| 1 | Quantum reinforcement learning | 1.00 | 1.00 | 0.00 | [1, 1, 1, 1]
|
| 2 | Quantifying and Mitigating the Impact of Label Errors on Model Disparity Metrics | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 3 | Suppression helps: Lateral Inhibition-inspired Convolutional Neural Network for Image Classification | 3.00 | 3.00 | 0.00 | [3, 5, 3, 1]
|
| 4 | Factorized Fourier Neural Operators | 5.60 | 5.60 | 0.00 | [8, 6, 3, 8, 3]
|
| 5 | DFPC: Data flow driven pruning of coupled channels without data. | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 6 | TVSPrune - Pruning Non-discriminative filters via Total Variation separability of intermediate representations without fine tuning | 5.50 | 5.75 | 0.25 | [8, 6, 6, 3]
|
| 7 | Adversarial Training descends without descent: Finding actual descent directions based on Danskin"s theorem | 6.50 | 7.50 | 1.00 | [6, 6, 10, 8]
|
| 8 | A Study of Biologically Plausible Neural Network: the Role and Interactions of Brain-Inspired Mechanisms in Continual Learning | 5.00 | 5.00 | 0.00 | [3, 6, 3, 8]
|
| 9 | Learning Continuous Normalizing Flows For Faster Convergence To Target Distribution via Ascent Regularizations | 6.33 | 6.33 | 0.00 | [5, 8, 6]
|
| 10 | pFedKT: Personalized Federated Learning via Knowledge Transfer | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 11 | FARE: Provably Fair Representation Learning | 6.00 | 6.00 | 0.00 | [8, 3, 8, 8, 3]
|
| 12 | ONLINE RESTLESS BANDITS WITH UNOBSERVED STATES | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 13 | Dual-Domain Diffusion Based Progressive Style Rendering towards Semantic Structure Preservation | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 14 | UPop: Unified and Progressive Pruning for Compressing Vision-Language Transformers | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 15 | Learning to aggregate: A parameterized aggregator to debias aggregation for cross-device federated learning | 4.25 | 4.25 | 0.00 | [3, 5, 3, 6]
|
| 16 | NeuralStagger: accelerating physics constrained neural PDE solver with spatial-temporal decomposition | 4.75 | 4.75 | 0.00 | [5, 3, 5, 6]
|
| 17 | Towards Robust Online Dialogue Response Generation | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 18 | Deep Reinforcement Learning based Insight Selection Policy | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 19 | Data Leakage in Tabular Federated Learning | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 20 | Long-horizon video prediction using a dynamic latent hierarchy | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 21 | SwinZS3: Zero-Shot Semantic Segmentation with a Swin Transformer | 3.75 | 3.75 | 0.00 | [6, 3, 5, 1]
|
| 22 | Softened Symbol Grounding for Neuro-symbolic Systems | 7.00 | 7.00 | 0.00 | [10, 8, 5, 5]
|
| 23 | Encoding Recurrence into Transformers | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 24 | Generating Intuitive Fairness Specifications for Natural Language Processing | 6.50 | 6.50 | 0.00 | [6, 8, 6, 6]
|
| 25 | Learning to Perturb for Contrastive Learning of Unsupervised Sentence Representations | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 26 | Proper Scoring Rules for Survival Analysis | 5.00 | 5.33 | 0.33 | [5, 5, 6]
|
| 27 | Social Network Structure Shapes Innovation: Experience-sharing in RL with SAPIENS | 6.00 | 6.00 | 0.00 | [8, 3, 5, 8]
|
| 28 | Mini-batch $k$-means terminates within $O(d/\epsilon)$ iterations | 4.67 | 6.00 | 1.33 | [10, 6, 5, 3]
|
| 29 | Convergence is Not Enough: Average-Case Performance of No-Regret Learning Dynamics | 5.33 | 5.33 | 0.00 | [3, 5, 8]
|
| 30 | Gene finding revisited: improved robustness through structured decoding from learning embeddings | 4.25 | 4.25 | 0.00 | [1, 5, 3, 8]
|
| 31 | PPAT: Progressive Graph Pairwise Attention Network for Event Causality Identification | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 32 | Learning Uncertainty for Unknown Domains with Zero-Target-Assumption | 6.33 | 6.33 | 0.00 | [6, 5, 8]
|
| 33 | Detecting Out-of-Distribution Data with Semi-supervised Graph “Feature" Networks | 3.00 | 3.00 | 0.00 | [5, 1, 3, 3]
|
| 34 | Let Offline RL Flow: Training Conservative Agents in the Latent Space of Normalizing Flow | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 35 | Towards a Complete Theory of Neural Networks with Few Neurons | 4.25 | 4.25 | 0.00 | [5, 3, 6, 3]
|
| 36 | Machine Learning from Explanations | 3.50 | 3.50 | 0.00 | [1, 5, 5, 3]
|
| 37 | Functional Risk Minimization | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 38 | Latent Linear ODEs with Neural Kalman Filtering for Irregular Time Series Forecasting | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 39 | Transformer-based model for symbolic regression via joint supervised learning | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 40 | Gradient-Based Transfer Learning | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 41 | Coreset for Rational Functions | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 42 | Joint Representations of Text and Knowledge Graphs for Retrieval and Evaluation | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 43 | Transformer needs NMDA receptor nonlinearity for long-term memory | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 44 | Simple Spectral Graph Convolution from an Optimization Perspective | 5.33 | 4.75 | -0.58 | [3, 5, 5, 6]
|
| 45 | QAID: Question Answering Inspired Few-shot Intent Detection | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 46 | Rethinking the Value of Prompt Learning for Vision-Language Models | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 47 | Partial Output Norm: Mitigating the Model Output Blow-up Effect of Cross Entropy Loss | 1.50 | 1.50 | 0.00 | [1, 1, 1, 3]
