and Optimal Greedy Online Contention Resolution Schemes | 5.50 | | Accept
|
| 13 | Evaluating Latent Space Robustness and Uncertainty of EEG-ML Models under Realistic Distribution Shifts | 5.25 | | Accept
|
| 14 | COLD Decoding: Energy-based Constrained Text Generation with Langevin Dynamics | 7.25 | | Accept
|
| 15 | From Gradient Flow on Population Loss to Learning with Stochastic Gradient Descent | 6.25 | | Accept
|
| 16 | Fast Neural Kernel Embeddings for General Activations | 6.50 | | Accept
|
| 17 | On Reinforcement Learning and Distribution Matching for Fine-Tuning Language Models with no Catastrophic Forgetting | 6.67 | | Accept
|
| 18 | Provably tuning the ElasticNet across instances | 6.67 | | Accept
|
| 19 | LAMP: Extracting Text from Gradients with Language Model Priors | 6.33 | | Accept
|
| 20 | ELIGN: Expectation Alignment as a Multi-Agent Intrinsic Reward | 5.80 | | Accept
|
| 21 | Explicable Policy Search | 5.20 | | Accept
|
| 22 | A Practical, Progressively-Expressive GNN | 5.75 | | Accept
|
| 23 | The Impact of Task Underspecification in Evaluating Deep Reinforcement Learning | 6.33 | | Accept
|
| 24 | Chaotic Dynamics are Intrinsic to Neural Network Training with SGD | 5.00 | | Accept
|
| 25 | A PAC-Bayesian Generalization Bound for Equivariant Networks | 5.50 | | Accept
|
| 26 | Autoregressive Perturbations for Data Poisoning | 6.00 | | Accept
|
| 27 | Near-Optimal No-Regret Learning Dynamics for General Convex Games | 6.50 | | Accept
|
| 28 | Learning the Structure of Large Networked Systems Obeying Conservation Laws | 6.00 | | Accept
|
| 29 | Neural Payoff Machines: Predicting Fair and Stable Payoff Allocations Among Team Members | 5.33 | | Accept
|
| 30 | Implicit Neural Representations with Levels-of-Experts | 6.75 | | Accept
|
| 31 | LieGG: Studying Learned Lie Group Generators | 6.33 | | Accept
|
| 32 | Local Bayesian optimization via maximizing probability of descent | 7.00 | | Accept
|
| 33 | A Closer Look at Learned Optimization: Stability, Robustness, and Inductive Biases | 6.25 | | Accept
|
| 34 | Empirical Gateaux Derivatives for Causal Inference | 5.67 | | Accept
|
| 35 | Adaptive Interest for Emphatic Reinforcement Learning | 6.50 | | Accept
|
| 36 | Human-Robotic Prosthesis as Collaborating Agents for Symmetrical Walking | 6.00 | | Accept
|
| 37 | Uni[MASK]: Unified Inference in Sequential Decision Problems | 8.00 | | Accept
|
| 38 | Leveraging the Hints: Adaptive Bidding in Repeated First-Price Auctions | 6.75 | | Accept
|
| 39 | ReCo: Retrieve and Co-segment for Zero-shot Transfer | 5.00 | | Accept
|
| 40 | Boosting the Performance of Generic Deep Neural Network Frameworks with Log-supermodular CRFs | 5.67 | | Accept
|
| 41 | End-to-end Stochastic Optimization with Energy-based Model | 6.25 | | Accept
|
| 42 | Context-enriched molecule representations improve few-shot drug discovery | 5.33 | | Reject
|
| 43 | EAGER: Asking and Answering Questions for Automatic Reward Shaping in Language-guided RL | 6.00 | | Accept
|
| 44 | A Causal Analysis of Harm | 5.20 | | Accept
|
| 45 | The Slingshot Mechanism: An Empirical Study of Adaptive Optimizers and the \emph{Grokking Phenomenon} | 5.33 | | Reject
|
| 46 | On-Demand Sampling: Learning Optimally from Multiple Distributions | 7.25 | | Accept
|
| 47 | Logical Activation Functions: Logit-space equivalents of Probabilistic Boolean Operators | 6.67 | | Accept
|
| 48 | Dynamic pricing and assortment under a contextual MNL demand | 5.67 | | Accept
|
| 49 | Off-Team Learning | 6.00 | | Accept
|
| 50 | A Deep Reinforcement Learning Framework for Column Generation | 5.75 | | Accept
|
| 51 | Sublinear Algorithms for Hierarchical Clustering | 6.00 | | Accept
|
| 52 | A Few Expert Queries Suffices for Sample-Efficient RL with Resets and Linear Value Approximation | 6.25 | | Accept
|
| 53 | Certifying Some Distributional Fairness with Subpopulation Decomposition | 6.33 | | Accept
|
| 54 | Accelerating Certified Robustness Training via Knowledge Transfer | 5.75 | | Accept
|
| 55 | Fairness in Federated Learning via Core-Stability | 6.67 | | Accept
|
| 56 | Learning NP-Hard Multi-Agent Assignment Planning using GNN: Inference on a Random Graph and Provable Auction-Fitted Q-learning | 4.67 | | Accept
|
| 57 | Memory safe computations with XLA compiler | 6.00 | | Accept
|
| 58 | A Communication-efficient Algorithm with Linear Convergence for Federated Minimax Learning | 5.25 | | Accept
|
| 59 | On Efficient Online Imitation Learning via Classification | 6.50 | | Accept
|
| 60 | AMP: Automatically Finding Model Parallel Strategies with Heterogeneity Awareness | 5.75 | | Accept
|
| 61 | Nonstationary Dual Averaging and Online Fair Allocation | 5.75 | | Accept
|
| 62 | New Definitions and Evaluations for Saliency Methods: Staying Intrinsic, Complete and Sound | 7.25 | | Accept
|
| 63 | A Unified Framework for Deep Symbolic Regression | 5.67 | | Accept
|
| 64 | Pitfalls of Epistemic Uncertainty Quantification through Loss Minimisation | 6.75 | | Accept
|
| 65 | Best of Both Worlds Model Selection | 6.67 | | Accept
|
| 66 | Structuring Representations Using Group Invariants | 6.25 | | Accept
|
| 67 | The Query Complexity of Cake Cutting | 6.00 | | Accept
|
| 68 | Structural Pruning via Latency-Saliency Knapsack | 5.75 | | Accept
|
| 69 | Subgame Solving in Adversarial Team Games | 5.00 | | Accept
|
| 70 | Multi-Game Decision Transformers | 7.00 | | Accept
|
| 71 | Parameter-free Regret in High Probability with Heavy Tails | 5.33 | | Accept
|
| 72 | Learning to Compare Nodes in Branch and Bound with Graph Neural Networks | 3.67 | | Accept
|
| 73 | Communication Acceleration of Local Gradient Methods via an Accelerated Primal-Dual Algorithm with an Inexact Prox | 6.25 | | Accept
|
| 74 | On the detrimental effect of invariances in the likelihood for variational inference | 5.50 | | Accept
|
| 75 | BayesPCN: A Continually Learnable Predictive Coding Associative Memory | 4.75 | | Accept
|
| 76 | Robustness to Unbounded Smoothness of Generalized SignSGD | 6.00 | | Accept
|
| 77 | Generalization for multiclass classification with overparameterized linear models | 6.25 | | Accept
|
| 78 | Finite-Sample Maximum Likelihood Estimation of Location | 6.25 | | Accept
|
| 79 | Graphein - a Python Library for Geometric Deep Learning and Network Analysis on Biomolecular Structures and Interaction Networks | 6.75 | | Accept
|
| 80 | Root Cause Analysis of Failures in Microservices through Causal Discovery | 4.00 | | Accept
|
| 81 | Robust Model Selection and Nearly-Proper Learning for GMMs | 7.00 | | Accept
|
| 82 | Explain My Surprise: Learning Efficient Long-Term Memory by predicting uncertain outcomes | 5.00 | | Accept
|
| 83 | Structural Knowledge Distillation for Object Detection | 6.50 | | Accept
|
| 84 | Exploring the Latent Space of Autoencoders with Interventional Assays | 6.67 | | Accept
|
| 85 | Performative Power | 7.00 | | Accept
|
| 86 | Debiased Machine Learning without Sample-Splitting for Stable Estimators | 5.33 | | Accept
|
| 87 | HyperTree Proof Search for Neural Theorem Proving | 5.00 | | Accept
|
| 88 | Spherical Channels for Modeling Atomic Interactions | 5.00 | | Accept
|
| 89 | Chroma-VAE: Mitigating Shortcut Learning with Generative Classifiers | 6.25 | | Accept
|
| 90 | VisCo Grids: Surface Reconstruction with Viscosity and Coarea Grids | 4.75 | | Accept
|
| 91 | Learning Probabilistic Models from Generator Latent Spaces with Hat EBM | 6.00 | | Accept
|
| 92 | On the Effectiveness of Fine-tuning Versus Meta-reinforcement Learning | 4.67 | | Accept
|
| 93 | SatMAE: Pre-training Transformers for Temporal and Multi-Spectral Satellite Imagery | 5.75 | | Accept
|
| 94 | Maximizing and Satisficing in Multi-armed Bandits with Graph Information | 7.00 | | Accept
|
| 95 | $k$-Sliced Mutual Information: A Quantitative Study of Scalability with Dimension | 4.33 | | Accept
|
| 96 | Distinguishing discrete and continuous behavioral variability using warped autoregressive HMMs | 6.67 | | Accept
|
| 97 | Analyzing Data-Centric Properties for Graph Contrastive Learning | 6.00 | | Accept
|
| 98 | Combining Implicit and Explicit Regularization for Efficient Learning in Deep Networks | 6.50 | | Accept
|
| 99 | WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents | 6.33 | | Accept
|
| 100 | On Infinite Separations Between Simple and Optimal Mechanisms | 5.75 | | Accept
|
| 101 | IMED-RL: Regret optimal learning of ergodic Markov decision processes | 6.33 | | Accept
|
| 102 | Semantic Probabilistic Layers for Neuro-Symbolic Learning | 6.75 | | Accept
|
| 103 | Adversarial training for high-stakes reliability | 6.67 | | Accept
|
| 104 | Provable Defense against Backdoor Policies in Reinforcement Learning | 5.75 | | Accept
|
| 105 | Defining and Characterizing Reward Gaming | 6.25 | | Accept
|
| 106 | A Unified Framework for Alternating Offline Model Training and Policy Learning | 6.00 | | Accept
|
| 107 | S4ND: Modeling Images and Videos as Multidimensional Signals with State Spaces | 7.00 | | Accept
|
| 108 | JAWS: Auditing Predictive Uncertainty Under Covariate Shift | 5.50 | | Accept
|
| 109 | Disentangling Transfer in Continual Reinforcement Learning | 6.00 | | Accept
|
| 110 | List-Decodable Sparse Mean Estimation via Difference-of-Pairs Filtering | 7.67 | | Accept
|
| 111 | Finite-Time Last-Iterate Convergence for Learning in Multi-Player Games | 7.25 | | Accept
|
| 112 | Normalizing Flows for Knockoff-free Controlled Feature Selection | 6.00 | | Accept
|
| 113 | Training language models to follow instructions with human feedback | 6.50 | | Accept
|
| 114 | Efficiently Factorizing Boolean Matrices using Proximal Gradient Descent | 5.67 | | Accept
|
| 115 | Robust Anytime Learning of Markov Decision Processes | 5.33 | | Accept
|
| 116 | Neural Topological Ordering for Computation Graphs | 6.33 | | Accept
|
| 117 | Benign, Tempered, or Catastrophic: Toward a Refined Taxonomy of Overfitting | 6.00 | | Accept
|
| 118 | Evident: a Development Methodology and a Knowledge Base Topology for Data Mining, Machine Learning and General Knowledge Management | 2.67 | | Reject
|
| 119 | Characterizing Datapoints via Second-Split Forgetting | 7.25 | | Accept
|
| 120 | Regret Bounds for Multilabel Classification in Sparse Label Regimes | 6.67 | | Accept
|
| 121 | Resolving the data ambiguity for periodic crystals | 5.33 | | Accept
|
| 122 | The Power and Limitation of Pretraining-Finetuning for Linear Regression under Covariate Shift | 5.75 | | Accept
|
| 123 | Self-Supervised Contrastive Pre-Training For Time Series via Time-Frequency Consistency | 7.00 | | Accept
|
| 124 | Exact learning dynamics of deep linear networks with prior knowledge | 6.75 | | Accept
|
| 125 | Automatic Differentiation of Programs with Discrete Randomness | 6.50 | | Accept
|
| 126 | Unsupervised Reinforcement Learning with Contrastive Intrinsic Control | 5.33 | | Accept
|
| 127 | Prompt Certified Machine Unlearning with Randomized Gradient Smoothing and Quantization | 6.33 | | Accept
|
| 128 | Do Current Multi-Task Optimization Methods in Deep Learning Even Help? | 6.67 | | Accept
|
| 129 | Instance-optimal PAC Algorithms for Contextual Bandits | 6.00 | | Accept
|
| 130 | Thinned random measures for sparse graphs with overlapping communities | 5.33 | | Accept
|
| 131 | Cryptographic Hardness of Learning Halfspaces with Massart Noise | 7.25 | | Accept
|
| 132 | Hyperparameter Sensitivity in Deep Outlier Detection: Analysis and a Scalable Hyper-Ensemble Solution | 6.00 | | Accept
|
| 133 | Adversarial Auto-Augment with Label Preservation: A Representation Learning Principle Guided Approach | 5.50 | | Accept
|
| 134 | Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance | 5.33 | | Reject
|
| 135 | Hybrid Neural Autoencoders for Stimulus Encoding in Visual and Other Sensory Neuroprostheses | 7.00 | | Accept
|
| 136 | The Franz-Parisi Criterion and Computational Trade-offs in High Dimensional Statistics | 7.33 | | Accept
|
| 137 | Toward Efficient Robust Training against Union of $\ell_p$ Threat Models | 5.75 | | Accept
|
| 138 | On the Parameterization and Initialization of Diagonal State Space Models | 6.50 | | Accept
|
| 139 | Coreset for Line-Sets Clustering | 6.33 | | Accept
|
| 140 | Multitasking Models are Robust to Structural Failure: A Neural Model for Bilingual Cognitive Reserve | 6.00 | | Accept
|
| 141 | On Learning and Refutation in Noninteractive Local Differential Privacy | 7.00 | | Accept
|
| 142 | Learning to Follow Instructions in Text-Based Games | 5.50 | | Accept
|
| 143 | Non-Convex Bilevel Games with Critical Point Selection Maps | 5.25 | | Accept
|
| 144 | Differentially Private Generalized Linear Models Revisited | 6.67 | | Accept
|
| 145 | Autoformalization with Large Language Models | 6.00 | | Accept
|
| 146 | The Role of Baselines in Policy Gradient Optimization | 5.50 | | Accept
|
| 147 | Learning Mixed Multinomial Logits with Provable Guarantees | 6.25 | | Accept
|
| 148 | Phase transitions in when feedback is useful | 6.75 | | Accept
|
| 149 | OOD Link Prediction Generalization Capabilities of Message-Passing GNNs in Larger Test Graphs | 5.75 | | Accept
|
| 150 | Sample-Efficient Reinforcement Learning of Partially Observable Markov Games | 5.25 | | Accept
|
| 151 | Collaborative Learning of Discrete Distributions under Heterogeneity and Communication Constraints | 6.00 | | Accept
|
| 152 | On Uncertainty, Tempering, and Data Augmentation in Bayesian Classification | 6.75 | | Accept
|
| 153 | Marksman Backdoor: Backdoor Attacks with Arbitrary Target Class | 5.00 | | Accept
|
| 154 | MABSplit: Faster Forest Training Using Multi-Armed Bandits | 6.00 | | Accept
|
| 155 | The Missing Invariance Principle found -- the Reciprocal Twin of Invariant Risk Minimization | 6.00 | | Accept
|
| 156 | LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning | 4.25 | | Accept
|
| 157 | On Feature Learning in the Presence of Spurious Correlations | 6.67 | | Accept
|
| 158 | Learning Concept Credible Models for Mitigating Shortcuts | 6.00 | | Accept
|
| 159 | Peer Prediction for Learning Agents | 5.75 | | Accept
|
| 160 | Mean Estimation with User-level Privacy under Data Heterogeneity | 6.75 | | Accept
|
| 161 | CryptoGCN: Fast and Scalable Homomorphically Encrypted Graph Convolutional Network Inference | 6.00 | | Accept
|
| 162 | Tight Analysis of Extra-gradient and Optimistic Gradient Methods For Nonconvex Minimax Problems | 6.25 | | Accept
|
| 163 | Efficient coding, channel capacity, and the emergence of retinal mosaics | 6.75 | | Accept
|
| 164 | Amortized Inference for Causal Structure Learning | 6.33 | | Accept
|
| 165 | Robust Neural Posterior Estimation and Statistical Model Criticism | 4.75 | | Accept
|
| 166 | Expected Frequency Matrices of Elections: Computation, Geometry, and Preference Learning | 6.67 | | Accept
|
| 167 | Confident Approximate Policy Iteration for Efficient Local Planning in $q^\pi$-realizable MDPs | 6.33 | | Accept
|
| 168 | Escaping from the Barren Plateau via Gaussian Initializations in Deep Variational Quantum Circuits | 6.50 | | Accept
|
| 169 | ComENet: Towards Complete and Efficient Message Passing for 3D Molecular Graphs | 5.75 | | Accept
|
| 170 | Fairness without Demographics through Knowledge Distillation | 5.33 | | Accept
|
| 171 | Estimation of Entropy in Constant Space with Improved Sample Complexity | 6.00 | | Accept
|
| 172 | Communication Efficient Distributed Learning for Kernelized Contextual Bandits | 5.75 | | Accept
|
| 173 | Linear Label Ranking with Bounded Noise | 7.50 | | Accept
|
| 174 | Data-Driven Conditional Robust Optimization | 7.33 | | Accept
|
| 175 | Learning Tractable Probabilistic Models from Inconsistent Local Estimates | 6.00 | | Accept
|
| 176 | Learning from a Sample in Online Algorithms | 7.00 | | Accept
|
| 177 | (Optimal) Online Bipartite Matching with Degree Information | 6.00 | | Accept
|
| 178 | Can Adversarial Training Be Manipulated By Non-Robust Features? | 5.50 | | Accept
|
| 179 | A Fast Scale-Invariant Algorithm for Non-negative Least Squares with Non-negative Data | 6.50 | | Accept
|
| 180 | When Does Differentially Private Learning Not Suffer in High Dimensions? | 7.00 | | Accept
|
| 181 | Training stochastic stabilized supralinear networks by dynamics-neutral growth | 5.67 | | Accept
|
| 182 | Sparse Fourier Backpropagation in Cryo-EM Reconstruction | 6.00 | | Accept
|
| 183 | Not All Bits have Equal Value: Heterogeneous Precisions via Trainable Noise | 6.33 | | Accept
|
| 184 | Detecting Abrupt Changes in Sequential Pairwise Comparison Data | 5.67 | | Accept
|
| 185 | Uniqueness and Complexity of Inverse MDP Models | 4.00 | | Reject
|
| 186 | Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models | 5.75 | | Accept
|
| 187 | When Combinatorial Thompson Sampling meets Approximation Regret | 6.00 | | Accept
|
| 188 | Lifting Weak Supervision To Structured Prediction | 6.67 | | Accept
|
| 189 | What is a Good Metric to Study Generalization of Minimax Learners? | 5.75 | | Accept
|
| 190 | Learning Audio-Visual Dynamics Using Scene Graphs for Audio Source Separation | 6.00 | | Accept
|
| 191 | Lost in Latent Space: Examining failures of disentangled models at combinatorial generalisation | 6.50 | | Accept
|
| 192 | TVLT: Textless Vision-Language Transformer | 7.00 | | Accept
|
| 193 | Unpacking Reward Shaping: Understanding the Benefits of Reward Engineering on Sample Complexity | 7.00 | | Accept
|
| 194 | Distributed Optimization for Overparameterized Problems: Achieving Optimal Dimension Independent Communication Complexity | 6.00 | | Accept
|
| 195 | Staircase Attention for Recurrent Processing of Sequences | 6.50 | | Accept
|
| 196 | On Computing Probabilistic Explanations for Decision Trees | 6.33 | | Accept
|
| 197 | Tensor Program Optimization with Probabilistic Programs | 5.75 | | Accept
|
| 198 | A Multi-Resolution Framework for U-Nets with Applications to Hierarchical VAEs | 6.67 | | Accept
|
| 199 | Instability and Local Minima in GAN Training with Kernel Discriminators | 6.00 | | Accept
|
| 200 | Introspective Learning : A Two-Stage approach for Inference in Neural Networks | 5.00 | | Accept
|
| 201 | MMRR: Unsupervised Anomaly Detection through Multi-Level Masking and Restoration with Refinement | 3.33 | | Reject
|
| 202 | Formalizing Consistency and Coherence of Representation Learning | 5.33 | | Accept
|
| 203 | CARD: Classification and Regression Diffusion Models | 5.25 | | Accept
|
| 204 | Learning Modular Simulations for Homogeneous Systems | 6.67 | | Accept
|
| 205 | Concept Embedding Models | 6.25 | | Accept
|
| 206 | Online Learning and Pricing for Network Revenue Management with Reusable Resources | 5.50 | | Accept
|
| 207 | MAgNet: Mesh Agnostic Neural PDE Solver | 5.67 | | Accept
|
| 208 | Society of Agents: Regrets Bounds of Concurrent Thompson Sampling | 6.00 | | Accept
|
| 209 | Exploring Length Generalization in Large Language Models | 7.00 | | Accept
|
| 210 | Randomized Channel Shuffling: Minimal-Overhead Backdoor Attack Detection without Clean Datasets | 6.25 | | Accept
|
| 211 | Towards Practical Few-shot Query Sets: Transductive Minimum Description Length Inference | 5.75 | | Accept
|
| 212 | Differentially Private Graph Learning via Sensitivity-Bounded Personalized PageRank | 5.50 | | Accept
|
| 213 | Generating Training Data with Language Models: Towards Zero-Shot Language Understanding | 5.67 | | Accept
|
| 214 | Recurrent Memory Transformer | 6.00 | | Accept
|
| 215 | Statistical, Robustness, and Computational Guarantees for Sliced Wasserstein Distances | 7.00 | | Accept
|
| 216 | Collaborative Linear Bandits with Adversarial Agents: Near-Optimal Regret Bounds | 6.50 | | Accept
|
| 217 | Neural Differential Equations for Learning to Program Neural Nets Through Continuous Learning Rules | 6.33 | | Accept
|
| 218 | Operative dimensions in unconstrained connectivity of recurrent neural networks | 7.00 | | Accept
|
| 219 | Multi-Class $H$-Consistency Bounds | 6.00 | | Accept
|
| 220 | Biologically plausible solutions for spiking networks with efficient coding | 4.67 | | Accept
|
| 221 | Improving Multi-Task Generalization via Regularizing Spurious Correlation | 6.75 | | Accept
|
| 222 | Online Bipartite Matching with Advice: Tight Robustness-Consistency Tradeoffs for the Two-Stage Model | 6.75 | | Accept
|
| 223 | Safety Guarantees for Neural Network Dynamic Systems via Stochastic Barrier Functions | 5.33 | | Accept
|
| 224 | Zonotope Domains for Lagrangian Neural Network Verification | 6.00 | | Accept
|
| 225 | Neural Set Function Extensions: Learning with Discrete Functions in High Dimensions | 7.00 | | Accept
|
| 226 | Algorithms with Prediction Portfolios | 6.00 | | Accept
|
| 227 | Pushing the limits of fairness impossibility: Who's the fairest of them all? | 6.33 | | Accept
|
| 228 | Tsetlin Machine for Solving Contextual Bandit Problems | 5.00 | | Accept
|
| 229 | Learning with convolution and pooling operations in kernel methods | 5.75 | | Accept
|
| 230 | QUARK: Controllable Text Generation with Reinforced Unlearning | 7.50 | | Accept
|
| 231 | Global Normalization for Streaming Speech Recognition in a Modular Framework | 6.50 | | Accept
|
| 232 | Learning sparse features can lead to overfitting in neural networks | 6.50 | | Accept
|
| 233 | Multi-fidelity Monte Carlo: a pseudo-marginal approach | 6.00 | | Accept
|
| 234 | Turbocharging Solution Concepts: Solving NEs, CEs and CCEs with Neural Equilibrium Solvers | 7.00 | | Accept
|
| 235 | Learning dynamics of deep linear networks with multiple pathways | 6.33 | | Accept
|
| 236 | Fine-tuning language models to find agreement among humans with diverse preferences | 6.00 | | Accept
|
| 237 | Parameters or Privacy: A Provable Tradeoff Between Overparameterization and Membership Inference | 6.00 | | Accept
|
| 238 | Few-Shot Fast-Adaptive Anomaly Detection | 7.33 | | Accept
|
| 239 | Transformer Memory as a Differentiable Search Index | 6.50 | | Accept
|
| 240 | LOT: Layer-wise Orthogonal Training on Improving l2 Certified Robustness | 6.00 | | Accept
|
| 241 | SAGDA: Achieving $\mathcal{O}(\epsilon^{-2})$ Communication Complexity in Federated Min-Max Learning | 6.00 | | Accept
|
| 242 | Data Augmentation for Compositional Data: Advancing Predictive Models of the Microbiome | 6.67 | | Accept
|
| 243 | Invariance-Aware Randomized Smoothing Certificates | 5.33 | | Accept
|
| 244 | Deep Compression of Pre-trained Transformer Models | 7.33 | | Accept
|
| 245 | Chaotic Regularization and Heavy-Tailed Limits for Deterministic Gradient Descent | 6.00 | | Accept
|
| 246 | Task Discovery: Finding the Tasks that Neural Networks Generalize on | 7.00 | | Accept
|
| 247 | Beyond neural scaling laws: beating power law scaling via data pruning | 8.00 | | Accept
|
| 248 | Unsupervised Learning for Combinatorial Optimization with Principled Objective Relaxation | 5.50 | | Accept
|
| 249 | GPT3.int8(): 8-bit Matrix Multiplication for Transformers at Scale | 5.75 | | Accept
|
| 250 | The Mechanism of Prediction Head in Non-contrastive Self-supervised Learning | 5.75 | | Accept
|
| 251 | Learning low-dimensional generalizable natural features from retina using a U-net | 5.75 | | Accept
|
| 252 | (De-)Randomized Smoothing for Decision Stump Ensembles | 6.00 | | Accept
|
| 253 | Diffusion Visual Counterfactual Explanations | 6.25 | | Accept
|
| 254 | ProtoVAE: A Trustworthy Self-Explainable Prototypical Variational Model | 6.00 | | Accept
|
| 255 | Sketching based Representations for Robust Image Classification with Provable Guarantees | 5.33 | | Accept
|
| 256 | Active Ranking without Strong Stochastic Transitivity | 6.67 | | Accept
|
| 257 | Cross-Linked Unified Embedding for cross-modality representation learning | 6.67 | | Accept
|
| 258 | Subgroup Robustness Grows On Trees: An Empirical Baseline Investigation | 5.33 | | Accept
|
| 259 | Recursive Reinforcement Learning | 5.00 | | Accept
|
| 260 | Contrastive Adapters for Foundation Model Group Robustness | 6.67 | | Accept
|
| 261 | Lottery Tickets on a Data Diet: Finding Initializations with Sparse Trainable Networks | 7.00 | | Accept
|
| 262 | An empirical analysis of compute-optimal large language model training | 7.75 | | Accept
|
| 263 | Dynamic Pricing with Monotonicity Constraint under Unknown Parametric Demand Model | 5.60 | | Accept
|
| 264 | On the Effectiveness of Lipschitz-Driven Rehearsal in Continual Learning | 5.75 | | Accept
|
| 265 | An Algorithm for Learning Switched Linear Dynamics from Data | 5.75 | | Accept
|
| 266 | Make Some Noise: Reliable and Efficient Single-Step Adversarial Training | 5.50 | | Accept
|
| 267 | Shape And Structure Preserving Differential Privacy | 6.00 | | Accept
|
| 268 | Forward-Backward Latent State Inference for Hidden Continuous-Time semi-Markov Chains | 6.25 | | Accept
|
| 269 | Lifting the Information Ratio: An Information-Theoretic Analysis of Thompson Sampling for Contextual Bandits | 6.33 | | Accept
|
| 270 | How Sampling Impacts the Robustness of Stochastic Neural Networks | 5.50 | | Accept
|
| 271 | Robust Reinforcement Learning using Offline Data | 5.50 | | Accept
|
| 272 | Characterizing the Ventral Visual Stream with Response-Optimized Neural Encoding Models | 7.00 | | Accept
|
| 273 | NOMAD: Nonlinear Manifold Decoders for Operator Learning | 6.40 | | Accept
|
| 274 | Implications of Model Indeterminacy for Explanations of Automated Decisions | 7.00 | | Accept
|
| 275 | Single Model Uncertainty Estimation via Stochastic Data Centering | 6.00 | | Accept
|
| 276 | Pre-Train Your Loss: Easy Bayesian Transfer Learning with Informative Priors | 6.00 | | Accept
|
| 277 | A Theoretical View on Sparsely Activated Networks | 5.75 | | Accept
|
| 278 | Deep Counterfactual Estimation with Categorical Background Variables | 5.50 | | Accept
|
| 279 | Temporal Latent Bottleneck: Synthesis of Fast and Slow Processing Mechanisms in Sequence Learning | 5.75 | | Accept
|
| 280 | On the symmetries of the synchronization problem in Cryo-EM: Multi-Frequency Vector Diffusion Maps on the Projective Plane | 5.67 | | Accept
|
| 281 | Towards Trustworthy Automatic Diagnosis Systems by Emulating Doctors' Reasoning with Deep Reinforcement Learning | 5.75 | | Accept
|
| 282 | Reinforcement Learning with Non-Exponential Discounting | 5.75 | | Accept
|
| 283 | Algorithms and Hardness for Learning Linear Thresholds from Label Proportions | 6.00 | | Accept
|
| 284 | MoCoDA: Model-based Counterfactual Data Augmentation | 6.75 | | Accept
|
| 285 | Learning Optimal Flows for Non-Equilibrium Importance Sampling | 6.25 | | Accept
|
| 286 | Residual Multiplicative Filter Networks for Multiscale Reconstruction | 6.00 | | Accept
|
| 287 | On global convergence of ResNets: From finite to infinite width using linear parameterization | 4.67 | | Accept
|
| 288 | Learning Robust Dynamics through Variational Sparse Gating | 5.75 | | Accept
|
| 289 | A Theoretical Framework for Inference Learning | 6.67 | | Accept
|
| 290 | Deep Learning Methods for Proximal Inference via Maximum Moment Restriction | 6.67 | | Accept
|
| 291 | Does GNN Pretraining Help Molecular Representation? | 5.60 | | Accept
|
| 292 | Structure-Aware Image Segmentation with Homotopy Warping | 6.00 | | Accept
|
| 293 | Enhanced Meta Reinforcement Learning via Demonstrations in Sparse Reward Environments | 6.33 | | Accept
|
| 294 | DOPE: Doubly Optimistic and Pessimistic Exploration for Safe Reinforcement Learning | 6.33 | | Accept
|
| 295 | Incentivizing Combinatorial Bandit Exploration | 5.25 | | Accept
|
| 296 | Near-optimal Distributional Reinforcement Learning towards Risk-sensitive Control | 5.75 | | Reject
|
| 297 | A Simple Decentralized Cross-Entropy Method | 5.75 | | Accept
|
| 298 | Structural Analysis of Branch-and-Cut and the Learnability of Gomory Mixed Integer Cuts | 8.00 | | Accept
|
| 299 | Score-Based Generative Models Detect Manifolds | 5.75 | | Accept
|
| 300 | Environment Diversification with Multi-head Neural Network for Invariant Learning | 6.25 | | Accept
|
| 301 | UnfoldML: Cost-Aware and Uncertainty-Based Dynamic 2D Prediction for Multi-Stage Classification | 4.75 | | Accept
|
| 302 | Learning Enhanced Representation for Tabular Data via Neighborhood Propagation | 6.33 | | Accept
|
| 303 | FiLM-Ensemble: Probabilistic Deep Learning via Feature-wise Linear Modulation | 5.25 | | Accept
|
| 304 | Maximizing Revenue under Market Shrinkage and Market Uncertainty | 6.25 | | Accept
|
| 305 | FP8 Quantization: The Power of the Exponent | 5.25 | | Accept
|
| 306 | The Neural Covariance SDE: Shaped Infinite Depth-and-Width Networks at Initialization | 7.25 | | Accept
|
| 307 | Toward Understanding Privileged Features Distillation in Learning-to-Rank | 5.75 | | Accept
|
| 308 | Outlier-Robust Sparse Estimation via Non-Convex Optimization | 6.67 | | Accept
|
| 309 | Neural Abstractions | 6.33 | | Accept
|
| 310 | Analyzing Sharpness along GD Trajectory: Progressive Sharpening and Edge of Stability | 6.00 | | Accept
|
| 311 | Template based Graph Neural Network with Optimal Transport Distances | 7.00 | | Accept
|
| 312 | Single-pass Streaming Lower Bounds for Multi-armed Bandits Exploration with Instance-sensitive Sample Complexity | 6.75 | | Accept
|
| 313 | Embrace the Gap: VAEs Perform Independent Mechanism Analysis | 6.33 | | Accept
|
| 314 | Active Bayesian Causal Inference | 7.00 | | Accept
|
| 315 | Learning Dense Object Descriptors from Multiple Views for Low-shot Category Generalization | 5.75 | | Accept
|
| 316 | VisFIS: Visual Feature Importance Supervision with Right-for-the-Right-Reason Objectives | 5.67 | | Accept
|
| 317 | Data augmentation for efficient learning from parametric experts | 5.75 | | Accept
|
| 318 | A theory of weight distribution-constrained learning | 5.75 | | Accept
|
| 319 | Average Sensitivity of Euclidean k-Clustering | 5.33 | | Accept
|
| 320 | Visual correspondence-based explanations improve AI robustness and human-AI team accuracy | 5.50 | | Accept
|
| 321 | Meta-Reward-Net: Implicitly Differentiable Reward Learning for Preference-based Reinforcement Learning | 6.25 | | Accept
|
| 322 | Flowification: Everything is a normalizing flow | 5.50 | | Accept
|
| 323 | Asynchronous Actor-Critic for Multi-Agent Reinforcement Learning | 5.33 | | Accept
|
| 324 | SQ Lower Bounds for Learning Single Neurons with Massart Noise | 6.00 | | Accept
|
| 325 | Object Representations as Fixed Points: Training Iterative Refinement Algorithms with Implicit Differentiation | 6.50 | | Accept
|
| 326 | Operator Splitting Value Iteration | 7.33 | | Accept
|
| 327 | Discovering and Overcoming Limitations of Noise-engineered Data-free Knowledge Distillation | 5.33 | | Accept
|
| 328 | Drawing out of Distribution with Neuro-Symbolic Generative Models | 5.25 | | Accept
|
| 329 | Beyond Adult and COMPAS: Fair Multi-Class Prediction via Information Projection | 7.50 | | Accept
|
| 330 | Batch size-invariance for policy optimization | 6.00 | | Accept
|
| 331 | Faster Linear Algebra for Distance Matrices | 7.67 | | Accept
|
| 332 | CCCP is Frank-Wolfe in disguise | 6.00 | | Accept
|
| 333 | Generalised Mutual Information for Discriminative Clustering | 5.67 | | Accept
|
| 334 | Controlled Sparsity via Constrained Optimization or: How I Learned to Stop Tuning Penalties and Love Constraints | 6.75 | | Accept
|
| 335 | Nonparametric Uncertainty Quantification for Single Deterministic Neural Network | 6.33 | | Accept
|
| 336 | RNNs of RNNs: Recursive Construction of Stable Assemblies of Recurrent Neural Networks | 5.75 | | Accept
|
| 337 | Benchopt: Reproducible, efficient and collaborative optimization benchmarks | 6.00 | | Accept
|
| 338 | Error Analysis of Tensor-Train Cross Approximation | 5.25 | | Accept
|
| 339 | Adversarially Robust Learning with Tolerance | 5.50 | | Reject
|
| 340 | Evaluation beyond Task Performance: Analyzing Concepts in AlphaZero in Hex | 5.00 | | Accept
|
| 341 | Non-monotonic Resource Utilization in the Bandits with Knapsacks Problem | 6.33 | | Accept
|
| 342 | Improved Differential Privacy for SGD via Optimal Private Linear Operators on Adaptive Streams | 6.33 | | Accept
|
| 343 | Adversarial Robustness is at Odds with Lazy Training | 5.25 | | Accept
|
| 344 | Faster Reinforcement Learning with Value Target Lower Bounding | 3.50 | | Reject
|
| 345 | On the generalization of learning algorithms that do not converge | 5.75 | | Accept
|
| 346 | Task-Free Continual Learning via Online Discrepancy Distance Learning | 6.67 | | Accept
|
| 347 | On Convergence of FedProx: Local Dissimilarity Invariant Bounds, Non-smoothness and Beyond | 6.75 | | Accept
|
| 348 | Trajectory balance: Improved credit assignment in GFlowNets | 7.25 | | Accept
|
| 349 | Are Defenses for Graph Neural Networks Robust? | 6.67 | | Accept
|
| 350 | Information-Theoretic Safe Exploration with Gaussian Processes | 6.00 | | Accept
|
| 351 | Evaluating Robustness to Dataset Shift via Parametric Robustness Sets | 6.25 | | Accept
|
| 352 | Generative Time Series Forecasting with Diffusion, Denoise, and Disentanglement | 5.67 | | Accept
|
| 353 | MorphTE: Injecting Morphology in Tensorized Embeddings | 6.67 | | Accept
|
| 354 | Diffusion Models as Plug-and-Play Priors | 5.25 | | Accept
|
| 355 | Capturing Graphs with Hypo-Elliptic Diffusions | 5.50 | | Accept
|
| 356 | PAC Prediction Sets for Meta-Learning | 5.80 | | Accept
|
| 357 | Supervised Training of Conditional Monge Maps | 6.40 | | Accept
|
| 358 | Bridging Central and Local Differential Privacy in Data Acquisition Mechanisms | 5.75 | | Accept
|
| 359 | Exploration-Guided Reward Shaping for Reinforcement Learning under Sparse Rewards | 5.33 | | Accept
|
| 360 | Modular Flows: Differential Molecular Generation | 5.50 | | Accept
|
| 361 | Provably Adversarially Robust Detection of Out-of-Distribution Data (Almost) for Free | 5.25 | | Accept
|
| 362 | Anchor-Changing Regularized Natural Policy Gradient for Multi-Objective Reinforcement Learning | 6.50 | | Accept
|
| 363 | Self-Explaining Deviations for Coordination | 6.50 | | Accept
|
| 364 | Overparameterization from Computational Constraints | 6.00 | | Accept
|
| 365 | Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP | 7.00 | | Accept
|
| 366 | Multi-Objective Deep Learning with Adaptive Reference Vectors | 5.40 | | Accept
|
| 367 | Self-Supervised Learning Through Efference Copies | 5.50 | | Accept
|
| 368 | Mesoscopic modeling of hidden spiking neurons | 7.00 | | Accept
|
| 369 | Learning Interface Conditions in Domain Decomposition Solvers | 6.00 | | Accept
|
| 370 | Private and Communication-Efficient Algorithms for Entropy Estimation | 5.67 | | Accept
|
| 371 | Securing Secure Aggregation: Mitigating Multi-Round Privacy Leakage in Federated Learning | 6.25 | | Reject
|
| 372 | Asymptotics of $\ell_2$ Regularized Network Embeddings | 6.25 | | Accept