|
| 48 | Disentangled Feature Swapping Augmentation for Weakly Supervised Semantic Segmentation | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 49 | FLOP: Tasks for Fitness Landscapes Of Protein families using sequence- and structure-based representations | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 50 | Distributed Least Square Ranking with Random Features | 5.67 | 5.67 | 0.00 | [6, 3, 8]
|
| 51 | Doing Fast Adaptation Fast: Conditionally Independent Deep Ensembles for Distribution Shifts | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 52 | Solving stochastic weak Minty variational inequalities without increasing batch size | 6.25 | 6.75 | 0.50 | [8, 6, 5, 8]
|
| 53 | Diversity Boosted Learning for Domain Generalization with a Large Number of Domains | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 54 | A Hybrid Framework for Generating A Country-scale Synthetic Population | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 55 | Towards Performance-maximizing Network Pruning via Global Channel Attention | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 56 | Adaptive Block-wise Learning for Knowledge Distillation | 5.50 | 5.50 | 0.00 | [6, 5, 8, 3]
|
| 57 | Curriculum-based Co-design of Morphology and Control of Voxel-based Soft Robots | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 58 | Object-Centric Learning with Slot Mixture Models | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 59 | WiNeRT: Towards Neural Ray Tracing for Wireless Channel Modelling and Differentiable Simulations | 6.25 | 6.25 | 0.00 | [8, 5, 6, 6]
|
| 60 | Pocket-specific 3D Molecule Generation by Fragment-based Autoregressive Diffusion Models | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 61 | Learning with Non-Uniform Label Noise: A Cluster-Dependent Semi-Supervised Approach | 4.75 | 4.75 | 0.00 | [5, 3, 6, 5]
|
| 62 | Towards scalable and non-IID robust Hierarchical Federated Learning via Label-driven Knowledge Aggregator | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 63 | Free Bits: Platform-Aware Latency Optimization of Mixed-Precision Neural Networks for Edge Deployment | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 64 | LS-IQ: Implicit Reward Regularization for Inverse Reinforcement Learning | 6.50 | 6.50 | 0.00 | [8, 5, 8, 5]
|
| 65 | On the Certification of Classifiers for Outperforming Human Annotators | 5.67 | 6.25 | 0.58 | [8, 6, 6, 5]
|
| 66 | Loss Adapted Plasticity: Learning From Data With Unreliable Sources | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 67 | Share Your Representation Only: Guaranteed Improvement of the Privacy-Utility Tradeoff in Federated Learning | 5.50 | 5.75 | 0.25 | [6, 6, 5, 6]
|
| 68 | Quantized Disentangled Representations for Object-Centric Visual Tasks | 2.50 | 2.50 | 0.00 | [3, 3, 1, 3]
|
| 69 | Supervised Random Feature Regression via Projection Pursuit | 2.33 | 2.33 | 0.00 | [3, 1, 3]
|
| 70 | Graph Spline Networks for Efficient Continuous Simulation of Dynamical Systems | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 71 | Online black-box adaptation to label-shift in the presence of conditional-shift | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 72 | RuDar: Weather Radar Dataset for Precipitation Nowcasting with Geographical and Seasonal Variability | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 73 | Learning Representations for Reinforcement Learning with Hierarchical Forward Models | 5.25 | 5.75 | 0.50 | [6, 6, 6, 5]
|
| 74 | xTrimoABFold: Improving Antibody Structure Prediction without Multiple Sequence Alignments | 3.75 | 3.75 | 0.00 | [1, 5, 6, 3]
|
| 75 | Thresholded Lexicographic Ordered Multi-Objective Reinforcement Learning | 3.75 | 3.75 | 0.00 | [6, 3, 3, 3]
|
| 76 | HOW SAMPLING AFFECTS TRAINING: AN EFFECTIVE SAMPLING THEORY STUDY FOR LONG-TAILED IMAGE CLASSIFICATION | 2.50 | 2.50 | 0.00 | [3, 3, 3, 1]
|
| 77 | MolBART: Generative Masked Language Models for Molecular Representations | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 78 | EquiMod: An Equivariance Module to Improve Self-Supervised Learning | 5.67 | 5.67 | 0.00 | [8, 3, 6]
|
| 79 | Cross-utterance Conditioned Coherent Speech Editing via Biased Training and Entire Inference | 5.50 | 5.50 | 0.00 | [6, 3, 8, 5]
|
| 80 | Manipulating Multi-agent Navigation Task via Emergent Communications | 1.00 | 1.00 | 0.00 | [1, 1, 1]
|
| 81 | Task-Aware Information Routing from Common Representation Space in Lifelong Learning | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 82 | CodeBPE: Investigating Subtokenization Options for Large Language Model Pretraining on Source Code | 6.00 | 6.00 | 0.00 | [5, 3, 8, 8]
|
| 83 | SWRM: Similarity Window Reweighting and Margins for Long-Tailed Recognition | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 84 | Transport with Support: Data-Conditional Diffusion Bridges | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 85 | Supervised Q-Learning can be a Strong Baseline for Continuous Control | 4.75 | 4.75 | 0.00 | [5, 3, 6, 5]
|
| 86 | Randomized Sharpness-Aware Training for Boosting Computational Efficiency in Deep Learning | 5.25 | 5.25 | 0.00 | [8, 5, 3, 5]
|
| 87 | Self-Supervised Off-Policy Ranking via Crowd Layer | 4.75 | 4.75 | 0.00 | [5, 5, 3, 6]
|
| 88 | Probing for Correlations of Causal Facts: Large Language Models and Causality | 2.25 | 2.25 | 0.00 | [6, 1, 1, 1]
|
| 89 | Geometry Problem Solving based on Counterfactual Evolutionary Reasoning | 2.33 | 2.33 | 0.00 | [3, 1, 3]
|
| 90 | Few-Shot Domain Adaptation For End-to-End Communication | 7.33 | 7.33 | 0.00 | [8, 6, 8]
|
| 91 | HyPHEN: A Hybrid Packing Method and Optimizations for Homomorphic Encryption-Based Neural Network | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 92 | Causal Inference for Knowledge Graph Completion | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 93 | Formal Specifications from Natural Language | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 94 | DELTA: Diverse Client Sampling for Fasting Federated Learning | 4.50 | 4.50 | 0.00 | [3, 3, 6, 6]
|
| 95 | Incremental Predictive Coding: A Parallel and Fully Automatic Learning Algorithm | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 96 | Rethinking Metric Based Contrastive Learning Method’s Generalization Capability | 4.67 | 3.75 | -0.92 | [1, 3, 5, 6]
|
| 97 | RISC-V MICROARCHITECTURE EXPLORATION VIA REINFORCEMENT LEARNING | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 98 | Learning Geometric Representations of Interactive Objects | 5.50 | 5.50 | 0.00 | [8, 6, 5, 3]
|
| 99 | Improve distance metric learning by learning positions of class centers | 2.33 | 2.33 | 0.00 | [1, 3, 3]
|
| 100 | The guide and the explorer: smart agents for resource-limited iterated batch reinforcement learning | 4.25 | 4.25 | 0.00 | [3, 3, 5, 6]
|
| 101 | FairGBM: Gradient Boosting with Fairness Constraints | 5.75 | 5.75 | 0.00 | [6, 8, 6, 3]
|
| 102 | Kinship Representation Learning with Face Componential Relation | 5.00 | 5.00 | 0.00 | [3, 8, 6, 3]
|
| 103 | Pseudo-Differential Integral Operator for Learning Solution Operators of Partial Differential Equations | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 104 | How (Un)Fair is Text Summarization? | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 105 | Simulating Task-Free Continual Learning Streams From Existing Datasets | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 106 | Online Bias Correction for Task-Free Continual Learning | 5.50 | 5.50 | 0.00 | [6, 8, 3, 5]
|
| 107 | A Simple Contrastive Learning Objective for Alleviating Neural Text Degeneration | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 108 | Enriching Online Knowledge Distillation with Specialist Ensemble | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 109 | Improved Training of Physics-Informed Neural Networks with Model Ensembles | 5.00 | 5.00 | 0.00 | [3, 3, 6, 8]
|
| 110 | Improved Gradient Descent Optimization Algorithm based on Inverse Model-Parameter Difference | 2.00 | 2.00 | 0.00 | [3, 1, 3, 1]
|
| 111 | Variational Learning ISTA | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 112 | Moment Distributionally Robust Probabilistic Supervised Learning | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 113 | CLEP: Exploiting Edge Partitioning for Graph Contrastive Learning | 4.40 | 4.40 | 0.00 | [3, 3, 3, 5, 8]
|
| 114 | Meta-Learning the Inductive Biases of Simple Neural Circuits | 5.50 | 5.50 | 0.00 | [5, 6, 3, 8]
|
| 115 | Enabling Equation Learning with the Bayesian Model Evidence via systematic $R^2$-elimination | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 116 | Curvature Informed Furthest Point Sampling | 1.00 | 1.00 | 0.00 | [1, 1, 1]
|
| 117 | Accelerating spiking neural network training using the $d$-block model | 4.00 | 4.00 | 0.00 | [3, 5, 6, 3, 3]
|
| 118 | RG: OUT-OF-DISTRIBUTION DETECTION WITH REACTIVATE GRADNORM | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 119 | Don’t fear the unlabelled: safe semi-supervised learning via debiasing | 6.25 | 6.25 | 0.00 | [8, 8, 3, 6]
|
| 120 | Gandalf : Data Augmentation is all you need for Extreme Classification | 3.75 | 3.75 | 0.00 | [3, 3, 3, 6]
|
| 121 | Learning a Data-Driven Policy Network for Pre-Training Automated Feature Engineering | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 122 | Attention Flows for General Transformers | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 123 | Grounded Contrastive Learning for Open-world Semantic Segmentation | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 124 | Making Substitute Models More Bayesian Can Enhance Transferability of Adversarial Examples | 6.33 | 6.33 | 0.00 | [6, 8, 5]
|
| 125 | Learning Group Importance using the Differentiable Hypergeometric Distribution | 7.00 | 7.50 | 0.50 | [8, 8, 6, 8]
|
| 126 | Convergence Rate of Primal-Dual Approach to Constrained Reinforcement Learning with Softmax Policy | 3.25 | 3.25 | 0.00 | [3, 1, 3, 6]
|
| 127 | Cross-Layer Retrospective Retrieving via Layer Attention | 6.00 | 6.00 | 0.00 | [6, 8, 5, 5]
|
| 128 | RephraseTTS: Dynamic Length Text based Speech Insertion with Speaker Style Transfer | 5.00 | 5.00 | 0.00 | [3, 6, 6, 5]
|
| 129 | Decision S4: Efficient Sequence-Based RL via State Spaces Layers | 5.67 | 6.33 | 0.67 | [5, 8, 6]
|
| 130 | Deep autoregressive density nets vs neural ensembles for model-based offline reinforcement learning | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 131 | Light and Accurate: Neural Architecture Search via Two Constant Shared Weights Initialisations | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 132 | Unveiling the sampling density in non-uniform geometric graphs | 5.33 | 5.25 | -0.08 | [5, 5, 6, 5]
|
| 133 | Smooth image-to-image translations with latent space interpolations | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 134 | Boosting Causal Discovery via Adaptive Sample Reweighting | 6.25 | 6.25 | 0.00 | [6, 5, 6, 8]
|