|
| 373 | K-LITE: Learning Transferable Visual Models with External Knowledge | 6.75 | | Accept
|
| 374 | Kernel Multimodal Continuous Attention | 6.00 | | Accept
|
| 375 | Continual Learning In Environments With Polynomial Mixing Times | 6.00 | | Accept
|
| 376 | Stars: Tera-Scale Graph Building for Clustering and Learning | 5.75 | | Accept
|
| 377 | Multifidelity Reinforcement Learning with Control Variates | 5.67 | | Reject
|
| 378 | Evaluated CMI Bounds for Meta Learning: Tightness and Expressiveness | 6.33 | | Accept
|
| 379 | Graph Neural Networks are Dynamic Programmers | 5.67 | | Accept
|
| 380 | On the Adversarial Robustness of Mixture of Experts | 5.50 | | Accept
|
| 381 | Learning to Reconstruct Missing Data from Spatiotemporal Graphs with Sparse Observations | 6.00 | | Accept
|
| 382 | A New Family of Generalization Bounds Using Samplewise Evaluated CMI | 6.50 | | Accept
|
| 383 | CS-Shapley: Class-wise Shapley Values for Data Valuation in Classification | 5.50 | | Accept
|
| 384 | Anonymous Bandits for Multi-User Systems | 6.75 | | Accept
|
| 385 | Are Two Heads the Same as One? Identifying Disparate Treatment in Fair Neural Networks | 5.00 | | Accept
|
| 386 | Tempo: Accelerating Transformer-Based Model Training through Memory Footprint Reduction | 5.50 | | Accept
|
| 387 | Towards a Unified Framework for Uncertainty-aware Nonlinear Variable Selection with Theoretical Guarantees | 6.25 | | Accept
|
| 388 | Proppo: a Message Passing Framework for Customizable and Composable Learning Algorithms | 4.00 | | Accept
|
| 389 | EZNAS: Evolving Zero-Cost Proxies For Neural Architecture Scoring | 5.75 | | Accept
|
| 390 | Benefits of Additive Noise in Composing Classes with Bounded Capacity | 6.67 | | Accept
|
| 391 | Trimmed Maximum Likelihood Estimation for Robust Generalized Linear Model | 7.00 | | Accept
|
| 392 | On the Stability and Scalability of Node Perturbation Learning | 6.00 | | Accept
|
| 393 | The Effects of Regularization and Data Augmentation are Class Dependent | 5.50 | | Accept
|
| 394 | On the Effectiveness of Persistent Homology | 4.75 | | Accept
|
| 395 | Log-Linear-Time Gaussian Processes Using Binary Tree Kernels | 6.25 | | Accept
|
| 396 | Hypothesis Testing for Differentially Private Linear Regression | 6.50 | | Accept
|
| 397 | BEER: Fast $O(1/T)$ Rate for Decentralized Nonconvex Optimization with Communication Compression | 6.00 | | Accept
|
| 398 | GlanceNets: Interpretable, Leak-proof Concept-based Models | 6.00 | | Accept
|
| 399 | Distributed Online Convex Optimization with Compressed Communication | 4.75 | | Accept
|
| 400 | Contextual Dynamic Pricing with Unknown Noise: Explore-then-UCB Strategy and Improved Regrets | 6.00 | | Accept
|
| 401 | Indicators of Attack Failure: Debugging and Improving Optimization of Adversarial Examples | 5.50 | | Accept
|
| 402 | SoteriaFL: A Unified Framework for Private Federated Learning with Communication Compression | 6.33 | | Accept
|
| 403 | Variable-rate hierarchical CPC leads to acoustic unit discovery in speech | 5.67 | | Accept
|
| 404 | Hierarchical Agglomerative Graph Clustering in Poly-Logarithmic Depth | 6.00 | | Accept
|
| 405 | Scalable and Efficient Non-adaptive Deterministic Group Testing | 5.25 | | Accept
|
| 406 | Learning to Configure Computer Networks with Neural Algorithmic Reasoning | 6.00 | | Accept
|
| 407 | Supervising the Multi-Fidelity Race of Hyperparameter Configurations | 7.00 | | Accept
|
| 408 | Anytime-Valid Inference For Multinomial Count Data | 5.75 | | Accept
|
| 409 | A Theoretical Study on Solving Continual Learning | 5.25 | | Accept
|
| 410 | Understanding Deep Contrastive Learning via Coordinate-wise Optimization | 7.00 | | Accept
|
| 411 | Privacy Induces Robustness: Information-Computation Gaps and Sparse Mean Estimation | 6.67 | | Accept
|
| 412 | The trade-offs of model size in large recommendation models : 100GB to 10MB Criteo-tb DLRM model | 5.67 | | Accept
|
| 413 | Simple Unsupervised Object-Centric Learning for Complex and Naturalistic Videos | 5.75 | | Accept
|
| 414 | Robustness to Label Noise Depends on the Shape of the Noise Distribution | 6.00 | | Accept
|
| 415 | MACK: Multimodal Aligned Conceptual Knowledge for Unpaired Image-text Matching | 5.75 | | Accept
|
| 416 | CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers | 5.25 | | Reject
|
| 417 | Intra-agent speech permits zero-shot task acquisition | 5.50 | | Accept
|
| 418 | Neural Attentive Circuits | 6.33 | | Accept
|
| 419 | Learning Physics Constrained Dynamics Using Autoencoders | 5.75 | | Accept
|
| 420 | Near-Optimal Correlation Clustering with Privacy | 6.75 | | Accept
|
| 421 | Stochastic Halpern Iteration with Variance Reduction for Stochastic Monotone Inclusions | 5.75 | | Accept
|
| 422 | Augmenting Online Algorithms with $\varepsilon$-Accurate Predictions | 6.00 | | Accept
|
| 423 | PALMER: Perception - Action Loop with Memory for Long-Horizon Planning | 6.50 | | Accept
|
| 424 | DataMUX: Data Multiplexing for Neural Networks | 7.25 | | Accept
|
| 425 | Learning (Very) Simple Generative Models Is Hard | 7.00 | | Accept
|
| 426 | Recurrent Convolutional Neural Networks Learn Succinct Learning Algorithms | 5.50 | | Accept
|
| 427 | Assaying Out-Of-Distribution Generalization in Transfer Learning | 6.25 | | Accept
|
| 428 | Learning-Augmented Algorithms for Online Linear and Semidefinite Programming | 6.33 | | Accept
|
| 429 | Trustworthy Monte Carlo | 5.25 | | Accept
|
| 430 | Fair Rank Aggregation | 5.25 | | Accept
|
| 431 | Holomorphic Equilibrium Propagation Computes Exact Gradients Through Finite Size Oscillations | 8.25 | | Accept
|
| 432 | Active Learning with Safety Constraints | 4.00 | | Accept
|
| 433 | A Boosting Approach to Reinforcement Learning | 7.00 | | Accept
|
| 434 | VaiPhy: a Variational Inference Based Algorithm for Phylogeny | 7.25 | | Accept
|
| 435 | Curious Exploration via Structured World Models Yields Zero-Shot Object Manipulation | 7.00 | | Accept
|
| 436 | Convexity Certificates from Hessians | 6.00 | | Accept
|
| 437 | Envy-free Policy Teaching to Multiple Agents | 6.00 | | Accept
|
| 438 | Finite Sample Analysis Of Dynamic Regression Parameter Learning | 6.67 | | Accept
|
| 439 | Learning to Navigate Wikipedia by Taking Random Walks | 5.33 | | Accept
|
| 440 | Efficient and Stable Fully Dynamic Facility Location | 6.75 | | Accept
|
| 441 | RISE: Robust Individualized Decision Learning with Sensitive Variables | 5.75 | | Accept
|
| 442 | Adaptive Stochastic Variance Reduction for Non-convex Finite-Sum Minimization | 5.67 | | Accept
|
| 443 | Invariance Learning in Deep Neural Networks with Differentiable Laplace Approximations | 6.67 | | Accept
|
| 444 | Jump Self-attention: Capturing High-order Statistics in Transformers | 6.25 | | Accept
|
| 445 | Predictive Coding beyond Gaussian Distributions | 6.25 | | Accept
|
| 446 | Constrained GPI for Zero-Shot Transfer in Reinforcement Learning | 6.33 | | Accept
|
| 447 | Multi-agent Dynamic Algorithm Configuration | 6.75 | | Accept
|
| 448 | An Adaptive Kernel Approach to Federated Learning of Heterogeneous Causal Effects | 6.25 | | Accept
|
| 449 | DevFly: Bio-Inspired Development of Binary Connections for Locality Preserving Sparse Codes | 5.67 | | Accept
|
| 450 | Monte Carlo Tree Search based Variable Selection for High Dimensional Bayesian Optimization | 6.80 | | Accept
|
| 451 | Learning from Few Samples: Transformation-Invariant SVMs with Composition and Locality at Multiple Scales | 6.67 | | Accept
|
| 452 | Recovering Private Text in Federated Learning of Language Models | 5.25 | | Accept
|
| 453 | Improved Coresets for Euclidean $k$-Means | 5.50 | | Accept
|
| 454 | Computational Doob h-transforms for Online Filtering of Discretely Observed Diffusions | 5.75 | | Reject
|
| 455 | SPD domain-specific batch normalization to crack interpretable unsupervised domain adaptation in EEG | 7.25 | | Accept
|
| 456 | Better SGD using Second-order Momentum | 6.33 | | Accept
|
| 457 | Fairness for Workers Who Pull the Arms: An Index Based Policy for Allocation of Restless Bandit Tasks | 5.33 | | Reject
|
| 458 | Archimedes Meets Privacy: On Privately Estimating Quantiles in High Dimensions Under Minimal Assumptions | 6.50 | | Accept
|
| 459 | A Unified Hard-Constraint Framework for Solving Geometrically Complex PDEs | 5.75 | | Accept
|
| 460 | PhysGNN: A Physics--Driven Graph Neural Network Based Model for Predicting Soft Tissue Deformation in Image--Guided Neurosurgery | 6.00 | | Accept
|
| 461 | Rethinking Knowledge Graph Evaluation Under the Open-World Assumption | 6.50 | | Accept
|
| 462 | Thor: Wielding Hammers to Integrate Language Models and Automated Theorem Provers | 7.33 | | Accept
|
| 463 | Data-Efficient Pipeline for Offline Reinforcement Learning with Limited Data | 7.00 | | Accept
|
| 464 | Diversity vs. Recognizability: Human-like generalization in one-shot generative models | 7.00 | | Accept
|
| 465 | Where2comm: Communication-Efficient Collaborative Perception via Spatial Confidence Maps | 6.00 | | Accept
|
| 466 | Predicting Cellular Responses to Novel Drug Perturbations at a Single-Cell Resolution | 6.67 | | Accept
|
| 467 | The least-control principle for local learning at equilibrium | 7.50 | | Accept
|
| 468 | Evolution of Neural Tangent Kernels under Benign and Adversarial Training | 6.25 | | Accept
|
| 469 | Generalizing Consistent Multi-Class Classification with Rejection to be Compatible with Arbitrary Losses | 6.75 | | Accept
|
| 470 | Addressing Leakage in Concept Bottleneck Models | 6.33 | | Accept
|
| 471 | Contrastive and Non-Contrastive Self-Supervised Learning Recover Global and Local Spectral Embedding Methods | 5.75 | | Accept
|
| 472 | Models of human preference for learning reward functions | 4.50 | | Reject
|
| 473 | Deep Equilibrium Approaches to Diffusion Models | 6.00 | | Accept
|
| 474 | Distributed Influence-Augmented Local Simulators for Parallel MARL in Large Networked Systems | 6.67 | | Accept
|
| 475 | Neural Temporal Walks: Motif-Aware Representation Learning on Continuous-Time Dynamic Graphs | 6.33 | | Accept
|
| 476 | AutoST: Towards the Universal Modeling of Spatio-temporal Sequences | 6.33 | | Accept
|
| 477 | Estimating individual treatment effects under unobserved confounding using binary instruments | 6.33 | | Reject
|
| 478 | Intrinsic dimensionality estimation using Normalizing Flows | 6.25 | | Accept
|
| 479 | Neural Lyapunov Control of Unknown Nonlinear Systems with Stability Guarantees | 6.33 | | Accept
|
| 480 | Group Meritocratic Fairness in Linear Contextual Bandits | 6.25 | | Accept
|
| 481 | Private Multiparty Perception for Navigation | 5.67 | | Accept
|
| 482 | Scalable Multi-agent Covering Option Discovery based on Kronecker Graphs | 6.25 | | Accept
|
| 483 | Beyond IID: data-driven decision-making in heterogeneous environments | 6.40 | | Accept
|
| 484 | In Defense of the Unitary Scalarization for Deep Multi-Task Learning | 5.67 | | Accept
|
| 485 | The Gyro-Structure of Some Matrix Manifolds | 6.67 | | Accept
|
| 486 | Controlling Confusion via Generalisation Bounds | 5.67 | | Reject
|
| 487 | Effective Dimension in Bandit Problems under Censorship | 5.00 | | Accept
|
| 488 | LAPO: Latent-Variable Advantage-Weighted Policy Optimization for Offline Reinforcement Learning | 5.50 | | Accept
|
| 489 | Augmented Deep Unrolling Networks for Snapshot Compressive Hyperspectral Imaging | 5.00 | | Reject
|
| 490 | Luckiness in Multiscale Online Learning | 6.50 | | Accept
|
| 491 | On Kernelized Multi-Armed Bandits with Constraints | 5.75 | | Accept
|
| 492 | Beyond Rewards: a Hierarchical Perspective on Offline Multiagent Behavioral Analysis | 6.75 | | Accept
|
| 493 | Unsupervised Object Representation Learning using Translation and Rotation Group Equivariant VAE | 5.33 | | Accept
|
| 494 | Unbiased Estimates for Multilabel Reductions of Extreme Classification with Missing Labels | 5.25 | | Reject
|
| 495 | A Solver-free Framework for Scalable Learning in Neural ILP Architectures | 7.00 | | Accept
|
| 496 | Better Best of Both Worlds Bounds for Bandits with Switching Costs | 6.50 | | Accept
|
| 497 | SoLar: Sinkhorn Label Refinery for Imbalanced Partial-Label Learning | 6.00 | | Accept
|
| 498 | 3D Concept Grounding on Neural Fields | 6.50 | | Accept
|
| 499 | Learning Dynamical Systems via Koopman Operator Regression in Reproducing Kernel Hilbert Spaces | 6.25 | | Accept
|
| 500 | Confident Adaptive Language Modeling | 7.50 | | Accept
|
| 501 | Is Integer Arithmetic Enough for Deep Learning Training? | 6.25 | | Accept
|
| 502 | A Unified Sequence Interface for Vision Tasks | 5.75 | | Accept
|
| 503 | Semantic Exploration from Language Abstractions and Pretrained Representations | 5.75 | | Accept
|
| 504 | Semantic uncertainty intervals for disentangled latent spaces | 5.00 | | Accept
|
| 505 | Decomposable Non-Smooth Convex Optimization with Nearly-Linear Gradient Oracle Complexity | 6.00 | | Accept
|
| 506 | Better Uncertainty Calibration via Proper Scores for Classification and Beyond | 6.67 | | Accept
|
| 507 | Look where you look! Saliency-guided Q-networks for generalization in visual Reinforcement Learning | 5.67 | | Accept
|
| 508 | Multi-Lingual Acquisition on Multimodal Pre-training for Cross-modal Retrieval | 6.25 | | Accept
|
| 509 | Learning Distributed and Fair Policies for Network Load Balancing as Markov Potential Game | 5.60 | | Accept
|
| 510 | Robust Imitation of a Few Demonstrations with a Backwards Model | 5.67 | | Accept
|
| 511 | Learning on Arbitrary Graph Topologies via Predictive Coding | 5.67 | | Accept
|
| 512 | Efficient Graph Similarity Computation with Alignment Regularization | 5.67 | | Accept
|
| 513 | Neural Estimation of Submodular Functions with Applications to Differentiable Subset Selection | 6.33 | | Accept
|
| 514 | Probabilistic Transformer: Modelling Ambiguities and Distributions for RNA Folding and Molecule Design | 6.67 | | Accept
|
| 515 | Polynomial-Time Optimal Equilibria with a Mediator in Extensive-Form Games | 5.50 | | Accept
|
| 516 | Discovered Policy Optimisation | 6.00 | | Accept
|
| 517 | Langevin Autoencoders for Learning Deep Latent Variable Models | 6.00 | | Accept
|
| 518 | Risk-Driven Design of Perception Systems | 7.00 | | Accept
|
| 519 | Training Scale-Invariant Neural Networks on the Sphere Can Happen in Three Regimes | 6.50 | | Accept
|
| 520 | Highly Parallel Deep Ensemble Learning | 4.50 | | Reject
|
| 521 | You Never Stop Dancing: Non-freezing Dance Generation via Bank-constrained Manifold Projection | 6.75 | | Accept
|
| 522 | Regularized Molecular Conformation Fields | 6.50 | | Accept
|
| 523 | A gradient sampling method with complexity guarantees for Lipschitz functions in high and low dimensions | 7.50 | | Accept
|
| 524 | Decoupled Self-supervised Learning for Graphs | 6.25 | | Accept
|
| 525 | Meta Reinforcement Learning with Finite Training Tasks - a Density Estimation Approach | 6.00 | | Accept
|
| 526 | Exponentially Improving the Complexity of Simulating the Weisfeiler-Lehman Test with Graph Neural Networks | 5.67 | | Accept
|
| 527 | Post-hoc estimators for learning to defer to an expert | 6.67 | | Accept
|
| 528 | Personalized Federated Learning towards Communication Efficiency, Robustness and Fairness | 5.20 | | Accept
|
| 529 | Bayesian Optimistic Optimization: Optimistic Exploration for Model-based Reinforcement Learning | 5.67 | | Accept
|
| 530 | Pre-trained Adversarial Perturbations | 5.50 | | Accept
|
| 531 | A contrastive rule for meta-learning | 6.75 | | Accept
|
| 532 | Finding Optimal Arms in Non-stochastic Combinatorial Bandits with Semi-bandit Feedback and Finite Budget | 6.33 | | Accept
|
| 533 | Rate-Distortion Theoretic Bounds on Generalization Error for Distributed Learning | 6.00 | | Accept
|
| 534 | ReFactor GNNs: Revisiting Factorisation-based Models from a Message-Passing Perspective | 6.00 | | Accept
|
| 535 | Local Metric Learning for Off-Policy Evaluation in Contextual Bandits with Continuous Actions | 6.20 | | Accept
|
| 536 | Variance Reduced ProxSkip: Algorithm, Theory and Application to Federated Learning | 6.67 | | Accept
|
| 537 | Learning Neural Acoustic Fields | 7.25 | | Accept
|
| 538 | Partial Identification of Treatment Effects with Implicit Generative Models | 6.25 | | Accept
|
| 539 | ESCADA: Efficient Safety and Context Aware Dose Allocation for Precision Medicine | 5.75 | | Accept
|
| 540 | A Data-Augmentation Is Worth A Thousand Samples: Analytical Moments And Sampling-Free Training | 6.25 | | Accept
|
| 541 | Statistically Meaningful Approximation: a Case Study on Approximating Turing Machines with Transformers | 6.75 | | Accept
|
| 542 | Grounded Video Situation Recognition | 6.25 | | Accept
|
| 543 | Do Residual Neural Networks discretize Neural Ordinary Differential Equations? | 6.00 | | Accept
|
| 544 | Information bottleneck theory of high-dimensional regression: relevancy, efficiency and optimality | 5.33 | | Accept
|
| 545 | On the Representation Collapse of Sparse Mixture of Experts | 5.67 | | Accept
|
| 546 | Certifying Robust Graph Classification under Orthogonal Gromov-Wasserstein Threats | 6.00 | | Accept
|
| 547 | Decentralized Training of Foundation Models in Heterogeneous Environments | 7.67 | | Accept
|
| 548 | Explicit Tradeoffs between Adversarial and Natural Distributional Robustness | 5.75 | | Accept
|
| 549 | Escaping Saddle Points for Effective Generalization on Class-Imbalanced Data | 6.00 | | Accept
|
| 550 | Randomized Sketches for Clustering: Fast and Optimal Kernel $k$-Means | 6.67 | | Accept
|
| 551 | Learning Articulated Rigid Body Dynamics with Lagrangian Graph Neural Network | 5.75 | | Accept
|
| 552 | Prompt Injection: Parameterization of Fixed Inputs | 6.33 | | Reject
|
| 553 | A composable machine-learning approach for steady-state simulations on high-resolution grids | 6.33 | | Accept
|
| 554 | Graph Learning Assisted Multi-Objective Integer Programming | 6.33 | | Accept
|
| 555 | Disentangling the Predictive Variance of Deep Ensembles through the Neural Tangent Kernel | 7.00 | | Accept
|
| 556 | Probing Classifiers are Unreliable for Concept Removal and Detection | 6.50 | | Accept
|
| 557 | Learning to Scaffold: Optimizing Model Explanations for Teaching | 7.33 | | Accept
|
| 558 | Public Wisdom Matters! Discourse-Aware Hyperbolic Fourier Co-Attention for Social Text Classification | 7.00 | | Accept
|
| 559 | Positive-Unlabeled Learning using Random Forests via Recursive Greedy Risk Minimization | 6.25 | | Accept
|
| 560 | Missing Data Imputation and Acquisition with Deep Hierarchical Models and Hamiltonian Monte Carlo | 6.00 | | Accept
|
| 561 | RényiCL: Contrastive Representation Learning with Skew Rényi Divergence | 6.50 | | Accept
|
| 562 | Fine-tuning Language Models over Slow Networks using Activation Quantization with Guarantees | 6.00 | | Accept
|
| 563 | Benefits of Permutation-Equivariance in Auction Mechanisms | 5.75 | | Accept
|
| 564 | Efficient Methods for Non-stationary Online Learning | 7.00 | | Accept
|
| 565 | Continuous MDP Homomorphisms and Homomorphic Policy Gradient | 7.00 | | Accept
|
| 566 | Sustainable Online Reinforcement Learning for Auto-bidding | 6.67 | | Accept
|
| 567 | Learning to Branch with Tree MDPs | 6.67 | | Accept
|
| 568 | Learning Recourse on Instance Environment to Enhance Prediction Accuracy | 5.50 | | Accept
|
| 569 | Sleeper Agent: Scalable Hidden Trigger Backdoors for Neural Networks Trained from Scratch | 6.25 | | Accept
|
| 570 | Sparse Gaussian Process Hyperparameters: Optimize or Integrate? | 6.25 | | Accept
|
| 571 | MCL-GAN: Generative Adversarial Networks with Multiple Specialized Discriminators | 4.75 | | Accept
|
| 572 | Relaxing Equivariance Constraints with Non-stationary Continuous Filters | 5.50 | | Accept
|
| 573 | A general approximation lower bound in $L^p$ norm, with applications to feed-forward neural networks | 6.00 | | Accept
|
| 574 | Generalization Bounds for Gradient Methods via Discrete and Continuous Prior | 5.50 | | Accept
|
| 575 | Implicitly regularized interaction between SGD and the loss landscape geometry | 4.33 | | Reject
|
| 576 | Function Classes for Identifiable Nonlinear Independent Component Analysis | 5.00 | | Accept
|
| 577 | Tree ensemble kernels for Bayesian optimization with known constraints over mixed-feature spaces | 6.33 | | Accept
|
| 578 | Anonymized Histograms in Intermediate Privacy Models | 6.50 | | Accept
|
| 579 | Subquadratic Kronecker Regression with Applications to Tensor Decomposition | 7.00 | | Accept
|
| 580 | CascadeXML: Rethinking Transformers for End-to-end Multi-resolution Training in Extreme Multi-label Classification | 6.50 | | Accept
|
| 581 | Mathematically Modeling the Lexicon Entropy of Emergent Language | 4.00 | | Reject
|
| 582 | Unsupervised Learning From Incomplete Measurements for Inverse Problems | 6.00 | | Accept
|
| 583 | Support Recovery in Sparse PCA with Incomplete Data | 5.50 | | Accept
|
| 584 | ULNeF: Untangled Layered Neural Fields for Mix-and-Match Virtual Try-On | 6.25 | | Accept
|
| 585 | Private Isotonic Regression | 7.00 | | Accept
|
| 586 | Real-Valued Backpropagation is Unsuitable for Complex-Valued Neural Networks | 7.00 | | Accept
|
| 587 | Learning Partial Equivariances From Data | 5.67 | | Accept
|
| 588 | A Variant of Anderson Mixing with Minimal Memory Size | 6.50 | | Accept
|
| 589 | A hybrid approach to seismic deblending: when physics meets self-supervision | 4.50 | | Reject
|
| 590 | Improved techniques for deterministic l2 robustness | 5.50 | | Accept
|
| 591 | Augmented RBMLE-UCB Approach for Adaptive Control of Linear Quadratic Systems | 5.80 | | Accept
|
| 592 | Optimizing Data Collection for Machine Learning | 5.33 | | Accept
|
| 593 | On Sample Optimality in Personalized Collaborative and Federated Learning | 6.25 | | Accept
|
| 594 | Dual-discriminative Graph Neural Network for Imbalanced Graph-level Anomaly Detection | 6.50 | | Accept
|
| 595 | Revisiting Populations in Multi-Agent Communication | 5.00 | | Reject
|
| 596 | Sharper Convergence Guarantees for Asynchronous SGD for Distributed and Federated Learning | 7.33 | | Accept
|
| 597 | Vision Transformers provably learn spatial structure | 4.50 | | Accept
|
| 598 | Using Mixup as a Regularizer Can Surprisingly Improve Accuracy & Out-of-Distribution Robustness | 6.00 | | Accept
|
| 599 | Unsupervised Adaptation from Repeated Traversals for Autonomous Driving | 5.25 | | Accept
|
| 600 | General Cutting Planes for Bound-Propagation-Based Neural Network Verification | 6.33 | | Accept
|
| 601 | Byzantine Spectral Ranking | 6.25 | | Accept
|
| 602 | Low-Rank Modular Reinforcement Learning via Muscle Synergy | 6.67 | | Accept
|
| 603 | CLOOB: Modern Hopfield Networks with InfoLOOB Outperform CLIP | 4.67 | | Accept
|
| 604 | Learning on the Edge: Online Learning with Stochastic Feedback Graphs | 6.50 | | Accept
|
| 605 | On Measuring Excess Capacity in Neural Networks | 6.33 | | Accept
|
| 606 | Log-Concave and Multivariate Canonical Noise Distributions for Differential Privacy | 6.67 | | Accept
|
| 607 | Bayesian Active Learning with Fully Bayesian Gaussian Processes | 6.00 | | Accept
|
| 608 | The computational and learning benefits of Daleian neural networks | 6.67 | | Accept
|
| 609 | Robust Streaming PCA | 6.25 | | Accept
|
| 610 | Coincidence Detection Is All You Need | 1.67 | | Reject
|
| 611 | A Reparametrization-Invariant Sharpness Measure Based on Information Geometry | 6.50 | | Accept
|
| 612 | Disentangling Causal Effects from Sets of Interventions in the Presence of Unobserved Confounders | 5.75 | | Accept
|
| 613 | Mask Matching Transformer for Few-Shot Segmentation | 4.50 | | Accept
|
| 614 | Adjoint-aided inference of Gaussian process driven differential equations | 5.50 | | Accept
|
| 615 | Estimating the Arc Length of the Optimal ROC Curve and Lower Bounding the Maximal AUC | 5.75 | | Accept
|
| 616 | Unsupervised Learning of Group Invariant and Equivariant Representations | 6.25 | | Accept
|
| 617 | Bounding and Approximating Intersectional Fairness through Marginal Fairness | 5.67 | | Accept
|
| 618 | BYOL-Explore: Exploration by Bootstrapped Prediction | 6.75 | | Accept
|
| 619 | Meta-sketch: A Neural Data Structure for Estimating Item Frequencies of Data Streams | 6.00 | | Reject
|
| 620 | Lipschitz Bandits with Batched Feedback | 6.25 | | Accept
|
| 621 | NeuroSchedule: A Novel Effective GNN-based Scheduling Method for High-level Synthesis | 6.00 | | Accept
|
| 622 | Quantized Training of Gradient Boosting Decision Trees | 6.00 | | Accept
|
| 623 | On the difficulty of learning chaotic dynamics with RNNs | 7.50 | | Accept
|
| 624 | Embracing Consistency: A One-Stage Approach for Spatio-Temporal Video Grounding | 6.00 | | Accept
|
| 625 | Meta-ticket: Finding optimal subnetworks for few-shot learning within randomly initialized neural networks | 5.25 | | Accept
|
| 626 | FR: Folded Rationalization with a Unified Encoder | 6.00 | | Accept
|
| 627 | Generalization Properties of NAS under Activation and Skip Connection Search | 5.75 | | Accept
|
| 628 | Improving Out-of-Distribution Generalization by Adversarial Training with Structured Priors | 5.60 | | Accept
|
| 629 | Batch Bayesian Optimization on Permutations using the Acquisition Weighted Kernel | 6.00 | | Accept
|
| 630 | Optimal Weak to Strong Learning | 7.00 | | Accept
|
| 631 | Differentiable Rendering with Reparameterized Volume Sampling | 3.33 | | Reject
|
| 632 | Principle Components Analysis based frameworks for efficient missing data imputation algorithms | 3.75 | | Reject
|
| 633 | Sequential Information Design: Learning to Persuade in the Dark | 6.75 | | Accept
|
| 634 | On Optimal Learning Under Targeted Data Poisoning | 6.50 | | Accept
|
| 635 | Distilled Gradient Aggregation: Purify Features for Input Attribution in the Deep Neural Network | 5.50 | | Accept
|
| 636 | Okapi: Generalising Better by Making Statistical Matches Match | 5.25 | | Accept
|
| 637 | Accelerated Primal-Dual Gradient Method for Smooth and Convex-Concave Saddle-Point Problems with Bilinear Coupling | 7.25 | | Accept
|
| 638 | Accelerating SGD for Highly Ill-Conditioned Huge-Scale Online Matrix Completion | 6.00 | | Accept
|
| 639 | ShuffleMixer: An Efficient ConvNet for Image Super-Resolution | 4.75 | | Accept
|
| 640 | BadPrompt: Backdoor Attacks on Continuous Prompts | 6.00 | | Accept
|
| 641 | A Characterization of Semi-Supervised Adversarially Robust PAC Learnability | 6.50 | | Accept
|
| 642 | The First Optimal Acceleration of High-Order Methods in Smooth Convex Optimization | 6.00 | | Accept
|
| 643 | A Multilabel Classification Framework for Approximate Nearest Neighbor Search | 5.00 | | Accept
|
| 644 | Power and limitations of single-qubit native quantum neural networks | 5.50 | | Accept
|
| 645 | Learning Debiased Classifier with Biased Committee | 6.00 | | Accept
|
| 646 | Effectiveness of Vision Transformer for Fast and Accurate Single-Stage Pedestrian Detection | 5.00 | | Accept
|
| 647 | Extrapolation and Spectral Bias of Neural Nets with Hadamard Product: a Polynomial Net Study | 6.50 | | Accept
|
| 648 | Local Identifiability of Deep ReLU Neural Networks: the Theory | 5.33 | | Accept
|
| 649 | The First Optimal Algorithm for Smooth and Strongly-Convex-Strongly-Concave Minimax Optimization | 7.00 | | Accept
|
| 650 | On the Robustness of Graph Neural Diffusion to Topology Perturbations | 6.33 | | Accept
|
| 651 | Graph Neural Network Bandits | 6.33 | | Accept
|
| 652 | SelecMix: Debiased Learning by Contradicting-pair Sampling | 5.67 | | Accept
|
| 653 | Maximum Common Subgraph Guided Graph Retrieval: Late and Early Interaction Networks | 6.33 | | Accept
|
| 654 | Proximal Point Imitation Learning | 6.00 | | Accept
|
| 655 | Benign Overfitting in Two-layer Convolutional Neural Networks | 6.50 | | Accept
|
| 656 | Joint Entropy Search For Maximally-Informed Bayesian Optimization | 5.75 | | Accept
|
| 657 | On the Learning Mechanisms in Physical Reasoning | 6.50 | | Accept
|
| 658 | Towards a Standardised Performance Evaluation Protocol for Cooperative MARL | 6.50 | | Accept
|
| 659 | Inverse Design for Fluid-Structure Interactions using Graph Network Simulators | 6.25 | | Accept
|
| 660 | Optimal Query Complexities for Dynamic Trace Estimation | 7.00 | | Accept
|
| 661 | Towards Efficient Post-training Quantization of Pre-trained Language Models | 6.25 | | Accept
|
| 662 | On A Mallows-type Model For (Ranked) Choices | 6.50 | | Accept
|
| 663 | Not too little, not too much: a theoretical analysis of graph (over)smoothing | 6.50 | | Accept
|
| 664 | On Analyzing Generative and Denoising Capabilities of Diffusion-based Deep Generative Models | 5.75 | | Accept
|
| 665 | A Robust Phased Elimination Algorithm for Corruption-Tolerant Gaussian Process Bandits | 5.00 | | Accept
|
| 666 | Optimal Brain Compression: A Framework for Accurate Post-Training Quantization and Pruning | 6.33 | | Accept
|
| 667 | Movement Penalized Bayesian Optimization with Application to Wind Energy Systems | 6.00 | | Accept
|
| 668 | A Regret-Variance Trade-Off in Online Learning | 6.00 | | Accept
|
| 669 | An $\alpha$-regret analysis of Adversarial Bilateral Trade | 6.40 | | Accept
|
| 670 | Unified Optimal Transport Framework for Universal Domain Adaptation | 5.75 | | Accept
|
| 671 | Efficient Meta Reinforcement Learning for Preference-based Fast Adaptation | 6.50 | | Accept
|
| 672 | Paraphrasing Is All You Need for Novel Object Captioning | 6.75 | | Accept
|
| 673 | Consistency of Constrained Spectral Clustering under Graph Induced Fair Planted Partitions | 6.25 | | Accept
|
| 674 | Causal Discovery in Probabilistic Networks with an Identifiable Causal Effect | 6.00 | | Reject
|
| 675 | A Win-win Deal: Towards Sparse and Robust Pre-trained Language Models | 5.00 | | Accept
|
| 676 | What Makes Graph Neural Networks Miscalibrated? | 6.25 | | Accept
|
| 677 | Sequence-to-Set Generative Models | 6.00 | | Accept
|
| 678 | Active Exploration for Inverse Reinforcement Learning | 7.00 | | Accept
|
| 679 | A Universal Error Measure for Input Predictions Applied to Online Graph Problems | 6.25 | | Accept
|
| 680 | FeLMi : Few shot Learning with hard Mixup | 5.25 | | Accept
|
| 681 | Reinforcement Learning in a Birth and Death Process: Breaking the Dependence on the State Space | 5.75 | | Accept
|
| 682 | Meta-Learning with Self-Improving Momentum Target | 6.25 | | Accept
|
| 683 | Generalization Analysis of Message Passing Neural Networks on Large Random Graphs | 6.33 | | Accept
|
| 684 | Hyper-Representations as Generative Models: Sampling Unseen Neural Network Weights | 5.67 | | Accept
|
| 685 | Isometric 3D Adversarial Examples in the Physical World | 6.33 | | Accept
|
| 686 | Uncovering the Structural Fairness in Graph Contrastive Learning | 7.25 | | Accept
|
| 687 | Ordered Subgraph Aggregation Networks | 7.00 | | Accept
|
| 688 | Distilling Representations from GAN Generator via Squeeze and Span | 5.33 | | Accept
|
| 689 | Provably expressive temporal graph networks | 6.75 | | Accept
|
| 690 | Exploitability Minimization in Games and Beyond | 5.75 | | Accept
|
| 691 | Black-box coreset variational inference | 5.67 | | Accept
|
| 692 | Policy Optimization with Linear Temporal Logic Constraints | 6.67 | | Accept
|
| 693 | An Analytical Theory of Curriculum Learning in Teacher-Student Networks | 5.67 | | Accept
|
| 694 | Smoothed Embeddings for Certified Few-Shot Learning | 6.25 | | Accept
|
| 695 | When to Intervene: Learning Optimal Intervention Policies for Critical Events | 5.75 | | Accept
|
| 696 | Sparse Probabilistic Circuits via Pruning and Growing | 7.75 | | Accept
|
| 697 | On the relationship between variational inference and auto-associative memory | 4.50 | | Accept
|
| 698 | Neural network architecture beyond width and depth | 5.67 | | Accept
|
| 699 | Learning interacting dynamical systems with latent Gaussian process ODEs | 6.50 | | Accept
|
| 700 | Selective compression learning of latent representations for variable-rate image compression | 5.00 | | Accept
|
| 701 | Bring Your Own Algorithm for Optimal Differentially Private Stochastic Minimax Optimization | 6.25 | | Accept
|
| 702 | Zero-Sum Stochastic Stackelberg Games | 6.00 | | Accept
|
| 703 | Learnable Graph Convolutional Attention Networks | 5.00 | | Reject
|
| 704 | The Hessian Screening Rule | 5.25 | | Accept
|
| 705 | A gradient estimator via L1-randomization for online zero-order optimization with two point feedback | 6.67 | | Accept
|
| 706 | Shielding Federated Learning: Aligned Dual Gradient Pruning Against Gradient Leakage | 4.50 | | Reject
|
| 707 | Expected Improvement for Contextual Bandits | 6.50 | | Accept
|
| 708 | Dynamics of SGD with Stochastic Polyak Stepsizes: Truly Adaptive Variants and Convergence to Exact Solution | 6.00 | | Accept
|
| 709 | Collaborative Decision Making Using Action Suggestions | 6.00 | | Accept
|
| 710 | BinauralGrad: A Two-Stage Conditional Diffusion Probabilistic Model for Binaural Audio Synthesis | 6.67 | | Accept
|
| 711 | MAtt: A Manifold Attention Network for EEG Decoding | 6.00 | | Accept
|
| 712 | Feature Learning in $L_2$-regularized DNNs: Attraction/Repulsion and Sparsity | 5.67 | | Accept
|
| 713 | Revisiting Active Sets for Gaussian Process Decoders | 5.67 | | Accept
|
| 714 | Matching in Multi-arm Bandit with Collision | 4.60 | | Accept
|
| 715 | Optimistic Posterior Sampling for Reinforcement Learning with Few Samples and Tight Guarantees | 6.00 | | Accept
|
| 716 | Measuring Data Reconstruction Defenses in Collaborative Inference Systems | 5.33 | | Accept
|
| 717 | Memory Efficient Continual Learning with Transformers | 5.67 | | Accept
|
| 718 | Oracle Inequalities for Model Selection in Offline Reinforcement Learning | 4.67 | | Accept
|
| 719 | Laplacian Autoencoders for Learning Stochastic Representations | 6.67 | | Accept
|
| 720 | Assistive Teaching of Motor Control Tasks to Humans | 5.75 | | Accept
|
| 721 | Sound and Complete Verification of Polynomial Networks | 6.33 | | Accept
|
| 722 | Multiagent Q-learning with Sub-Team Coordination | 5.75 | | Accept
|
| 723 | Relational Reasoning via Set Transformers: Provable Efficiency and Applications to MARL | 5.67 | | Accept
|
| 724 | HyperDomainNet: Universal Domain Adaptation for Generative Adversarial Networks | 5.67 | | Accept
|
| 725 | Challenging Common Assumptions in Convex Reinforcement Learning | 6.50 | | Accept
|
| 726 | Neural-Symbolic Entangled Framework for Complex Query Answering | 6.33 | | Accept
|
| 727 | Near Instance-Optimal PAC Reinforcement Learning for Deterministic MDPs | 6.25 | | Accept
|
| 728 | S2P: State-conditioned Image Synthesis for Data Augmentation in Offline Reinforcement Learning | 6.00 | | Accept
|
| 729 | A Differentially Private Linear-Time fPTAS for the Minimum Enclosing Ball Problem | 6.75 | | Accept
|
| 730 | Debiased Causal Tree: Heterogeneous Treatment Effects Estimation with Unmeasured Confounding | 6.67 | | Accept
|
| 731 | Optimal Positive Generation via Latent Transformation for Contrastive Learning | 5.50 | | Accept
|
| 732 | AnoFormer: Time Series Anomaly Detection using Transformer-based GAN with Two-Step Masking | 4.00 | | Reject
|
| 733 | A Simple Contrastive Learning Objective for Alleviating Neural Text Degeneration | 4.33 | | Reject
|
| 734 | Graph Coloring via Neural Networks for Haplotype Assembly and Viral Quasispecies Reconstruction | 6.00 | | Accept
|
| 735 | Theoretically Better and Numerically Faster Distributed Optimization with Smoothness-Aware Quantization Techniques | 6.50 | | Accept
|
| 736 | Joint Learning of 2D-3D Weakly Supervised Semantic Segmentation | 5.75 | | Accept
|
| 737 | Off-Policy Evaluation with Deficient Support Using Side Information | 5.75 | | Accept
|
| 738 | Random Rank: The One and Only Strategyproof and Proportionally Fair Randomized Facility Location Mechanism | 5.75 | | Accept
|
| 739 | Measuring and Reducing Model Update Regression in Structured Prediction for NLP | 6.25 | | Accept
|
| 740 | Non-Monotonic Latent Alignments for CTC-Based Non-Autoregressive Machine Translation | 6.33 | | Accept
|
| 741 | Focal Modulation Networks | 6.25 | | Accept
|
| 742 | Expansion and Shrinkage of Localization for Weakly-Supervised Semantic Segmentation | 6.33 | | Accept
|
| 743 | Measures of Information Reflect Memorization Patterns | 5.25 | | Accept
|
| 744 | Clipped Stochastic Methods for Variational Inequalities with Heavy-Tailed Noise | 6.33 | | Accept
|
| 745 | Where do Models go Wrong? Parameter-Space Saliency Maps for Explainability | 6.75 | | Accept
|
| 746 | Reinforcement Learning with Neural Radiance Fields | 6.00 | | Accept
|
| 747 | Unlabelled Sample Compression Schemes for Intersection-Closed Classes and Extremal Classes | 6.25 | | Accept
|
| 748 | Structuring Uncertainty for Fine-Grained Sampling in Stochastic Segmentation Networks | 6.67 | | Accept
|
| 749 | Revisit last-iterate convergence of mSGD under milder requirement on step size | 6.40 | | Accept
|
| 750 | Graph Convolution Network based Recommender Systems: Learning Guarantee and Item Mixture Powered Strategy | 6.33 | | Accept
|
| 751 | Multi-agent Performative Prediction with Greedy Deployment and Consensus Seeking Agents | 5.25 | | Accept
|
| 752 | Last-Iterate Convergence of Optimistic Gradient Method for Monotone Variational Inequalities | 5.67 | | Accept
|
| 753 | Collaborative Learning by Detecting Collaboration Partners | 5.75 | | Accept
|
| 754 | A Stochastic Linearized Augmented Lagrangian Method for Decentralized Bilevel Optimization | 6.50 | | Accept
|
| 755 | Kernel Memory Networks: A Unifying Framework for Memory Modeling | 6.00 | | Accept
|
| 756 | Batch Bayesian optimisation via density-ratio estimation with guarantees | 5.50 | | Accept
|
| 757 | Towards Consistency in Adversarial Classification | 7.33 | | Accept
|
| 758 | Revisiting Neural Scaling Laws in Language and Vision | 6.67 | | Accept
|
| 759 | Asynchronous SGD Beats Minibatch SGD Under Arbitrary Delays | 6.00 | | Accept
|
| 760 | MetricFormer: A Unified Perspective of Correlation Exploring in Similarity Learning | 6.25 | | Accept
|
| 761 | A Reduction to Binary Approach for Debiasing Multiclass Datasets | 5.20 | | Accept
|
| 762 | Chromatic Correlation Clustering, Revisited | 6.00 | | Accept
|
| 763 | DeVRF: Fast Deformable Voxel Radiance Fields for Dynamic Scenes | 5.33 | | Accept
|
| 764 | Learning Deep Input-Output Stable Dynamics | 5.67 | | Accept
|
| 765 | A Neural Pre-Conditioning Active Learning Algorithm to Reduce Label Complexity | 4.75 | | Accept
|
| 766 | Inducing Equilibria via Incentives: Simultaneous Design-and-Play Ensures Global Convergence | 6.00 | | Accept
|
| 767 | Bridging Implicit and Explicit Geometric Transformations for Single-Image View Synthesis | 6.25 | | Reject
|
| 768 | Combinatorial Bandits with Linear Constraints: Beyond Knapsacks and Fairness | 6.75 | | Accept
|
| 769 | Unifying and Boosting Gradient-Based Training-Free Neural Architecture Search | 6.50 | | Accept
|
| 770 | Palm up: Playing in the Latent Manifold for Unsupervised Pretraining | 5.75 | | Accept
|
| 771 | SCINet: Time Series Modeling and Forecasting with Sample Convolution and Interaction | 5.25 | | Accept
|
| 772 | CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning | 6.25 | | Accept
|
| 773 | Flexible Diffusion Modeling of Long Videos | 5.00 | | Accept
|
| 774 | WT-MVSNet: Window-based Transformers for Multi-view Stereo | 6.50 | | Accept
|
| 775 | Concentration of Data Encoding in Parameterized Quantum Circuits | 7.00 | | Accept
|
| 776 | Label Noise in Adversarial Training: A Novel Perspective to Study Robust Overfitting | 6.00 | | Accept
|
| 777 | Learning Structure from the Ground up---Hierarchical Representation Learning by Chunking | 6.50 | | Accept
|
| 778 | 360-MLC: Multi-view Layout Consistency for Self-training and Hyper-parameter Tuning | 6.00 | | Accept
|
| 779 | How Mask Matters: Towards Theoretical Understandings of Masked Autoencoders | 5.25 | | Accept
|
| 780 | Prune and distill: similar reformatting of image information along rat visual cortex and deep neural networks | 6.25 | | Accept
|
| 781 | Meta-Complementing the Semantics of Short Texts in Neural Topic Models | 6.25 | | Accept
|
| 782 | Towards Improving Calibration in Object Detection Under Domain Shift | 6.25 | | Accept
|
| 783 | Injecting Domain Knowledge from Empirical Interatomic Potentials to Neural Networks for Predicting Material Properties | 6.00 | | Accept
|
| 784 | Experimental Design for Linear Functionals in Reproducing Kernel Hilbert Spaces | 7.67 | | Accept
|
| 785 | GAL: Gradient Assisted Learning for Decentralized Multi-Organization Collaborations | 6.00 | | Accept
|
| 786 | Risk Bounds of Multi-Pass SGD for Least Squares in the Interpolation Regime | 6.50 | | Accept
|
| 787 | Imbalance Trouble: Revisiting Neural-Collapse Geometry | 6.80 | | Accept
|
| 788 | An Adaptive Deep RL Method for Non-Stationary Environments with Piecewise Stable Context | 5.00 | | Accept
|
| 789 | Text-Adaptive Multiple Visual Prototype Matching for Video-Text Retrieval | 5.75 | | Accept
|
| 790 | Active Learning with Neural Networks: Insights from Nonparametric Statistics | 6.50 | | Accept
|
| 791 | A Rotated Hyperbolic Wrapped Normal Distribution for Hierarchical Representation Learning | 6.00 | | Accept
|
| 792 | Max-Min Off-Policy Actor-Critic Method Focusing on Worst-Case Robustness to Model Misspecification | 5.25 | | Accept
|
| 793 | An In-depth Study of Stochastic Backpropagation | 6.50 | | Accept
|
| 794 | FlowHMM: Flow-based continuous hidden Markov models | 6.20 | | Accept
|
| 795 | Lazy and Fast Greedy MAP Inference for Determinantal Point Process | 5.50 | | Accept
|
| 796 | Coresets for Wasserstein Distributionally Robust Optimization Problems | 6.25 | | Accept
|
| 797 | LBD: Decouple Relevance and Observation for Individual-Level Unbiased Learning to Rank | 5.50 | | Accept
|
| 798 | Robust Feature-Level Adversaries are Interpretability Tools | 6.25 | | Accept
|
| 799 | Capturing Failures of Large Language Models via Human Cognitive Biases | 6.20 | | Accept
|
| 800 | Coresets for Relational Data and The Applications | 6.75 | | Accept
|
| 801 | Contrastive Language-Image Pre-Training with Knowledge Graphs | 6.00 | | Accept
|
| 802 | A time-resolved theory of information encoding in recurrent neural networks | 5.50 | | Accept
|
| 803 | Towards Understanding the Mixture-of-Experts Layer in Deep Learning | 5.75 | | Accept
|
| 804 | Knowledge-Aware Bayesian Deep Topic Model | 5.33 | | Accept
|
| 805 | Near-Optimal Goal-Oriented Reinforcement Learning in Non-Stationary Environments | 6.67 | | Accept
|
| 806 | Deciding What to Model: Value-Equivalent Sampling for Reinforcement Learning | 5.50 | | Accept
|
| 807 | Dynamic Learning in Large Matching Markets | 6.00 | | Accept
|
| 808 | Redundant representations help generalization in wide neural networks | 6.00 | | Accept
|
| 809 | Single Loop Gaussian Homotopy Method for Non-convex Optimization | 6.00 | | Accept
|
| 810 | MEMO: Test Time Robustness via Adaptation and Augmentation | 6.25 | | Accept
|
| 811 | How Powerful are K-hop Message Passing Graph Neural Networks | 4.50 | | Accept
|
| 812 | Private Set Generation with Discriminative Information | 6.67 | | Accept
|
| 813 | Shape, Light, and Material Decomposition from Images using Monte Carlo Rendering and Denoising | 6.25 | | Accept
|
| 814 | Grounded Reinforcement Learning: Learning to Win the Game under Human Commands | 5.80 | | Accept
|
| 815 | Spherization Layer: Representation Using Only Angles | 6.50 | | Accept
|
| 816 | When to Ask for Help: Proactive Interventions in Autonomous Reinforcement Learning | 6.33 | | Accept
|
| 817 | Learning in Observable POMDPs, without Computationally Intractable Oracles | 7.00 | | Accept
|
| 818 | Geodesic Graph Neural Network for Efficient Graph Representation Learning | 6.67 | | Accept
|
| 819 | Symmetry-induced Disentanglement on Graphs | 6.75 | | Accept
|
| 820 | DARE: Disentanglement-Augmented Rationale Extraction | 5.25 | | Accept
|
| 821 | Tractable Optimality in Episodic Latent MABs | 6.00 | | Accept
|
| 822 | Empirical Phase Diagram for Three-layer Neural Networks with Infinite Width | 5.67 | | Accept
|
| 823 | Unsupervised Point Cloud Completion and Segmentation by Generative Adversarial Autoencoding Network | 5.67 | | Accept
|
| 824 | Concrete Score Matching: Generalized Score Matching for Discrete Data | 6.33 | | Accept
|
| 825 | Improving Diffusion Models for Inverse Problems using Manifold Constraints | 6.60 | | Accept
|
| 826 | MGNNI: Multiscale Graph Neural Networks with Implicit Layers | 6.50 | | Accept
|
| 827 | DHRL: A Graph-Based Approach for Long-Horizon and Sparse Hierarchical Reinforcement Learning | 7.00 | | Accept
|
| 828 | Making Look-Ahead Active Learning Strategies Feasible with Neural Tangent Kernels | 5.75 | | Accept
|
| 829 | Bridging the Gap from Asymmetry Tricks to Decorrelation Principles in Non-contrastive Self-supervised Learning | 5.00 | | Accept
|
| 830 | So3krates: Equivariant attention for interactions on arbitrary length-scales in molecular systems | 6.67 | | Accept
|
| 831 | Meta-Query-Net: Resolving Purity-Informativeness Dilemma in Open-set Active Learning | 6.25 | | Accept
|
| 832 | On Elimination Strategies for Bandit Fixed-Confidence Identification | 5.50 | | Accept
|
| 833 | Influencing Long-Term Behavior in Multiagent Reinforcement Learning | 5.50 | | Accept
|
| 834 | When Does Group Invariant Learning Survive Spurious Correlations? | 6.00 | | Accept
|
| 835 | Maximum Likelihood Training of Implicit Nonlinear Diffusion Model | 6.25 | | Accept
|
| 836 | Personalized Online Federated Learning with Multiple Kernels | 4.75 | | Accept
|
| 837 | Patching open-vocabulary models by interpolating weights | 4.67 | | Accept
|
| 838 | Evaluating Graph Generative Models with Contrastively Learned Features | 6.00 | | Accept
|
| 839 | Differentially Private Learning Needs Hidden State (Or Much Faster Convergence) | 6.50 | | Accept
|
| 840 | Mind Reader: Reconstructing complex images from brain activities | 6.00 | | Accept
|
| 841 | Adapting to Online Label Shift with Provable Guarantees | 6.67 | | Accept
|
| 842 | Data-Driven Model-Based Optimization via Invariant Representation Learning | 5.80 | | Accept
|
| 843 | Atlas: Universal Function Approximator For Memory Retention | 3.67 | | Reject
|
| 844 | Provably Feedback-Efficient Reinforcement Learning via Active Reward Learning | 6.50 | | Accept
|
| 845 | Sharp Analysis of Stochastic Optimization under Global Kurdyka-Lojasiewicz Inequality | 5.50 | | Accept
|
| 846 | GALOIS: Boosting Deep Reinforcement Learning via Generalizable Logic Synthesis | 6.00 | | Accept
|
| 847 | What Can Transformers Learn In-Context? A Case Study of Simple Function Classes | 7.25 | | Accept
|
| 848 | A Scalable Deterministic Global Optimization Algorithm for Training Optimal Decision Tree | 5.50 | | Accept
|
| 849 | Understanding Square Loss in Training Overparametrized Neural Network Classifiers | 6.00 | | Accept
|
| 850 | Additive MIL: Intrinsically Interpretable Multiple Instance Learning for Pathology | 7.00 | | Accept
|
| 851 | Undersampling is a Minimax Optimal Robustness Intervention in Nonparametric Classification | 7.67 | | Reject
|
| 852 | Minimax Optimal Fixed-Budget Best Arm Identification in Linear Bandits | 6.25 | | Accept
|
| 853 | Learning with little mixing | 5.50 | | Accept
|
| 854 | Explaining Graph Neural Networks with Structure-Aware Cooperative Games | 6.33 | | Accept
|
| 855 | Global Optimal K-Medoids Clustering of One Million Samples | 6.00 | | Accept
|
| 856 | Quantum Algorithms for Sampling Log-Concave Distributions and Estimating Normalizing Constants | 4.67 | | Accept
|
| 857 | Nearly Optimal Best-of-Both-Worlds Algorithms for Online Learning with Feedback Graphs | 7.25 | | Accept
|
| 858 | Identification, Amplification and Measurement: A bridge to Gaussian Differential Privacy | 6.00 | | Accept
|
| 859 | High-dimensional Asymptotics of Feature Learning: How One Gradient Step Improves the Representation | 7.33 | | Accept
|
| 860 | On Leave-One-Out Conditional Mutual Information For Generalization | 6.50 | | Accept
|
| 861 | Computationally Efficient Horizon-Free Reinforcement Learning for Linear Mixture MDPs | 6.75 | | Accept
|
| 862 | Infinite Recommendation Networks: A Data-Centric Approach | 5.50 | | Accept
|
| 863 | Giving Feedback on Interactive Student Programs with Meta-Exploration | 7.33 | | Accept
|
| 864 | Quantum Speedups of Optimizing Approximately Convex Functions with Applications to Logarithmic Regret Stochastic Convex Bandits | 6.25 | | Accept
|
| 865 | A Consolidated Cross-Validation Algorithm for Support Vector Machines via Data Reduction | 6.25 | | Accept
|
| 866 | Losses Can Be Blessings: Routing Self-Supervised Speech Representations Towards Efficient Multilingual and Multitask Speech Processing | 6.33 | | Accept
|
| 867 | Understanding the Evolution of Linear Regions in Deep Reinforcement Learning | 5.25 | | Accept
|
| 868 | What's the Harm? Sharp Bounds on the Fraction Negatively Affected by Treatment | 6.00 | | Accept
|
| 869 | Active Learning Helps Pretrained Models Learn the Intended Task | 5.33 | | Accept
|
| 870 | Improving Certified Robustness via Statistical Learning with Logical Reasoning | 6.25 | | Accept
|
| 871 | Truly Deterministic Policy Optimization | 6.33 | | Accept
|
| 872 | DiSC: Differential Spectral Clustering of Features | 5.75 | | Accept
|
| 873 | DASCO: Dual-Generator Adversarial Support Constrained Offline Reinforcement Learning | 6.00 | | Accept
|
| 874 | Bag of Tricks for FGSM Adversarial Training | 5.00 | | Reject
|
| 875 | FourierNets enable the design of highly non-local optical encoders for computational imaging | 6.67 | | Accept
|
| 876 | Provable Subspace Identification Under Post-Nonlinear Mixtures | 6.50 | | Accept
|
| 877 | You Can’t Count on Luck: Why Decision Transformers and RvS Fail in Stochastic Environments | 6.00 | | Accept
|
| 878 | Sample Constrained Treatment Effect Estimation | 6.33 | | Accept
|
| 879 | Online Decision Mediation | 6.00 | | Accept
|
| 880 | Two-layer neural network on infinite dimensional data: global optimization guarantee in the mean-field regime | 6.67 | | Accept
|
| 881 | Unsupervised Learning under Latent Label Shift | 6.50 | | Accept
|
| 882 | No Free Lunch from Deep Learning in Neuroscience: A Case Study through Models of the Entorhinal-Hippocampal Circuit | 6.75 | | Accept
|
| 883 | Are all Frames Equal? Active Sparse Labeling for Video Action Detection | 5.50 | | Accept
|
| 884 | Tractable Function-Space Variational Inference in Bayesian Neural Networks | 5.75 | | Accept
|
| 885 | Transform Once: Efficient Operator Learning in Frequency Domain | 6.00 | | Accept
|
| 886 | Reinforcement Learning with Automated Auxiliary Loss Search | 6.67 | | Accept
|
| 887 | Zero-shot Transfer Learning within a Heterogeneous Graph via Knowledge Transfer Networks | 6.75 | | Accept
|
| 888 | Uncertainty Estimation for Multi-view Data: The Power of Seeing the Whole Picture | 5.67 | | Accept
|
| 889 | Sub-exponential time Sum-of-Squares lower bounds for Principal Components Analysis | 6.60 | | Accept
|
| 890 | Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination | 6.25 | | Accept
|
| 891 | Nearly-Tight Bounds for Testing Histogram Distributions | 7.25 | | Accept
|
| 892 | Conditional Diffusion Process for Inverse Halftoning | 4.75 | | Accept
|
| 893 | Analyzing Lottery Ticket Hypothesis from PAC-Bayesian Theory Perspective | 6.25 | | Accept
|
| 894 | ISAAC Newton: Input-based Approximate Curvature for Newton's Method | 5.50 | | Reject
|
| 895 | Self-Similarity Priors: Neural Collages as Differentiable Fractal Representations | 5.33 | | Accept
|
| 896 | PlasticityNet: Learning to Simulate Metal, Sand, and Snow for Optimization Time Integration | 6.75 | | Accept
|
| 897 | Long-Form Video-Language Pre-Training with Multimodal Temporal Contrastive Learning | 5.25 | | Accept
|
| 898 | Deep Differentiable Logic Gate Networks | 6.25 | | Accept
|
| 899 | SemiFL: Semi-Supervised Federated Learning for Unlabeled Clients with Alternate Training | 4.00 | | Accept
|
| 900 | Non-Stationary Bandits under Recharging Payoffs: Improved Planning with Sublinear Regret | 6.67 | | Accept
|
| 901 | Extreme Compression for Pre-trained Transformers Made Simple and Efficient | 6.25 | | Accept
|
| 902 | Meta-Auto-Decoder for Solving Parametric Partial Differential Equations | 6.00 | | Accept
|
| 903 | Maximum-Likelihood Inverse Reinforcement Learning with Finite-Time Guarantees | 5.50 | | Accept
|
| 904 | CoNSoLe: Convex Neural Symbolic Learning | 6.25 | | Accept
|
| 905 | Understanding and Improving Robustness of Vision Transformers through Patch-based Negative Augmentation | 6.00 | | Accept
|
| 906 | Scalable Distributional Robustness in a Class of Non-Convex Optimization with Guarantees | 6.75 | | Accept
|
| 907 | Finding and Listing Front-door Adjustment Sets | 7.00 | | Accept
|
| 908 | Retaining Knowledge for Learning with Dynamic Definition | 6.25 | | Accept
|
| 909 | Transferring Pre-trained Multimodal Representations with Cross-modal Similarity Matching | 5.20 | | Accept
|
| 910 | Gaussian Copula Embeddings | 6.33 | | Accept
|
| 911 | On the Complexity of Adversarial Decision Making | 6.67 | | Accept
|
| 912 | Exploiting the Relationship Between Kendall's Rank Correlation and Cosine Similarity for Attribution Protection | 7.00 | | Accept
|
| 913 | M2N: Mesh Movement Networks for PDE Solvers | 5.25 | | Accept
|
| 914 | Hierarchical Lattice Layer for Partially Monotone Neural Networks | 7.00 | | Accept
|
| 915 | Emergence of Hierarchical Layers in a Single Sheet of Self-Organizing Spiking Neurons | 6.50 | | Accept
|
| 916 | Skills Regularized Task Decomposition for Multi-task Offline Reinforcement Learning | 7.00 | | Accept
|
| 917 | Masked Autoencoding for Scalable and Generalizable Decision Making | 7.33 | | Accept
|
| 918 | Information-Theoretic Analysis of Unsupervised Domain Adaptation | 4.50 | | Reject
|
| 919 | STNDT: Modeling Neural Population Activity with Spatiotemporal Transformers | 5.33 | | Accept
|
| 920 | Understanding Cross-Domain Few-Shot Learning Based on Domain Similarity and Few-Shot Difficulty | 4.67 | | Accept
|
| 921 | ALMA: Hierarchical Learning for Composite Multi-Agent Tasks | 6.00 | | Accept
|
| 922 | Foreseeing Privacy Threats from Gradient Inversion Through the Lens of Angular Lipschitz Smoothness | 3.50 | | Reject
|
| 923 | Graph Reordering for Cache-Efficient Near Neighbor Search | 6.33 | | Accept
|
| 924 | Integral Probability Metrics PAC-Bayes Bounds | 6.50 | | Accept
|
| 925 | Human-AI Collaborative Bayesian Optimisation | 6.00 | | Accept
|
| 926 | Constrained Stochastic Nonconvex Optimization with State-dependent Markov Data | 5.25 | | Accept
|
| 927 | Double Bubble, Toil and Trouble: Enhancing Certified Robustness through Transitivity | 6.00 | | Accept
|
| 928 | Deep Surrogate Assisted Generation of Environments | 5.25 | | Accept
|
| 929 | Batch Multi-Fidelity Active Learning with Budget Constraints | 6.25 | | Accept
|
| 930 | Time-Conditioned Dances with Simplicial Complexes: Zigzag Filtration Curve based Supra-Hodge Convolution Networks for Time-series Forecasting | 6.00 | | Accept
|
| 931 | Theoretical analysis of deep neural networks for temporally dependent observations | 5.00 | | Accept
|
| 932 | Federated Hypergradient Descent | 5.33 | | Reject
|
| 933 | Learning to Mitigate AI Collusion on Economic Platforms | 5.50 | | Accept
|
| 934 | A Unified Analysis of Federated Learning with Arbitrary Client Participation | 7.00 | | Accept
|
| 935 | Iterative Feature Matching: Toward Provable Domain Generalization with Logarithmic Environments | 5.33 | | Accept
|
| 936 | Training with More Confidence: Mitigating Injected and Natural Backdoors During Training | 6.00 | | Accept
|
| 937 | Why Robust Generalization in Deep Learning is Difficult: Perspective of Expressive Power | 6.67 | | Accept
|
| 938 | Few-shot Task-agnostic Neural Architecture Search for Distilling Large Language Models | 6.00 | | Accept
|
| 939 | “Why Not Other Classes?”: Towards Class-Contrastive Back-Propagation Explanations | 5.33 | | Accept
|
| 940 | PAC: Assisted Value Factorization with Counterfactual Predictions in Multi-Agent Reinforcement Learning | 5.00 | | Accept
|
| 941 | Learning Fractional White Noises in Neural Stochastic Differential Equations | 5.80 | | Accept
|
| 942 | On the Epistemic Limits of Personalized Prediction | 5.00 | | Accept
|
| 943 | Deep Learning: When Conventional Wisdom Fails to be Wise | 2.25 | | Reject
|
| 944 | Meta-DMoE: Adapting to Domain Shift by Meta-Distillation from Mixture-of-Experts | 6.00 | | Accept
|
| 945 | Few-shot Relational Reasoning via Connection Subgraph Pretraining | 6.67 | | Accept
|
| 946 | Associating Objects and Their Effects in Video through Coordination Games | 6.00 | | Accept
|
| 947 | Provably Efficient Model-Free Constrained RL with Linear Function Approximation | 6.50 | | Accept
|
| 948 | Get More at Once: Alternating Sparse Training with Gradient Correction | 5.00 | | Accept
|
| 949 | Consistent Interpolating Ensembles via the Manifold-Hilbert Kernel | 6.25 | | Accept
|
| 950 | Learning Symmetric Rules with SATNet | 7.00 | | Accept
|
| 951 | Off-Policy Evaluation for Episodic Partially Observable Markov Decision Processes under Non-Parametric Models | 6.67 | | Accept
|
| 952 | A simple but strong baseline for online continual learning: Repeated Augmented Rehearsal | 6.25 | | Accept
|
| 953 | Causal Discovery in Linear Latent Variable Models Subject to Measurement Error | 6.67 | | Accept
|
| 954 | Maximum-Likelihood Quantum State Tomography by Soft-Bayes | 4.00 | | Reject
|
| 955 | Finite-Time Regret of Thompson Sampling Algorithms for Exponential Family Multi-Armed Bandits | 6.00 | | Accept
|
| 956 | PAC-Bayes Compression Bounds So Tight That They Can Explain Generalization | 5.25 | | Accept
|
| 957 | Fault-Aware Neural Code Rankers | 6.67 | | Accept
|
| 958 | Accelerated Training of Physics-Informed Neural Networks (PINNs) using Meshless Discretizations | 6.33 | | Accept
|
| 959 | On the Frequency-bias of Coordinate-MLPs | 6.00 | | Accept
|
| 960 | Geodesic Self-Attention for 3D Point Clouds | 5.33 | | Accept
|
| 961 | Point Transformer V2: Grouped Vector Attention and Partition-based Pooling | 5.25 | | Accept
|
| 962 | A Simple Approach to Automated Spectral Clustering | 6.50 | | Accept
|
| 963 | Exploring the Limits of Domain-Adaptive Training for Detoxifying Large-Scale Language Models | 6.25 | | Accept
|
| 964 | A Variational Edge Partition Model for Supervised Graph Representation Learning | 6.75 | | Accept
|
| 965 | Sparsity in Continuous-Depth Neural Networks | 6.25 | | Accept
|
| 966 | Invariant and Transportable Representations for Anti-Causal Domain Shifts | 6.33 | | Accept
|
| 967 | Transition to Linearity of General Neural Networks with Directed Acyclic Graph Architecture | 4.75 | | Accept
|
| 968 | Self-Supervised Pretraining for Large-Scale Point Clouds | 6.00 | | Accept
|
| 969 | Cooperative Distribution Alignment via JSD Upper Bound | 5.50 | | Accept
|
| 970 | Diffusion-LM Improves Controllable Text Generation | 7.00 | | Accept
|
| 971 | The Stability-Efficiency Dilemma: Investigating Sequence Length Warmup for Training GPT Models | 6.25 | | Accept
|
| 972 | Mixture-of-Experts with Expert Choice Routing | 6.75 | | Accept
|
| 973 | Sampling in Constrained Domains with Orthogonal-Space Variational Gradient Descent | 6.00 | | Accept
|
| 974 | Precise Learning Curves and Higher-Order Scalings for Dot-product Kernel Regression | 6.20 | | Accept
|
| 975 | Is Sortition Both Representative and Fair? | 6.67 | | Accept
|
| 976 | SoftPatch: Unsupervised Anomaly Detection with Noisy Data | 5.50 | | Accept
|
| 977 | Identifying good directions to escape the NTK regime and efficiently learn low-degree plus sparse polynomials | 6.00 | | Accept
|
| 978 | Weighted Distillation with Unlabeled Examples | 5.25 | | Accept
|
| 979 | SemMAE: Semantic-Guided Masking for Learning Masked Autoencoders | 5.67 | | Accept
|
| 980 | Counterfactual Neural Temporal Point Process for Estimating Causal Influence of Misinformation on Social Media | 5.33 | | Accept
|
| 981 | Compositional Generalization in Unsupervised Compositional Representation Learning: A Study on Disentanglement and Emergent Language | 6.25 | | Accept
|
| 982 | Redundancy-Free Message Passing for Graph Neural Networks | 6.25 | | Accept
|
| 983 | Few-Shot Audio-Visual Learning of Environment Acoustics | 6.75 | | Accept
|
| 984 | Incrementality Bidding via Reinforcement Learning under Mixed and Delayed Rewards | 6.75 | | Accept
|
| 985 | Implicit Bias of Gradient Descent on Reparametrized Models: On Equivalence to Mirror Descent | 6.33 | | Accept
|
| 986 | Provably Efficient Offline Multi-agent Reinforcement Learning via Strategy-wise Bonus | 5.67 | | Accept
|
| 987 | Understanding the Generalization Benefit of Normalization Layers: Sharpness Reduction | 6.40 | | Accept
|
| 988 | Tree Mover's Distance: Bridging Graph Metrics and Stability of Graph Neural Networks | 6.00 | | Accept
|
| 989 | Quantifying Statistical Significance of Neural Network-based Image Segmentation by Selective Inference | 5.67 | | Accept
|
| 990 | Adam Can Converge Without Any Modification On Update Rules | 6.00 | | Accept
|
| 991 | When are Offline Two-Player Zero-Sum Markov Games Solvable? | 7.00 | | Accept
|
| 992 | Optimal Neural Network Approximations of Wasserstein Gradient Direction via Convex Optimization | 5.50 | | Reject
|
| 993 | Federated Learning from Pre-Trained Models: A Contrastive Learning Approach | 5.75 | | Accept
|
| 994 | Lower Bounds and Nearly Optimal Algorithms in Distributed Learning with Communication Compression | 7.00 | | Accept
|
| 995 | Left Heavy Tails and the Effectiveness of the Policy and Value Networks in DNN-based best-first search for Sokoban Planning | 7.00 | | Accept
|
| 996 | Learning Generalizable Models for Vehicle Routing Problems via Knowledge Distillation | 5.75 | | Accept
|
| 997 | Online Algorithms for the Santa Claus Problem | 6.00 | | Accept
|
| 998 | Invariance Learning based on Label Hierarchy | 5.50 | | Accept
|
| 999 | Segmenting Moving Objects via an Object-Centric Layered Representation | 5.50 | | Accept
|
| 1000 | Efficient Multi-agent Communication via Self-supervised Information Aggregation | 6.33 | | Accept
|
| 1001 | Global Convergence of Federated Learning for Mixed Regression | 6.33 | | Accept
|
| 1002 | Decentralized, Communication- and Coordination-free Learning in Structured Matching Markets | 6.50 | | Accept
|
| 1003 | Robust On-Policy Sampling for Data-Efficient Policy Evaluation in Reinforcement Learning | 6.00 | | Accept
|
| 1004 | Dual-Curriculum Contrastive Multi-Instance Learning for Cancer Prognosis Analysis with Whole Slide Images | 6.67 | | Accept
|
| 1005 | A Theory of PAC Learnability under Transformation Invariances | 7.33 | | Accept
|
| 1006 | Private Graph All-Pairwise-Shortest-Path Distance Release with Improved Error Rate | 6.50 | | Accept
|
| 1007 | Why So Pessimistic? Estimating Uncertainties for Offline RL through Ensembles, and Why Their Independence Matters | 5.75 | | Accept
|
| 1008 | Path Independent Equilibrium Models Can Better Exploit Test-Time Computation | 5.00 | | Accept
|
| 1009 | Surprising Instabilities in Training Deep Networks and a Theoretical Analysis | 5.50 | | Accept
|
| 1010 | Beyond the Return: Off-policy Function Estimation under User-specified Error-measuring Distributions | 5.67 | | Accept
|
| 1011 | Merging Models with Fisher-Weighted Averaging | 6.00 | | Accept
|
| 1012 | Continuous Deep Q-Learning in Optimal Control Problems: Normalized Advantage Functions Analysis | 5.33 | | Accept
|
| 1013 | Distributed Distributionally Robust Optimization with Non-Convex Objectives | 5.33 | | Accept
|
| 1014 | Energy-Based Contrastive Learning of Visual Representations | 6.67 | | Accept
|
| 1015 | On the Statistical Efficiency of Reward-Free Exploration in Non-Linear RL | 5.75 | | Accept
|
| 1016 | BiMLP: Compact Binary Architectures for Vision Multi-Layer Perceptrons | 5.50 | | Accept
|
| 1017 | Multi-block Min-max Bilevel Optimization with Applications in Multi-task Deep AUC Maximization | 6.50 | | Accept
|
| 1018 | Rethinking the Reverse-engineering of Trojan Triggers | 6.25 | | Accept
|
| 1019 | Agreement-on-the-line: Predicting the Performance of Neural Networks under Distribution Shift | 7.50 | | Accept
|
| 1020 | A Statistical Online Inference Approach in Averaged Stochastic Approximation | 5.67 | | Accept
|
| 1021 | A Ranking Game for Imitation Learning | 5.80 | | Reject
|
| 1022 | Beyond Not-Forgetting: Continual Learning with Backward Knowledge Transfer | 5.00 | | Accept
|
| 1023 | Neural Conservation Laws: A Divergence-Free Perspective | 6.33 | | Accept
|
| 1024 | Sparse Hypergraph Community Detection Thresholds in Stochastic Block Model | 5.67 | | Accept
|
| 1025 | Deep Bidirectional Language-Knowledge Graph Pretraining | 6.33 | | Accept
|
| 1026 | Structure-Preserving Embedding of Multi-layer Networks | 5.33 | | Reject
|
| 1027 | An Asymptotically Optimal Batched Algorithm for the Dueling Bandit Problem | 6.00 | | Accept
|
| 1028 | Faster Deep Reinforcement Learning with Slower Online Network | 7.00 | | Accept
|
| 1029 | Old can be Gold: Better Gradient Flow can Make Vanilla-GCNs Great Again | 5.00 | | Accept
|
| 1030 | Offline Goal-Conditioned Reinforcement Learning via $f$-Advantage Regression | 7.00 | | Accept
|
| 1031 | Graph Few-shot Learning with Task-specific Structures | 5.75 | | Accept
|
| 1032 | Pre-Trained Model Reusability Evaluation for Small-Data Transfer Learning | 5.67 | | Accept
|
| 1033 | Tight Mutual Information Estimation With Contrastive Fenchel-Legendre Optimization | 6.75 | | Accept
|
| 1034 | Trade-off between Payoff and Model Rewards in Shapley-Fair Collaborative Machine Learning | 5.60 | | Accept
|
| 1035 | Minimax-Optimal Multi-Agent RL in Markov Games With a Generative Model | 7.00 | | Accept
|
| 1036 | Effects of Data Geometry in Early Deep Learning | 6.00 | | Accept
|
| 1037 | Model Preserving Compression for Neural Networks | 5.00 | | Accept
|
| 1038 | NSNet: A General Neural Probabilistic Framework for Satisfiability Problems | 5.25 | | Accept
|
| 1039 | RORL: Robust Offline Reinforcement Learning via Conservative Smoothing | 5.75 | | Accept
|
| 1040 | GraphQNTK: Quantum Neural Tangent Kernel for Graph Data | 5.33 | | Accept
|
| 1041 | Diffusion Curvature for Estimating Local Curvature in High Dimensional Data | 4.75 | | Accept
|
| 1042 | Rethinking Value Function Learning for Generalization in Reinforcement Learning | 6.00 | | Accept
|
| 1043 | LISA: Learning Interpretable Skill Abstractions from Language | 6.00 | | Accept
|
| 1044 | VF-PS: How to Select Important Participants in Vertical Federated Learning, Efficiently and Securely? | 6.33 | | Accept
|
| 1045 | Surprise-Guided Search for Learning Task Specifications From Demonstrations | 5.00 | | Reject
|
| 1046 | Outlier-Robust Sparse Mean Estimation for Heavy-Tailed Distributions | 5.00 | | Accept
|
| 1047 | Instance-Dependent Policy Learning for Linear MDPs via Online Experiment Design | 7.33 | | Accept
|
| 1048 | Explainable Spatio-Temporal Forecasting with Shape Functions | 5.67 | | Reject
|
| 1049 | On the Convergence Theory for Hessian-Free Bilevel Algorithms | 6.50 | | Accept
|
| 1050 | Asymptotic Behaviors of Projected Stochastic Approximation: A Jump Diffusion Perspective | 7.00 | | Accept
|
| 1051 | Recall Distortion in Neural Network Pruning and the Undecayed Pruning Algorithm | 6.00 | | Accept
|
| 1052 | Curriculum Reinforcement Learning using Optimal Transport via Gradual Domain Adaptation | 6.00 | | Accept
|
| 1053 | TaSIL: Taylor Series Imitation Learning | 5.50 | | Accept
|
| 1054 | A Unifying Framework of Off-Policy General Value Function Evaluation | 5.75 | | Accept
|
| 1055 | Using Embeddings for Causal Estimation of Peer Influence in Social Networks | 6.50 | | Accept
|
| 1056 | Preservation of the Global Knowledge by Not-True Distillation in Federated Learning | 5.33 | | Accept
|
| 1057 | Latent Hierarchical Causal Structure Discovery with Rank Constraints | 6.33 | | Accept
|
| 1058 | Bandit Theory and Thompson Sampling-Guided Directed Evolution for Sequence Optimization | 5.75 | | Accept
|
| 1059 | Label-invariant Augmentation for Semi-Supervised Graph Classification | 6.33 | | Accept
|
| 1060 | A Communication-Efficient Distributed Gradient Clipping Algorithm for Training Deep Neural Networks | 4.75 | | Accept
|
| 1061 | Task-Agnostic Graph Explanations | 6.25 | | Accept
|
| 1062 | Communication-Efficient Topologies for Decentralized Learning with $O(1)$ Consensus Rate | 6.00 | | Accept
|
| 1063 | Human-AI Shared Control via Policy Dissection | 5.25 | | Accept
|
| 1064 | QC-StyleGAN - Quality Controllable Image Generation and Manipulation | 5.50 | | Accept
|
| 1065 | VoiceBlock: Privacy through Real-Time Adversarial Attacks with Audio-to-Audio Models | 7.33 | | Accept
|
| 1066 | Kernel similarity matching with Hebbian networks | 6.25 | | Accept
|
| 1067 | OPEN: Orthogonal Propagation with Ego-Network Modeling | 5.33 | | Accept
|
| 1068 | Embedding game: dimensionality reduction as a two-person zero-sum game | 3.00 | | Reject
|
| 1069 | An efficient graph generative model for navigating ultra-large combinatorial synthesis libraries | 6.00 | | Accept
|