| 135 | Robust Training through Adversarially Selected Data Subsets | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 136 | Beyond Reward: Offline Preference-guided Policy Optimization | 5.00 | 5.00 | 0.00 | [6, 3, 3, 8]
|
| 137 | Iterative Circuit Repair Against Formal Specifications | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 138 | Neural Probabilistic Logic Programming in Discrete-Continuous Domains | 5.80 | 5.80 | 0.00 | [6, 8, 5, 5, 5]
|
| 139 | Can BERT Refrain from Forgetting on Sequential Tasks? A Probing Study | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 140 | Behavior Proximal Policy Optimization | 4.40 | 4.40 | 0.00 | [3, 5, 6, 3, 5]
|
| 141 | UiTTa: Online Test-Time Adaptation by User Interaction | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 142 | FedGC: An Accurate and Efficient Federated Learning under Gradient Constraint for Heterogeneous Data | 4.67 | 4.00 | -0.67 | [3, 3, 6]
|
| 143 | Actionable Neural Representations: Grid Cells from Minimal Constraints | 5.67 | 5.67 | 0.00 | [8, 6, 3]
|
| 144 | xTrimoDock: Cross-Modal Transformer for Multi-Chain Protein Docking | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 145 | Compression-aware Training of Neural Networks using Frank-Wolfe | 5.00 | 5.00 | 0.00 | [8, 3, 3, 6]
|
| 146 | Modeling content creator incentives on algorithm-curated platforms | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 147 | MBrain: A Multi-channel Self-Supervised Learning Framework for Brain Signals | 5.40 | 5.40 | 0.00 | [5, 5, 6, 8, 3]
|
| 148 | Group-Disentangling Conditional Shift | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 149 | When and Why Is Pretraining Object-Centric Representations Good for Reinforcement Learning? | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 150 | Face reconstruction from facial templates by learning latent space of a generator network | 5.75 | 5.75 | 0.00 | [6, 6, 6, 5]
|
| 151 | Mole-BERT: Rethinking Pre-training Graph Neural Networks for Molecules | 6.25 | 6.50 | 0.25 | [6, 6, 8, 6]
|
| 152 | A sparse, fast, and stable representation for multiparameter topological data analysis | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 153 | What"s in a name? The Influence of Personal Names on Spatial Reasoning in BLOOM Large Language Models | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 154 | Contrastive Representation Learning for Multi-scale Spatial Scenes | 4.75 | 4.75 | 0.00 | [1, 5, 5, 8]
|
| 155 | Improving Protein Interaction Prediction using Pretrained Structure Embedding | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 156 | Batch Normalization and Bounded Activation Functions | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 157 | Versatile Energy-Based Models for High Energy Physics | 3.00 | 3.00 | 0.00 | [1, 3, 5, 3]
|
| 158 | MEDOE: A Multi-Expert Decoder and Output Ensemble Framework for Long-tailed Semantic Segmentation | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 159 | Concept-level Debugging of Part-Prototype Networks | 7.50 | 8.00 | 0.50 | [8, 8, 8, 8]
|
| 160 | Geometrically regularized autoencoders for non-Euclidean data | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 161 | Model-based Unknown Input Estimation via Partially Observable Markov Decision Processes | 3.75 | 3.75 | 0.00 | [3, 6, 1, 5]
|
| 162 | TransFool: An Adversarial Attack against Neural Machine Translation Models | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 163 | Protein Sequence Design in a Latent Space via Model-based Reinforcement Learning | 4.25 | 4.25 | 0.00 | [8, 3, 3, 3]
|
| 164 | Breaking Large Language Model-based Code Generation | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 165 | The GANfather: Controllable generation of malicious activity to expose detection weaknesses and improve defence systems. | 1.67 | 1.67 | 0.00 | [3, 1, 1]
|
| 166 | Proximal Validation Protocol | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 167 | A Message Passing Perspective on Learning Dynamics of Contrastive Learning | 7.00 | 7.00 | 0.00 | [8, 5, 8]
|
| 168 | Farsighter: Efficient Multi-step Exploration for Deep Reinforcement Learning | 2.50 | 2.50 | 0.00 | [1, 3, 3, 3]
|
| 169 | Help Me Explore: Combining Autotelic and Social Learning via Active Goal Queries | 3.75 | 3.75 | 0.00 | [1, 3, 6, 5]
|
| 170 | AUTOMATIC CURRICULUM FOR UNSUPERVISED REIN- FORCEMENT LEARNING | 4.00 | 4.00 | 0.00 | [6, 5, 1]
|
| 171 | Exploiting Personalized Invariance for Better Out-of-distribution Generalization in Federated Learning | 4.75 | 4.75 | 0.00 | [3, 5, 5, 6]
|
| 172 | Filtered Semi-Markov CRF | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 173 | Zeroth-Order Optimization with Trajectory-Informed Derivative Estimation | 6.33 | 6.33 | 0.00 | [6, 8, 5]
|
| 174 | Distance VS. Coordinate: Distance Based Embedding Improves Model Generalization for Routing Problems | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 175 | Towards biologically plausible Dreaming and Planning | 3.25 | 3.25 | 0.00 | [3, 6, 3, 1]
|
| 176 | Mixture of Basis for Interpretable Continual Learning with Distribution Shifts | 3.00 | 3.00 | 0.00 | [3, 5, 1, 3]
|
| 177 | Extracting Meaningful Attention on Source Code: An Empirical Study of Developer and Neural Model Code Exploration | 5.00 | 5.00 | 0.00 | [5, 6, 5, 3, 6]
|
| 178 | Denoising Differential Privacy in Split Learning | 5.00 | 5.00 | 0.00 | [6, 6, 5, 3]
|
| 179 | Neuroevolution is a Competitive Alternative to Reinforcement Learning for Skill Discovery | 5.75 | 6.25 | 0.50 | [8, 8, 6, 3]
|
| 180 | On Representation Learning in the First Layer of Deep CNNs and the Dynamics of Gradient Descent | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 181 | Learning Layered Implicit Model for 3D Avatar Clothing Representation | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 182 | Scrunch: Preventing sensitive property inference through privacy-preserving representation learning | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 183 | Uniform-in-time propagation of chaos for the mean field gradient Langevin dynamics | 6.20 | 6.20 | 0.00 | [6, 6, 6, 5, 8]
|
| 184 | GM-VAE: Representation Learning with VAE on Gaussian Manifold | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 185 | Improving Adversarial Robustness by Putting More Regularizations on Less Robust Samples | 5.50 | 5.50 | 0.00 | [6, 8, 5, 3]
|
| 186 | Generalizable Multi-Relational Graph Representation Learning: A Message Intervention Approach | 4.00 | 4.00 | 0.00 | [3, 3, 3, 10, 1]
|
| 187 | Causal Explanations of Structural Causal Models | 5.67 | 5.67 | 0.00 | [3, 8, 6]
|
| 188 | Asynchronous Distributed Bilevel Optimization | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 189 | Multi-Agent Reinforcement Learning with Shared Resources for Inventory Management | 4.75 | 4.75 | 0.00 | [5, 6, 3, 5]
|
| 190 | Confidence-Based Feature Imputation for Graphs with Partially Known Features | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 191 | Explicitly Maintaining Diverse Playing Styles in Self-Play | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 192 | Toward Learning Geometric Eigen-Lengths Crucial for Robotic Fitting Tasks | 5.50 | 5.50 | 0.00 | [5, 6, 8, 3]
|
| 193 | Text2Model: Model Induction for Zero-shot Generalization Using Task Descriptions | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 194 | LiftedCL: Lifting Contrastive Learning for Human-Centric Perception | 7.00 | 7.00 | 0.00 | [8, 5, 8]
|
| 195 | Individual Privacy Accounting with Gaussian Differential Privacy | 5.50 | 5.75 | 0.25 | [6, 5, 6, 6]
|
| 196 | Evolving Populations of Diverse RL Agents with MAP-Elites | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 197 | Deconfounded Noisy Labels Learning | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 198 | Implicit Bias in Leaky ReLU Networks Trained on High-Dimensional Data | 6.75 | 7.50 | 0.75 | [8, 6, 6, 10]
|
| 199 | Learning Test Time Augmentation with Cascade Loss Prediction | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 200 | Adaptive Computation with Elastic Input Sequence | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 201 | Opportunistic Actor-Critic (OPAC) with Clipped Triple Q-learning | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 202 | Optimizing Data-Flow in Binary Neural Networks | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 203 | Gray-Box Gaussian Processes for Automated Reinforcement Learning | 5.75 | 5.75 | 0.00 | [8, 5, 5, 5]
|
| 204 | Protein Sequence and Structure Co-Design with Equivariant Translation | 5.25 | 5.25 | 0.00 | [6, 3, 6, 6]
|
| 205 | Deep Equilibrium Non-Autoregressive Sequence Learning | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 206 | PTUnifier: Pseudo Tokens as Paradigm Unifiers in Medical Vision-and-Language Pre-training | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 207 | SGD Through the Lens of Kolmogorov Complexity | 5.57 | 5.57 | 0.00 | [8, 5, 3, 6, 6, 6, 5]
|
| 208 | Offline imitation learning by controlling the effective planning horizon | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 209 | Learning in temporally structured environments | 6.25 | 6.25 | 0.00 | [6, 5, 6, 8]
|
| 210 | Identifying Phase Transition Thresholds of Permuted Linear Regression via Message Passing | 3.80 | 3.80 | 0.00 | [3, 3, 6, 6, 1]
|
| 211 | RandProx: Primal-Dual Optimization Algorithms with Randomized Proximal Updates | 6.00 | 6.00 | 0.00 | [5, 10, 3]
|
| 212 | Improving the Calibration of Fine-tuned Language Models via Denoising Variational Auto-Encoders | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 213 | A Hierarchical Bayesian Approach to Federated Learning | 5.00 | 5.00 | 0.00 | [3, 5, 6, 6]
|
| 214 | Neural Representations in Multi-Task Learning guided by Task-Dependent Contexts | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 215 | MCTransformer: Combining Transformers And Monte-Carlo Tree Search For Offline Reinforcement Learning | 2.33 | 2.33 | 0.00 | [3, 1, 3]
|
| 216 | One-Step Estimator for Permuted Sparse Recovery | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 217 | Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling? | 4.75 | 4.75 | 0.00 | [5, 6, 3, 5]
|
| 218 | Guarded Policy Optimization with Imperfect Online Demonstrations | 6.00 | 6.00 | 0.00 | [8, 5, 3, 8]
|
| 219 | Fast Nonlinear Vector Quantile Regression | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 220 | Multi Task Learning of Different Class Label Representations for Stronger Models | 3.00 | 3.00 | 0.00 | [5, 1, 3, 3]
|
| 221 | On the Existence of a Trojaned Twin Model | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 222 | On Information Maximisation in Multi-View Self-Supervised Learning | 3.50 | 3.50 | 0.00 | [5, 5, 1, 3]
|
| 223 | Leveraging Large Language Models for Multiple Choice Question Answering | 5.75 | 5.75 | 0.00 | [5, 5, 5, 8]
|
| 224 | SELCOR: Self-Correction for Weakly Supervised Learning | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 225 | Efficiently Meta-Learning for Robust Deep Networks without Prior Unbiased Set | 5.25 | 5.25 | 0.00 | [3, 5, 8, 5]
|
| 226 | Learning with Logical Constraints but without Shortcut Satisfaction | 7.00 | 7.00 | 0.00 | [6, 6, 8, 8]
|
| 227 | Certified Training: Small Boxes are All You Need | 6.75 | 7.50 | 0.75 | [8, 8, 6, 8]