| 1070 | Your Out-of-Distribution Detection Method is Not Robust! | 5.50 | | Accept
|
| 1071 | Pruning’s Effect on Generalization Through the Lens of Training and Regularization | 6.33 | | Accept
|
| 1072 | Stacked unsupervised learning with a network architecture found by supervised meta-learning | 5.33 | | Reject
|
| 1073 | Quantile Constrained Reinforcement Learning: A Reinforcement Learning Framework Constraining Outage Probability | 6.25 | | Accept
|
| 1074 | Branch & Learn for Recursively and Iteratively Solvable Problems in Predict+Optimize | 6.00 | | Accept
|
| 1075 | Minimax Optimal Algorithms for Fixed-Budget Best Arm Identification | 6.00 | | Accept
|
| 1076 | Exposing and Exploiting Fine-Grained Block Structures for Fast and Accurate Sparse Training | 5.25 | | Accept
|
| 1077 | Model-Based Opponent Modeling | 5.00 | | Accept
|
| 1078 | A General Framework for Auditing Differentially Private Machine Learning | 6.00 | | Accept
|
| 1079 | Non-Linguistic Supervision for Contrastive Learning of Sentence Embeddings | 5.80 | | Accept
|
| 1080 | A Non-Asymptotic Moreau Envelope Theory for High-Dimensional Generalized Linear Models | 6.33 | | Accept
|
| 1081 | ACIL: Analytic Class-Incremental Learning with Absolute Memorization and Privacy Protection | 7.33 | | Accept
|
| 1082 | Co-Modality Graph Contrastive Learning for Imbalanced Node Classification | 6.00 | | Accept
|
| 1083 | Faster and Scalable Algorithms for Densest Subgraph and Decomposition | 7.00 | | Accept
|
| 1084 | In What Ways Are Deep Neural Networks Invariant and How Should We Measure This? | 6.25 | | Accept
|
| 1085 | Second Thoughts are Best: Learning to Re-Align With Human Values from Text Edits | 5.75 | | Accept
|
| 1086 | FourierFormer: Transformer Meets Generalized Fourier Integral Theorem | 6.25 | | Accept
|
| 1087 | Decision-based Black-box Attack Against Vision Transformers via Patch-wise Adversarial Removal | 5.75 | | Accept
|
| 1088 | Calibrated Data-Dependent Constraints with Exact Satisfaction Guarantees | 7.00 | | Accept
|
| 1089 | Robust Option Learning for Adversarial Generalization | 4.00 | | Reject
|
| 1090 | Efficient Dataset Distillation using Random Feature Approximation | 6.33 | | Accept
|
| 1091 | On the Symmetries of Deep Learning Models and their Internal Representations | 6.67 | | Accept
|
| 1092 | Non-identifiability and the Blessings of Misspecification in Models of Molecular Fitness | 7.50 | | Accept
|
| 1093 | On the Sample Complexity of Stabilizing LTI Systems on a Single Trajectory | 5.75 | | Accept
|
| 1094 | A Lagrangian Duality Approach to Active Learning | 6.50 | | Accept
|
| 1095 | Fast Bayesian Estimation of Point Process Intensity as Function of Covariates | 5.00 | | Accept
|
| 1096 | HUMUS-Net: Hybrid Unrolled Multi-scale Network Architecture for Accelerated MRI Reconstruction | 5.75 | | Accept
|
| 1097 | Interaction-Grounded Learning with Action-inclusive Feedback | 5.33 | | Accept
|
| 1098 | Identifiability of deep generative models without auxiliary information | 7.00 | | Accept
|
| 1099 | Dataset Distillation using Neural Feature Regression | 7.25 | | Accept
|
| 1100 | Decomposed Knowledge Distillation for Class-Incremental Semantic Segmentation | 5.33 | | Accept
|
| 1101 | On Learning Fairness and Accuracy on Multiple Subgroups | 6.75 | | Accept
|
| 1102 | Low-rank lottery tickets: finding efficient low-rank neural networks via matrix differential equations | 5.67 | | Accept
|
| 1103 | If Influence Functions are the Answer, Then What is the Question? | 6.50 | | Accept
|
| 1104 | Locally Hierarchical Auto-Regressive Modeling for Image Generation | 5.67 | | Accept
|
| 1105 | Amortized Proximal Optimization | 7.00 | | Accept
|
| 1106 | Submodular Maximization in Clean Linear Time | 6.00 | | Accept
|
| 1107 | MMC Transformer: Multiscale Multigrid Comparator Transformer for Few-Shot Video Segmentation | 4.50 | | Reject
|
| 1108 | Distributionally Adaptive Meta Reinforcement Learning | 5.50 | | Accept
|
| 1109 | Byzantine-tolerant federated Gaussian process regression for streaming data | 5.33 | | Accept
|
| 1110 | DMAP: a Distributed Morphological Attention Policy for learning to locomote with a changing body | 7.00 | | Accept
|
| 1111 | Simplified Graph Convolution with Heterophily | 4.50 | | Accept
|
| 1112 | Learning Generalized Policy Automata for Relational Stochastic Shortest Path Problems | 7.25 | | Accept
|
| 1113 | A Combinatorial Perspective on the Optimization of Shallow ReLU Networks | 5.75 | | Accept
|
| 1114 | Physics-Informed Implicit Representations of Equilibrium Network Flows | 5.50 | | Accept
|
| 1115 | Revisiting Optimal Convergence Rate for Smooth and Non-convex Stochastic Decentralized Optimization | 6.25 | | Accept
|
| 1116 | Nest Your Adaptive Algorithm for Parameter-Agnostic Nonconvex Minimax Optimization | 6.00 | | Accept
|
| 1117 | On Deep Generative Models for Approximation and Estimation of Distributions on Manifolds | 6.60 | | Accept
|
| 1118 | Online Reinforcement Learning for Mixed Policy Scopes | 6.25 | | Accept
|
| 1119 | Diversified Recommendations for Agents with Adaptive Preferences | 6.00 | | Accept
|
| 1120 | VectorAdam for Rotation Equivariant Geometry Optimization | 6.00 | | Accept
|
| 1121 | Scalable design of Error-Correcting Output Codes using Discrete Optimization with Graph Coloring | 6.67 | | Accept
|
| 1122 | Polynomial time guarantees for the Burer-Monteiro method | 7.25 | | Accept
|
| 1123 | Conformal Prediction with Temporal Quantile Adjustments | 6.50 | | Accept
|
| 1124 | Neurosymbolic Deep Generative Models for Sequence Data with Relational Constraints | 6.50 | | Accept
|
| 1125 | AdaFocal: Calibration-aware Adaptive Focal Loss | 5.25 | | Accept
|
| 1126 | SIXO: Smoothing Inference with Twisted Objectives | 8.00 | | Accept
|
| 1127 | On the Discrimination Risk of Mean Aggregation Feature Imputation in Graphs | 5.00 | | Accept
|
| 1128 | Generalizing Goal-Conditioned Reinforcement Learning with Variational Causal Reasoning | 6.00 | | Accept
|
| 1129 | Free Probability for predicting the performance of feed-forward fully connected neural networks | 6.40 | | Accept
|
| 1130 | Syndicated Bandits: A Framework for Auto Tuning Hyper-parameters in Contextual Bandit Algorithms | 6.25 | | Accept
|
| 1131 | Domain Adaptation meets Individual Fairness. And they get along. | 5.00 | | Accept
|
| 1132 | End-to-end Algorithm Synthesis with Recurrent Networks: Extrapolation without Overthinking | 6.75 | | Accept
|
| 1133 | Optimal Scaling for Locally Balanced Proposals in Discrete Spaces | 6.67 | | Accept
|
| 1134 | ZSON: Zero-Shot Object-Goal Navigation using Multimodal Goal Embeddings | 5.50 | | Accept
|
| 1135 | Training Subset Selection for Weak Supervision | 6.50 | | Accept
|
| 1136 | Fair Infinitesimal Jackknife: Mitigating the Influence of Biased Training Data Points Without Refitting | 5.67 | | Accept
|
| 1137 | Towards Understanding the Condensation of Neural Networks at Initial Training | 5.33 | | Accept
|
| 1138 | An Analysis of Ensemble Sampling | 6.25 | | Accept
|
| 1139 | Signal Propagation in Transformers: Theoretical Perspectives and the Role of Rank Collapse | 5.33 | | Accept
|
| 1140 | Beyond Separability: Analyzing the Linear Transferability of Contrastive Representations to Related Subpopulations | 5.75 | | Accept
|
| 1141 | Convergence for score-based generative modeling with polynomial complexity | 7.20 | | Accept
|
| 1142 | Locating and Editing Factual Associations in GPT | 6.00 | | Accept
|
| 1143 | Efficient and Near-Optimal Smoothed Online Learning for Generalized Linear Functions | 7.25 | | Accept
|
| 1144 | Leveraging Factored Action Spaces for Efficient Offline Reinforcement Learning in Healthcare | 6.25 | | Accept
|
| 1145 | Convergent Representations of Computer Programs in Human and Artificial Neural Networks | 5.50 | | Accept
|
| 1146 | Active Learning Polynomial Threshold Functions | 7.25 | | Accept
|
| 1147 | Toward Robust Spiking Neural Network Against Adversarial Perturbation | 6.00 | | Accept
|
| 1148 | Towards Optimal Communication Complexity in Distributed Non-Convex Optimization | 6.00 | | Accept
|
| 1149 | A Projection-free Algorithm for Constrained Stochastic Multi-level Composition Optimization | 5.00 | | Accept
|
| 1150 | Sketch-GNN: Scalable Graph Neural Networks with Sublinear Training Complexity | 6.75 | | Accept
|
| 1151 | Score-based Generative Modeling Secretly Minimizes the Wasserstein Distance | 6.50 | | Accept
|
| 1152 | VC Theoretical Explanation of Double Descent | 4.00 | | Reject
|
| 1153 | Bayesian Spline Learning for Equation Discovery of Nonlinear Dynamics with Quantified Uncertainty | 5.75 | | Accept
|
| 1154 | Few-shot Learning for Feature Selection with Hilbert-Schmidt Independence Criterion | 6.00 | | Accept
|
| 1155 | Understanding Hyperdimensional Computing for Parallel Single-Pass Learning | 7.00 | | Accept
|
| 1156 | Rapidly Mixing Multiple-try Metropolis Algorithms for Model Selection Problems | 7.00 | | Accept
|
| 1157 | Learning Options via Compression | 6.75 | | Accept
|
| 1158 | Understanding Non-linearity in Graph Neural Networks from the Bayesian-Inference Perspective | 5.33 | | Accept
|
| 1159 | Improving Self-Supervised Learning by Characterizing Idealized Representations | 6.25 | | Accept
|
| 1160 | Conformalized Fairness via Quantile Regression | 5.50 | | Accept
|
| 1161 | A Simple and Optimal Policy Design for Online Learning with Safety against Heavy-tailed Risk | 6.50 | | Accept
|
| 1162 | C2FAR: Coarse-to-Fine Autoregressive Networks for Precise Probabilistic Forecasting | 6.67 | | Accept
|
| 1163 | Chain of Thought Imitation with Procedure Cloning | 5.50 | | Accept
|
| 1164 | Hedging as Reward Augmentation in Probabilistic Graphical Models | 6.00 | | Accept
|
| 1165 | Multiview Human Body Reconstruction from Uncalibrated Cameras | 6.60 | | Accept
|
| 1166 | Layer Freezing & Data Sieving: Missing Pieces of a Generic Framework for Sparse Training | 5.50 | | Accept
|
| 1167 | Efficiently Computing Local Lipschitz Constants of Neural Networks via Bound Propagation | 5.67 | | Accept
|
| 1168 | Emergent Graphical Conventions in a Visual Communication Game | 6.50 | | Accept
|
| 1169 | Few-Shot Non-Parametric Learning with Deep Latent Variable Model | 7.33 | | Accept
|
| 1170 | Robustness in deep learning: The good (width), the bad (depth), and the ugly (initialization) | 6.33 | | Accept
|
| 1171 | Uncalibrated Models Can Improve Human-AI Collaboration | 6.00 | | Accept
|
| 1172 | $\alpha$-ReQ : Assessing {\bf Re}presentation {\bf Q}uality in Self-Supervised Learning by measuring eigenspectrum decay | 5.33 | | Accept
|
| 1173 | Maximum a posteriori natural scene reconstruction from retinal ganglion cells with deep denoiser priors | 6.33 | | Accept
|
| 1174 | Continuously Tempered PDMP samplers | 6.67 | | Accept
|
| 1175 | Generalization Gap in Amortized Inference | 6.25 | | Accept
|
| 1176 | Policy Optimization for Markov Games: Unified Framework and Faster Convergence | 6.33 | | Accept
|
| 1177 | Robust Learning against Relational Adversaries | 7.67 | | Accept
|
| 1178 | Falconn++: A Locality-sensitive Filtering Approach for Approximate Nearest Neighbor Search | 6.00 | | Accept
|
| 1179 | ShapeCrafter: A Recursive Text-Conditioned 3D Shape Generation Model | 5.33 | | Accept
|
| 1180 | Beyond black box densities: Parameter learning for the deviated components | 5.75 | | Accept
|
| 1181 | Monte Carlo Augmented Actor-Critic for Sparse Reward Deep Reinforcement Learning from Suboptimal Demonstrations | 5.50 | | Accept
|
| 1182 | Friendly Noise against Adversarial Noise: A Powerful Defense against Data Poisoning Attack | 4.75 | | Accept
|
| 1183 | Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners | 4.75 | | Accept
|
| 1184 | Dynamic Tensor Product Regression | 5.33 | | Accept
|
| 1185 | Data-Efficient Augmentation for Training Neural Networks | 6.00 | | Accept
|
| 1186 | What Can the Neural Tangent Kernel Tell Us About Adversarial Robustness? | 5.50 | | Accept
|
| 1187 | Near-Optimal Private and Scalable $k$-Clustering | 7.50 | | Accept
|
| 1188 | On Scrambling Phenomena for Randomly Initialized Recurrent Networks | 6.00 | | Accept
|
| 1189 | Meta-Learning Dynamics Forecasting Using Task Inference | 7.33 | | Accept
|
| 1190 | Optimal Dynamic Regret in LQR Control | 6.00 | | Accept
|
| 1191 | Bellman Residual Orthogonalization for Offline Reinforcement Learning | 7.00 | | Accept
|
| 1192 | Bounded-Regret MPC via Perturbation Analysis: Prediction Error, Constraints, and Nonlinearity | 6.00 | | Accept
|
| 1193 | NaturalProver: Grounded Mathematical Proof Generation with Language Models | 7.00 | | Accept
|
| 1194 | The Implicit Delta Method | 6.50 | | Accept
|
| 1195 | Globally Gated Deep Linear Networks | 7.00 | | Accept
|
| 1196 | Model-based RL with Optimistic Posterior Sampling: Structural Conditions and Sample Complexity | 6.75 | | Accept
|
| 1197 | On the Safety of Interpretable Machine Learning: A Maximum Deviation Approach | 5.33 | | Accept
|
| 1198 | Towards Safe Reinforcement Learning with a Safety Editor Policy | 6.75 | | Accept
|
| 1199 | Discrete Compositional Representations as an Abstraction for Goal Conditioned Reinforcement Learning | 6.00 | | Accept
|
| 1200 | Natural image synthesis for the retina with variational information bottleneck representation | 6.00 | | Accept
|
| 1201 | Riemannian Diffusion Models | 6.33 | | Accept
|
| 1202 | Near-Isometric Properties of Kronecker-Structured Random Tensor Embeddings | 6.33 | | Accept
|
| 1203 | Semi-supervised Active Linear Regression | 6.67 | | Accept
|
| 1204 | Adversarially Robust Learning: A Generic Minimax Optimal Learner and Characterization | 8.00 | | Accept
|
| 1205 | MACE: Higher Order Equivariant Message Passing Neural Networks for Fast and Accurate Force Fields | 7.00 | | Accept
|
| 1206 | Regret Bounds for Risk-Sensitive Reinforcement Learning | 6.50 | | Accept
|
| 1207 | Boosting Barely Robust Learners: A New Perspective on Adversarial Robustness | 5.80 | | Accept
|
| 1208 | Timing is Everything: Learning to Act Selectively with Costly Actions and Budgetary Constraints | 5.33 | | Reject
|
| 1209 | Robust Generalized Method of Moments: A Finite Sample Viewpoint | 6.25 | | Accept
|
| 1210 | Improving Intrinsic Exploration with Language Abstractions | 5.67 | | Accept
|
| 1211 | On the Global Convergence Rates of Decentralized Softmax Gradient Play in Markov Potential Games | 5.25 | | Accept
|
| 1212 | Single-phase deep learning in cortico-cortical networks | 7.50 | | Accept
|
| 1213 | Predictive Querying for Autoregressive Neural Sequence Models | 7.00 | | Accept
|
| 1214 | Composition Theorems for Interactive Differential Privacy | 5.25 | | Accept
|
| 1215 | Efficient Frameworks for Generalized Low-Rank Matrix Bandit Problems | 6.00 | | Accept
|
| 1216 | GULP: a prediction-based metric between representations | 6.50 | | Accept
|
| 1217 | Online Allocation and Learning in the Presence of Strategic Agents | 6.00 | | Accept
|
| 1218 | Reduced Representation of Deformation Fields for Effective Non-rigid Shape Matching | 5.50 | | Accept
|
| 1219 | Interpreting Operation Selection in Differentiable Architecture Search: A Perspective from Influence-Directed Explanations | 6.25 | | Accept
|
| 1220 | Learning single-index models with shallow neural networks | 7.00 | | Accept
|
| 1221 | Sequence Model Imitation Learning with Unobserved Contexts | 5.33 | | Accept
|
| 1222 | Repairing Neural Networks by Leaving the Right Past Behind | 6.00 | | Accept
|
| 1223 | Doubly-Asynchronous Value Iteration: Making Value Iteration Asynchronous in Actions | 6.67 | | Accept
|
| 1224 | Learning Two-Player Markov Games: Neural Function Approximation and Correlated Equilibrium | 6.50 | | Accept
|
| 1225 | Differentially Private Linear Sketches: Efficient Implementations and Applications | 5.25 | | Accept
|
| 1226 | On the role of overparameterization in off-policy Temporal Difference learning with linear function approximation | 6.25 | | Accept
|
| 1227 | Fast Bayesian Coresets via Subsampling and Quasi-Newton Refinement | 7.25 | | Accept
|
| 1228 | Learning Spatially-Adaptive Squeeze-Excitation Networks for Image Synthesis and Image Recognition | 4.40 | | Reject
|
| 1229 | Single-Stage Visual Relationship Learning using Conditional Queries | 5.00 | | Accept
|
| 1230 | Probable Domain Generalization via Quantile Risk Minimization | 6.00 | | Accept
|
| 1231 | Teacher Forcing Recovers Reward Functions for Text Generation | 6.50 | | Accept
|
| 1232 | Acceleration in Distributed Sparse Regression | 6.50 | | Accept
|
| 1233 | Distributive Justice as the Foundational Premise of Fair ML: Unification, Extension, and Interpretation of Group Fairness Metrics | 5.33 | | Reject
|
| 1234 | Embed and Emulate: Learning to estimate parameters of dynamical systems with uncertainty quantification | 7.00 | | Accept
|
| 1235 | DGD^2: A Linearly Convergent Distributed Algorithm For High-dimensional Statistical Recovery | 7.33 | | Accept
|
| 1236 | Draft-and-Revise: Effective Image Generation with Contextual RQ-Transformer | 5.50 | | Accept
|
| 1237 | Generative multitask learning mitigates target-causing confounding | 5.67 | | Accept
|
| 1238 | Minimax Optimal Online Imitation Learning via Replay Estimation | 7.33 | | Accept
|
| 1239 | Variational Model Perturbation for Source-Free Domain Adaptation | 7.00 | | Accept
|
| 1240 | The Neural Testbed: Evaluating Joint Predictions | 5.25 | | Accept
|
| 1241 | Tight Lower Bounds on Worst-Case Guarantees for Zero-Shot Learning with Attributes | 6.00 | | Accept
|
| 1242 | Deep Ensembles Work, But Are They Necessary? | 7.25 | | Accept
|
| 1243 | Recursive Reasoning in Minimax Games: A Level $k$ Gradient Play Method | 6.00 | | Accept
|
| 1244 | The Privacy Onion Effect: Memorization is Relative | 6.50 | | Accept
|
| 1245 | Learning to Sample and Aggregate: Few-shot Reasoning over Temporal Knowledge Graphs | 6.00 | | Accept
|
| 1246 | A Character-Level Length-Control Algorithm for Non-Autoregressive Sentence Summarization | 5.75 | | Accept
|
| 1247 | Optimal Rates for Regularized Conditional Mean Embedding Learning | 7.50 | | Accept
|
| 1248 | Scaling Multimodal Pre-Training via Cross-Modality Gradient Harmonization | 6.33 | | Accept
|
| 1249 | A permutation-free kernel two-sample test | 7.00 | | Accept
|
| 1250 | Deep Architecture Connectivity Matters for Its Convergence: A Fine-Grained Analysis | 6.67 | | Accept
|
| 1251 | Seeing the forest and the tree: Building representations of both individual and collective dynamics with transformers | 6.50 | | Accept
|
| 1252 | Pruning has a disparate impact on model accuracy | 6.67 | | Accept
|
| 1253 | Efficient Non-Parametric Optimizer Search for Diverse Tasks | 5.67 | | Accept
|
| 1254 | Triangulation candidates for Bayesian optimization | 6.50 | | Accept
|
| 1255 | Rashomon Capacity: A Metric for Predictive Multiplicity in Classification | 5.33 | | Accept
|
| 1256 | Are All Losses Created Equal: A Neural Collapse Perspective | 6.67 | | Accept
|
| 1257 | Interventions, Where and How? Experimental Design for Causal Models at Scale | 6.17 | | Accept
|
| 1258 | CoPur: Certifiably Robust Collaborative Inference via Feature Purification | 5.20 | | Accept
|
| 1259 | CroCo: Self-Supervised Pre-training for 3D Vision Tasks by Cross-View Completion | 5.75 | | Accept
|
| 1260 | On the SDEs and Scaling Rules for Adaptive Gradient Algorithms | 6.50 | | Accept
|
| 1261 | Scalable Representation Learning in Linear Contextual Bandits with Constant Regret Guarantees | 7.00 | | Accept
|
| 1262 | Universal Rates for Interactive Learning | 8.00 | | Accept
|
| 1263 | Wavelet Feature Maps Compression for Image-to-Image CNNs | 5.50 | | Accept
|
| 1264 | AutoMTL: A Programming Framework for Automating Efficient Multi-Task Learning | 5.67 | | Accept
|
| 1265 | What You See is What You Get: Principled Deep Learning via Distributional Generalization | 6.00 | | Accept
|
| 1266 | Subspace Recovery from Heterogeneous Data with Non-isotropic Noise | 6.00 | | Accept
|
| 1267 | Hyperbolic Embedding Inference for Structured Multi-Label Prediction | 6.00 | | Accept
|
| 1268 | UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes | 7.33 | | Accept
|
| 1269 | BOME! Bilevel Optimization Made Easy: A Simple First-Order Approach | 5.75 | | Accept
|
| 1270 | Coordinate Linear Variance Reduction for Generalized Linear Programming | 5.75 | | Accept
|
| 1271 | Finding Correlated Equilibrium of Constrained Markov Game: A Primal-Dual Approach | 6.20 | | Accept
|
| 1272 | Fair Bayes-Optimal Classifiers Under Predictive Parity | 5.25 | | Accept
|
| 1273 | First Hitting Diffusion Models for Generating Manifold, Graph and Categorical Data | 5.25 | | Accept
|
| 1274 | Rapid Model Architecture Adaption for Meta-Learning | 5.50 | | Accept
|
| 1275 | Density-driven Regularization for Out-of-distribution Detection | 5.75 | | Accept
|
| 1276 | Nearly Optimal Algorithms for Linear Contextual Bandits with Adversarial Corruptions | 6.00 | | Accept
|
| 1277 | On the Generalization Power of the Overfitted Three-Layer Neural Tangent Kernel Model | 6.25 | | Accept
|
| 1278 | Insights into Pre-training via Simpler Synthetic Tasks | 5.50 | | Accept
|
| 1279 | ORIENT: Submodular Mutual Information Measures for Data Subset Selection under Distribution Shift | 5.75 | | Accept
|
| 1280 | An Information-Theoretic Framework for Deep Learning | 5.50 | | Accept
|
| 1281 | DeepFoids: Adaptive Bio-Inspired Fish Simulation with Deep Reinforcement Learning | 6.00 | | Accept
|
| 1282 | Poisson Flow Generative Models | 5.33 | | Accept
|
| 1283 | On the Efficient Implementation of High Accuracy Optimality of Profile Maximum Likelihood | 6.00 | | Accept
|
| 1284 | KERPLE: Kernelized Relative Positional Embedding for Length Extrapolation | 6.00 | | Accept
|
| 1285 | Staggered Rollout Designs Enable Causal Inference Under Interference Without Network Knowledge | 6.00 | | Accept
|
| 1286 | AUTOMATA: Gradient Based Data Subset Selection for Compute-Efficient Hyper-parameter Tuning | 5.50 | | Accept
|
| 1287 | projUNN: efficient method for training deep networks with unitary matrices | 7.50 | | Accept
|
| 1288 | SUNMASK: Mask Enhanced Control in Step Unrolled Denoising Autoencoders | 4.80 | | Reject
|
| 1289 | Extra-Newton: A First Approach to Noise-Adaptive Accelerated Second-Order Methods | 6.50 | | Accept
|
| 1290 | Learning to Discover and Detect Objects | 6.00 | | Accept
|
| 1291 | FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness | 7.20 | | Accept
|
| 1292 | Rate-Optimal Online Convex Optimization in Adaptive Linear Control | 7.00 | | Accept
|
| 1293 | Model-based Lifelong Reinforcement Learning with Bayesian Exploration | 6.33 | | Accept
|
| 1294 | Knowledge Distillation: Bad Models Can Be Good Role Models | 6.25 | | Accept
|
| 1295 | AVLEN: Audio-Visual-Language Embodied Navigation in 3D Environments | 5.50 | | Accept
|
| 1296 | Transferring Fairness under Distribution Shifts via Fair Consistency Regularization | 5.00 | | Accept
|
| 1297 | A Consistent and Differentiable Lp Canonical Calibration Error Estimator | 6.67 | | Accept
|
| 1298 | On Batch Teaching with Sample Complexity Bounded by VCD | 6.75 | | Accept
|
| 1299 | Nonlinear Sufficient Dimension Reduction with a Stochastic Neural Network | 5.00 | | Accept
|
| 1300 | Fine-Tuning Pre-Trained Language Models Effectively by Optimizing Subnetworks Adaptively | 6.75 | | Accept
|
| 1301 | Exploring the Whole Rashomon Set of Sparse Decision Trees | 7.75 | | Accept
|
| 1302 | Global Convergence of Direct Policy Search for State-Feedback $\mathcal{H}_\infty$ Robust Control: A Revisit of Nonsmooth Synthesis with Goldstein Subdifferential | 7.00 | | Accept
|
| 1303 | Improved Algorithms for Neural Active Learning | 6.25 | | Accept
|
| 1304 | Denoising Diffusion Restoration Models | 5.50 | | Accept
|
| 1305 | How to talk so AI will learn: Instructions, descriptions, and autonomy | 6.60 | | Accept
|
| 1306 | Sign and Basis Invariant Networks for Spectral Graph Representation Learning | 5.50 | | Reject
|
| 1307 | Spectral Bias Outside the Training Set for Deep Networks in the Kernel Regime | 6.75 | | Accept
|
| 1308 | On Image Segmentation With Noisy Labels: Characterization and Volume Properties of the Optimal Solutions to Accuracy and Dice | 6.00 | | Accept
|
| 1309 | Weisfeiler and Leman Go Walking: Random Walk Kernels Revisited | 6.50 | | Accept
|
| 1310 | Provably Efficient Reinforcement Learning in Partially Observable Dynamical Systems | 5.75 | | Accept
|
| 1311 | WeightedSHAP: analyzing and improving Shapley based feature attributions | 5.50 | | Accept
|
| 1312 | The Burer-Monteiro SDP method can fail even above the Barvinok-Pataki bound | 6.50 | | Accept
|
| 1313 | Fairness Transferability Subject to Bounded Distribution Shift | 6.50 | | Accept
|
| 1314 | Near-Optimal Sample Complexity Bounds for Constrained MDPs | 6.25 | | Accept
|
| 1315 | Multi-Fidelity Best-Arm Identification | 5.75 | | Accept
|
| 1316 | TreeMoCo: Contrastive Neuron Morphology Representation Learning | 6.00 | | Accept
|
| 1317 | Learning in Congestion Games with Bandit Feedback | 6.33 | | Accept
|
| 1318 | Deep feedforward functionality by equilibrium-point control in a shallow recurrent network. | 4.75 | | Reject
|
| 1319 | Kernel Interpolation with Sparse Grids | 6.50 | | Accept
|
| 1320 | Large-scale Optimization of Partial AUC in a Range of False Positive Rates | 6.00 | | Accept
|
| 1321 | Revisiting Non-Parametric Matching Cost Volumes for Robust and Generalizable Stereo Matching | 5.75 | | Accept
|
| 1322 | Learning and Covering Sums of Independent Random Variables with Unbounded Support | 7.00 | | Accept
|
| 1323 | When Do Flat Minima Optimizers Work? | 6.00 | | Accept
|
| 1324 | Using Partial Monotonicity in Submodular Maximization | 6.25 | | Accept
|
| 1325 | Phase diagram of Stochastic Gradient Descent in high-dimensional two-layer neural networks | 6.67 | | Accept
|
| 1326 | Exploiting Semantic Relations for Glass Surface Detection | 5.00 | | Accept
|
| 1327 | Lifelong Neural Predictive Coding: Learning Cumulatively Online without Forgetting | 5.67 | | Accept
|
| 1328 | Stochastic Online Learning with Feedback Graphs: Finite-Time and Asymptotic Optimality | 6.00 | | Accept
|
| 1329 | FedSR: A Simple and Effective Domain Generalization Method for Federated Learning | 5.75 | | Accept
|
| 1330 | Distribution-Informed Neural Networks for Domain Adaptation Regression | 5.20 | | Accept
|
| 1331 | Deep Learning meets Nonparametric Regression: Are Weight-Decayed DNNs Locally Adaptive? | 5.25 | | Reject
|
| 1332 | Rare Gems: Finding Lottery Tickets at Initialization | 5.75 | | Accept
|
| 1333 | A Curriculum Perspective of Robust Loss Functions | 5.25 | | Reject
|
| 1334 | Optimal Transport of Classifiers to Fairness | 6.00 | | Accept
|
| 1335 | Navigating Memory Construction by Global Pseudo-Task Simulation for Continual Learning | 5.00 | | Accept
|
| 1336 | Hidden Progress in Deep Learning: SGD Learns Parities Near the Computational Limit | 5.67 | | Accept
|
| 1337 | How and Why to Manipulate Your Own Agent: On the Incentives of Users of Learning Agents | 5.75 | | Accept
|
| 1338 | Data-IQ: Characterizing subgroups with heterogeneous outcomes in tabular data | 5.80 | | Accept
|
| 1339 | Domain Generalization without Excess Empirical Risk | 6.00 | | Accept
|
| 1340 | LECO: Learnable Episodic Count for Task-Specific Intrinsic Reward | 5.33 | | Accept
|
| 1341 | Extrapolative Continuous-time Bayesian Neural Network for Fast Training-free Test-time Adaptation | 6.00 | | Accept
|
| 1342 | A Fourier Approach to Mixture Learning | 6.67 | | Accept
|
| 1343 | Global Linear and Local Superlinear Convergence of IRLS for Non-Smooth Robust Regression | 6.00 | | Accept
|
| 1344 | Constrained Update Projection Approach to Safe Policy Optimization | 5.75 | | Accept
|
| 1345 | Conformal Off-Policy Prediction in Contextual Bandits | 5.67 | | Accept
|
| 1346 | AutoML Two-Sample Test | 5.50 | | Accept
|
| 1347 | Constraining Gaussian Processes to Systems of Linear Ordinary Differential Equations | 6.25 | | Accept
|
| 1348 | Value Function Decomposition for Iterative Design of Reinforcement Learning Agents | 5.25 | | Accept
|
| 1349 | Perfect Sampling from Pairwise Comparisons | 6.75 | | Accept
|
| 1350 | An $\alpha$-No-Regret Algorithm For Graphical Bilinear Bandits | 6.00 | | Accept
|
| 1351 | Listen to Interpret: Post-hoc Interpretability for Audio Networks with NMF | 6.50 | | Accept
|
| 1352 | Temporally-Consistent Survival Analysis | 6.75 | | Accept
|
| 1353 | Exponential Separations in Symmetric Neural Networks | 7.25 | | Accept
|
| 1354 | STaR: Bootstrapping Reasoning With Reasoning | 6.75 | | Accept
|
| 1355 | Gradient Estimation with Discrete Stein Operators | 7.25 | | Accept
|
| 1356 | Composite Feature Selection Using Deep Ensembles | 5.75 | | Accept
|
| 1357 | Fast Mixing of Stochastic Gradient Descent with Normalization and Weight Decay | 6.25 | | Accept
|
| 1358 | Sobolev Acceleration and Statistical Optimality for Learning Elliptic Equations via Gradient Descent | 6.00 | | Accept
|
| 1359 | Bayesian inference via sparse Hamiltonian flows | 8.00 | | Accept
|
| 1360 | SHAQ: Incorporating Shapley Value Theory into Multi-Agent Q-Learning | 6.33 | | Accept
|
| 1361 | Neural Stochastic PDEs: Resolution-Invariant Learning of Continuous Spatiotemporal Dynamics | 6.00 | | Accept
|
| 1362 | Amortized Inference for Heterogeneous Reconstruction in Cryo-EM | 5.75 | | Accept
|
| 1363 | NIERT: Accurate Numerical Interpolation through Unifying Scattered Data Representations using Transformer Encoder | 5.67 | | Reject
|
| 1364 | VAEL: Bridging Variational Autoencoders and Probabilistic Logic Programming | 5.25 | | Accept
|
| 1365 | Reinforced Genetic Algorithm for Structure-based Drug Design | 5.00 | | Accept
|
| 1366 | One for All: Simultaneous Metric and Preference Learning over Multiple Users | 6.50 | | Accept
|
| 1367 | Uplifting Bandits | 5.50 | | Accept
|
| 1368 | CyCLIP: Cyclic Contrastive Language-Image Pretraining | 7.00 | | Accept
|
| 1369 | Spectrum Random Masking for Generalization in Image-based Reinforcement Learning | 6.25 | | Accept
|
| 1370 | First Contact: Unsupervised Human-Machine Co-Adaptation via Mutual Information Maximization | 5.67 | | Accept
|
| 1371 | Learning Superpoint Graph Cut for 3D Instance Segmentation | 6.00 | | Accept
|
| 1372 | Learning Bipartite Graphs: Heavy Tails and Multiple Components | 5.33 | | Accept
|
| 1373 | MissDAG: Causal Discovery in the Presence of Missing Data with Continuous Additive Noise Models | 6.00 | | Accept
|
| 1374 | Efficient Scheduling of Data Augmentation for Deep Reinforcement Learning | 6.50 | | Accept
|
| 1375 | Chain of Thought Prompting Elicits Reasoning in Large Language Models | 7.00 | | Accept
|
| 1376 | Weakly Supervised Representation Learning with Sparse Perturbations | 6.25 | | Accept
|
| 1377 | Association Graph Learning for Multi-Task Classification with Category Shifts | 6.00 | | Accept
|
| 1378 | Learning from Label Proportions by Learning with Label Noise | 6.00 | | Accept
|
| 1379 | SignRFF: Sign Random Fourier Features | 5.25 | | Accept
|
| 1380 | HYPRO: A Hybridly Normalized Probabilistic Model for Long-Horizon Prediction of Event Sequences | 6.33 | | Accept
|
| 1381 | Off-Policy Evaluation for Action-Dependent Non-stationary Environments | 5.50 | | Accept
|
| 1382 | Asymptotics of smoothed Wasserstein distances in the small noise regime | 7.00 | | Accept
|
| 1383 | Defending Against Adversarial Attacks via Neural Dynamic System | 6.25 | | Accept
|
| 1384 | Sampling with Riemannian Hamiltonian Monte Carlo in a Constrained Space | 6.40 | | Accept
|
| 1385 | Optimal-er Auctions through Attention | 6.00 | | Accept
|
| 1386 | The Phenomenon of Policy Churn | 6.33 | | Accept
|
| 1387 | RTFormer: Efficient Design for Real-Time Semantic Segmentation with Transformer | 5.00 | | Accept
|
| 1388 | Near-Optimal Regret for Adversarial MDP with Delayed Bandit Feedback | 6.33 | | Accept
|
| 1389 | Which Explanation Should I Choose? A Function Approximation Perspective to Characterizing Post Hoc Explanations | 6.00 | | Accept
|
| 1390 | On the Computational Efficiency of Adapting Transformer Models via Adversarial Noise | 6.00 | | Reject
|
| 1391 | Latent Planning via Expansive Tree Search | 6.00 | | Accept
|
| 1392 | Emergent Communication: Generalization and Overfitting in Lewis Games | 7.00 | | Accept
|
| 1393 | Entropy-Driven Mixed-Precision Quantization for Deep Network Design | 6.50 | | Accept
|
| 1394 | Label-Aware Global Consistency for Multi-Label Learning with Single Positive Labels | 7.25 | | Accept
|
| 1395 | Black-Box Generalization: Stability of Zeroth-Order Learning | 6.00 | | Accept
|
| 1396 | DReS-FL: Dropout-Resilient Secure Federated Learning for Non-IID Clients via Secret Data Sharing | 5.25 | | Accept
|
| 1397 | Dynamic Inverse Reinforcement Learning for Characterizing Animal Behavior | 7.50 | | Accept
|
| 1398 | Confidence-based Reliable Learning under Dual Noises | 5.33 | | Accept
|
| 1399 | Interpolation and Regularization for Causal Learning | 6.25 | | Accept
|
| 1400 | Off-Policy Evaluation with Policy-Dependent Optimization Response | 6.00 | | Accept
|
| 1401 | PDSketch: Integrated Domain Programming, Learning, and Planning | 5.00 | | Accept
|
| 1402 | Spatial Mixture-of-Experts | 5.40 | | Accept
|
| 1403 | Adaptive Distribution Calibration for Few-Shot Learning with Hierarchical Optimal Transport | 6.00 | | Accept
|
| 1404 | Iterative Structural Inference of Directed Graphs | 5.67 | | Accept
|
| 1405 | Contrastive Graph Structure Learning via Information Bottleneck for Recommendation | 6.25 | | Accept
|
| 1406 | A Geometric Perspective on Variational Autoencoders | 6.33 | | Accept
|
| 1407 | Foundation Posteriors for Approximate Probabilistic Inference | 7.00 | | Accept
|
| 1408 | On Non-Linear operators for Geometric Deep Learning | 6.00 | | Accept
|
| 1409 | Scale-invariant Learning by Physics Inversion | 6.00 | | Accept
|
| 1410 | Towards Improving Faithfulness in Abstractive Summarization | 6.50 | | Accept
|
| 1411 | Nonlinear MCMC for Bayesian Machine Learning | 6.50 | | Accept
|
| 1412 | Neural Approximation of Graph Topological Features | 5.67 | | Accept
|
| 1413 | Self-Supervised Fair Representation Learning without Demographics | 5.75 | | Accept
|
| 1414 | Efficient Training of Low-Curvature Neural Networks | 5.25 | | Accept
|
| 1415 | Log-Polar Space Convolution Layers | 5.50 | | Accept
|
| 1416 | Reinforcement Learning with Logarithmic Regret and Policy Switches | 6.25 | | Accept
|
| 1417 | Ensemble of Averages: Improving Model Selection and Boosting Performance in Domain Generalization | 6.25 | | Accept
|
| 1418 | Gradient flow dynamics of shallow ReLU networks for square loss and orthogonal inputs | 6.75 | | Accept