|
| 228 | Label Similarity Aware Contrastive Learning | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 229 | Counterfactual Generation Under Confounding | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 230 | Regression with Label Differential Privacy | 5.25 | 7.00 | 1.75 | [8, 8, 6, 6]
|
| 231 | Hierarchical Abstraction for Combinatorial Generalization in Object Rearrangement | 6.00 | 6.33 | 0.33 | [8, 5, 6]
|
| 232 | SRBGCN: Tangent space-Free Lorentz Transformations for Graph Feature Learning | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 233 | Transfer NAS with Meta-learned Bayesian Surrogates | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 234 | Mitigating the Limitations of Multimodal VAEs with Coordination-Based Approach | 5.75 | 5.75 | 0.00 | [8, 5, 5, 5]
|
| 235 | Incompatibility between Deterministic Policy and Generative Adversarial Imitation Learning | 4.00 | 4.00 | 0.00 | [5, 3, 6, 3, 3]
|
| 236 | FiD-Light: Efficient and Effective Retrieval-Augmented Text Generation | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 237 | Contrastive Learning of Molecular Representation with Fragmented Views | 4.75 | 4.75 | 0.00 | [8, 3, 3, 5]
|
| 238 | Theoretical Study of Provably Efficient Offline Reinforcement Learning with Trajectory-Wise Reward | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 239 | Sharp Convergence Analysis of Gradient Descent for Deep Linear Neural Networks | 5.75 | 5.75 | 0.00 | [5, 8, 5, 5]
|
| 240 | Selective Frequency Network for Image Restoration | 6.50 | 6.50 | 0.00 | [5, 5, 8, 8]
|
| 241 | Contextualized Generative Retrieval | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 242 | Mirror Training for Input Convex Neural Network | 3.50 | 3.50 | 0.00 | [1, 5, 3, 5]
|
| 243 | Scaling Up Probabilistic Circuits by Latent Variable Distillation | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 244 | Oscillation Neural Ordinary Differential Equations | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 245 | Improving Differentiable Neural Architecture Search by Encouraging Transferability | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 246 | MA-BERT: Towards Matrix Arithmetic-only BERT Inference by Eliminating Complex Non-linear Functions | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 247 | Automatically Answering and Generating Machine Learning Final Exams | 7.00 | 7.00 | 0.00 | [3, 10, 8]
|
| 248 | CAT: Collaborative Adversarial Training | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 249 | Efficient Certified Training and Robustness Verification of Neural ODEs | 6.25 | 7.00 | 0.75 | [6, 8, 8, 6]
|
| 250 | Arbitrary Virtual Try-On Network: Characteristics Representation and Trade-off between Body and Clothing | 6.00 | 6.00 | 0.00 | [5, 8, 3, 8]
|
| 251 | A Benchmark Dataset for Learning from Label Proportions | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 252 | UL2: Unifying Language Learning Paradigms | 6.25 | 6.25 | 0.00 | [6, 8, 3, 8]
|
| 253 | Emergence of Exploration in Policy Gradient Reinforcement Learning via Resetting | 2.00 | 2.00 | 0.00 | [3, 1, 3, 1]
|
| 254 | CASR: Generating Complex Sequences with Autoregressive Self-Boost Refinement | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 255 | SciRepEval: A Multi-Format Benchmark for Scientific Document Representations | 5.67 | 5.67 | 0.00 | [3, 8, 6]
|
| 256 | On the convergence of SGD under the over-parameter setting | 4.25 | 4.25 | 0.00 | [5, 5, 6, 1]
|
| 257 | MASTER: Multi-task Pre-trained Bottlenecked Masked Autoencoders are Better Dense Retrievers | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 258 | Offline Reinforcement Learning via Weighted $f$-divergence | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 259 | Bitrate-Constrained DRO: Beyond Worst Case Robustness To Unknown Group Shifts | 6.25 | 6.25 | 0.00 | [5, 8, 6, 6]
|
| 260 | Some Practical Concerns and Solutions for Using Pretrained Representation in Industrial Systems | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 261 | Exphormer: Scaling Graph Transformers with Expander Graphs | 4.25 | 4.25 | 0.00 | [6, 3, 3, 5]
|
| 262 | Feature selection and low test error in shallow low-rotation ReLU networks | 6.00 | 6.00 | 0.00 | [6, 8, 5, 5]
|
| 263 | Backpropagation through Combinatorial Algorithms: Identity with Projection Works | 5.25 | 5.50 | 0.25 | [8, 5, 6, 3]
|
| 264 | Therbligs in Action: Video Understanding through Motion Primitives | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 265 | On the Adversarial Robustness against Natural Weather Perturbations | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 266 | Coupled Multiwavelet Operator Learning for Coupled Differential Equations | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 267 | Don’t Bet on Sparsity: Designing Brain-inspired Distance-preserving Encoder | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 268 | Mid-Vision Feedback for Convolutional Neural Networks | 5.33 | 5.33 | 0.00 | [5, 3, 8]
|
| 269 | Cross-Window Self-Training via Context Variations from Sparsely-Labeled Time Series | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 270 | Revisiting and Improving FGSM Adversarial Training | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 271 | Safe Reinforcement Learning From Pixels Using a Stochastic Latent Representation | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 272 | TrojText: Test-time Invisible Textual Trojan Insertion | 5.00 | 5.25 | 0.25 | [3, 6, 6, 6]
|
| 273 | An Experiment Design Paradigm using Joint Feature Selection and Task Optimization | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 274 | Multi-Objective Online Learning | 6.50 | 6.50 | 0.00 | [8, 5, 8, 5]