|
| 1419 | Bandit Learning in Many-to-one Matching Markets with Uniqueness Conditions | 5.25 | | Reject
|
| 1420 | Self-Supervised Learning of Brain Dynamics from Broad Neuroimaging Data | 6.33 | | Accept
|
| 1421 | On Translation and Reconstruction Guarantees of the Cycle-Consistent Generative Adversarial Networks | 6.00 | | Accept
|
| 1422 | Near-Optimal Regret Bounds for Multi-batch Reinforcement Learning | 6.00 | | Accept
|
| 1423 | On Overcompression in Continual Semantic Segmentation | 3.50 | | Reject
|
| 1424 | WaveBound: Dynamic Error Bounds for Stable Time Series Forecasting | 6.25 | | Accept
|
| 1425 | Sampling from Log-Concave Distributions with Infinity-Distance Guarantees | 7.25 | | Accept
|
| 1426 | Distributed Inverse Constrained Reinforcement Learning for Multi-agent Systems | 6.25 | | Accept
|
| 1427 | Early Stage Convergence and Global Convergence of Training Mildly Parameterized Neural Networks | 5.75 | | Accept
|
| 1428 | Task-level Differentially Private Meta Learning | 5.00 | | Accept
|
| 1429 | Surprise Minimizing Multi-Agent Learning with Energy-based Models | 6.00 | | Accept
|
| 1430 | Learning Predictions for Algorithms with Predictions | 6.25 | | Accept
|
| 1431 | GLIF: A Unified Gated Leaky Integrate-and-Fire Neuron for Spiking Neural Networks | 4.75 | | Accept
|
| 1432 | Spectral Bias in Practice: The Role of Function Frequency in Generalization | 6.00 | | Accept
|
| 1433 | Robust Binary Models by Pruning Randomly-initialized Networks | 5.75 | | Accept
|
| 1434 | Re-Analyze Gauss: Bounds for Private Matrix Approximation via Dyson Brownian Motion | 5.50 | | Accept
|
| 1435 | Sparse Structure Search for Delta Tuning | 5.75 | | Accept
|
| 1436 | Modeling Human Exploration Through Resource-Rational Reinforcement Learning | 7.50 | | Accept
|
| 1437 | Order-Invariant Cardinality Estimators Are Differentially Private | 6.50 | | Accept
|
| 1438 | Optimal and Adaptive Monteiro-Svaiter Acceleration | 7.00 | | Accept
|
| 1439 | Fair Ranking with Noisy Protected Attributes | 6.75 | | Accept
|
| 1440 | A consistently adaptive trust-region method | 6.33 | | Accept
|
| 1441 | Alternating Mirror Descent for Constrained Min-Max Games | 6.00 | | Accept
|
| 1442 | Semi-Supervised Video Salient Object Detection Based on Uncertainty-Guided Pseudo Labels | 5.33 | | Accept
|
| 1443 | Beyond Time-Average Convergence: Near-Optimal Uncoupled Online Learning via Clairvoyant Multiplicative Weights Update | 6.00 | | Accept
|
| 1444 | Torsional Diffusion for Molecular Conformer Generation | 7.25 | | Accept
|
| 1445 | Can Variance-Based Regularization Improve Domain Generalization? | 4.50 | | Reject
|
| 1446 | Learning to Find Proofs and Theorems by Learning to Refine Search Strategies: The Case of Loop Invariant Synthesis | 5.33 | | Accept
|
| 1447 | ZooD: Exploiting Model Zoo for Out-of-Distribution Generalization | 5.67 | | Accept
|
| 1448 | Debiasing Graph Neural Networks via Learning Disentangled Causal Substructure | 5.75 | | Accept
|
| 1449 | GraB: Finding Provably Better Data Permutations than Random Reshuffling | 6.33 | | Accept
|
| 1450 | Enhancing Safe Exploration Using Safety State Augmentation | 5.25 | | Accept
|
| 1451 | Generalization Error Bounds on Deep Learning with Markov Datasets | 6.00 | | Accept
|
| 1452 | Posterior Matching for Arbitrary Conditioning | 6.75 | | Accept
|
| 1453 | Learning to Re-weight Examples with Optimal Transport for Imbalanced Classification | 5.25 | | Accept
|
| 1454 | Matrix Multiplicative Weights Updates in Quantum Zero-Sum Games: Conservation Laws & Recurrence | 6.25 | | Accept
|
| 1455 | On the non-universality of deep learning: quantifying the cost of symmetry | 6.00 | | Accept
|
| 1456 | Don’t fear the unlabelled: safe semi-supervised learning via simple debiasing | 5.00 | | Reject
|
| 1457 | Pre-activation Distributions Expose Backdoor Neurons | 5.75 | | Accept
|
| 1458 | Flamingo: a Visual Language Model for Few-Shot Learning | 6.80 | | Accept
|
| 1459 | The Curse of Unrolling: Rate of Differentiating Through Optimization | 6.67 | | Accept
|
| 1460 | Adaptive Multi-stage Density Ratio Estimation for Learning Latent Space Energy-based Model | 7.00 | | Accept
|
| 1461 | Distributionally robust weighted k-nearest neighbors | 6.25 | | Accept
|
| 1462 | Finite-Time Analysis of Fully Decentralized Single-Timescale Actor Critic | 5.67 | | Reject
|
| 1463 | Towards Disentangling Information Paths with Coded ResNeXt | 5.75 | | Accept
|
| 1464 | Stability and Generalization for Markov Chain Stochastic Gradient Methods | 5.67 | | Accept
|
| 1465 | Safe Opponent-Exploitation Subgame Refinement | 5.67 | | Accept
|
| 1466 | Local Latent Space Bayesian Optimization over Structured Inputs | 6.67 | | Accept
|
| 1467 | Iron: Private Inference on Transformers | 6.33 | | Accept
|
| 1468 | Uncertainty-Aware Hierarchical Refinement for Incremental Implicitly-Refined Classification | 4.75 | | Accept
|
| 1469 | Understanding Why Generalized Reweighting Does Not Improve Over ERM | 5.00 | | Reject
|
| 1470 | Increasing the Scope as You Learn: Adaptive Bayesian Optimization in Nested Subspaces | 7.00 | | Accept
|
| 1471 | Streaming Radiance Fields for 3D Video Synthesis | 5.67 | | Accept
|
| 1472 | Universal approximation and model compression for radial neural networks | 5.33 | | Reject
|
| 1473 | MOVE: Unsupervised Movable Object Segmentation and Detection | 6.33 | | Accept
|
| 1474 | Robust Semi-Supervised Learning when Not All Classes have Labels | 6.75 | | Accept
|
| 1475 | An Error Analysis of Deep Density-Ratio Estimation with Bregman Divergence | 6.00 | | Reject
|
| 1476 | Near-Optimal Collaborative Learning in Bandits | 6.67 | | Accept
|
| 1477 | On Embeddings for Numerical Features in Tabular Deep Learning | 5.00 | | Accept
|
| 1478 | Decentralized Gossip-Based Stochastic Bilevel Optimization over Communication Networks | 6.50 | | Accept
|
| 1479 | Offline Multi-Agent Reinforcement Learning with Knowledge Distillation | 5.67 | | Accept
|
| 1480 | A Unified Convergence Theorem for Stochastic Optimization Methods | 6.50 | | Accept
|
| 1481 | Distributional Reinforcement Learning for Risk-Sensitive Policies | 6.00 | | Accept
|
| 1482 | Pareto Set Learning for Expensive Multi-Objective Optimization | 6.25 | | Accept
|
| 1483 | Tracking Functional Changes in Nonstationary Signals with Evolutionary Ensemble Bayesian Model for Robust Neural Decoding | 5.00 | | Accept
|
| 1484 | Simultaneous Missing Value Imputation and Structure Learning with Groups | 6.00 | | Accept
|
| 1485 | Approximation with CNNs in Sobolev Space: with Applications to Classification | 6.67 | | Accept
|
| 1486 | Reduction Algorithms for Persistence Diagrams of Networks: CoralTDA and PrunIT | 5.67 | | Accept
|
| 1487 | FedAvg with Fine Tuning: Local Updates Lead to Representation Learning | 6.75 | | Accept
|
| 1488 | Improved Regret Analysis for Variance-Adaptive Linear Bandits and Horizon-Free Linear Mixture MDPs | 6.00 | | Accept
|
| 1489 | Sparse Winning Tickets are Data-Efficient Image Recognizers | 6.00 | | Accept
|
| 1490 | Counterfactual Temporal Point Processes | 6.00 | | Accept
|
| 1491 | Diverse Weight Averaging for Out-of-Distribution Generalization | 7.00 | | Accept
|
| 1492 | Vector Quantized Diffusion Model with CodeUnet for Text-to-Sign Pose Sequences Generation | 5.00 | | Reject
|
| 1493 | Adaptive Sampling for Discovery | 5.33 | | Accept
|
| 1494 | Learned Index with Dynamic $\epsilon$ | 5.67 | | Reject
|
| 1495 | Smoothed Online Convex Optimization Based on Discounted-Normal-Predictor | 6.50 | | Accept
|
| 1496 | Learning Expressive Meta-Representations with Mixture of Expert Neural Processes | 6.67 | | Accept
|
| 1497 | Causal Discovery in Heterogeneous Environments Under the Sparse Mechanism Shift Hypothesis | 5.67 | | Accept
|
| 1498 | Neural Stochastic Control | 5.75 | | Accept
|
| 1499 | Beyond L1: Faster and Better Sparse Models with skglm | 6.00 | | Accept
|
| 1500 | Promising or Elusive? Unsupervised Object Segmentation from Real-world Single Images | 6.67 | | Accept
|
| 1501 | Mining Multi-Label Samples from Single Positive Labels | 6.00 | | Accept
|
| 1502 | Unsupervised Domain Adaptation for Semantic Segmentation using Depth Distribution | 5.00 | | Accept
|
| 1503 | A Damped Newton Method Achieves Global $\mathcal O \left(\frac{1}{k^2}\right)$ and Local Quadratic Convergence Rate | 6.67 | | Accept
|
| 1504 | Improving GANs with A Dynamic Discriminator | 5.50 | | Accept
|
| 1505 | Star Temporal Classification: Sequence Modeling with Partially Labeled Data | 5.33 | | Accept
|
| 1506 | PKD: General Distillation Framework for Object Detectors via Pearson Correlation Coefficient | 6.00 | | Accept
|
| 1507 | Data-Efficient Structured Pruning via Submodular Optimization | 6.75 | | Accept
|
| 1508 | Blessing of Depth in Linear Regression: Deeper Models Have Flatter Landscape Around the True Solution | 7.00 | | Accept
|
| 1509 | Aligning individual brains with fused unbalanced Gromov Wasserstein | 6.67 | | Accept
|
| 1510 | Minimax Regret for Cascading Bandits | 7.00 | | Accept
|
| 1511 | EGSDE: Unpaired Image-to-Image Translation via Energy-Guided Stochastic Differential Equations | 5.75 | | Accept
|
| 1512 | Fast Bayesian Inference with Batch Bayesian Quadrature via Kernel Recombination | 6.00 | | Accept
|
| 1513 | Efficient Adversarial Training without Attacking: Worst-Case-Aware Robust Reinforcement Learning | 6.75 | | Accept
|
| 1514 | CoNT: Contrastive Neural Text Generation | 6.00 | | Accept
|
| 1515 | Sample-Then-Optimize Batch Neural Thompson Sampling | 6.50 | | Accept
|
| 1516 | RSA: Reducing Semantic Shift from Aggressive Augmentations for Self-supervised Learning | 6.00 | | Accept
|
| 1517 | Concurrent 3D super resolution on intensity and segmentation maps improves detection of structural effects in neurodegenerative disease | 4.33 | | Reject
|
| 1518 | Communication Efficient Federated Learning for Generalized Linear Bandits | 5.67 | | Accept
|
| 1519 | Brain Network Transformer | 5.50 | | Accept
|
| 1520 | AZ-whiteness test: a test for signal uncorrelation on spatio-temporal graphs | 6.00 | | Accept
|
| 1521 | ViewFool: Evaluating the Robustness of Visual Recognition to Adversarial Viewpoints | 6.00 | | Accept
|
| 1522 | Discovery of Single Independent Latent Variable | 6.50 | | Accept
|
| 1523 | Between Stochastic and Adversarial Online Convex Optimization: Improved Regret Bounds via Smoothness | 6.33 | | Accept
|
| 1524 | Pseudo-Riemannian Graph Convolutional Networks | 6.25 | | Accept
|
| 1525 | Conditional Meta-Learning of Linear Representations | 5.75 | | Accept
|
| 1526 | Grounding Aleatoric Uncertainty for Unsupervised Environment Design | 5.67 | | Accept
|
| 1527 | Alleviating ``Posterior Collapse'' in Deep Topic Models via Policy Gradient | 5.67 | | Accept
|
| 1528 | Fast Algorithms for Packing Proportional Fairness and its Dual | 5.50 | | Accept
|
| 1529 | LobsDICE: Offline Learning from Observation via Stationary Distribution Correction Estimation | 6.25 | | Accept
|
| 1530 | MoGDE: Boosting Mobile Monocular 3D Object Detection with Ground Depth Estimation | 5.75 | | Accept
|
| 1531 | Finding Second-Order Stationary Points in Nonconvex-Strongly-Concave Minimax Optimization | 6.00 | | Accept
|
| 1532 | Structured Energy Network As a Loss | 6.67 | | Accept
|
| 1533 | Moment Distributionally Robust Tree Structured Prediction | 7.00 | | Accept
|
| 1534 | Iso-Dream: Isolating Noncontrollable Visual Dynamics in World Models | 7.00 | | Accept
|
| 1535 | Improving RENet by Introducing Modified Cross Attention for Few-Shot Classification | 3.50 | | Reject
|
| 1536 | On the Spectral Bias of Convolutional Neural Tangent and Gaussian Process Kernels | 6.50 | | Accept
|
| 1537 | On Robust Multiclass Learnability | 7.25 | | Accept
|
| 1538 | Formulating Robustness Against Unforeseen Attacks | 6.00 | | Accept
|
| 1539 | Improving Barely Supervised Learning by Discriminating Unlabeled Samples with Super-Class | 5.50 | | Accept
|
| 1540 | Alleviating Adversarial Attacks on Variational Autoencoders with MCMC | 6.00 | | Accept
|
| 1541 | MORA: Improving Ensemble Robustness Evaluation with Model Reweighing Attack | 5.50 | | Accept
|
| 1542 | Shadow Knowledge Distillation: Bridging Offline and Online Knowledge Transfer | 5.33 | | Accept
|
| 1543 | A Theoretical Understanding of Gradient Bias in Meta-Reinforcement Learning | 5.75 | | Accept
|
| 1544 | EvenNet: Ignoring Odd-Hop Neighbors Improves Robustness of Graph Neural Networks | 6.00 | | Accept
|
| 1545 | An Information-theoretic Perspective of Hierarchical Clustering | 4.50 | | Reject
|
| 1546 | Generalization Bounds with Minimal Dependency on Hypothesis Class via Distributionally Robust Optimization | 6.00 | | Accept
|
| 1547 | PALBERT: Teaching ALBERT to Ponder | 4.75 | | Accept
|
| 1548 | Provable General Function Class Representation Learning in Multitask Bandits and MDP | 5.50 | | Accept
|
| 1549 | Exact Shape Correspondence via 2D graph convolution | 5.75 | | Accept
|
| 1550 | NeMF: Neural Motion Fields for Kinematic Animation | 7.25 | | Accept
|
| 1551 | Logical Credal Networks | 6.25 | | Accept
|
| 1552 | Asymmetric Temperature Scaling Makes Larger Networks Teach Well Again | 6.00 | | Accept
|
| 1553 | DeepMed: Semiparametric Causal Mediation Analysis with Debiased Deep Learning | 6.00 | | Accept
|
| 1554 | SnAKe: Bayesian Optimization with Pathwise Exploration | 5.00 | | Accept
|
| 1555 | Distributionally Robust Optimization via Ball Oracle Acceleration | 5.75 | | Accept
|
| 1556 | VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts | 6.33 | | Accept
|
| 1557 | Unknown-Aware Domain Adversarial Learning for Open-Set Domain Adaptation | 5.33 | | Accept
|
| 1558 | Constrained Monotonic Neural Networks | 5.00 | | Reject
|
| 1559 | Semi-Supervised Generative Models for Multiagent Trajectories | 5.50 | | Accept
|
| 1560 | Learning to Generate Inversion-Resistant Model Explanations | 6.75 | | Accept
|
| 1561 | Stability Analysis and Generalization Bounds of Adversarial Training | 7.00 | | Accept
|
| 1562 | Rethinking and Improving Robustness of Convolutional Neural Networks: a Shapley Value-based Approach in Frequency Domain | 6.25 | | Accept
|
| 1563 | On the Convergence of Stochastic Multi-Objective Gradient Manipulation and Beyond | 5.60 | | Accept
|
| 1564 | Revisiting Injective Attacks on Recommender Systems | 6.33 | | Accept
|
| 1565 | Seeing Differently, Acting Similarly: Heterogeneously Observable Imitation Learning | 6.00 | | Reject
|
| 1566 | Pruning Neural Networks via Coresets and Convex Geometry: Towards No Assumptions | 6.25 | | Accept
|
| 1567 | The Policy-gradient Placement and Generative Routing Neural Networks for Chip Design | 6.00 | | Accept
|
| 1568 | Distributed Learning of Conditional Quantiles in the Reproducing Kernel Hilbert Space | 5.00 | | Accept
|
| 1569 | Modeling the Machine Learning Multiverse | 6.50 | | Accept
|
| 1570 | DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps | 7.67 | | Accept
|
| 1571 | Bezier Gaussian Processes for Tall and Wide Data | 5.50 | | Accept
|
| 1572 | Multi-Agent Reinforcement Learning is a Sequence Modeling Problem | 6.33 | | Accept
|
| 1573 | GRASP: Navigating Retrosynthetic Planning with Goal-driven Policy | 6.33 | | Accept
|
| 1574 | Uni-Perceiver-MoE: Learning Sparse Generalist Models with Conditional MoEs | 5.75 | | Accept
|
| 1575 | Efficient Architecture Search for Diverse Tasks | 5.67 | | Accept
|
| 1576 | NodeFormer: A Scalable Graph Structure Learning Transformer for Node Classification | 6.50 | | Accept
|
| 1577 | Active Surrogate Estimators: An Active Learning Approach to Label-Efficient Model Evaluation | 6.50 | | Accept
|
| 1578 | Towards Out-of-Distribution Sequential Event Prediction: A Causal Treatment | 5.75 | | Accept
|
| 1579 | Learning to Constrain Policy Optimization with Virtual Trust Region | 4.67 | | Accept
|
| 1580 | Geometric Knowledge Distillation: Topology Compression for Graph Neural Networks | 5.50 | | Accept
|
| 1581 | Exploring evolution-aware & -free protein language models as protein function predictors | 6.00 | | Accept
|
| 1582 | Robust Graph Structure Learning over Images via Multiple Statistical Tests | 6.33 | | Accept
|
| 1583 | On the Tradeoff Between Robustness and Fairness | 5.33 | | Accept
|
| 1584 | Active Learning Through a Covering Lens | 5.33 | | Accept
|
| 1585 | NeIF: Representing General Reflectance as Neural Intrinsics Fields for Uncalibrated Photometric Stereo | 4.75 | | Reject
|
| 1586 | Amplifying Membership Exposure via Data Poisoning | 4.75 | | Accept
|
| 1587 | Universality of Group Convolutional Neural Networks Based on Ridgelet Analysis on Groups | 5.75 | | Accept
|
| 1588 | Self-supervised surround-view depth estimation with volumetric feature fusion | 5.33 | | Accept
|
| 1589 | Learning Representations via a Robust Behavioral Metric for Deep Reinforcement Learning | 6.25 | | Accept
|
| 1590 | Descent Steps of a Relation-Aware Energy Produce Heterogeneous Graph Neural Networks | 6.00 | | Accept
|
| 1591 | Learning to Reason with Neural Networks: Generalization, Unseen Data and Boolean Measures | 6.25 | | Accept
|
| 1592 | Large Language Models are Zero-Shot Reasoners | 5.80 | | Accept
|
| 1593 | Effective Adaptation in Multi-Task Co-Training for Unified Autonomous Driving | 5.67 | | Accept
|
| 1594 | Escaping Saddle Points with Bias-Variance Reduced Local Perturbed SGD for Communication Efficient Nonconvex Distributed Learning | 6.00 | | Accept
|
| 1595 | Causality-driven Hierarchical Structure Discovery for Reinforcement Learning | 6.00 | | Accept
|
| 1596 | Are AlphaZero-like Agents Robust to Adversarial Perturbations? | 4.75 | | Accept
|
| 1597 | Learning to Drop Out: An Adversarial Approach to Training Sequence VAEs | 5.33 | | Accept
|
| 1598 | Wasserstein Iterative Networks for Barycenter Estimation | 6.00 | | Accept
|
| 1599 | FedPop: A Bayesian Approach for Personalised Federated Learning | 5.67 | | Accept
|
| 1600 | AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition | 5.00 | | Accept
|
| 1601 | Active Learning of Classifiers with Label and Seed Queries | 6.33 | | Accept
|
| 1602 | Optimal Binary Classification Beyond Accuracy | 6.50 | | Accept
|
| 1603 | On Margin Maximization in Linear and ReLU Networks | 6.00 | | Accept
|
| 1604 | Causality Preserving Chaotic Transformation and Classification using Neurochaos Learning | 5.00 | | Accept
|
| 1605 | A Closer Look at Offline RL Agents | 6.00 | | Accept
|
| 1606 | Picking on the Same Person: Does Algorithmic Monoculture lead to Outcome Homogenization? | 5.33 | | Accept
|
| 1607 | Thinking Outside the Ball: Optimal Learning with Gradient Descent for Generalized Linear Stochastic Convex Optimization | 6.00 | | Accept
|
| 1608 | Federated Submodel Optimization for Hot and Cold Data Features | 5.00 | | Accept
|
| 1609 | Parameter-free Dynamic Graph Embedding for Link Prediction | 6.00 | | Accept
|
| 1610 | S3GC: Scalable Self-Supervised Graph Clustering | 5.67 | | Accept
|
| 1611 | Consistent Sufficient Explanations and Minimal Local Rules for explaining the decision of any classifier or regressor | 5.50 | | Accept
|
| 1612 | Detecting danger in gridworlds using Gromov's Link Condition | 3.00 | | Reject
|
| 1613 | MExMI: Pool-based Active Model Extraction Crossover Membership Inference | 6.00 | | Accept
|
| 1614 | Neural Sheaf Diffusion: A Topological Perspective on Heterophily and Oversmoothing in GNNs | 7.00 | | Accept
|
| 1615 | Improving Neural Ordinary Differential Equations with Nesterov's Accelerated Gradient Method | 6.67 | | Accept
|
| 1616 | Stimulative Training of Residual Networks: A Social Psychology Perspective of Loafing | 4.25 | | Accept
|
| 1617 | Transformers from an Optimization Perspective | 5.75 | | Accept
|
| 1618 | LDSA: Learning Dynamic Subtask Assignment in Cooperative Multi-Agent Reinforcement Learning | 6.25 | | Accept
|
| 1619 | Knowledge Distillation Improves Graph Structure Augmentation for Graph Neural Networks | 6.00 | | Accept
|
| 1620 | Guaranteed Conservation of Momentum for Learning Particle-based Fluid Dynamics | 6.67 | | Accept
|
| 1621 | Characterization of Excess Risk for Locally Strongly Convex Population Risk | 6.50 | | Accept
|
| 1622 | A Probabilistic Graph Coupling View of Dimension Reduction | 5.75 | | Accept
|
| 1623 | Revisiting Graph Contrastive Learning from the Perspective of Graph Spectrum | 5.80 | | Accept
|
| 1624 | Pluralistic Image Completion with Gaussian Mixture Models | 6.00 | | Accept
|
| 1625 | Effective Decision Boundary Learning for Class Incremental Learning | 4.50 | | Reject
|
| 1626 | Top Two Algorithms Revisited | 6.00 | | Accept
|
| 1627 | Attracting and Dispersing: A Simple Approach for Source-free Domain Adaptation | 6.25 | | Accept
|
| 1628 | Mingling Foresight with Imagination: Model-Based Cooperative Multi-Agent Reinforcement Learning | 5.50 | | Accept
|
| 1629 | Generalization Analysis on Learning with a Concurrent Verifier | 6.67 | | Accept
|
| 1630 | Bridge the Gap Between Architecture Spaces via A Cross-Domain Predictor | 6.00 | | Accept
|
| 1631 | Online Frank-Wolfe with Arbitrary Delays | 5.75 | | Accept
|
| 1632 | One Positive Label is Sufficient: Single-Positive Multi-Label Learning with Label Enhancement | 7.50 | | Accept
|
| 1633 | Semi-infinitely Constrained Markov Decision Processes | 5.67 | | Accept
|
| 1634 | Quasi-Newton Methods for Saddle Point Problems | 6.50 | | Accept
|
| 1635 | Hierarchical Channel-spatial Encoding for Communication-efficient Collaborative Learning | 5.75 | | Accept
|
| 1636 | Retrospective Adversarial Replay for Continual Learning | 5.25 | | Accept
|
| 1637 | LTMD: Learning Improvement of Spiking Neural Networks with Learnable Thresholding Neurons and Moderate Dropout | 5.00 | | Accept
|
| 1638 | Benign Underfitting of Stochastic Gradient Descent | 5.75 | | Accept
|
| 1639 | Equivariant Graph Hierarchy-Based Neural Networks | 6.67 | | Accept
|
| 1640 | Learning Neural Set Functions Under the Optimal Subset Oracle | 7.20 | | Accept
|
| 1641 | Conditional Independence Testing with Heteroskedastic Data and Applications to Causal Discovery | 6.33 | | Accept
|
| 1642 | Molecule Generation by Principal Subgraph Mining and Assembling | 6.33 | | Accept
|
| 1643 | Receding Horizon Inverse Reinforcement Learning | 5.50 | | Accept
|
| 1644 | AgraSSt: Approximate Graph Stein Statistics for Interpretable Assessment of Implicit Graph Generators | 6.50 | | Accept
|
| 1645 | First is Better Than Last for Language Data Influence | 6.33 | | Accept
|
| 1646 | Learning to Share in Multi-Agent Reinforcement Learning | 5.67 | | Accept
|
| 1647 | EF-BV: A Unified Theory of Error Feedback and Variance Reduction Mechanisms for Biased and Unbiased Compression in Distributed Optimization | 5.67 | | Accept
|
| 1648 | Improving Generative Adversarial Networks via Adversarial Learning in Latent Space | 5.75 | | Accept
|
| 1649 | Self-supervised Amodal Video Object Segmentation | 6.50 | | Accept
|
| 1650 | SwinTrack: A Simple and Strong Baseline for Transformer Tracking | 6.50 | | Accept
|
| 1651 | MaskPlace: Fast Chip Placement via Reinforced Visual Representation Learning | 6.00 | | Accept
|
| 1652 | Mask-based Latent Reconstruction for Reinforcement Learning | 5.75 | | Accept
|
| 1653 | Debugging and Explaining Metric Learning Approaches: An Influence Function Based Perspective | 5.67 | | Accept
|
| 1654 | Unsupervised Skill Discovery via Recurrent Skill Training | 5.33 | | Accept
|
| 1655 | Convolutional Neural Networks on Graphs with Chebyshev Approximation, Revisited | 6.67 | | Accept
|
| 1656 | Gradient Methods Provably Converge to Non-Robust Networks | 6.50 | | Accept
|
| 1657 | TA-GATES: An Encoding Scheme for Neural Network Architectures | 5.67 | | Accept
|
| 1658 | PaCo: Parameter-Compositional Multi-task Reinforcement Learning | 5.67 | | Accept
|
| 1659 | NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis | 5.75 | | Accept
|
| 1660 | Multi-Objective Online Learning | 5.25 | | Reject
|
| 1661 | A Differentiable Semantic Metric Approximation in Probabilistic Embedding for Cross-Modal Retrieval | 6.25 | | Accept
|
| 1662 | Para-CFlows: $C^k$-universal diffeomorphism approximators as superior neural surrogates | 6.33 | | Accept
|
| 1663 | Learning Contrastive Embedding in Low-Dimensional Space | 5.50 | | Accept
|
| 1664 | Improving Transformer with an Admixture of Attention Heads | 6.67 | | Accept
|
| 1665 | On the Theoretical Properties of Noise Correlation in Stochastic Optimization | 6.00 | | Accept
|
| 1666 | Temporally Disentangled Representation Learning | 5.75 | | Accept
|
| 1667 | Robust Rent Division | 7.50 | | Accept
|
| 1668 | Truncated Matrix Power Iteration for Differentiable DAG Learning | 6.00 | | Accept
|
| 1669 | Semantic Field of Words Represented as Non-Linear Functions | 5.00 | | Accept
|
| 1670 | VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training | 6.00 | | Accept
|
| 1671 | Most Activation Functions Can Win the Lottery Without Excessive Depth | 4.67 | | Accept
|
| 1672 | Debiased, Longitudinal and Coordinated Drug Recommendation through Multi-Visit Clinic Records | 6.00 | | Accept
|
| 1673 | On the Double Descent of Random Features Models Trained with SGD | 5.75 | | Accept
|
| 1674 | Knowledge Distillation from A Stronger Teacher | 6.00 | | Accept
|
| 1675 | Generic bounds on the approximation error for physics-informed (and) operator learning | 5.67 | | Accept
|
| 1676 | Perceptual Attacks of No-Reference Image Quality Models with Human-in-the-Loop | 6.00 | | Accept
|
| 1677 | Refining Low-Resource Unsupervised Translation by Language Disentanglement of Multilingual Translation Model | 6.00 | | Accept
|
| 1678 | GT-GAN: General Purpose Time Series Synthesis with Generative Adversarial Networks | 6.33 | | Accept
|
| 1679 | Fair Wrapping for Black-box Predictions | 4.67 | | Accept
|
| 1680 | Fast Instrument Learning with Faster Rates | 6.20 | | Accept
|
| 1681 | Double Check Your State Before Trusting It: Confidence-Aware Bidirectional Offline Model-Based Imagination | 6.33 | | Accept
|
| 1682 | Bootstrapped Transformer for Offline Reinforcement Learning | 5.67 | | Accept
|
| 1683 | Towards Skill and Population Curriculum for MARL | 3.75 | | Reject
|
| 1684 | Learning from Distributed Users in Contextual Linear Bandits Without Sharing the Context | 6.00 | | Accept
|
| 1685 | Self-explaining deep models with logic rule reasoning | 6.25 | | Accept
|
| 1686 | Action-modulated midbrain dopamine activity arises from distributed control policies | 6.67 | | Accept
|
| 1687 | Causal Inference with Non-IID Data using Linear Graphical Models | 5.33 | | Accept
|
| 1688 | Off-Beat Multi-Agent Reinforcement Learning | 5.25 | | Reject
|
| 1689 | On the Importance of Gradient Norm in PAC-Bayesian Bounds | 6.00 | | Accept
|
| 1690 | What are the best Systems? New Perspectives on NLP Benchmarking | 5.33 | | Accept
|
| 1691 | Autoinverse: Uncertainty Aware Inversion of Neural Networks | 6.67 | | Accept
|
| 1692 | Factorized-FL: Personalized Federated Learning with Parameter Factorization & Similarity Matching | 5.75 | | Accept
|
| 1693 | Learning a Condensed Frame for Memory-Efficient Video Class-Incremental Learning | 6.00 | | Accept
|
| 1694 | FINDE: Neural Differential Equations for Finding and Preserving Invariant Quantities | 6.00 | | Reject
|
| 1695 | Towards Effective and Interpretable Human-AI Collaboration in MOBA Games | 4.50 | | Reject
|
| 1696 | OGC: Unsupervised 3D Object Segmentation from Rigid Dynamics of Point Clouds | 6.50 | | Accept
|
| 1697 | Grow and Merge: A Unified Framework for Continuous Categories Discovery | 5.67 | | Accept
|
| 1698 | Factuality Enhanced Language Models for Open-Ended Text Generation | 5.50 | | Accept
|
| 1699 | Domain Generalization by Learning and Removing Domain-specific Features | 6.00 | | Accept
|
| 1700 | To update or not to update? Neurons at equilibrium in deep models | 5.50 | | Accept
|
| 1701 | Leveraging Inter-Layer Dependency for Post -Training Quantization | 5.25 | | Accept
|
| 1702 | Zeroth-Order Hard-Thresholding: Gradient Error vs. Expansivity | 7.00 | | Accept
|
| 1703 | Multi-view Subspace Clustering on Topological Manifold | 6.67 | | Accept
|
| 1704 | Globally Convergent Policy Search for Output Estimation | 6.80 | | Accept
|
| 1705 | Learning Distributions Generated by Single-Layer ReLU Networks in the Presence of Arbitrary Outliers | 5.67 | | Accept
|
| 1706 | Why do We Need Large Batchsizes in Contrastive Learning? A Gradient-Bias Perspective | 6.00 | | Accept
|
| 1707 | Follow-the-Perturbed-Leader for Adversarial Markov Decision Processes with Bandit Feedback | 7.00 | | Accept
|
| 1708 | Knowledge-Consistent Dialogue Generation with Knowledge Graphs | 4.33 | | Reject
|
| 1709 | Efficient Phi-Regret Minimization in Extensive-Form Games via Online Mirror Descent | 7.33 | | Accept
|
| 1710 | The Sample Complexity of One-Hidden-Layer Neural Networks | 6.50 | | Accept
|
| 1711 | Functional Ensemble Distillation | 6.25 | | Accept
|
| 1712 | Provable Benefit of Multitask Representation Learning in Reinforcement Learning | 6.33 | | Accept
|
| 1713 | GAGA: Deciphering Age-path of Generalized Self-paced Regularizer | 6.50 | | Accept
|
| 1714 | A High Performance and Low Latency Deep Spiking Neural Networks Conversion Framework | 3.00 | | Reject
|
| 1715 | Learn to Match with No Regret: Reinforcement Learning in Markov Matching Markets | 6.75 | | Accept
|
| 1716 | Provable Generalization of Overparameterized Meta-learning Trained with SGD | 6.00 | | Accept
|
| 1717 | Accelerated Linearized Laplace Approximation for Bayesian Deep Learning | 6.00 | | Accept
|
| 1718 | Alleviating the Sample Selection Bias in Few-shot Learning by Removing Projection to the Centroid | 5.50 | | Accept
|
| 1719 | Proximal Learning With Opponent-Learning Awareness | 6.00 | | Accept
|
| 1720 | Explaining a Reinforcement Learning Agent via Prototyping | 6.00 | | Accept
|
| 1721 | Secure Split Learning against Property Inference and Data Reconstruction Attacks | 5.00 | | Reject
|
| 1722 | ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers | 6.00 | | Accept
|
| 1723 | Distributional Reinforcement Learning via Sinkhorn Iterations | 5.75 | | Reject
|
| 1724 | Symbolic Distillation for Learned TCP Congestion Control | 5.50 | | Accept
|
| 1725 | Accelerating Sparse Convolution with Column Vector-Wise Sparsity | 6.00 | | Accept
|
| 1726 | Generalization Bounds for Stochastic Gradient Descent via Localized $\varepsilon$-Covers | 6.60 | | Accept
|
| 1727 | Pyramid Attention For Source Code Summarization | 5.50 | | Accept
|
| 1728 | When to Trust Your Simulator: Dynamics-Aware Hybrid Offline-and-Online Reinforcement Learning | 5.33 | | Accept
|
| 1729 | FasterRisk: Fast and Accurate Interpretable Risk Scores | 6.75 | | Accept
|
| 1730 | Taming Fat-Tailed (“Heavier-Tailed” with Potentially Infinite Variance) Noise in Federated Learning | 5.50 | | Accept
|
| 1731 | FreGAN: Exploiting Frequency Components for Training GANs under Limited Data | 5.33 | | Accept
|
| 1732 | Momentum Adversarial Distillation: Handling Large Distribution Shifts in Data-Free Knowledge Distillation | 5.50 | | Accept
|
| 1733 | A Simple and Provably Efficient Algorithm for Asynchronous Federated Contextual Linear Bandits | 5.67 | | Accept
|
| 1734 | On Divergence Measures for Bayesian Pseudocoresets | 6.00 | | Accept
|
| 1735 | Domain Adaptation under Open Set Label Shift | 6.00 | | Accept
|
| 1736 | Robust Bayesian Regression via Hard Thresholding | 6.00 | | Accept
|
| 1737 | A Closer Look at the Adversarial Robustness of Deep Equilibrium Models | 5.33 | | Accept
|
| 1738 | Continual learning: a feature extraction formalization, an efficient algorithm, and fundamental obstructions | 5.75 | | Accept
|
| 1739 | DigGAN: Discriminator gradIent Gap Regularization for GAN Training with Limited Data | 5.67 | | Accept
|
| 1740 | Tiered Reinforcement Learning: Pessimism in the Face of Uncertainty and Constant Regret | 6.25 | | Accept
|
| 1741 | DEQGAN: Learning the Loss Function for PINNs with Generative Adversarial Networks | 5.67 | | Reject
|
| 1742 | GenerSpeech: Towards Style Transfer for Generalizable Out-Of-Domain Text-to-Speech | 6.00 | | Accept
|
| 1743 | Improving Task-Specific Generalization in Few-Shot Learning via Adaptive Vicinal Risk Minimization | 5.50 | | Accept
|
| 1744 | Two-Stream Network for Sign Language Recognition and Translation | 7.00 | | Accept
|
| 1745 | Characteristic Neural Ordinary Differential Equations | 5.67 | | Reject
|
| 1746 | Pre-Trained Image Encoder for Generalizable Visual Reinforcement Learning | 5.33 | | Accept
|
| 1747 | Graphical Resource Allocation with Matching-Induced Utilities | 5.00 | | Reject
|
| 1748 | Test Time Adaptation via Conjugate Pseudo-labels | 7.25 | | Accept
|
| 1749 | TANKBind: Trigonometry-Aware Neural NetworKs for Drug-Protein Binding Structure Prediction | 5.67 | | Accept
|
| 1750 | Reconstruction on Trees and Low-Degree Polynomials | 6.75 | | Accept
|
| 1751 | Discovering Design Concepts for CAD Sketches | 6.75 | | Accept
|
| 1752 | HyperMiner: Topic Taxonomy Mining with Hyperbolic Embedding | 6.33 | | Accept
|
| 1753 | Learning Manifold Dimensions with Conditional Variational Autoencoders | 5.67 | | Accept
|
| 1754 | APG: Adaptive Parameter Generation Network for Click-Through Rate Prediction | 5.75 | | Accept
|
| 1755 | On the Effective Number of Linear Regions in Shallow Univariate ReLU Networks: Convergence Guarantees and Implicit Bias | 7.00 | | Accept
|
| 1756 | DNA: Proximal Policy Optimization with a Dual Network Architecture | 6.67 | | Accept
|
| 1757 | Self-Organized Group for Cooperative Multi-agent Reinforcement Learning | 6.00 | | Accept
|
| 1758 | MaskTune: Mitigating Spurious Correlations by Forcing to Explore | 6.50 | | Accept
|
| 1759 | House of Cans: Covert Transmission of Internal Datasets via Capacity-Aware Neuron Steganography | 6.00 | | Accept
|
| 1760 | Mirror Descent Maximizes Generalized Margin and Can Be Implemented Efficiently | 6.25 | | Accept
|
| 1761 | DIMES: A Differentiable Meta Solver for Combinatorial Optimization Problems | 5.50 | | Accept
|
| 1762 | LOG: Active Model Adaptation for Label-Efficient OOD Generalization | 6.50 | | Accept
|
| 1763 | Neuron with Steady Response Leads to Better Generalization | 6.33 | | Accept
|
| 1764 | Improved Feature Distillation via Projector Ensemble | 5.20 | | Accept
|
| 1765 | ConfounderGAN: Protecting Image Data Privacy with Causal Confounder | 7.00 | | Accept
|
| 1766 | A Fast Post-Training Pruning Framework for Transformers | 6.25 | | Accept
|
| 1767 | Controllable Text Generation with Neurally-Decomposed Oracle | 7.00 | | Accept
|
| 1768 | Moderate-fitting as a Natural Backdoor Defender for Pre-trained Language Models | 6.00 | | Accept
|
| 1769 | Unsupervised Learning of Shape Programs with Repeatable Implicit Parts | 6.00 | | Accept
|
| 1770 | Efficient Active Learning with Abstention | 6.00 | | Accept
|
| 1771 | Brownian Noise Reduction: Maximizing Privacy Subject to Accuracy Constraints | 6.50 | | Accept
|
| 1772 | Make an Omelette with Breaking Eggs: Zero-Shot Learning for Novel Attribute Synthesis | 5.50 | | Accept
|
| 1773 | All Politics is Local: Redistricting via Local Fairness | 5.00 | | Accept
|
| 1774 | Adaptive Oracle-Efficient Online Learning | 6.25 | | Accept
|
| 1775 | Neural Collapse with Normalized Features: A Geometric Analysis over the Riemannian Manifold | 5.67 | | Accept
|
| 1776 | Zero-Shot 3D Drug Design by Sketching and Generating | 5.67 | | Accept
|
| 1777 | Why neural networks find simple solutions: The many regularizers of geometric complexity | 6.67 | | Accept
|
| 1778 | Multiclass Learnability Beyond the PAC Framework: Universal Rates and Partial Concept Classes | 6.67 | | Accept
|
| 1779 | Diagonal State Spaces are as Effective as Structured State Spaces | 6.67 | | Accept
|
| 1780 | MetaTeacher: Coordinating Multi-Model Domain Adaptation for Medical Image Classification | 5.33 | | Accept
|
| 1781 | Privacy of Noisy Stochastic Gradient Descent: More Iterations without More Privacy Loss | 6.50 | | Accept
|
| 1782 | Block-Recurrent Transformers | 6.00 | | Accept
|
| 1783 | Markovian Interference in Experiments | 7.00 | | Accept
|
| 1784 | DP-PCA: Statistically Optimal and Differentially Private PCA | 7.00 | | Accept
|
| 1785 | Differentially Private Learning with Margin Guarantees | 6.25 | | Accept
|
| 1786 | Oracle-Efficient Online Learning for Smoothed Adversaries | 7.50 | | Accept
|
| 1787 | Systematic improvement of neural network quantum states using Lanczos | 5.50 | | Accept
|
| 1788 | Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering | 6.40 | | Accept
|
| 1789 | Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning | 6.25 | | Accept
|
| 1790 | Reproducibility in Optimization: Theoretical Framework and Limits | 7.00 | | Accept
|
| 1791 | Unsupervised Image-to-Image Translation with Density Changing Regularization | 5.25 | | Accept
|
| 1792 | Network change point localisation under local differential privacy | 6.00 | | Accept
|
| 1793 | Annihilation of Spurious Minima in Two-Layer ReLU Networks | 5.75 | | Accept
|
| 1794 | Will Bilevel Optimizers Benefit from Loops | 6.25 | | Accept
|
| 1795 | Algorithms that Approximate Data Removal: New Results and Limitations | 6.00 | | Accept
|
| 1796 | Online Minimax Multiobjective Optimization: Multicalibeating and Other Applications | 7.33 | | Accept
|
| 1797 | No-regret learning in games with noisy feedback: Faster rates and adaptivity via learning rate separation | 7.00 | | Accept
|
| 1798 | Physics-Embedded Neural Networks: Graph Neural PDE Solvers with Mixed Boundary Conditions | 6.25 | | Accept
|
| 1799 | On Scalable Testing of Samplers | 6.00 | | Accept
|
| 1800 | A Best-of-Both-Worlds Algorithm for Bandits with Delayed Feedback | 6.33 | | Accept
|
| 1801 | Lower Bounds on Randomly Preconditioned Lasso via Robust Sparse Designs | 6.50 | | Accept
|
| 1802 | CLIPDraw: Exploring Text-to-Drawing Synthesis through Language-Image Encoders | 6.67 | | Accept
|
| 1803 | Pre-Trained Language Models for Interactive Decision-Making | 7.00 | | Accept
|
| 1804 | Diffusion-based Molecule Generation with Informative Prior Bridges | 6.33 | | Accept
|
| 1805 | Learning from Stochastically Revealed Preference | 6.00 | | Accept
|
| 1806 | When does dough become a bagel? Analyzing the remaining mistakes on ImageNet | 5.67 | | Accept
|
| 1807 | Scalable Sensitivity and Uncertainty Analyses for Causal-Effect Estimates of Continuous-Valued Interventions | 7.25 | | Accept
|
| 1808 | On the convergence of policy gradient methods to Nash equilibria in general stochastic games | 6.50 | | Accept
|
| 1809 | Semi-Supervised Learning with Decision Trees: Graph Laplacian Tree Alternating Optimization | 6.50 | | Accept
|
| 1810 | You Only Live Once: Single-Life Reinforcement Learning | 5.50 | | Accept
|
| 1811 | Neural Circuit Architectural Priors for Embodied Control | 5.00 | | Accept
|
| 1812 | Micro and Macro Level Graph Modeling for Graph Variational Auto-Encoders | 5.50 | | Accept
|
| 1813 | Conformal Frequency Estimation with Sketched Data | 5.67 | | Accept
|
| 1814 | A Single-timescale Analysis for Stochastic Approximation with Multiple Coupled Sequences | 7.00 | | Accept
|
| 1815 | Reconstructing Training Data From Trained Neural Networks | 6.50 | | Accept
|
| 1816 | Redeeming intrinsic rewards via constrained policy optimization | 7.33 | | Accept
|
| 1817 | S-PIFu: Integrating Parametric Human Models with PIFu for Single-view Clothed Human Reconstruction | 4.33 | | Accept
|
| 1818 | Use-Case-Grounded Simulations for Explanation Evaluation | 6.25 | | Accept
|
| 1819 | LIFT: Language-Interfaced Fine-Tuning for Non-language Machine Learning Tasks | 6.25 | | Accept
|
| 1820 | Class-Aware Adversarial Transformers for Medical Image Segmentation | 5.67 | | Accept
|
| 1821 | SALSA: Attacking Lattice Cryptography with Transformers | 5.75 | | Accept
|
| 1822 | Robust Imitation via Mirror Descent Inverse Reinforcement Learning | 5.00 | | Accept
|
| 1823 | Near-Optimal Randomized Exploration for Tabular Markov Decision Processes | 6.25 | | Accept
|
| 1824 | TTOpt: A Maximum Volume Quantized Tensor Train-based Optimization and its Application to Reinforcement Learning | 6.00 | | Accept
|
| 1825 | RKHS-SHAP: Shapley Values for Kernel Methods | 5.67 | | Accept
|
| 1826 | GREED: A Neural Framework for Learning Graph Distance Functions | 6.00 | | Accept
|
| 1827 | Context-Based Dynamic Pricing with Partially Linear Demand Model | 6.25 | | Accept
|
| 1828 | Target alignment in truncated kernel ridge regression | 6.25 | | Accept
|
| 1829 | Bridging the Gap: Unifying the Training and Evaluation of Neural Network Binary Classifiers | 5.75 | | Accept
|
| 1830 | Uncertainty Estimation Using Riemannian Model Dynamics for Offline Reinforcement Learning | 6.33 | | Accept
|
| 1831 | Adversarial Unlearning: Reducing Confidence Along Adversarial Directions | 6.50 | | Accept
|
| 1832 | Queue Up Your Regrets: Achieving the Dynamic Capacity Region of Multiplayer Bandits | 6.00 | | Accept
|
| 1833 | High-Order Pooling for Graph Neural Networks with Tensor Decomposition | 6.00 | | Accept
|
| 1834 | Imitating Past Successes can be Very Suboptimal | 6.67 | | Accept
|
| 1835 | Bivariate Causal Discovery for Categorical Data via Classification with Optimal Label Permutation | 5.00 | | Accept
|
| 1836 | Joint Model-Policy Optimization of a Lower Bound for Model-Based RL | 7.25 | | Accept
|
| 1837 | TabNAS: Rejection Sampling for Neural Architecture Search on Tabular Datasets | 6.00 | | Accept
|
| 1838 | SAPD+: An Accelerated Stochastic Method for Nonconvex-Concave Minimax Problems | 6.00 | | Accept
|
| 1839 | Procedural Image Programs for Representation Learning | 4.67 | | Accept
|
| 1840 | Online Agnostic Multiclass Boosting | 6.25 | | Accept
|
| 1841 | Momentum Aggregation for Private Non-convex ERM | 6.00 | | Accept
|
| 1842 | Earthformer: Exploring Space-Time Transformers for Earth System Forecasting | 5.25 | | Accept
|
| 1843 | Augmentations in Hypergraph Contrastive Learning: Fabricated and Generative | 5.33 | | Accept
|
| 1844 | Data Augmentation MCMC for Bayesian Inference from Privatized Data | 5.00 | | Accept
|
| 1845 | Improving Zero-Shot Generalization in Offline Reinforcement Learning using Generalized Similarity Functions | 5.67 | | Accept
|
| 1846 | Learning to Attack Federated Learning: A Model-based Reinforcement Learning Attack Framework | 5.75 | | Accept
|
| 1847 | Communication-efficient distributed eigenspace estimation with arbitrary node failures | 6.00 | | Accept
|
| 1848 | Weighted Mutual Learning with Diversity-Driven Model Compression | 5.75 | | Accept
|
| 1849 | NeuForm: Adaptive Overfitting for Neural Shape Editing | 7.33 | | Accept
|
| 1850 | Non-stationary Bandits with Knapsacks | 5.00 | | Accept
|
| 1851 | SKFlow: Learning Optical Flow with Super Kernels | 6.25 | | Accept
|
| 1852 | Towards Understanding Grokking: An Effective Theory of Representation Learning | 6.67 | | Accept
|
| 1853 | Dynamic Sparse Network for Time Series Classification: Learning What to “See” | 5.00 | | Accept
|
| 1854 | Smooth Fictitious Play in Stochastic Games with Perturbed Payoffs and Unknown Transitions | 6.40 | | Accept
|
| 1855 | Uncertainty-Aware Reinforcement Learning for Risk-Sensitive Player Evaluation in Sports Game | 5.33 | | Accept
|
| 1856 | Doubly Robust Counterfactual Classification | 6.00 | | Accept
|
| 1857 | Manifold Interpolating Optimal-Transport Flows for Trajectory Inference | 5.75 | | Accept
|
| 1858 | Local-Global MCMC kernels: the best of both worlds | 6.67 | | Accept
|
| 1859 | InsNet: An Efficient, Flexible, and Performant Insertion-based Text Generation Model | 5.50 | | Accept
|
| 1860 | Accelerated Projected Gradient Algorithms for Sparsity Constrained Optimization Problems | 6.50 | | Accept
|
| 1861 | Provably sample-efficient RL with side information about latent dynamics | 6.50 | | Accept
|
| 1862 | Differentially Private Online-to-batch for Smooth Losses | 5.33 | | Accept
|
| 1863 | UniCLIP: Unified Framework for Contrastive Language-Image Pre-training | 5.50 | | Accept
|
| 1864 | Structured Recognition for Generative Models with Explaining Away | 6.00 | | Accept
|
| 1865 | LiteTransformerSearch: Training-free Neural Architecture Search for Efficient Language Models | 5.50 | | Accept
|
| 1866 | Adversarial Reprogramming Revisited | 6.33 | | Accept
|
| 1867 | Scalable and Efficient Training of Large Convolutional Neural Networks with Differential Privacy | 6.33 | | Accept
|
| 1868 | Stochastic Second-Order Methods Improve Best-Known Sample Complexity of SGD for Gradient-Dominated Functions | 5.75 | | Accept
|
| 1869 | GENIE: Higher-Order Denoising Diffusion Solvers | 7.25 | | Accept
|
| 1870 | Automatic Clipping: Differentially Private Deep Learning Made Easy and Stronger | 4.75 | | Reject
|
| 1871 | First-Order Algorithms for Min-Max Optimization in Geodesic Metric Spaces | 6.20 | | Accept
|
| 1872 | u-HuBERT: Unified Mixed-Modal Speech Pretraining And Zero-Shot Transfer to Unlabeled Modality | 5.50 | | Accept
|
| 1873 | Efficient and Effective Augmentation Strategy for Adversarial Training | 6.00 | | Accept
|
| 1874 | Efficient Sampling on Riemannian Manifolds via Langevin MCMC | 7.25 | | Accept
|
| 1875 | A Direct Approximation of AIXI Using Logical State Abstractions | 5.67 | | Accept
|
| 1876 | Instance-based Learning for Knowledge Base Completion | 5.50 | | Accept
|
| 1877 | ATD: Augmenting CP Tensor Decomposition by Self Supervision | 6.00 | | Accept
|
| 1878 | AniFaceGAN: Animatable 3D-Aware Face Image Generation for Video Avatars | 4.75 | | Accept
|
| 1879 | Depth is More Powerful than Width with Prediction Concatenation in Deep Forest | 6.67 | | Accept
|
| 1880 | On the Word Boundaries of Emergent Languages Based on Harris's Articulation Scheme | 6.33 | | Reject
|
| 1881 | Dance of SNN and ANN: Solving binding problem by combining spike timing and reconstructive attention | 5.75 | | Accept
|
| 1882 | Direct Advantage Estimation | 6.50 | | Accept
|
| 1883 | Expectation-Maximization Contrastive Learning for Compact Video-and-Language Representations | 5.50 | | Accept
|
| 1884 | Adversarial Task Up-sampling for Meta-learning | 5.50 | | Accept
|
| 1885 | A Unifying Framework for Online Optimization with Long-Term Constraints | 6.00 | | Accept
|
| 1886 | Masked Prediction: A Parameter Identifiability View | 6.50 | | Accept
|
| 1887 | Tabular data imputation: quality over quantity | 3.33 | | Reject
|
| 1888 | ST-Adapter: Parameter-Efficient Image-to-Video Transfer Learning | 5.75 | | Accept
|
| 1889 | Exact Solutions of a Deep Linear Network | 6.00 | | Accept
|
| 1890 | Constrained Predictive Coding as a Biologically Plausible Model of the Cortical Hierarchy | 5.67 | | Accept
|
| 1891 | SCL-WC: Cross-Slide Contrastive Learning for Weakly-Supervised Whole-Slide Image Classification | 5.50 | | Accept
|
| 1892 | VRL3: A Data-Driven Framework for Visual Deep Reinforcement Learning | 4.75 | | Accept
|
| 1893 | Renyi Differential Privacy of Propose-Test-Release and Applications to Private and Robust Machine Learning | 5.50 | | Accept
|
| 1894 | Towards Diverse and Faithful One-shot Adaption of Generative Adversarial Networks | 6.25 | | Accept
|
| 1895 | Does Momentum Change the Implicit Regularization on Separable Data? | 6.25 | | Accept
|
| 1896 | Can Push-forward Generative Models Fit Multimodal Distributions? | 5.60 | | Accept
|
| 1897 | DualCoOp: Fast Adaptation to Multi-Label Recognition with Limited Annotations | 5.50 | | Accept
|
| 1898 | When Adversarial Training Meets Vision Transformers: Recipes from Training to Architecture | 6.00 | | Accept
|
| 1899 | Block-wise Separable Convolutions: An Alternative Way to Factorize Standard Convolutions | 4.33 | | Reject
|
| 1900 | Conservative Dual Policy Optimization for Efficient Model-Based Reinforcement Learning | 6.00 | | Accept
|
| 1901 | Efficient Submodular Optimization under Noise: Local Search is Robust | 6.33 | | Accept
|
| 1902 | Egocentric Video-Language Pretraining | 5.25 | | Accept
|
| 1903 | Generalised Implicit Neural Representations | 6.33 | | Accept
|
| 1904 | Few-shot Image Generation via Adaptation-Aware Kernel Modulation | 6.33 | | Accept
|
| 1905 | Look Around and Refer: 2D Synthetic Semantics Knowledge Distillation for 3D Visual Grounding | 5.50 | | Accept
|
| 1906 | Wavelet Score-Based Generative Modeling | 6.67 | | Accept
|
| 1907 | Self-supervised Heterogeneous Graph Pre-training Based on Structural Clustering | 5.25 | | Accept
|
| 1908 | Improving 3D-aware Image Synthesis with A Geometry-aware Discriminator | 5.25 | | Accept
|
| 1909 | Estimating graphical models for count data with applications to single-cell gene network | 6.67 | | Accept
|
| 1910 | Policy Gradient With Serial Markov Chain Reasoning | 7.00 | | Accept
|
| 1911 | Towards Effective Multi-Modal Interchanges in Zero-Resource Sounding Object Localization | 5.50 | | Accept
|
| 1912 | Out-of-Distribution Detection via Conditional Kernel Independence Model | 5.75 | | Accept
|
| 1913 | Riemannian Score-Based Generative Modelling | 7.50 | | Accept
|
| 1914 | Gradient Descent: The Ultimate Optimizer | 6.67 | | Accept
|
| 1915 | Contextual Squeeze-and-Excitation for Efficient Few-Shot Image Classification | 6.00 | | Accept
|
| 1916 | Perturbation Learning Based Anomaly Detection | 5.67 | | Accept
|
| 1917 | Incorporating Bias-aware Margins into Contrastive Loss for Collaborative Filtering | 5.67 | | Accept
|
| 1918 | Module-Aware Optimization for Auxiliary Learning | 6.00 | | Accept
|
| 1919 | A Classification of $G$-invariant Shallow Neural Networks | 6.00 | | Accept
|
| 1920 | Improved Utility Analysis of Private CountSketch | 6.67 | | Accept
|
| 1921 | Hierarchical Graph Transformer with Adaptive Node Sampling | 5.50 | | Accept
|
| 1922 | Self-Supervised Learning with an Information Maximization Criterion | 5.50 | | Accept
|
| 1923 | Transcormer: Transformer for Sentence Scoring with Sliding Language Modeling | 5.00 | | Accept
|
| 1924 | LogiGAN: Learning Logical Reasoning via Adversarial Pre-training | 5.75 | | Accept
|
| 1925 | Deep Combinatorial Aggregation | 5.33 | | Accept
|
| 1926 | Revisiting Realistic Test-Time Training: Sequential Inference and Adaptation by Anchored Clustering | 6.25 | | Accept
|
| 1927 | Museformer: Transformer with Fine- and Coarse-Grained Attention for Music Generation | 5.50 | | Accept
|
| 1928 | Theoretically Provable Spiking Neural Networks | 6.00 | | Accept
|
| 1929 | Trading Off Resource Budgets For Improved Regret Bounds | 5.50 | | Accept
|
| 1930 | Transformers meet Stochastic Block Models: Attention with Data-Adaptive Sparsity and Cost | 6.00 | | Accept
|
| 1931 | Outsourcing Training without Uploading Data via Efficient Collaborative Open-Source Sampling | 6.20 | | Accept
|
| 1932 | Understanding the Failure of Batch Normalization for Transformers in NLP | 5.67 | | Accept
|
| 1933 | Unsupervised Visual Representation Learning via Mutual Information Regularized Assignment | 7.00 | | Accept
|
| 1934 | Pure Transformers are Powerful Graph Learners | 6.00 | | Accept
|
| 1935 | Differentiable hierarchical and surrogate gradient search for spiking neural networks | 6.25 | | Accept
|
| 1936 | TA-MoE: Topology-Aware Large Scale Mixture-of-Expert Training | 5.33 | | Accept
|
| 1937 | DetCLIP: Dictionary-Enriched Visual-Concept Paralleled Pre-training for Open-world Detection | 6.00 | | Accept
|
| 1938 | On the Identifiability of Nonlinear ICA: Sparsity and Beyond | 7.33 | | Accept
|
| 1939 | Transfer Learning on Heterogeneous Feature Spaces for Treatment Effects Estimation | 6.33 | | Accept
|
| 1940 | BR-SNIS: Bias Reduced Self-Normalized Importance Sampling | 5.50 | | Accept
|
| 1941 | Where to Pay Attention in Sparse Training for Feature Selection? | 6.75 | | Accept
|
| 1942 | A Continuous Time Framework for Discrete Denoising Models | 7.00 | | Accept
|
| 1943 | AD-DROP: Attribution-Driven Dropout for Robust Language Model Fine-Tuning | 5.50 | | Accept
|
| 1944 | Verification and search algorithms for causal DAGs | 5.67 | | Accept
|
| 1945 | Hyperbolic Feature Augmentation via Distribution Estimation and Infinite Sampling on Manifolds | 6.00 | | Accept
|
| 1946 | TokenMixup: Efficient Attention-guided Token-level Data Augmentation for Transformers | 6.25 | | Accept
|
| 1947 | IM-Loss: Information Maximization Loss for Spiking Neural Networks | 5.75 | | Accept
|
| 1948 | Operator-Discretized Representation for Temporal Neural Networks | 3.25 | | Reject
|
| 1949 | Could Giant Pre-trained Image Models Extract Universal Representations? | 5.00 | | Accept
|
| 1950 | Searching for Better Spatio-temporal Alignment in Few-Shot Action Recognition | 6.33 | | Accept
|
| 1951 | Relation-Constrained Decoding for Text Generation | 5.50 | | Accept
|
| 1952 | Margin-Based Few-Shot Class-Incremental Learning with Class-Level Overfitting Mitigation | 5.67 | | Accept
|
| 1953 | Zeroth-Order Negative Curvature Finding: Escaping Saddle Points without Gradients | 6.50 | | Accept
|
| 1954 | Latency-aware Spatial-wise Dynamic Networks | 6.00 | | Accept
|
| 1955 | Learning to Break the Loop: Analyzing and Mitigating Repetitions for Neural Text Generation | 6.33 | | Accept
|
| 1956 | Toward a realistic model of speech processing in the brain with self-supervised learning | 6.00 | | Accept
|
| 1957 | Multi-layer State Evolution Under Random Convolutional Design | 6.75 | | Accept
|
| 1958 | Learning Robust Rule Representations for Abstract Reasoning via Internal Inferences | 6.60 | | Accept
|
| 1959 | CalFAT: Calibrated Federated Adversarial Training with Label Skewness | 5.33 | | Accept
|
| 1960 | Eliciting Thinking Hierarchy without a Prior | 6.00 | | Accept
|
| 1961 | GBA: A Tuning-free Approach to Switch between Synchronous and Asynchronous Training for Recommendation Models | 6.33 | | Accept
|
| 1962 | Online Neural Sequence Detection with Hierarchical Dirichlet Point Process | 5.50 | | Accept
|
| 1963 | Iterative Scene Graph Generation | 4.33 | | Accept
|
| 1964 | Low-rank Optimal Transport: Approximation, Statistics and Debiasing | 7.00 | | Accept
|
| 1965 | Fast Distance Oracles for Any Symmetric Norm | 5.75 | | Accept
|
| 1966 | Towards Hard-pose Virtual Try-on via 3D-aware Global Correspondence Learning | 5.75 | | Accept
|
| 1967 | Learning Causally Invariant Representations for Out-of-Distribution Generalization on Graphs | 6.00 | | Accept
|
| 1968 | Ultra-marginal Feature Importance | 7.00 | | Reject
|
| 1969 | Non-Linear Coordination Graphs | 7.00 | | Accept
|
| 1970 | ComGAN: Unsupervised Disentanglement and Segmentation via Image Composition | 6.00 | | Accept
|
| 1971 | Homomorphic Matrix Completion | 5.33 | | Accept
|
| 1972 | Cluster Randomized Designs for One-Sided Bipartite Experiments | 6.00 | | Accept
|
| 1973 | Multimodal Contrastive Learning with LIMoE: the Language-Image Mixture of Experts | 7.00 | | Accept
|
| 1974 | Node-oriented Spectral Filtering for Graph Neural Networks | 5.50 | | Reject
|
| 1975 | EGRU: Event-based GRU for activity-sparse inference and learning | 5.67 | | Reject
|
| 1976 | Structure-Preserving 3D Garment Modeling with Neural Sewing Machines | 5.75 | | Accept
|
| 1977 | Improved Bounds on Neural Complexity for Representing Piecewise Linear Functions | 6.33 | | Accept
|
| 1978 | Learning Graph-embedded Key-event Back-tracing for Object Tracking in Event Clouds | 5.00 | | Accept
|
| 1979 | OrdinalCLIP: Learning Rank Prompts for Language-Guided Ordinal Regression | 5.67 | | Accept
|
| 1980 | Unsupervised learning of features and object boundaries from local prediction | 6.00 | | Reject
|
| 1981 | Amortized Projection Optimization for Sliced Wasserstein Generative Models | 6.00 | | Accept
|
| 1982 | Revisiting Sliced Wasserstein on Images: From Vectorization to Convolution | 5.25 | | Accept
|
| 1983 | Towards Learning Universal Hyperparameter Optimizers with Transformers | 6.00 | | Accept
|
| 1984 | Optimal Transport-based Identity Matching for Identity-invariant Facial Expression Recognition | 5.33 | | Accept
|
| 1985 | I2Q: A Fully Decentralized Q-Learning Algorithm | 6.33 | | Accept
|
| 1986 | HierSpeech: Bridging the Gap between Text and Speech by Hierarchical Variational Inference using Self-supervised Representations for Speech Synthesis | 6.33 | | Accept
|
| 1987 | Unifying Voxel-based Representation with Transformer for 3D Object Detection | 5.33 | | Accept
|
| 1988 | Monte Carlo Tree Descent for Black-Box Optimization | 5.25 | | Accept
|
| 1989 | A Mean-Field Game Approach to Cloud Resource Management with Function Approximation | 6.00 | | Accept
|
| 1990 | Translation-equivariant Representation in Recurrent Networks with a Continuous Manifold of Attractors | 7.00 | | Accept
|
| 1991 | 3DILG: Irregular Latent Grids for 3D Generative Modeling | 5.75 | | Accept
|
| 1992 | Coresets for Vertical Federated Learning: Regularized Linear Regression and $K$-Means Clustering | 6.67 | | Accept
|
| 1993 | CHIMLE: Conditional Hierarchical IMLE | 5.25 | | Accept
|
| 1994 | Sharpness-Aware Training for Free | 5.00 | | Accept
|
| 1995 | Distributional Convergence of the Sliced Wasserstein Process | 6.00 | | Accept
|
| 1996 | Stochastic Multiple Target Sampling Gradient Descent | 6.33 | | Accept
|
| 1997 | Multi-Sample Training for Neural Image Compression | 6.33 | | Accept
|
| 1998 | Controllable and Lossless Non-Autoregressive End-to-End Text-to-Speech | 4.67 | | Reject
|
| 1999 | Implicit Regularization or Implicit Conditioning? Exact Risk Trajectories of SGD in High Dimensions | 5.00 | | Accept
|
| 2000 | FedRolex: Model-Heterogeneous Federated Learning with Rolling Sub-Model Extraction | 6.25 | | Accept
|
| 2001 | Differentially Private Covariance Revisited | 7.00 | | Accept
|
| 2002 | LION: Latent Point Diffusion Models for 3D Shape Generation | 6.00 | | Accept
|
| 2003 | Learning Efficient Vision Transformers via Fine-Grained Manifold Distillation | 5.75 | | Accept
|
| 2004 | On the Limitations of Stochastic Pre-processing Defenses | 6.33 | | Accept
|
| 2005 | Distributionally Robust Optimization with Data Geometry | 6.75 | | Accept
|
| 2006 | Learning Unified Representations for Multi-Resolution Face Recognition | 4.00 | | Reject
|
| 2007 | Falsification before Extrapolation in Causal Effect Estimation | 5.50 | | Accept
|
| 2008 | Improving Policy Learning via Language Dynamics Distillation | 5.00 | | Accept
|
| 2009 | On Gap-dependent Bounds for Offline Reinforcement Learning | 6.25 | | Accept
|
| 2010 | ResQ: A Residual Q Function-based Approach for Multi-Agent Reinforcement Learning Value Factorization | 6.25 | | Accept
|
| 2011 | Spartan: Differentiable Sparsity via Regularized Transportation | 6.25 | | Accept
|
| 2012 | Hardness of Noise-Free Learning for Two-Hidden-Layer Neural Networks | 7.33 | | Accept
|
| 2013 | BILCO: An Efficient Algorithm for Joint Alignment of Time Series | 6.33 | | Accept
|
| 2014 | Models Out of Line: A Fourier Lens on Distribution Shift Robustness | 6.33 | | Accept
|
| 2015 | Gradient-Free Methods for Deterministic and Stochastic Nonsmooth Nonconvex Optimization | 6.67 | | Accept
|
| 2016 | Visual Clues: Bridging Vision and Language Foundations for Image Paragraph Captioning | 6.00 | | Accept
|
| 2017 | Size and depth of monotone neural networks: interpolation and approximation | 6.00 | | Accept
|
| 2018 | Test-Time Training with Masked Autoencoders | 6.50 | | Accept
|
| 2019 | Visual Prompting via Image Inpainting | 6.50 | | Accept
|
| 2020 | Global Convergence and Stability of Stochastic Gradient Descent | 5.60 | | Accept
|
| 2021 | Functional Indirection Neural Estimator for Better Out-of-distribution Generalization | 5.00 | | Accept
|
| 2022 | SparCL: Sparse Continual Learning on the Edge | 5.50 | | Accept
|
| 2023 | Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models | 7.00 | | Accept
|
| 2024 | High-dimensional limit theorems for SGD: Effective dynamics and critical scaling | 7.33 | | Accept
|
| 2025 | Neur2SP: Neural Two-Stage Stochastic Programming | 6.50 | | Accept
|
| 2026 | Approximate Value Equivalence | 5.67 | | Accept
|
| 2027 | Learning-based Motion Planning in Dynamic Environments Using GNNs and Temporal Encoding | 6.00 | | Accept
|
| 2028 | Decomposing NeRF for Editing via Feature Field Distillation | 6.25 | | Accept
|
| 2029 | Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos | 8.00 | | Accept
|
| 2030 | Rethinking Image Restoration for Object Detection | 5.67 | | Accept
|
| 2031 | On Privacy and Personalization in Cross-Silo Federated Learning | 5.00 | | Accept
|
| 2032 | Approaching Quartic Convergence Rates for Quasi-Stochastic Approximation with Application to Gradient-Free Optimization | 6.50 | | Accept
|
| 2033 | Delving into Out-of-Distribution Detection with Vision-Language Representations | 6.00 | | Accept
|
| 2034 | Non-convex online learning via algorithmic equivalence | 5.33 | | Accept
|
| 2035 | VICRegL: Self-Supervised Learning of Local Visual Features | 5.33 | | Accept
|
| 2036 | Bayesian Clustering of Neural Spiking Activity Using a Mixture of Dynamic Poisson Factor Analyzers | 5.67 | | Accept
|
| 2037 | MCVD - Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation | 5.67 | | Accept
|
| 2038 | Solving Quantitative Reasoning Problems with Language Models | 6.00 | | Accept
|
| 2039 | Attention-based Neural Cellular Automata | 7.25 | | Accept
|
| 2040 | The price of ignorance: how much does it cost to forget noise structure in low-rank matrix estimation? | 6.00 | | Accept
|
| 2041 | Biological Learning of Irreducible Representations of Commuting Transformations | 6.75 | | Accept
|
| 2042 | The Unreliability of Explanations in Few-shot Prompting for Textual Reasoning | 5.33 | | Accept
|
| 2043 | Inductive Logical Query Answering in Knowledge Graphs | 5.75 | | Accept
|
| 2044 | Regularized Gradient Descent Ascent for Two-Player Zero-Sum Markov Games | 5.75 | | Accept
|
| 2045 | Posted Pricing and Dynamic Prior-independent Mechanisms with Value Maximizers | 6.33 | | Accept
|
| 2046 | Incorporating Prior Knowledge into Neural Networks through an Implicit Composite Kernel | 5.75 | | Reject
|
| 2047 | Recruitment Strategies That Take a Chance | 6.50 | | Accept
|
| 2048 | When does return-conditioned supervised learning work for offline reinforcement learning? | 6.25 | | Accept
|
| 2049 | Detection and Localization of Changes in Conditional Distributions | 6.50 | | Accept
|
| 2050 | Inference and Sampling for Archimax Copulas | 7.25 | | Accept
|
| 2051 | Online Deep Equilibrium Learning for Regularization by Denoising | 6.00 | | Accept
|
| 2052 | Optimal algorithms for group distributionally robust optimization and beyond | 5.25 | | Reject
|
| 2053 | Exploring through Random Curiosity with General Value Functions | 5.75 | | Accept
|
| 2054 | Unsupervised Multi-View Object Segmentation Using Radiance Field Propagation | 5.75 | | Accept
|
| 2055 | Text Classification with Born's Rule | 5.75 | | Accept
|
| 2056 | SIREN: Shaping Representations for Detecting Out-of-Distribution Objects | 4.00 | | Accept
|
| 2057 | Reincarnating Reinforcement Learning: Reusing Prior Computation to Accelerate Progress | 7.00 | | Accept
|
| 2058 | A sharp NMF result with applications in network modeling | 5.67 | | Accept
|
| 2059 | Generating multivariate time series with COmmon Source CoordInated GAN (COSCI-GAN) | 5.75 | | Accept
|
| 2060 | Learnable Polyphase Sampling for Shift Invariant and Equivariant Convolutional Networks | 6.00 | | Accept
|
| 2061 | Policy Optimization with Advantage Regularization for Long-Term Fairness in Decision Systems | 5.50 | | Accept
|
| 2062 | Cluster and Aggregate: Face Recognition with Large Probe Set | 5.75 | | Accept
|
| 2063 | Parameter tuning and model selection in Optimal Transport with semi-dual Brenier formulation | 6.00 | | Accept
|
| 2064 | Handcrafted Backdoors in Deep Neural Networks | 6.67 | | Accept
|
| 2065 | Local Spatiotemporal Representation Learning for Longitudinally-consistent Neuroimage Analysis | 7.00 | | Accept
|
| 2066 | Understanding Deep Neural Function Approximation in Reinforcement Learning via $\epsilon$-Greedy Exploration | 6.33 | | Accept
|
| 2067 | Compositional generalization through abstract representations in human and artificial neural networks | 6.75 | | Accept
|
| 2068 | Robust $\phi$-Divergence MDPs | 5.33 | | Accept
|
| 2069 | The price of unfairness in linear bandits with biased feedback | 6.00 | | Accept
|
| 2070 | Intrinsic Sliced Wasserstein Distances for Comparing Collections of Probability Distributions on Manifolds and Graphs | 4.67 | | Reject
|
| 2071 | SInGE: Sparsity via Integrated Gradients Estimation of Neuron Relevance | 5.67 | | Accept
|
| 2072 | Sample-Efficient Learning of Correlated Equilibria in Extensive-Form Games | 6.75 | | Accept
|
| 2073 | In Differential Privacy, There is Truth: on Vote-Histogram Leakage in Ensemble Private Learning | 6.00 | | Accept
|
| 2074 | Washing The Unwashable : On The (Im)possibility of Fairwashing Detection | 5.50 | | Accept
|
| 2075 | Graph Neural Networks with Adaptive Readouts | 6.67 | | Accept
|
| 2076 | Approximate Euclidean lengths and distances beyond Johnson-Lindenstrauss | 6.00 | | Accept
|
| 2077 | Change-point Detection for Sparse and Dense Functional Data in General Dimensions | 6.40 | | Accept
|
| 2078 | Markov Chain Score Ascent: A Unifying Framework of Variational Inference with Markovian Gradients | 6.50 | | Accept
|
| 2079 | D^2NeRF: Self-Supervised Decoupling of Dynamic and Static Objects from a Monocular Video | 6.00 | | Accept
|
| 2080 | A Near-Optimal Best-of-Both-Worlds Algorithm for Online Learning with Feedback Graphs | 6.75 | | Accept
|
| 2081 | Improved Imaging by Invex Regularizers with Global Optima Guarantees | 7.33 | | Accept
|
| 2082 | Random Normalization Aggregation for Adversarial Defense | 5.75 | | Accept
|
| 2083 | ToDD: Topological Compound Fingerprinting in Computer-Aided Drug Discovery | 6.67 | | Accept
|
| 2084 | Score-Based Diffusion meets Annealed Importance Sampling | 6.67 | | Accept
|
| 2085 | Rethinking Counterfactual Explanations as Local and Regional Counterfactual Policies | 5.00 | | Reject
|
| 2086 | VTC-LFC: Vision Transformer Compression with Low-Frequency Components | 7.00 | | Accept
|
| 2087 | Dynamic Fair Division with Partial Information | 6.00 | | Accept
|
| 2088 | Set-based Meta-Interpolation for Few-Task Meta-Learning | 6.50 | | Accept
|
| 2089 | How To Design Stable Machine Learned Solvers For Scalar Hyperbolic PDEs | 4.00 | | Reject
|
| 2090 | Convergence beyond the over-parameterized regime using Rayleigh quotients | 6.00 | | Accept
|
| 2091 | A Quadrature Rule combining Control Variates and Adaptive Importance Sampling | 7.00 | | Accept
|
| 2092 | TransBoost: Improving the Best ImageNet Performance using Deep Transduction | 6.00 | | Accept
|
| 2093 | Data Distributional Properties Drive Emergent In-Context Learning in Transformers | 7.00 | | Accept
|
| 2094 | Automatic differentiation of nonsmooth iterative algorithms | 7.00 | | Accept
|
| 2095 | Truncated proposals for scalable and hassle-free simulation-based inference | 6.50 | | Accept
|
| 2096 | Extracting computational mechanisms from neural data using low-rank RNNs | 6.00 | | Accept
|
| 2097 | Training Spiking Neural Networks with Local Tandem Learning | 7.00 | | Accept
|
| 2098 | Causal Identification under Markov equivalence: Calculus, Algorithm, and Completeness | 8.00 | | Accept
|
| 2099 | Shield Decentralization for Safe Multi-Agent Reinforcement Learning | 7.00 | | Accept
|
| 2100 | Hardness in Markov Decision Processes: Theory and Practice | 6.25 | | Accept
|
| 2101 | On the Interpretability of Regularisation for Neural Networks Through Model Gradient Similarity | 5.33 | | Accept
|
| 2102 | A Closer Look at Prototype Classifier for Few-shot Image Classification | 5.67 | | Accept
|
| 2103 | ALIFE: Adaptive Logit Regularizer and Feature Replay for Incremental Semantic Segmentation | 6.50 | | Accept
|
| 2104 | When are Local Queries Useful for Robust Learning? | 6.00 | | Accept
|
| 2105 | Contrastive Learning as Goal-Conditioned Reinforcement Learning | 7.33 | | Accept
|
| 2106 | A Neural Corpus Indexer for Document Retrieval | 6.50 | | Accept
|
| 2107 | Invertible Monotone Operators for Normalizing Flows | 7.00 | | Accept
|
| 2108 | Large-Scale Retrieval for Reinforcement Learning | 5.50 | | Accept
|
| 2109 | Make Sharpness-Aware Minimization Stronger: A Sparsified Perturbation Approach | 5.50 | | Accept
|
| 2110 | Explainability Via Causal Self-Talk | 6.25 | | Accept
|
| 2111 | Randomized Message-Interception Smoothing: Gray-box Certificates for Graph Neural Networks | 6.75 | | Accept
|
| 2112 | UQGAN: A Unified Model for Uncertainty Quantification of Deep Classifiers trained via Conditional GANs | 5.50 | | Accept
|
| 2113 | Oscillatory Tracking of Continuous Attractor Neural Networks Account for Phase Precession and Procession of Hippocampal Place Cells | 6.00 | | Accept
|
| 2114 | ELASTIC: Numerical Reasoning with Adaptive Symbolic Compiler | 6.33 | | Accept
|
| 2115 | Adaptation Accelerating Sampling-based Bayesian Inference in Attractor Neural Networks | 6.50 | | Accept
|
| 2116 | Subspace clustering in high-dimensions: Phase transitions \& Statistical-to-Computational gap | 5.60 | | Accept
|
| 2117 | Diagnosing failures of fairness transfer across distribution shift in real-world medical settings | 6.67 | | Accept
|
| 2118 | Efficient identification of informative features in simulation-based inference | 5.75 | | Accept
|