|
| 275 | Improved Training of Physics-Informed Neural Networks Using Energy-Based Priors: a Study on Electrical Impedance Tomography | 7.33 | 7.33 | 0.00 | [6, 6, 10]
|
| 276 | Efficient Bayesian Optimization with Deep Kernel Learning and Transformer Pre-trained on Muliple Heterogeneous Datasets | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 277 | Robustness Guarantees for Adversarially Trained Neural Networks | 5.00 | 5.50 | 0.50 | [5, 6, 5, 6]
|
| 278 | Fast-PINN for Complex Geometry: Solving PDEs with Boundary Connectivity Loss | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 279 | Noise Transforms Feed-Forward Networks into Sparse Coding Networks | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 280 | DEFENDING BACKDOOR ATTACKS VIA ROBUSTNESS AGAINST NOISY LABEL | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 281 | A Kernel Perspective of Skip Connections in Convolutional Networks | 6.75 | 6.75 | 0.00 | [6, 8, 8, 5]
|
| 282 | Ordered GNN: Ordering Message Passing to Deal with Heterophily and Over-smoothing | 6.33 | 5.50 | -0.83 | [3, 8, 5, 6]
|
| 283 | Sparse Distributed Memory is a Continual Learner | 5.75 | 6.50 | 0.75 | [8, 5, 8, 5]
|
| 284 | Optimistic Exploration in Reinforcement Learning Using Symbolic Model Estimates | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 285 | FLIP: A Provable Defense Framework for Backdoor Mitigation in Federated Learning | 6.25 | 6.25 | 0.00 | [8, 6, 8, 3]
|
| 286 | Towards Automatic Generation of Advanced Shift Networks | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 287 | Robust attributions require rethinking robustness metrics | 3.00 | 3.40 | 0.40 | [3, 5, 3, 3, 3]
|
| 288 | Learned Nearest-Class-Mean for Biased Representations in Long-Tailed Recognition | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 289 | GradientMix: A Simple yet Effective Regularization for Large Batch Training | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 290 | UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 291 | Discrete State-Action Abstraction via the Successor Representation | 4.75 | 4.75 | 0.00 | [5, 3, 8, 3]
|
| 292 | Hyper-parameter Tuning for Fair Classification without Sensitive Attribute Access | 5.75 | 5.75 | 0.00 | [5, 5, 5, 8]
|
| 293 | Towards Learning Implicit Symbolic Representation for Visual Reasoning | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 294 | GNNInterpreter: A Probabilistic Generative Model-Level Explanation for Graph Neural Networks | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 295 | Intra-Instance VICReg: Bag of Self-Supervised Image Patch Embedding Explains the Performance | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 296 | Rethinking Symbolic Regression: Morphology and Adaptability in the Context of Evolutionary Algorithms | 5.75 | 5.75 | 0.00 | [3, 6, 6, 8]
|
| 297 | Efficient, probabilistic analysis of combinatorial neural codes | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 298 | On Pre-training Language Model for Antibody | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 299 | Challenging Common Assumptions about Catastrophic Forgetting | 4.25 | 4.25 | 0.00 | [3, 5, 6, 3]
|
| 300 | Learning to reason over visual objects | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 301 | Imitating Graph-Based Planning with Goal-Conditioned Policies | 5.75 | 6.50 | 0.75 | [6, 8, 6, 6]
|
| 302 | Prefer to Classify: Improving Text Classifier via Pair-wise Preference Learning | 5.33 | 5.33 | 0.00 | [3, 8, 5]
|
| 303 | Seeing Differently, Acting Similarly: Heterogeneously Observable Imitation Learning | 5.67 | 5.67 | 0.00 | [8, 3, 6]
|
| 304 | Simple and Deep Graph Attention Networks | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 305 | A theoretical study of inductive biases in contrastive learning | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 306 | Combinatorial Pure Exploration of Causal Bandits | 7.33 | 7.33 | 0.00 | [6, 8, 8]
|
| 307 | How to fine-tune vision models with SGD | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 308 | Computational Language Acquisition with Theory of Mind | 5.75 | 5.75 | 0.00 | [6, 3, 6, 8]
|
| 309 | Rényi Supervised Contrastive Learning for Transferable Representation | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 310 | MiDAS: Multi-integrated Domain Adaptive Supervision for Fake News Detection | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 311 | Walking the Tightrope: An Investigation of the Convolutional Autoencoder Bottleneck | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 312 | A Closer Look at Model Adaptation using Feature Distortion and Simplicity Bias | 7.00 | 8.00 | 1.00 | [6, 8, 10, 8]
|
| 313 | Pareto Invariant Risk Minimization | 5.75 | 6.00 | 0.25 | [5, 5, 6, 8]
|
| 314 | Understanding and Adopting Rational Behavior by Bellman Score Estimation | 6.29 | 6.86 | 0.57 | [6, 8, 8, 5, 8, 5, 8]
|
| 315 | Meta-Learning for Bootstrapping Medical Image Segmentation from Imperfect Supervision | 3.75 | 3.75 | 0.00 | [3, 3, 3, 6]
|
| 316 | L2B: Learning to Bootstrap for Combating Label Noise | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 317 | What Makes Convolutional Models Great on Long Sequence Modeling? | 7.00 | 7.00 | 0.00 | [6, 8, 6, 8]
|
| 318 | Progressive Mixup Augmented Teacher-Student Learning for Unsupervised Domain Adaptation | 3.50 | 3.40 | -0.10 | [3, 5, 3, 3, 3]
|
| 319 | M$^3$SAT: A Sparsely Activated Transformer for Efficient Multi-Task Learning from Multiple Modalities | 5.50 | 5.50 | 0.00 | [3, 8, 6, 5]