| 2119 | Sound and Complete Causal Identification with Latent Variables Given Local Background Knowledge | 6.67 | | Accept
|
| 2120 | Deep Active Learning by Leveraging Training Dynamics | 6.25 | | Accept
|
| 2121 | Model Extraction Attacks on Split Federated Learning | 5.50 | | Reject
|
| 2122 | CageNeRF: Cage-based Neural Radiance Field for Generalized 3D Deformation and Animation | 5.33 | | Accept
|
| 2123 | Boosting the Transferability of Adversarial Attacks with Reverse Adversarial Perturbation | 5.25 | | Accept
|
| 2124 | Contextual Bandits with Knapsacks for a Conversion Model | 6.33 | | Accept
|
| 2125 | Using natural language and program abstractions to instill human inductive biases in machines | 8.00 | | Accept
|
| 2126 | FairVFL: A Fair Vertical Federated Learning Framework with Contrastive Adversarial Learning | 6.00 | | Accept
|
| 2127 | Wasserstein Logistic Regression with Mixed Features | 5.80 | | Accept
|
| 2128 | Forecasting Human Trajectory from Scene History | 5.75 | | Accept
|
| 2129 | DOGE-Train: Discrete Optimization on GPU with End-to-end Training | 4.67 | | Reject
|
| 2130 | The Nature of Temporal Difference Errors in Multi-step Distributional Reinforcement Learning | 6.00 | | Accept
|
| 2131 | Personalized Subgraph Federated Learning | 5.00 | | Reject
|
| 2132 | DivBO: Diversity-aware CASH for Ensemble Learning | 6.25 | | Accept
|
| 2133 | TREC: Transient Redundancy Elimination-based Convolution | 5.25 | | Accept
|
| 2134 | Bidirectional Learning for Offline Infinite-width Model-based Optimization | 6.00 | | Accept
|
| 2135 | A Transformer-Based Object Detector with Coarse-Fine Crossing Representations | 6.33 | | Accept
|
| 2136 | Bessel Equivariant Networks for Inversion of Transmission Effects in Multi-Mode Optical Fibres | 6.33 | | Accept
|
| 2137 | VICE: Variational Interpretable Concept Embeddings | 5.50 | | Accept
|
| 2138 | Chefs' Random Tables: Non-Trigonometric Random Features | 6.00 | | Accept
|
| 2139 | SketchBoost: Fast Gradient Boosted Decision Tree for Multioutput Problems | 6.33 | | Accept
|
| 2140 | SizeShiftReg: a Regularization Method for Improving Size-Generalization in Graph Neural Networks | 5.67 | | Accept
|
| 2141 | CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers | 5.75 | | Accept
|
| 2142 | Deep invariant networks with differentiable augmentation layers | 4.50 | | Accept
|
| 2143 | FNeVR: Neural Volume Rendering for Face Animation | 5.33 | | Accept
|
| 2144 | HF-NeuS: Improved Surface Reconstruction Using High-Frequency Details | 6.00 | | Accept
|
| 2145 | TCT: Convexifying Federated Learning using Bootstrapped Neural Tangent Kernels | 6.00 | | Accept
|
| 2146 | Scalable Neural Video Representations with Learnable Positional Features | 5.67 | | Accept
|
| 2147 | Metric-Projected Accelerated Riemannian Optimization: Handling Constraints to Bound Geometric Penalties | 5.33 | | Reject
|
| 2148 | Cross-modal Learning for Image-Guided Point Cloud Shape Completion | 5.00 | | Accept
|
| 2149 | Retrieve, Reason, and Refine: Generating Accurate and Faithful Patient Instructions | 6.33 | | Accept
|
| 2150 | Rethinking the compositionality of point clouds through regularization in the hyperbolic space | 5.60 | | Accept
|
| 2151 | Redistribution of Weights and Activations for AdderNet Quantization | 6.00 | | Accept
|
| 2152 | Rethinking Variational Inference for Probabilistic Programs with Stochastic Support | 7.25 | | Accept
|
| 2153 | Online Convex Optimization with Hard Constraints: Towards the Best of Two Worlds and Beyond | 6.25 | | Accept
|
| 2154 | Information-Theoretic GAN Compression with Variational Energy-based Model | 6.00 | | Accept
|
| 2155 | Less-forgetting Multi-lingual Fine-tuning | 5.67 | | Accept
|
| 2156 | Exploring Figure-Ground Assignment Mechanism in Perceptual Organization | 5.00 | | Accept
|
| 2157 | Language Conditioned Spatial Relation Reasoning for 3D Object Grounding | 6.25 | | Accept
|
| 2158 | Weakly supervised causal representation learning | 5.50 | | Accept
|
| 2159 | HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions | 6.00 | | Accept
|
| 2160 | What You See is What You Classify: Black Box Attributions | 6.67 | | Accept
|
| 2161 | Amortized Mixing Coupling Processes for Clustering | 6.00 | | Accept
|
| 2162 | Revisiting Sparse Convolutional Model for Visual Recognition | 5.67 | | Accept
|
| 2163 | Cache-Augmented Inbatch Importance Resampling for Training Recommender Retriever | 6.75 | | Accept
|
| 2164 | Deep Attentive Belief Propagation: Integrating Reasoning and Learning for Solving Constraint Optimization Problems | 5.50 | | Accept
|
| 2165 | Category-Level 6D Object Pose Estimation in the Wild: A Semi-Supervised Learning Approach and A New Dataset | 4.75 | | Accept
|
| 2166 | Uni-Mol: A Universal 3D Molecular Representation Learning Framework | 5.00 | | Reject
|
| 2167 | Factored DRO: Factored Distributionally Robust Policies for Contextual Bandits | 5.80 | | Accept
|
| 2168 | SecureFedYJ: a safe feature Gaussianization protocol for Federated Learning | 5.25 | | Accept
|
| 2169 | Fixed-Distance Hamiltonian Monte Carlo | 6.00 | | Accept
|
| 2170 | An Investigation into Whitening Loss for Self-supervised Learning | 6.33 | | Accept
|
| 2171 | Beyond the Best: Distribution Functional Estimation in Infinite-Armed Bandits | 5.75 | | Accept
|
| 2172 | 🏘️ ProcTHOR: Large-Scale Embodied AI Using Procedural Generation | 7.00 | | Accept
|
| 2173 | M$^4$I: Multi-modal Models Membership Inference | 6.33 | | Accept
|
| 2174 | FOF: Learning Fourier Occupancy Field for Monocular Real-time Human Reconstruction | 5.67 | | Accept
|
| 2175 | Non-rigid Point Cloud Registration with Neural Deformation Pyramid | 5.50 | | Accept
|
| 2176 | Green Hierarchical Vision Transformer for Masked Image Modeling | 5.67 | | Accept
|
| 2177 | Hub-Pathway: Transfer Learning from A Hub of Pre-trained Models | 6.00 | | Accept
|
| 2178 | Cost-efficient Gaussian tensor network embeddings for tensor-structured inputs | 5.67 | | Accept
|
| 2179 | Biologically-plausible backpropagation through arbitrary timespans via local neuromodulators | 6.50 | | Accept
|
| 2180 | Wasserstein $K$-means for clustering probability distributions | 5.50 | | Accept
|
| 2181 | Beyond accuracy: generalization properties of bio-plausible temporal credit assignment rules | 6.50 | | Accept
|
| 2182 | Model-Based Offline Reinforcement Learning with Pessimism-Modulated Dynamics Belief | 7.50 | | Accept
|
| 2183 | Hierarchical classification at multiple operating points | 6.00 | | Accept
|
| 2184 | CLEAR: Generative Counterfactual Explanations on Graphs | 5.67 | | Accept
|
| 2185 | Symmetry Teleportation for Accelerated Optimization | 6.20 | | Accept
|
| 2186 | Fused Orthogonal Alternating Least Squares for Tensor Clustering | 6.67 | | Accept
|
| 2187 | Improving Variational Autoencoders with Density Gap-based Regularization | 6.33 | | Accept
|
| 2188 | Inherently Explainable Reinforcement Learning in Natural Language | 5.00 | | Accept
|
| 2189 | It's DONE: Direct ONE-shot learning with Hebbian weight imprinting | 5.33 | | Reject
|
| 2190 | BagFlip: A Certified Defense Against Data Poisoning | 5.67 | | Accept
|
| 2191 | Geo-Neus: Geometry-Consistent Neural Implicit Surfaces Learning for Multi-view Reconstruction | 5.25 | | Accept
|
| 2192 | Differentially Private Linear Regression via Medians | 4.67 | | Reject
|
| 2193 | Sparse2Dense: Learning to Densify 3D Features to Boost 3D Object Detection | 6.00 | | Accept
|
| 2194 | Deep Multi-Modal Structural Equations For Causal Effect Estimation With Unstructured Proxies | 5.67 | | Accept
|
| 2195 | NOTE: Robust Continual Test-time Adaptation Against Temporal Correlation | 6.00 | | Accept
|
| 2196 | A Deep Learning Dataloader with Shared Data Preparation | 6.00 | | Accept
|
| 2197 | Squeezeformer: An Efficient Transformer for Automatic Speech Recognition | 6.67 | | Accept
|
| 2198 | Neural Basis Models for Interpretability | 5.50 | | Accept
|
| 2199 | Scalable Interpretability via Polynomials | 6.67 | | Accept
|
| 2200 | NS3: Neuro-symbolic Semantic Code Search | 5.50 | | Accept
|
| 2201 | On the consistent estimation of optimal Receiver Operating Characteristic (ROC) curve | 6.50 | | Accept
|
| 2202 | Parallel Tempering With a Variational Reference | 5.33 | | Accept
|
| 2203 | Periodic Graph Transformers for Crystal Material Property Prediction | 6.00 | | Accept
|
| 2204 | Adaptive Cholesky Gaussian Processes | 4.33 | | Reject
|
| 2205 | GAUDI: A Neural Architect for Immersive 3D Scene Generation | 5.50 | | Accept
|
| 2206 | 3DB: A Framework for Debugging Computer Vision Models | 5.25 | | Accept
|
| 2207 | Exploration via Elliptical Episodic Bonuses | 6.33 | | Accept
|
| 2208 | Probabilistic Missing Value Imputation for Mixed Categorical and Ordered Data | 5.67 | | Accept
|
| 2209 | Near-Optimal Multi-Agent Learning for Safe Coverage Control | 5.50 | | Accept
|
| 2210 | Learning State-Aware Visual Representations from Audible Interactions | 5.33 | | Accept
|
| 2211 | Geometric Order Learning for Rank Estimation | 6.33 | | Accept
|
| 2212 | Enhanced Bilevel Optimization via Bregman Distance | 6.67 | | Accept
|
| 2213 | Optimal Comparator Adaptive Online Learning with Switching Cost | 6.00 | | Accept
|
| 2214 | Multi-objective Deep Data Generation with Correlated Property Control | 6.33 | | Accept
|
| 2215 | Deep Generative Model for Periodic Graphs | 6.00 | | Accept
|
| 2216 | Deep Generalized Schrödinger Bridge | 6.25 | | Accept
|
| 2217 | Biologically-Plausible Determinant Maximization Neural Networks for Blind Separation of Correlated Sources | 6.75 | | Accept
|
| 2218 | Practical Adversarial Multivalid Conformal Prediction | 7.00 | | Accept
|
| 2219 | Constrained Langevin Algorithms with L-mixing External Random Variables | 4.75 | | Accept
|
| 2220 | Equivariant Networks for Zero-Shot Coordination | 5.33 | | Accept
|
| 2221 | Simple Mechanisms for Welfare Maximization in Rich Advertising Auctions | 6.25 | | Accept
|
| 2222 | One-shot Neural Backdoor Erasing via Adversarial Weight Masking | 5.33 | | Accept
|
| 2223 | ASPiRe: Adaptive Skill Priors for Reinforcement Learning | 5.50 | | Accept
|
| 2224 | Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone | 6.00 | | Accept
|
| 2225 | Non-Gaussian Tensor Programs | 5.75 | | Accept
|
| 2226 | Ask4Help: Learning to Leverage an Expert for Embodied Tasks | 5.20 | | Accept
|
| 2227 | Bayesian Optimization over Discrete and Mixed Spaces via Probabilistic Reparameterization | 6.50 | | Accept
|
| 2228 | When to Update Your Model: Constrained Model-based Reinforcement Learning | 5.50 | | Accept
|
| 2229 | Distributed Methods with Compressed Communication for Solving Variational Inequalities, with Theoretical Guarantees | 6.20 | | Accept
|
| 2230 | Noise Attention Learning: Enhancing Noise Robustness by Gradient Scaling | 5.33 | | Accept
|
| 2231 | Exponential Family Model-Based Reinforcement Learning via Score Matching | 6.67 | | Accept
|
| 2232 | On the inability of Gaussian process regression to optimally learn compositional functions | 7.00 | | Accept
|
| 2233 | Understanding the Eluder Dimension | 6.33 | | Accept
|
| 2234 | Pessimism for Offline Linear Contextual Bandits using $\ell_p$ Confidence Sets | 6.75 | | Accept
|
| 2235 | Understanding and Extending Subgraph GNNs by Rethinking Their Symmetries | 7.00 | | Accept
|
| 2236 | Semi-supervised Semantic Segmentation with Prototype-based Consistency Regularization | 5.75 | | Accept
|
| 2237 | CoupAlign: Coupling Word-Pixel with Sentence-Mask Alignments for Referring Image Segmentation | 5.50 | | Accept
|
| 2238 | coVariance Neural Networks | 5.67 | | Accept
|
| 2239 | Unsupervised Cross-Task Generalization via Retrieval Augmentation | 6.00 | | Accept
|
| 2240 | Fast Stochastic Composite Minimization and an Accelerated Frank-Wolfe Algorithm under Parallelization | 5.67 | | Accept
|
| 2241 | Sampling without Replacement Leads to Faster Rates in Finite-Sum Minimax Optimization | 5.75 | | Accept
|
| 2242 | Beyond spectral gap: the role of the topology in decentralized learning | 6.33 | | Accept
|
| 2243 | Are GANs overkill for NLP? | 5.00 | | Accept
|
| 2244 | Relational Proxies: Emergent Relationships as Fine-Grained Discriminators | 6.00 | | Accept
|
| 2245 | Out-of-Distribution Detection with An Adaptive Likelihood Ratio on Informative Hierarchical VAE | 6.75 | | Accept
|
| 2246 | Towards Reliable Simulation-Based Inference with Balanced Neural Ratio Estimation | 6.00 | | Accept
|
| 2247 | Adv-Attribute: Inconspicuous and Transferable Adversarial Attack on Face Recognition | 5.75 | | Accept
|
| 2248 | Gold-standard solutions to the Schrödinger equation using deep learning: How much physics do we need? | 7.00 | | Accept
|
| 2249 | Adversarial Attack on Attackers: Post-Process to Mitigate Black-Box Score-Based Query Attacks | 6.25 | | Accept
|
| 2250 | Outlier Suppression: Pushing the Limit of Low-bit Transformer Language Models | 7.00 | | Accept
|
| 2251 | Fine-Grained Analysis of Stability and Generalization for Modern Meta Learning Algorithms | 6.50 | | Accept
|
| 2252 | Rethinking Lipschitz Neural Networks and Certified Robustness: A Boolean Function Perspective | 7.25 | | Accept
|
| 2253 | Deconfounded Representation Similarity for Comparison of Neural Networks | 6.67 | | Accept
|
| 2254 | Mirror Descent with Relative Smoothness in Measure Spaces, with application to Sinkhorn and EM | 6.75 | | Accept
|
| 2255 | Learning Energy Networks with Generalized Fenchel-Young Losses | 6.00 | | Accept
|
| 2256 | Reaching Nirvana: Maximizing the Margin in Both Euclidean and Angular Spaces for Deep Neural Network Classification | 5.00 | | Reject
|
| 2257 | Universally Expressive Communication in Multi-Agent Reinforcement Learning | 6.00 | | Accept
|
| 2258 | Efficient and Modular Implicit Differentiation | 7.00 | | Accept
|
| 2259 | Autoregressive Search Engines: Generating Substrings as Document Identifiers | 6.75 | | Accept
|
| 2260 | Heatmap Distribution Matching for Human Pose Estimation | 6.00 | | Accept
|
| 2261 | SageMix: Saliency-Guided Mixup for Point Clouds | 5.33 | | Accept
|
| 2262 | Efficient and Effective Optimal Transport-Based Biclustering | 5.67 | | Accept
|
| 2263 | Spending Thinking Time Wisely: Accelerating MCTS with Virtual Expansions | 5.00 | | Accept
|
| 2264 | Local Linear Convergence of Gradient Methods for Subspace Optimization via Strict Complementarity | 5.25 | | Accept
|
| 2265 | GraphDE: A Generative Framework for Debiased Learning and Out-of-Distribution Detection on Graphs | 5.20 | | Accept
|
| 2266 | Frank-Wolfe-based Algorithms for Approximating Tyler's M-estimator | 5.50 | | Accept
|
| 2267 | Object-Category Aware Reinforcement Learning | 5.80 | | Accept
|
| 2268 | Efficient Risk-Averse Reinforcement Learning | 6.00 | | Accept
|
| 2269 | Enhance the Visual Representation via Discrete Adversarial Training | 6.00 | | Accept
|
| 2270 | Concept Activation Regions: A Generalized Framework For Concept-Based Explanations | 7.00 | | Accept
|
| 2271 | ZIN: When and How to Learn Invariance Without Environment Partition? | 7.25 | | Accept
|
| 2272 | EfficientFormer: Vision Transformers at MobileNet Speed | 5.67 | | Accept
|
| 2273 | A Near-Optimal Primal-Dual Method for Off-Policy Learning in CMDP | 6.00 | | Accept
|
| 2274 | Distributional Reward Estimation for Effective Multi-agent Deep Reinforcement Learning | 5.80 | | Accept
|
| 2275 | KSD Aggregated Goodness-of-fit Test | 6.33 | | Accept
|
| 2276 | Efficient Aggregated Kernel Tests using Incomplete $U$-statistics | 6.67 | | Accept
|
| 2277 | OST: Improving Generalization of DeepFake Detection via One-Shot Test-Time Training | 6.00 | | Accept
|
| 2278 | Fuzzy Learning Machine | 6.00 | | Accept
|
| 2279 | Simulation-guided Beam Search for Neural Combinatorial Optimization | 5.75 | | Accept
|
| 2280 | Quo Vadis: Is Trajectory Forecasting the Key Towards Long-Term Multi-Object Tracking? | 6.00 | | Accept
|
| 2281 | Meta-Reinforcement Learning with Self-Modifying Networks | 6.67 | | Accept
|
| 2282 | Robust Models are less Over-Confident | 4.75 | | Accept
|
| 2283 | Generalizing Bayesian Optimization with Decision-theoretic Entropies | 6.00 | | Accept
|
| 2284 | Deep Hierarchical Planning from Pixels | 5.67 | | Accept
|
| 2285 | Multi-Scale Adaptive Network for Single Image Denoising | 7.00 | | Accept
|
| 2286 | Intermediate Prototype Mining Transformer for Few-Shot Semantic Segmentation | 6.00 | | Accept
|
| 2287 | DTG-SSOD: Dense Teacher Guidance for Semi-Supervised Object Detection | 6.00 | | Accept
|
| 2288 | Contact-aware Human Motion Forecasting | 6.00 | | Accept
|
| 2289 | Understanding Programmatic Weak Supervision via Source-aware Influence Function | 6.00 | | Accept
|
| 2290 | Elucidating the Design Space of Diffusion-Based Generative Models | 8.00 | | Accept
|
| 2291 | Dict-TTS: Learning to Pronounce with Prior Dictionary Knowledge for Text-to-Speech | 6.25 | | Accept
|
| 2292 | GhostNetV2: Enhance Cheap Operation with Long-Range Attention | 6.00 | | Accept
|
| 2293 | CASA: Category-agnostic Skeletal Animal Reconstruction | 6.00 | | Accept
|
| 2294 | Fair and Efficient Allocations Without Obvious Manipulations | 6.25 | | Accept
|
| 2295 | SNN-RAT: Robustness-enhanced Spiking Neural Network through Regularized Adversarial Training | 5.33 | | Accept
|
| 2296 | M³ViT: Mixture-of-Experts Vision Transformer for Efficient Multi-task Learning with Model-Accelerator Co-design | 6.00 | | Accept
|
| 2297 | Training Uncertainty-Aware Classifiers with Conformalized Deep Learning | 6.00 | | Accept
|
| 2298 | Compressible-composable NeRF via Rank-residual Decomposition | 5.25 | | Accept
|
| 2299 | Can Hybrid Geometric Scattering Networks Help Solve the Maximum Clique Problem? | 5.00 | | Accept
|
| 2300 | CEIP: Combining Explicit and Implicit Priors for Reinforcement Learning with Demonstrations | 6.00 | | Accept
|
| 2301 | Recipe for a General, Powerful, Scalable Graph Transformer | 6.00 | | Accept
|
| 2302 | Revisiting Heterophily For Graph Neural Networks | 5.20 | | Accept
|
| 2303 | Hamiltonian Latent Operators for content and motion disentanglement in image sequences | 5.33 | | Accept
|
| 2304 | Optimizing Relevance Maps of Vision Transformers Improves Robustness | 6.50 | | Accept
|
| 2305 | Decision-Focused Learning without Decision-Making: Learning Locally Optimized Decision Losses | 5.50 | | Accept
|
| 2306 | Learning General World Models in a Handful of Reward-Free Deployments | 5.50 | | Accept
|
| 2307 | Is a Modular Architecture Enough? | 6.75 | | Accept
|
| 2308 | Differentially Private Model Compression | 5.25 | | Accept
|
| 2309 | REVIVE: Regional Visual Representation Matters in Knowledge-Based Visual Question Answering | 5.67 | | Accept
|
| 2310 | Generative Neural Articulated Radiance Fields | 6.67 | | Accept
|
| 2311 | Learning Individualized Treatment Rules with Many Treatments: A Supervised Clustering Approach Using Adaptive Fusion | 6.00 | | Accept
|
| 2312 | Self-Consistent Dynamical Field Theory of Kernel Evolution in Wide Neural Networks | 7.33 | | Accept
|
| 2313 | Parametrically Retargetable Decision-Makers Tend To Seek Power | 6.00 | | Accept
|
| 2314 | Bayesian Persuasion for Algorithmic Recourse | 5.75 | | Accept
|
| 2315 | Graph Neural Networks as Gradient Flows | 5.00 | | Reject
|
| 2316 | Thompson Sampling Efficiently Learns to Control Diffusion Processes | 6.00 | | Accept
|
| 2317 | Is this the Right Neighborhood? Accurate and Query Efficient Model Agnostic Explanations | 5.50 | | Accept
|
| 2318 | A Quantitative Geometric Approach to Neural-Network Smoothness | 6.25 | | Accept
|
| 2319 | SCONE: Surface Coverage Optimization in Unknown Environments by Volumetric Integration | 7.00 | | Accept
|
| 2320 | Integrating Symmetry into Differentiable Planning | 5.67 | | Reject
|
| 2321 | Respecting Transfer Gap in Knowledge Distillation | 4.67 | | Accept
|
| 2322 | Generalized One-shot Domain Adaptation of Generative Adversarial Networks | 5.25 | | Accept
|
| 2323 | Random Sharpness-Aware Minimization | 6.25 | | Accept
|
| 2324 | Expediting Large-Scale Vision Transformer for Dense Prediction without Fine-tuning | 5.00 | | Accept
|
| 2325 | When Privacy Meets Partial Information: A Refined Analysis of Differentially Private Bandits | 6.50 | | Accept
|
| 2326 | What is Where by Looking: Weakly-Supervised Open-World Phrase-Grounding without Text Inputs | 5.25 | | Accept
|
| 2327 | SAPA: Similarity-Aware Point Affiliation for Feature Upsampling | 5.25 | | Accept
|
| 2328 | SAMURAI: Shape And Material from Unconstrained Real-world Arbitrary Image collections | 6.00 | | Accept
|
| 2329 | Generalized Laplacian Eigenmaps | 5.33 | | Accept
|
| 2330 | PatchComplete: Learning Multi-Resolution Patch Priors for 3D Shape Completion on Unseen Categories | 6.00 | | Accept
|
| 2331 | Neural Shape Deformation Priors | 5.00 | | Accept
|
| 2332 | Semi-Parametric Neural Image Synthesis | 5.50 | | Accept
|
| 2333 | Recommender Forest for Efficient Retrieval | 6.67 | | Accept
|
| 2334 | Self-Supervised Image Restoration with Blurry and Noisy Pairs | 5.33 | | Accept
|
| 2335 | A Non-asymptotic Analysis of Non-parametric Temporal-Difference Learning | 5.75 | | Accept
|
| 2336 | The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes | 6.33 | | Accept
|
| 2337 | The alignment property of SGD noise and how it helps select flat minima: A stability analysis | 6.67 | | Accept
|
| 2338 | Recommender Transformers with Behavior Pathways | 5.00 | | Reject
|
| 2339 | Mildly Conservative Q-Learning for Offline Reinforcement Learning | 6.00 | | Accept
|
| 2340 | Contrastive Neural Ratio Estimation | 6.67 | | Accept
|
| 2341 | Muffliato: Peer-to-Peer Privacy Amplification for Decentralized Optimization and Averaging | 7.00 | | Accept
|
| 2342 | UniGAN: Reducing Mode Collapse in GANs using a Uniform Generator | 6.00 | | Accept
|
| 2343 | Split-kl and PAC-Bayes-split-kl Inequalities for Ternary Random Variables | 5.75 | | Accept
|
| 2344 | Unsupervised Object Detection Pretraining with Joint Object Priors Generation and Detector Learning | 4.75 | | Accept
|
| 2345 | Spherical Sliced-Wasserstein | 5.25 | | Reject
|
| 2346 | On Margins and Generalisation for Voting Classifiers | 7.00 | | Accept
|
| 2347 | Transferring Textual Knowledge for Visual Recognition | 6.00 | | Reject
|
| 2348 | Open-Ended Reinforcement Learning with Neural Reward Functions | 5.50 | | Accept
|
| 2349 | LeRaC: Learning Rate Curriculum | 5.50 | | Reject
|
| 2350 | Alignment-guided Temporal Attention for Video Action Recognition | 5.00 | | Accept
|
| 2351 | SlateFree: a Model-Free Decomposition for Reinforcement Learning with Slate Actions | 4.50 | | Reject
|
| 2352 | BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework | 5.40 | | Accept
|
| 2353 | Active Learning for Multiple Target Models | 6.25 | | Accept
|
| 2354 | Neural Matching Fields: Implicit Representation of Matching Fields for Visual Correspondence | 5.50 | | Accept
|
| 2355 | Beyond Mahalanobis Distance for Textual OOD Detection | 5.25 | | Accept
|
| 2356 | Learning Generalizable Risk-Sensitive Policies to Coordinate in Decentralized Multi-Agent General-Sum Games | 5.00 | | Reject
|
| 2357 | ZeroC: A Neuro-Symbolic Model for Zero-shot Concept Recognition and Acquisition at Inference Time | 5.50 | | Accept
|
| 2358 | Learning to Accelerate Partial Differential Equations via Latent Global Evolution | 6.00 | | Accept
|
| 2359 | Localized Curvature-based Combinatorial Subgraph Sampling for Large-scale Graphs | 3.75 | | Reject
|
| 2360 | Graph Self-supervised Learning with Accurate Discrepancy Learning | 5.00 | | Accept
|
| 2361 | Tikhonov Regularization is Optimal Transport Robust under Martingale Constraints | 6.00 | | Accept
|
| 2362 | Boosting Out-of-distribution Detection with Typical Features | 6.75 | | Accept
|
| 2363 | Symplectic Spectrum Gaussian Processes: Learning Hamiltonians from Noisy and Sparse Data | 5.25 | | Accept
|
| 2364 | Plan To Predict: Learning an Uncertainty-Foreseeing Model For Model-Based Reinforcement Learning | 6.50 | | Accept
|
| 2365 | FiLM: Frequency improved Legendre Memory Model for Long-term Time Series Forecasting | 6.33 | | Accept
|
| 2366 | SAPipe: Staleness-Aware Pipeline for Data Parallel DNN Training | 5.67 | | Accept
|
| 2367 | Batch-Size Independent Regret Bounds for Combinatorial Semi-Bandits with Probabilistically Triggered Arms or Independent Arms | 6.67 | | Accept
|
| 2368 | A Unified Diversity Measure for Multiagent Reinforcement Learning | 6.00 | | Accept
|
| 2369 | GLIPv2: Unifying Localization and Vision-Language Understanding | 6.00 | | Accept
|
| 2370 | Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding | 6.67 | | Accept
|
| 2371 | Mutual Information Divergence: A Unified Metric for Multimodal Generative Models | 6.20 | | Accept
|
| 2372 | Neural Surface Reconstruction of Dynamic Scenes with Monocular RGB-D Camera | 6.75 | | Accept
|
| 2373 | Variational inference via Wasserstein gradient flows | 7.00 | | Accept
|
| 2374 | Finite-Time Analysis of Adaptive Temporal Difference Learning with Deep Neural Networks | 5.50 | | Accept
|
| 2375 | Multi-Granularity Cross-modal Alignment for Generalized Medical Visual Representation Learning | 6.67 | | Accept
|
| 2376 | An Embarrassingly Simple Approach to Semi-Supervised Few-Shot Learning | 6.25 | | Accept
|
| 2377 | Geo-SIC: Learning Deformable Geometric Shapes in Deep Image Classifiers | 6.67 | | Accept
|
| 2378 | On-Device Training Under 256KB Memory | 6.50 | | Accept
|
| 2379 | Independence Testing for Bounded Degree Bayesian Networks | 5.67 | | Accept
|
| 2380 | PCRL: Priority Convention Reinforcement Learning for Microscopically Sequencable Multi-agent Problems | 3.00 | | Reject
|
| 2381 | On the Effect of Pre-training for Transformer in Different Modality on Offline Reinforcement Learning | 6.33 | | Accept
|
| 2382 | Estimating and Explaining Model Performance When Both Covariates and Labels Shift | 6.00 | | Accept
|
| 2383 | PopArt: Efficient Sparse Regression and Experimental Design for Optimal Sparse Linear Bandits | 6.67 | | Accept
|
| 2384 | Distinguishing Learning Rules with Brain Machine Interfaces | 6.75 | | Accept
|
| 2385 | BiT: Robustly Binarized Multi-distilled Transformer | 6.33 | | Accept
|
| 2386 | Learning Chaotic Dynamics in Dissipative Systems | 6.00 | | Accept
|
| 2387 | Trading off Image Quality for Robustness is not Necessary with Regularized Deterministic Autoencoders | 6.25 | | Accept
|
| 2388 | Mean Estimation in High-Dimensional Binary Markov Gaussian Mixture Models | 6.00 | | Accept
|
| 2389 | Exploration via Planning for Information about the Optimal Trajectory | 6.00 | | Accept
|
| 2390 | Robust Calibration with Multi-domain Temperature Scaling | 6.67 | | Accept
|
| 2391 | Sparse Interaction Additive Networks via Feature Interaction Detection and Sparse Selection | 6.00 | | Accept
|
| 2392 | Fast variable selection makes scalable Gaussian process BSS-ANOVA a speedy and accurate choice for tabular and time series regression | 4.00 | | Reject
|
| 2393 | Efficient and Effective Multi-task Grouping via Meta Learning on Task Combinations | 6.00 | | Accept
|
| 2394 | CAGroup3D: Class-Aware Grouping for 3D Object Detection on Point Clouds | 5.75 | | Accept
|
| 2395 | Adaptive Data Debiasing through Bounded Exploration | 6.67 | | Accept
|
| 2396 | Bridging the Gap Between Vision Transformers and Convolutional Neural Networks on Small Datasets | 5.00 | | Accept
|
| 2397 | Loss Landscape Dependent Self-Adjusting Learning Rates in Decentralized Stochastic Gradient Descent | 4.50 | | Reject
|
| 2398 | MultiGuard: Provably Robust Multi-label Classification against Adversarial Examples | 6.00 | | Accept
|
| 2399 | Natural gradient enables fast sampling in spiking neural networks | 5.75 | | Accept
|
| 2400 | CEBaB: Estimating the Causal Effects of Real-World Concepts on NLP Model Behavior | 6.25 | | Accept
|
| 2401 | GAR: Generalized Autoregression for Multi-Fidelity Fusion | 6.33 | | Accept
|
| 2402 | RAMBO-RL: Robust Adversarial Model-Based Offline Reinforcement Learning | 5.50 | | Accept
|
| 2403 | Large-Scale Differentiable Causal Discovery of Factor Graphs | 6.00 | | Accept
|
| 2404 | Generating Long Videos of Dynamic Scenes | 6.25 | | Accept
|
| 2405 | Adaptively Exploiting d-Separators with Causal Bandits | 7.25 | | Accept
|
| 2406 | MonoSDF: Exploring Monocular Geometric Cues for Neural Implicit Surface Reconstruction | 6.00 | | Accept
|
| 2407 | TarGF: Learning Target Gradient Field for Object Rearrangement | 6.33 | | Accept
|
| 2408 | Rethinking Resolution in the Context of Efficient Video Recognition | 5.33 | | Accept
|
| 2409 | Feature-Proxy Transformer for Few-Shot Segmentation | 5.67 | | Accept
|
| 2410 | Private Synthetic Data for Multitask Learning and Marginal Queries | 6.00 | | Accept
|
| 2411 | Sauron U-Net: Simple automated redundancy elimination in medical image segmentation via filter pruning | 4.50 | | Reject
|
| 2412 | Implicit Warping for Animation with Image Sets | 7.00 | | Accept
|
| 2413 | AttCAT: Explaining Transformers via Attentive Class Activation Tokens | 5.75 | | Accept
|
| 2414 | Trading off Utility, Informativeness, and Complexity in Emergent Communication | 5.33 | | Accept
|
| 2415 | Online PAC-Bayes Learning | 6.00 | | Accept
|
| 2416 | Learning Physical Dynamics with Subequivariant Graph Neural Networks | 6.00 | | Accept
|
| 2417 | Scaling & Shifting Your Features: A New Baseline for Efficient Model Tuning | 7.00 | | Accept
|
| 2418 | MCMAE: Masked Convolution Meets Masked Autoencoders | 6.60 | | Accept
|
| 2419 | Training Spiking Neural Networks with Event-driven Backpropagation | 5.75 | | Accept
|
| 2420 | I2DFormer: Learning Image to Document Attention for Zero-Shot Image Classification | 5.50 | | Accept
|
| 2421 | Temporal Effective Batch Normalization in Spiking Neural Networks | 5.25 | | Accept
|
| 2422 | Masked Generative Adversarial Networks are Data-Efficient Generation Learners | 5.25 | | Accept
|
| 2423 | SAViT: Structure-Aware Vision Transformer Pruning via Collaborative Optimization | 5.00 | | Accept
|
| 2424 | SeqPATE: Differentially Private Text Generation via Knowledge Distillation | 6.00 | | Accept
|
| 2425 | A framework for bilevel optimization that enables stochastic and global variance reduction algorithms | 7.00 | | Accept
|
| 2426 | A Unified Model for Multi-class Anomaly Detection | 5.67 | | Accept
|
| 2427 | Learning from Future: A Novel Self-Training Framework for Semantic Segmentation | 6.00 | | Accept
|
| 2428 | Don't Roll the Dice, Ask Twice: The Two-Query Distortion of Matching Problems and Beyond | 5.50 | | Accept
|
| 2429 | Biologically Inspired Dynamic Thresholds for Spiking Neural Networks | 6.25 | | Accept
|
| 2430 | Structural Kernel Search via Bayesian Optimization and Symbolical Optimal Transport | 7.00 | | Accept
|
| 2431 | One Inlier is First: Towards Efficient Position Encoding for Point Cloud Registration | 5.50 | | Accept
|
| 2432 | Debiased Self-Training for Semi-Supervised Learning | 6.67 | | Accept
|
| 2433 | Transformer-based Working Memory for Multiagent Reinforcement Learning with Action Parsing | 6.00 | | Accept
|
| 2434 | Sharing Knowledge for Meta-learning with Feature Descriptions | 5.50 | | Accept
|
| 2435 | MultiScan: Scalable RGBD scanning for 3D environments with articulated objects | 4.33 | | Accept
|
| 2436 | Toward Equation of Motion for Deep Neural Networks: Continuous-time Gradient Descent and Discretization Error Analysis | 6.75 | | Accept
|
| 2437 | DENSE: Data-Free One-Shot Federated Learning | 6.75 | | Accept
|
| 2438 | Large-batch Optimization for Dense Visual Predictions | 5.50 | | Accept
|
| 2439 | Few-Shot Continual Active Learning by a Robot | 5.33 | | Accept
|
| 2440 | Adversarial Training with Complementary Labels: On the Benefit of Gradually Informative Attacks | 6.75 | | Accept
|
| 2441 | Stationary Deep Reinforcement Learning with Quantum K-spin Hamiltonian Equation | 4.75 | | Reject
|
| 2442 | Sym-NCO: Leveraging Symmetricity for Neural Combinatorial Optimization | 6.33 | | Accept
|
| 2443 | List-Decodable Sparse Mean Estimation | 6.33 | | Accept
|
| 2444 | The Pitfalls of Regularization in Off-Policy TD Learning | 6.75 | | Accept
|
| 2445 | Optimal Efficiency-Envy Trade-Off via Optimal Transport | 6.00 | | Accept
|
| 2446 | Physically-Based Face Rendering for NIR-VIS Face Recognition | 5.67 | | Accept
|
| 2447 | Learning With an Evolving Class Ontology | 5.33 | | Accept
|
| 2448 | The Curse of Low Task Diversity: On the Failure of Transfer Learning to Outperform MAML and their Empirical Equivalence | 3.75 | | Reject
|
| 2449 | Stability and Generalization Analysis of Gradient Methods for Shallow Neural Networks | 5.60 | | Accept
|
| 2450 | A Contrastive Framework for Neural Text Generation | 6.25 | | Accept
|
| 2451 | Generative Visual Prompt: Unifying Distributional Control of Pre-Trained Generative Models | 6.00 | | Accept
|
| 2452 | Polyhistor: Parameter-Efficient Multi-Task Adaptation for Dense Vision Tasks | 6.25 | | Accept
|
| 2453 | Model-based Safe Deep Reinforcement Learning via a Constrained Proximal Policy Optimization Algorithm | 5.75 | | Accept
|
| 2454 | On the Generalizability and Predictability of Recommender Systems | 6.25 | | Accept
|
| 2455 | Generalized Variational Inference in Function Spaces: Gaussian Measures meet Bayesian Deep Learning | 6.67 | | Accept
|
| 2456 | Non-deep Networks | 6.00 | | Accept
|
| 2457 | Private Estimation with Public Data | 5.67 | | Accept
|
| 2458 | Graph Scattering beyond Wavelet Shackles | 6.67 | | Accept
|
| 2459 | PointTAD: Multi-Label Temporal Action Detection with Learnable Query Points | 6.00 | | Accept
|
| 2460 | New Lower Bounds for Private Estimation and a Generalized Fingerprinting Lemma | 6.33 | | Accept
|
| 2461 | Theory and Approximate Solvers for Branched Optimal Transport with Multiple Sources | 5.50 | | Accept
|
| 2462 | Is $L^2$ Physics Informed Loss Always Suitable for Training Physics Informed Neural Network? | 6.25 | | Accept
|
| 2463 | Learning Infinite-Horizon Average-Reward Restless Multi-Action Bandits via Index Awareness | 6.25 | | Accept
|
| 2464 | Understanding Robust Learning through the Lens of Representation Similarities | 5.80 | | Accept
|
| 2465 | Why Do Artificially Generated Data Help Adversarial Robustness | 6.50 | | Accept
|
| 2466 | A Kernelised Stein Statistic for Assessing Implicit Generative Models | 6.33 | | Accept
|
| 2467 | Learning Consistency-Aware Unsigned Distance Functions Progressively from Raw Point Clouds | 6.50 | | Accept
|
| 2468 | Bilinear Exponential Family of MDPs: Frequentist Regret Bound with Tractable Exploration $\&$ Planning | 6.33 | | Reject
|
| 2469 | Hiding Images in Deep Probabilistic Models | 5.00 | | Accept
|
| 2470 | CUP: Critic-Guided Policy Reuse | 6.00 | | Accept
|
| 2471 | Non-Markovian Reward Modelling from Trajectory Labels via Interpretable Multiple Instance Learning | 5.67 | | Accept
|
| 2472 | Generalization Bounds for Estimating Causal Effects of Continuous Treatments | 5.25 | | Accept
|
| 2473 | Cost-Sensitive Self-Training for Optimizing Non-Decomposable Metrics | 5.00 | | Accept
|
| 2474 | SPD: Synergy Pattern Diversifying Oriented Unsupervised Multi-agent Reinforcement Learning | 5.75 | | Accept
|
| 2475 | EpiGRAF: Rethinking training of 3D GANs | 5.75 | | Accept
|
| 2476 | Coordinates Are NOT Lonely - Codebook Prior Helps Implicit Neural 3D representations | 5.75 | | Accept
|
| 2477 | Factored Adaptation for Non-Stationary Reinforcement Learning | 6.50 | | Accept
|
| 2478 | Bringing Image Scene Structure to Video via Frame-Clip Consistency of Object Tokens | 5.25 | | Accept
|
| 2479 | Increasing Confidence in Adversarial Robustness Evaluations | 6.75 | | Accept
|
| 2480 | TANGO: Text-driven Photorealistic and Robust 3D Stylization via Lighting Decomposition | 5.25 | | Accept
|
| 2481 | AutoMS: Automatic Model Selection for Novelty Detection with Error Rate Control | 5.33 | | Accept
|
| 2482 | Optimal Algorithms for Decentralized Stochastic Variational Inequalities | 5.67 | | Accept
|
| 2483 | Logit Margin Matters: Improving Transferable Targeted Adversarial Attack by Logit Calibration | 4.50 | | Reject
|
| 2484 | Adversarially Perturbed Batch Normalization: A Simple Way to Improve Image Recognition | 4.00 | | Reject
|
| 2485 | Singular Value Fine-tuning: Few-shot Segmentation requires Few-parameters Fine-tuning | 7.00 | | Accept
|
| 2486 | Supported Policy Optimization for Offline Reinforcement Learning | 6.00 | | Accept
|
| 2487 | Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline | 5.00 | | Accept
|
| 2488 | Adaptive Attention Link-based Regularization for Vision Transformers | 5.25 | | Reject
|
| 2489 | Rotation-Equivariant Conditional Spherical Neural Fields for Learning a Natural Illumination Prior | 5.50 | | Accept
|
| 2490 | E-MAPP: Efficient Multi-Agent Reinforcement Learning with Parallel Program Guidance | 6.00 | | Accept
|
| 2491 | Vision GNN: An Image is Worth Graph of Nodes | 6.75 | | Accept
|
| 2492 | Semi-supervised Vision Transformers at Scale | 5.50 | | Accept
|
| 2493 | Deep Model Reassembly | 7.33 | | Accept
|
| 2494 | Are You Stealing My Model? Sample Correlation for Fingerprinting Deep Neural Networks | 6.00 | | Accept
|
| 2495 | Towards Theoretically Inspired Neural Initialization Optimization | 5.75 | | Accept
|
| 2496 | Optimal Gradient Sliding and its Application to Optimal Distributed Optimization Under Similarity | 6.00 | | Accept
|
| 2497 | Decentralized Local Stochastic Extra-Gradient for Variational Inequalities | 5.25 | | Accept
|
| 2498 | P2P: Tuning Pre-trained Image Models for Point Cloud Analysis with Point-to-Pixel Prompting | 5.50 | | Accept
|
| 2499 | Your Transformer May Not be as Powerful as You Expect | 7.20 | | Accept
|
| 2500 | Multi-Instance Causal Representation Learning for Instance Label Prediction and Out-of-Distribution Generalization | 6.00 | | Accept
|
| 2501 | Online Training Through Time for Spiking Neural Networks | 6.33 | | Accept
|
| 2502 | Asymptotic Properties for Bayesian Neural Network in Besov Space | 5.67 | | Accept
|
| 2503 | Planning for Sample Efficient Imitation Learning | 6.33 | | Accept
|
| 2504 | Peripheral Vision Transformer | 6.25 | | Accept
|
| 2505 | ZARTS: On Zero-order Optimization for Neural Architecture Search | 6.67 | | Accept
|
| 2506 | Class-Dependent Label-Noise Learning with Cycle-Consistency Regularization | 6.25 | | Accept
|
| 2507 | InsPro: Propagating Instance Query and Proposal for Online Video Instance Segmentation | 5.75 | | Accept
|
| 2508 | Multi-dataset Training of Transformers for Robust Action Recognition | 5.00 | | Accept
|
| 2509 | LasUIE: Unifying Information Extraction with Latent Adaptive Structure-aware Generative Language Model | 6.67 | | Accept
|
| 2510 | Scalable Infomin Learning | 6.67 | | Accept
|
| 2511 | Linear tree shap | 7.00 | | Accept
|
| 2512 | CATER: Intellectual Property Protection on Text Generation APIs via Conditional Watermarks | 7.00 | | Accept
|
| 2513 | GAPX: Generalized Autoregressive Paraphrase-Identification X | 6.50 | | Accept
|
| 2514 | Explaining Preferences with Shapley Values | 6.25 | | Accept
|
| 2515 | C-Mixup: Improving Generalization in Regression | 6.00 | | Accept
|
| 2516 | Infinite-Fidelity Coregionalization for Physical Simulation | 6.00 | | Accept
|
| 2517 | Giga-scale Kernel Matrix-Vector Multiplication on GPU | 6.25 | | Accept
|
| 2518 | Self-Supervised Learning via Maximum Entropy Coding | 6.33 | | Accept
|
| 2519 | Neural Transmitted Radiance Fields | 6.00 | | Accept
|
| 2520 | Sequencer: Deep LSTM for Image Classification | 5.75 | | Accept
|
| 2521 | Delving into Sequential Patches for Deepfake Detection | 5.20 | | Accept
|
| 2522 | Maximum Class Separation as Inductive Bias in One Matrix | 6.75 | | Accept
|
| 2523 | Untargeted Backdoor Watermark: Towards Harmless and Stealthy Dataset Copyright Protection | 6.67 | | Accept
|
| 2524 | ClimbQ: Class Imbalanced Quantization Enabling Robustness on Efficient Inferences | 6.50 | | Accept
|
| 2525 | Error Correction Code Transformer | 6.75 | | Accept
|
| 2526 | DISCO: Adversarial Defense with Local Implicit Functions | 5.60 | | Accept
|
| 2527 | Watermarking for Out-of-distribution Detection | 6.00 | | Accept
|
| 2528 | Reinforcement Learning with a Terminator | 7.00 | | Accept
|
| 2529 | Rethinking Generalization in Few-Shot Classification | 6.25 | | Accept
|
| 2530 | Misspecified Phase Retrieval with Generative Priors | 5.60 | | Accept
|
| 2531 | Positively Weighted Kernel Quadrature via Subsampling | 6.25 | | Accept
|
| 2532 | SHINE: SubHypergraph Inductive Neural nEtwork | 5.25 | | Accept
|
| 2533 | LASSIE: Learning Articulated Shapes from Sparse Image Ensemble via 3D Part Discovery | 6.25 | | Accept
|
| 2534 | Bayesian Risk Markov Decision Processes | 5.25 | | Accept
|
| 2535 | Multi-block-Single-probe Variance Reduced Estimator for Coupled Compositional Optimization | 6.50 | | Accept
|
| 2536 | Synergy-of-Experts: Collaborate to Improve Adversarial Robustness | 6.33 | | Accept
|
| 2537 | Decoupling Knowledge from Memorization: Retrieval-augmented Prompt Learning | 5.75 | | Accept
|
| 2538 | HSDF: Hybrid Sign and Distance Field for Modeling Surfaces with Arbitrary Topologies | 5.00 | | Accept
|
| 2539 | Obj2Seq: Formatting Objects as Sequences with Class Prompt for Visual Tasks | 5.75 | | Accept
|
| 2540 | Riemannian Neural SDE: Learning Stochastic Representations on Manifolds | 6.00 | | Accept
|
| 2541 | Learning Latent Seasonal-Trend Representations for Time Series Forecasting | 6.50 | | Accept
|
| 2542 | QueryPose: Sparse Multi-Person Pose Regression via Spatial-Aware Part-Level Query | 6.00 | | Accept
|
| 2543 | A Mixture Of Surprises for Unsupervised Reinforcement Learning | 5.50 | | Accept
|
| 2544 | Monocular Dynamic View Synthesis: A Reality Check | 5.50 | | Accept
|
| 2545 | Antigen-Specific Antibody Design and Optimization with Diffusion-Based Generative Models for Protein Structures | 6.67 | | Accept
|
| 2546 | DropCov: A Simple yet Effective Method for Improving Deep Architectures | 5.25 | | Accept
|
| 2547 | Approximate Secular Equations for the Cubic Regularization Subproblem | 5.25 | | Accept
|
| 2548 | Spatial Pruned Sparse Convolution for Efficient 3D Object Detection | 5.25 | | Accept
|
| 2549 | BMU-MoCo: Bidirectional Momentum Update for Continual Video-Language Modeling | 5.00 | | Accept
|
| 2550 | GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images | 7.00 | | Accept
|
| 2551 | Learning Optical Flow from Continuous Spike Streams | 5.25 | | Accept
|
| 2552 | INRAS: Implicit Neural Representation for Audio Scenes | 6.00 | | Accept
|
| 2553 | Posterior and Computational Uncertainty in Gaussian Processes | 6.50 | | Accept
|
| 2554 | Precise Regret Bounds for Log-loss via a Truncated Bayesian Algorithm | 7.33 | | Accept
|
| 2555 | Robust Testing in High-Dimensional Sparse Models | 5.50 | | Accept
|
| 2556 | VER: Scaling On-Policy RL Leads to the Emergence of Navigation in Embodied Rearrangement | 5.25 | | Accept
|
| 2557 | Identifiability and generalizability from multiple experts in Inverse Reinforcement Learning | 5.75 | | Accept
|
| 2558 | AnimeSR: Learning Real-World Super-Resolution Models for Animation Videos | 6.00 | | Accept
|
| 2559 | Rethinking Alignment in Video Super-Resolution Transformers | 6.75 | | Accept
|
| 2560 | Censored Quantile Regression Neural Networks for Distribution-Free Survival Analysis | 6.50 | | Accept
|
| 2561 | Effective Backdoor Defense by Exploiting Sensitivity of Poisoned Samples | 6.75 | | Accept
|
| 2562 | Asymptotically Unbiased Instance-wise Regularized Partial AUC Optimization: Theory and Algorithm | 6.75 | | Accept
|
| 2563 | Constants of motion network | 5.67 | | Accept
|
| 2564 | OTKGE: Multi-modal Knowledge Graph Embeddings via Optimal Transport | 6.67 | | Accept
|
| 2565 | Keypoint-Guided Optimal Transport with Applications in Heterogeneous Domain Adaptation | 5.75 | | Accept
|
| 2566 | Weak-shot Semantic Segmentation via Dual Similarity Transfer | 5.33 | | Accept
|
| 2567 | Learning Generalizable Part-based Feature Representation for 3D Point Clouds | 6.00 | | Accept
|
| 2568 | Posterior Refinement Improves Sample Efficiency in Bayesian Neural Networks | 6.00 | | Accept
|
| 2569 | Training and Inference on Any-Order Autoregressive Models the Right Way | 6.75 | | Accept
|
| 2570 | Versatile Multi-stage Graph Neural Network for Circuit Representation | 6.00 | | Accept
|
| 2571 | S$^3$-NeRF: Neural Reflectance Field from Shading and Shadow under a Single Viewpoint | 5.75 | | Accept
|
| 2572 | High-dimensional Additive Gaussian Processes under Monotonicity Constraints | 5.67 | | Accept
|
| 2573 | Enhanced Latent Space Blind Model for Real Image Denoising via Alternative Optimization | 5.50 | | Accept
|
| 2574 | Generative Evolutionary Strategy For Black-Box Optimizations | 3.25 | | Reject
|
| 2575 | Learning Equivariant Segmentation with Instance-Unique Querying | 5.50 | | Accept
|
| 2576 | Video-based Human-Object Interaction Detection from Tubelet Tokens | 5.33 | | Accept
|
| 2577 | Semi-Supervised Semantic Segmentation via Gentle Teaching Assistant | 5.50 | | Accept
|
| 2578 | Faster Stochastic Algorithms for Minimax Optimization under Polyak-{\L}ojasiewicz Condition | 5.50 | | Accept
|
| 2579 | Back Razor: Memory-Efficient Transfer Learning by Self-Sparsified Backpropogation | 5.50 | | Accept
|
| 2580 | DreamShard: Generalizable Embedding Table Placement for Recommender Systems | 6.50 | | Accept
|
| 2581 | Learning Viewpoint-Agnostic Visual Representations by Recovering Tokens in 3D Space | 6.40 | | Accept
|
| 2582 | Does Self-supervised Learning Really Improve Reinforcement Learning from Pixels? | 5.00 | | Accept
|
| 2583 | CRAFT: explaining using Concepts from Recursive Activation FacTorization | 5.25 | | Reject
|
| 2584 | Masked Autoencoders that Listen | 6.00 | | Accept
|
| 2585 | MinVIS: A Minimal Video Instance Segmentation Framework without Video-based Training | 6.75 | | Accept
|
| 2586 | Unsupervised Learning of Equivariant Structure from Sequences | 5.33 | | Accept
|
| 2587 | A Conditional Randomization Test for Sparse Logistic Regression in High-Dimension | 6.75 | | Accept
|
| 2588 | Inducing Neural Collapse in Imbalanced Learning: Do We Really Need a Learnable Classifier at the End of Deep Neural Network? | 4.33 | | Accept
|
| 2589 | SegViT: Semantic Segmentation with Plain Vision Transformers | 4.75 | | Accept
|
| 2590 | Making Sense of Dependence: Efficient Black-box Explanations Using Dependence Measure | 5.50 | | Accept
|
| 2591 | Causally motivated multi-shortcut identification and removal | 6.00 | | Accept
|
| 2592 | Geometry-aware Two-scale PIFu Representation for Human Reconstruction | 5.25 | | Accept
|
| 2593 | A Unified Analysis of Mixed Sample Data Augmentation: A Loss Function Perspective | 6.75 | | Accept
|
| 2594 | Inception Transformer | 7.50 | | Accept
|
| 2595 | Dataset Distillation via Factorization | 6.00 | | Accept
|
| 2596 | Teach Less, Learn More: On the Undistillable Classes in Knowledge Distillation | 5.25 | | Accept
|
| 2597 | VITA: Video Instance Segmentation via Object Token Association | 6.75 | | Accept
|
| 2598 | Hilbert Distillation for Cross-Dimensionality Networks | 7.00 | | Accept
|
| 2599 | Non-stationary Transformers: Exploring the Stationarity in Time Series Forecasting | 5.50 | | Accept
|
| 2600 | VCT: A Video Compression Transformer | 5.50 | | Accept
|
| 2601 | Pragmatically Learning from Pedagogical Demonstrations in Multi-Goal Environments | 6.00 | | Accept
|
| 2602 | HUMANISE: Language-conditioned Human Motion Generation in 3D Scenes | 5.50 | | Accept
|
| 2603 | Fully Convolutional One-Stage 3D Object Detection on LiDAR Range Images | 5.67 | | Accept
|
| 2604 | GMMSeg: Gaussian Mixture based Generative Semantic Segmentation Models | 5.75 | | Accept
|
| 2605 | Counterfactual Fairness with Partially Known Causal Graph | 5.33 | | Accept
|
| 2606 | Learning Distinct and Representative Modes for Image Captioning | 6.25 | | Accept
|
| 2607 | Parameter-Efficient Masking Networks | 6.75 | | Accept
|
| 2608 | Look More but Care Less in Video Recognition | 5.20 | | Accept
|
| 2609 | Optimistic Mirror Descent Either Converges to Nash or to Strong Coarse Correlated Equilibria in Bimatrix Games | 6.33 | | Accept
|
| 2610 | Deterministic Langevin Monte Carlo with Normalizing Flows for Bayesian Inference | 5.67 | | Accept
|
| 2611 | Uncoupled Learning Dynamics with $O(\log T)$ Swap Regret in Multiplayer Games | 8.00 | | Accept
|
| 2612 | SAVi++: Towards End-to-End Object-Centric Learning from Real-World Videos | 5.75 | | Accept
|
| 2613 | AutoLink: Self-supervised Learning of Human Skeletons and Object Outlines by Linking Keypoints | 6.67 | | Accept
|
| 2614 | Video Diffusion Models | 6.75 | | Accept
|
| 2615 | UDC: Unified DNAS for Compressible TinyML Models for Neural Processing Units | 5.75 | | Accept
|
| 2616 | Towards Reasonable Budget Allocation in Untargeted Graph Structure Attacks via Gradient Debias | 5.33 | | Accept
|
| 2617 | Signal Recovery with Non-Expansive Generative Network Priors | 6.00 | | Accept
|
| 2618 | A Spectral Approach to Item Response Theory | 6.75 | | Accept
|
| 2619 | Regret Bounds for Information-Directed Reinforcement Learning | 6.50 | | Accept
|
| 2620 | TUSK: Task-Agnostic Unsupervised Keypoints | 5.33 | | Accept
|
| 2621 | Semantic Diffusion Network for Semantic Segmentation | 6.00 | | Accept
|
| 2622 | Social-Inverse: Inverse Decision-making of Social Contagion Management with Task Migrations | 5.50 | | Accept
|
| 2623 | Fair and Optimal Decision Trees: A Dynamic Programming Approach | 5.25 | | Accept
|
| 2624 | Instance-Based Uncertainty Estimation for Gradient-Boosted Regression Trees | 5.75 | | Accept
|
| 2625 | Counterfactual harm | 6.50 | | Accept
|
| 2626 | Hand-Object Interaction Image Generation | 5.50 | | Accept
|
| 2627 | Predicting Label Distribution from Multi-label Ranking | 5.75 | | Accept
|
| 2628 | Learning Best Combination for Efficient N:M Sparsity | 5.75 | | Accept
|
| 2629 | ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation | 6.25 | | Accept
|
| 2630 | Easy incremental learning methods to consider for commercial fine-tuning applications | 1.67 | | Reject
|
| 2631 | Saliency-Aware Neural Architecture Search | 6.00 | | Accept
|
| 2632 | NeurOLight: A Physics-Agnostic Neural Operator Enabling Parametric Photonic Device Simulation | 6.67 | | Accept
|
| 2633 | Controllable 3D Face Synthesis with Conditional Generative Occupancy Fields | 5.33 | | Accept
|
| 2634 | On the Robustness of Deep Clustering Models: Adversarial Attacks and Defenses | 5.75 | | Accept
|
| 2635 | Blackbox Attacks via Surrogate Ensemble Search | 5.00 | | Accept
|
| 2636 | Quadproj: a Python package for projecting onto quadratic hypersurfaces | 5.25 | | Reject
|
| 2637 | Inverse Game Theory for Stackelberg Games: the Blessing of Bounded Rationality | 6.00 | | Accept
|
| 2638 | Semi-Discrete Normalizing Flows through Differentiable Tessellation | 7.00 | | Accept
|
| 2639 | Trajectory of Mini-Batch Momentum: Batch Size Saturation and Convergence in High Dimensions | 6.50 | | Accept
|
| 2640 | A Closer Look at Weakly-Supervised Audio-Visual Source Localization | 7.25 | | Accept
|
| 2641 | A Policy-Guided Imitation Approach for Offline Reinforcement Learning | 7.00 | | Accept
|
| 2642 | Posterior Collapse of a Linear Latent Variable Model | 7.67 | | Accept
|
| 2643 | Active Learning in Bayesian Neural Networks: Balanced Entropy Learning Principle | 4.00 | | Reject
|
| 2644 | Weakly-Supervised Multi-Granularity Map Learning for Vision-and-Language Navigation | 7.25 | | Accept
|
| 2645 | Learning Active Camera for Multi-Object Navigation | 6.33 | | Accept
|
| 2646 | Signal Processing for Implicit Neural Representations | 5.75 | | Accept
|
| 2647 | Stochastic Window Transformer for Image Restoration | 5.00 | | Accept
|
| 2648 | An Empirical Study on Disentanglement of Negative-free Contrastive Learning | 5.25 | | Accept
|
| 2649 | What I Cannot Predict, I Do Not Understand: A Human-Centered Evaluation Framework for Explainability Methods | 5.50 | | Accept
|
| 2650 | Theseus: A Library for Differentiable Nonlinear Optimization | 7.25 | | Accept
|
| 2651 | Unsupervised Representation Learning from Pre-trained Diffusion Probabilistic Models | 5.75 | | Accept
|
| 2652 | SPoVT: Semantic-Prototype Variational Transformer for Dense Point Cloud Semantic Completion | 5.75 | | Accept
|
| 2653 | End-to-end Symbolic Regression with Transformers | 6.00 | | Accept
|
| 2654 | Pay attention to your loss : understanding misconceptions about Lipschitz neural networks | 5.25 | | Accept
|
| 2655 | Panchromatic and Multispectral Image Fusion via Alternating Reverse Filtering Network | 5.33 | | Accept
|
| 2656 | Joint Entropy Search for Multi-Objective Bayesian Optimization | 6.33 | | Accept
|
| 2657 | Prompt Learning with Optimal Transport for Vision-Language Models | 6.67 | | Reject
|
| 2658 | Mining Unseen Classes via Regional Objectness: A Simple Baseline for Incremental Segmentation | 5.80 | | Accept
|
| 2659 | Multi-modal Grouping Network for Weakly-Supervised Audio-Visual Video Parsing | 5.33 | | Accept
|
| 2660 | Unveiling The Mask of Position-Information Pattern Through the Mist of Image Features | 3.67 | | Reject
|
| 2661 | Understanding Benign Overfitting in Gradient-Based Meta Learning | 6.50 | | Accept
|
| 2662 | Representing Spatial Trajectories as Distributions | 6.00 | | Accept
|
| 2663 | Improved Convergence Rate of Stochastic Gradient Langevin Dynamics with Variance Reduction and its Application to Optimization | 6.33 | | Accept
|
| 2664 | Decoupling Features in Hierarchical Propagation for Video Object Segmentation | 6.00 | | Accept
|
| 2665 | Harmonizing the object recognition strategies of deep neural networks with humans | 4.00 | | Accept
|
| 2666 | Bi-directional Weakly Supervised Knowledge Distillation for Whole Slide Image Classification | 7.33 | | Accept
|
| 2667 | RankFeat: Rank-1 Feature Removal for Out-of-distribution Detection | 5.00 | | Accept
|
| 2668 | In the Eye of the Beholder: Robust Prediction with Causal User Modeling | 6.00 | | Accept
|
| 2669 | ResT V2: Simpler, Faster and Stronger | 5.67 | | Accept
|
| 2670 | Dataset Inference for Self-Supervised Models | 6.00 | | Accept
|
| 2671 | Remember the Past: Distilling Datasets into Addressable Memories for Neural Networks | 6.33 | | Accept
|
| 2672 | GenSDF: Two-Stage Learning of Generalizable Signed Distance Functions | 5.75 | | Accept
|
| 2673 | Product Ranking for Revenue Maximization with Multiple Purchases | 5.50 | | Accept
|
| 2674 | Explainable Reinforcement Learning via Model Transforms | 4.75 | | Accept
|
| 2675 | One Model to Edit Them All: Free-Form Text-Driven Image Manipulation with Semantic Modulations | 6.33 | | Accept
|
| 2676 | Privacy-Preserving Logistic Regression Training with A Faster Gradient Variant | 4.00 | | Reject
|
| 2677 | Towards Practical Control of Singular Values of Convolutional Layers | 6.25 | | Accept
|
| 2678 | Hyperbolic Contrastive Learning for Visual Representations beyond Objects | 5.67 | | Reject
|
| 2679 | Towards Versatile Embodied Navigation | 6.67 | | Accept
|
| 2680 | Resource-Adaptive Federated Learning with All-In-One Neural Composition | 6.00 | | Accept
|
| 2681 | Decision Trees with Short Explainable Rules | 6.00 | | Accept
|
| 2682 | MsSVT: Mixed-scale Sparse Voxel Transformer for 3D Object Detection on Point Clouds | 5.33 | | Accept
|
| 2683 | Generalized Delayed Feedback Model with Post-Click Information in Recommender Systems | 5.33 | | Accept
|
| 2684 | Degradation-Aware Unfolding Half-Shuffle Transformer for Spectral Compressive Imaging | 5.50 | | Accept
|
| 2685 | PerfectDou: Dominating DouDizhu with Perfect Information Distillation | 6.00 | | Accept
|
| 2686 | NCP: Neural Correspondence Prior for Effective Unsupervised Shape Matching | 5.75 | | Accept
|
| 2687 | A2: Efficient Automated Attacker for Boosting Adversarial Training | 6.33 | | Accept
|
| 2688 | Efficient learning of nonlinear prediction models with time-series privileged information | 6.00 | | Accept
|
| 2689 | ElasticMVS: Learning elastic part representation for self-supervised multi-view stereopsis | 5.50 | | Accept
|
| 2690 | Interaction Modeling with Multiplex Attention | 6.25 | | Accept
|
| 2691 | When to Make Exceptions: Exploring Language Models as Accounts of Human Moral Judgment | 6.00 | | Accept
|
| 2692 | Matryoshka Representation Learning | 6.25 | | Accept
|
| 2693 | Deep Fourier Up-Sampling | 6.00 | | Accept
|
| 2694 | Trajectory Inference via Mean-field Langevin in Path Space | 6.67 | | Accept
|
| 2695 | Divert More Attention to Vision-Language Tracking | 6.33 | | Accept
|
| 2696 | Object Scene Representation Transformer | 5.75 | | Accept
|
| 2697 | Rethinking Individual Global Max in Cooperative Multi-Agent Reinforcement Learning | 5.75 | | Accept
|
| 2698 | Discrete-Convex-Analysis-Based Framework for Warm-Starting Algorithms with Predictions | 6.33 | | Accept
|
| 2699 | R^2-VOS: Robust Referring Video Object Segmentation via Relational Cycle Consistency | 5.67 | | Reject
|
| 2700 | Exploring Example Influence in Continual Learning | 6.67 | | Accept
|
| 2701 | Motion Transformer with Global Intention Localization and Local Movement Refinement | 6.75 | | Accept
|
| 2702 | Bridging the Gap between Object and Image-level Representations for Open-Vocabulary Detection | 5.25 | | Accept
|
| 2703 | What Makes a "Good" Data Augmentation in Knowledge Distillation - A Statistical Perspective | 6.00 | | Accept
|
| 2704 | Behavior Transformers: Cloning $k$ modes with one stone | 6.75 | | Accept
|
| 2705 | Deliberated Domain Bridging for Domain Adaptive Semantic Segmentation | 6.00 | | Accept
|
| 2706 | VoxGRAF: Fast 3D-Aware Image Synthesis with Sparse Voxel Grids | 6.00 | | Accept
|
| 2707 | Cross Aggregation Transformer for Image Restoration | 7.00 | | Accept
|
| 2708 | Optimistic Curiosity Exploration and Conservative Exploitation with Linear Reward Shaping | 5.33 | | Accept
|
| 2709 | TotalSelfScan: Learning Full-body Avatars from Self-Portrait Videos of Faces, Hands, and Bodies | 6.67 | | Accept
|
| 2710 | PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies | 5.50 | | Accept
|
| 2711 | Stochastic Adaptive Activation Function | 6.50 | | Accept
|
| 2712 | Improved Fine-Tuning by Better Leveraging Pre-Training Data | 5.25 | | Accept
|
| 2713 | RainNet: A Large-Scale Imagery Dataset and Benchmark for Spatial Precipitation Downscaling | 5.25 | | Accept
|
| 2714 | Towards Robust Blind Face Restoration with Codebook Lookup Transformer | 6.25 | | Accept
|
| 2715 | A Coupled Design of Exploiting Record Similarity for Practical Vertical Federated Learning | 5.40 | | Accept
|
| 2716 | Memorization and Optimization in Deep Neural Networks with Minimum Over-parameterization | 5.75 | | Accept
|
| 2717 | Multivariate Time-Series Forecasting with Temporal Polynomial Graph Neural Networks | 5.50 | | Accept
|
| 2718 | Model-Based Imitation Learning for Urban Driving | 6.33 | | Accept
|
| 2719 | Learning Multi-resolution Functional Maps with Spectral Attention for Robust Shape Matching | 6.67 | | Accept
|
| 2720 | Fully Sparse 3D Object Detection | 6.33 | | Accept
|
| 2721 | Q-ViT: Accurate and Fully Quantized Low-bit Vision Transformer | 7.00 | | Accept
|
| 2722 | Stability and Generalization of Kernel Clustering: from Single Kernel to Multiple Kernel | 6.67 | | Accept
|
| 2723 | UMIX: Improving Importance Weighting for Subpopulation Shift via Uncertainty-Aware Mixup | 6.25 | | Accept
|
| 2724 | On the Strong Correlation Between Model Invariance and Generalization | 5.50 | | Accept
|
| 2725 | Unsupervised Multi-Object Segmentation by Predicting Probable Motion Patterns | 6.25 | | Accept
|
| 2726 | Roadblocks for Temporarily Disabling Shortcuts and Learning New Knowledge | 5.25 | | Accept
|
| 2727 | Synthetic Model Combination: An Instance-wise Approach to Unsupervised Ensemble Learning | 5.50 | | Accept
|
| 2728 | 4D Unsupervised Object Discovery | 5.67 | | Accept
|
| 2729 | Hierarchical Normalization for Robust Monocular Depth Estimation | 5.50 | | Accept
|
| 2730 | Whitening Convergence Rate of Coupling-based Normalizing Flows | 6.75 | | Accept
|
| 2731 | Estimating Noise Transition Matrix with Label Correlations for Noisy Multi-Label Learning | 5.50 | | Accept
|
| 2732 | Advancing Model Pruning via Bi-level Optimization | 5.50 | | Accept
|
| 2733 | Learn what matters: cross-domain imitation learning with task-relevant embeddings | 6.33 | | Accept
|
| 2734 | HumanLiker: A Human-like Object Detector to Model the Manual Labeling Process | 4.67 | | Accept
|
| 2735 | Towards Lightweight Black-Box Attack Against Deep Neural Networks | 6.00 | | Accept
|
| 2736 | OnePose++: Keypoint-Free One-Shot Object Pose Estimation without CAD Models | 5.00 | | Accept
|
| 2737 | DeepInteraction: 3D Object Detection via Modality Interaction | 4.67 | | Accept
|
| 2738 | MoVQ: Modulating Quantized Vectors for High-Fidelity Image Generation | 5.33 | | Accept
|
| 2739 | TransTab: Learning Transferable Tabular Transformers Across Tables | 7.00 | | Accept
|
| 2740 | Towards Efficient 3D Object Detection with Knowledge Distillation | 6.75 | | Accept
|
| 2741 | Tensor Wheel Decomposition and Its Tensor Completion Application | 5.25 | | Accept
|
| 2742 | Optimistic Tree Searches for Combinatorial Black-Box Optimization | 6.00 | | Accept
|
| 2743 | Recurrent Video Restoration Transformer with Guided Deformable Attention | 6.67 | | Accept
|
| 2744 | Prototypical VoteNet for Few-Shot 3D Point Cloud Object Detection | 5.50 | | Accept
|
| 2745 | Decoupling Classifier for Boosting Few-shot Object Detection and Instance Segmentation | 5.25 | | Accept
|
| 2746 | Planckian Jitter: countering the color-crippling effects of color jitter on self-supervised training | 5.67 | | Reject
|
| 2747 | Efficient Knowledge Distillation from Model Checkpoints | 6.25 | | Accept
|
| 2748 | PolarMix: A General Data Augmentation Technique for LiDAR Point Clouds | 5.20 | | Accept
|
| 2749 | Is Out-of-Distribution Detection Learnable? | 8.00 | | Accept
|
| 2750 | Let Images Give You More: Point Cloud Cross-Modal Training for Shape Analysis | 5.75 | | Accept
|
| 2751 | Equiformer: Equivariant Graph Attention Transformer for 3D Atomistic Graphs | 5.00 | | Reject
|
| 2752 | Trap and Replace: Defending Backdoor Attacks by Trapping Them into an Easy-to-Replace Subnetwork | 5.50 | | Accept
|
| 2753 | Masked Autoencoders As Spatiotemporal Learners | 7.33 | | Accept
|
| 2754 | TOIST: Task Oriented Instance Segmentation Transformer with Noun-Pronoun Distillation | 5.67 | | Accept
|
| 2755 | Cross-Image Context for Single Image Inpainting | 5.80 | | Accept
|
| 2756 | Natural Color Fool: Towards Boosting Black-box Unrestricted Attacks | 6.67 | | Accept
|
| 2757 | Adversarial Style Augmentation for Domain Generalized Urban-Scene Segmentation | 5.33 | | Accept
|
| 2758 | HSurf-Net: Normal Estimation for 3D Point Clouds by Learning Hyper Surfaces | 5.75 | | Accept
|
| 2759 | MetaMask: Revisiting Dimensional Confounder for Self-Supervised Learning | 6.25 | | Accept
|
| 2760 | Meta Optimal Transport | 6.00 | | Reject
|
| 2761 | Heterogeneous Skill Learning for Multi-agent Tasks | 5.33 | | Accept
|
| 2762 | End-to-End Learning to Index and Search in Large Output Spaces | 6.67 | | Accept
|
| 2763 | SNAKE: Shape-aware Neural 3D Keypoint Field | 5.00 | | Accept
|
| 2764 | Self-Supervised Aggregation of Diverse Experts for Test-Agnostic Long-Tailed Recognition | 5.67 | | Accept
|
| 2765 | A Novel Matrix-Encoding Method for Privacy-Preserving Neural Networks (Inference) | 2.75 | | Reject
|
| 2766 | Phase Transition from Clean Training to Adversarial Training | 4.25 | | Accept
|
| 2767 | On Enforcing Better Conditioned Meta-Learning for Rapid Few-Shot Adaptation | 6.25 | | Accept
|
| 2768 | Audio-Driven Co-Speech Gesture Video Generation | 6.50 | | Accept
|
| 2769 | Visual Concepts Tokenization | 5.67 | | Accept
|
| 2770 | Orthogonal Transformer: An Efficient Vision Transformer Backbone with Token Orthogonalization | 5.00 | | Accept
|
| 2771 | Finding Differences Between Transformers and ConvNets Using Counterfactual Simulation Testing | 6.00 | | Accept
|
| 2772 | Polynomial Neural Fields for Subband Decomposition and Manipulation | 6.75 | | Accept
|
| 2773 | Anticipating Performativity by Predicting from Predictions | 5.75 | | Accept
|
| 2774 | Learning Invariant Graph Representations for Out-of-Distribution Generalization | 5.25 | | Accept
|
| 2775 | SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation | 6.00 | | Accept
|
| 2776 | Active Labeling: Streaming Stochastic Gradients | 5.75 | | Accept
|
| 2777 | Practical Adversarial Attacks on Spatiotemporal Traffic Forecasting Models | 5.75 | | Accept
|
| 2778 | Fast Vision Transformers with HiLo Attention | 6.50 | | Accept
|
| 2779 | LGDN: Language-Guided Denoising Network for Video-Language Modeling | 6.33 | | Accept
|
| 2780 | PyramidCLIP: Hierarchical Feature Alignment for Vision-language Model Pretraining | 6.20 | | Accept
|
| 2781 | Divide and Contrast: Source-free Domain Adaptation via Adaptive Contrastive Learning | 5.75 | | Accept
|
| 2782 | Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning | 5.75 | | Accept
|
| 2783 | Adapting Self-Supervised Vision Transformers by Probing Attention-Conditioned Masking Consistency | 5.67 | | Accept
|
| 2784 | On Trace of PGD-Like Adversarial Attacks | 5.25 | | Reject
|
| 2785 | Dense Interspecies Face Embedding | 5.50 | | Accept
|
| 2786 | Self-Supervised Visual Representation Learning with Semantic Grouping | 6.25 | | Accept
|
| 2787 | Flexible Neural Image Compression via Code Editing | 6.67 | | Accept
|
| 2788 | DAGMA: Learning DAGs via M-matrices and a Log-Determinant Acyclicity Characterization | 6.75 | | Accept
|
| 2789 | The Minority Matters: A Diversity-Promoting Collaborative Metric Learning Algorithm | 7.67 | | Accept
|
| 2790 | DOMINO: Decomposed Mutual Information Optimization for Generalized Context in Meta-Reinforcement Learning | 6.25 | | Accept
|
| 2791 | OpenAUC: Towards AUC-Oriented Open-Set Recognition | 7.00 | | Accept
|
| 2792 | Exploring the Algorithm-Dependent Generalization of AUPRC Optimization with List Stability | 7.33 | | Accept
|
| 2793 | Point-M2AE: Multi-scale Masked Autoencoders for Hierarchical Point Cloud Pre-training | 5.67 | | Accept
|
| 2794 | OmniVL: One Foundation Model for Image-Language and Video-Language Tasks | 6.00 | | Accept
|
| 2795 | EcoFormer: Energy-Saving Attention with Linear Complexity | 5.00 | | Accept
|
| 2796 | Zero-Shot Video Question Answering via Frozen Bidirectional Language Models | 6.33 | | Accept
|
| 2797 | Align then Fusion: Generalized Large-scale Multi-view Clustering with Anchor Matching Correspondences | 6.33 | | Accept
|
| 2798 | RLIP: Relational Language-Image Pre-training for Human-Object Interaction Detection | 5.50 | | Accept
|
| 2799 | Dynamic Graph Neural Networks Under Spatio-Temporal Distribution Shift | 6.25 | | Accept
|
| 2800 | Mix and Reason: Reasoning over Semantic Topology with Data Mixing for Domain Generalization | 5.67 | | Accept
|
| 2801 | Independence Testing-Based Approach to Causal Discovery under Measurement Error and Linear Non-Gaussian Models | 6.00 | | Accept
|
| 2802 | Efficient Spatially Sparse Inference for Conditional GANs and Diffusion Models | 5.00 | | Accept
|
| 2803 | Subsidiary Prototype Alignment for Universal Domain Adaptation | 5.33 | | Accept
|
| 2804 | Generative Status Estimation and Information Decoupling for Image Rain Removal | 5.75 | | Accept
|
| 2805 | Embodied Scene-aware Human Pose Estimation | 5.75 | | Accept
|
| 2806 | "Lossless" Compression of Deep Neural Networks: A High-dimensional Neural Tangent Kernel Approach | 6.00 | | Accept
|
| 2807 | DaDA: Distortion-aware Domain Adaptation for Unsupervised Semantic Segmentation | 6.00 | | Accept
|
| 2808 | Coded Residual Transform for Generalizable Deep Metric Learning | 6.25 | | Accept
|
| 2809 | S-Prompts Learning with Pre-trained Transformers: An Occam’s Razor for Domain Incremental Learning | 5.75 | | Accept
|
| 2810 | Fairness Reprogramming | 5.33 | | Accept
|
| 2811 | DeepTOP: Deep Threshold-Optimal Policy for MDPs and RMABs | 5.75 | | Accept
|
| 2812 | GAMA: Generative Adversarial Multi-Object Scene Attacks | 6.00 | | Accept
|
| 2813 | RecursiveMix: Mixed Learning with History | 5.80 | | Accept
|
| 2814 | Differentiable Analog Quantum Computing for Optimization and Control | 7.00 | | Accept
|
| 2815 | NeuPhysics: Editable Neural Geometry and Physics from Monocular Videos | 5.00 | | Accept
|
| 2816 | SGAM: Building a Virtual 3D World through Simultaneous Generation and Mapping | 5.33 | | Accept
|
| 2817 | Learning Substructure Invariance for Out-of-Distribution Molecular Representations | 6.00 | | Accept
|
| 2818 | Lethal Dose Conjecture on Data Poisoning | 6.50 | | Accept
|
| 2819 | Unsupervised Causal Generative Understanding of Images | 6.25 | | Accept
|
| 2820 | Don't Pour Cereal into Coffee: Differentiable Temporal Logic for Temporal Action Segmentation | 5.67 | | Accept
|
| 2821 | Rank Diminishing in Deep Neural Networks | 5.75 | | Accept
|
| 2822 | A Lower Bound of Hash Codes' Performance | 5.33 | | Accept
|
| 2823 | Fine-Grained Semantically Aligned Vision-Language Pre-Training | 5.50 | | Accept
|
| 2824 | Sample Complexity of Learning Heuristic Functions for Greedy-Best-First and A* Search | 7.33 | | Accept
|
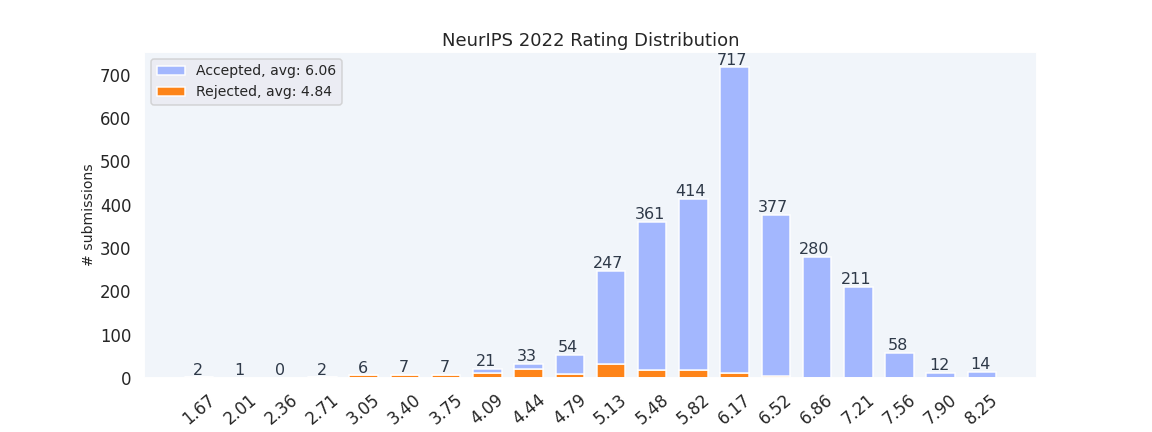
 /
/ ) to get submission info quickly
) to get submission info quickly