|
| 320 | Editing models with task arithmetic | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 321 | Structured World Representations via Block-Slot Attention | 6.25 | 7.00 | 0.75 | [6, 8, 8, 6]
|
| 322 | Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis | 5.00 | 5.00 | 0.00 | [3, 6, 6, 5]
|
| 323 | Atomized Deep Learning Models | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3, 3]
|
| 324 | Topology Matters in Fair Graph Learning: a Theoretical Pilot Study | 4.50 | 4.50 | 0.00 | [6, 6, 3, 3]
|
| 325 | Context-Aware Image Completion | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 326 | Speech denoising by listening to noise | 3.80 | 3.80 | 0.00 | [5, 3, 5, 3, 3]
|
| 327 | Can Agents Run Relay Race with Strangers? Generalization of RL to Out-of-Distribution Trajectories | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 328 | DYNAMIC BATCH NORM STATISTICS UPDATE FOR NATURAL ROBUSTNESS | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 329 | SKTformer: A Skeleton Transformer for Long Sequence Data | 5.25 | 5.25 | 0.00 | [6, 6, 3, 6]
|
| 330 | CktGNN: Circuit Graph Neural Network for Electronic Design Automation | 6.25 | 6.25 | 0.00 | [6, 6, 8, 5]
|
| 331 | How Should I Plan? A Performance Comparison of Decision-Time vs. Background Planning | 3.00 | 3.00 | 0.00 | [3, 3, 1, 5]
|
| 332 | Substructure-Atom Cross Attention for Molecular Representation Learning | 5.80 | 5.80 | 0.00 | [6, 5, 8, 5, 5]
|
| 333 | Differentially Private Algorithms for Smooth Nonconvex ERM | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 334 | Untangling Effect and Side Effect: Consistent Causal Inference in Non-Targeted Trials | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 335 | AMA: Asymptotic Midpoint Augmentation for Margin Balancing and Moderate Broadening | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 336 | STUNT: Few-shot Tabular Learning with Self-generated Tasks from Unlabeled Tables | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 337 | MEDIC: Model Backdoor Removal by Importance Driven Cloning | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 338 | The Role of Pre-training Data in Transfer Learning | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 339 | Compressed Predictive Information Coding | 5.75 | 5.75 | 0.00 | [8, 3, 6, 6]
|
| 340 | Importance of Class Selectivity in Early Epochs of Training | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 341 | Mechanistic Mode Connectivity | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 342 | CLASSIFICATION OF INCOMPLETE DATA USING AUGMENTED MLP | 2.50 | 2.50 | 0.00 | [3, 1, 3, 3]
|
| 343 | On the Convergence of Federated Deep AUC Maximization | 3.25 | 3.25 | 0.00 | [3, 3, 6, 1]
|
| 344 | Towards A Unified Neural Architecture for Visual Recognition and Reasoning | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 345 | BLOOM Large Language Models and the Chomsky Hierarchy | 3.00 | 3.00 | 0.00 | [5, 1, 3, 3]
|
| 346 | WebBrain: Learning to Generate Factually Correct Articles for Queries by Grounding on Large Web Corpus | 5.75 | 5.75 | 0.00 | [6, 8, 6, 3]
|
| 347 | HloEnv: A Graph Rewrite Environment for Deep Learning Compiler Optimization Research | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 348 | Towards Diverse Perspective Learning with Switch over Multiple Temporal Pooling | 3.00 | 3.00 | 0.00 | [5, 3, 1]
|
| 349 | Deep Latent State Space Models for Time-Series Generation | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 350 | Specformer: Spectral Graph Neural Networks Meet Transformers | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 351 | MetaP: How to Transfer Your Knowledge on Learning Hidden Physics | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 352 | CommsVAE: Learning the brain"s macroscale communication dynamics using coupled sequential VAEs | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 353 | Beyond the injective assumption in causal representation learning | 4.50 | 4.50 | 0.00 | [3, 6, 3, 6]
|
| 354 | Answer Me if You Can: Debiasing Video Question Answering via Answering Unanswerable Questions | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 355 | Language Models Can (kind of) Reason: A Systematic Formal Analysis of Chain-of-Thought | 5.80 | 5.80 | 0.00 | [6, 5, 5, 5, 8]
|
| 356 | Approximation ability of Transformer networks for functions with various smoothness of Besov spaces: error analysis and token extraction | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 357 | Clustering Embedding Tables, Without First Learning Them | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 358 | Architecture Matters in Continual Learning | 5.33 | 5.33 | 0.00 | [5, 8, 3]
|
| 359 | Machine Learning Force Fields with Data Cost Aware Training | 4.25 | 4.25 | 0.00 | [5, 3, 6, 3]
|
| 360 | Covariance Matrix Adaptation MAP-Annealing | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 361 | Learning Rewards and Skills to Follow Commands with a Data Efficient Visual-Audio Representation | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 362 | Reinforcement Learning-Based Estimation for Partial Differential Equations | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 363 | Heterogeneous-Agent Mirror Learning | 5.75 | 5.75 | 0.00 | [6, 6, 3, 8]
|
| 364 | ADELT: Unsupervised Transpilation Between Deep Learning Frameworks | 6.00 | 6.00 | 0.00 | [8, 5, 6, 5]
|
| 365 | Recursive Time Series Data Augmentation | 6.00 | 6.00 | 0.00 | [10, 5, 3, 6]
|
| 366 | Auto-Encoding Goodness of Fit | 5.00 | 5.00 | 0.00 | [3, 5, 6, 6]
|
| 367 | VER: Learning Natural Language Representations for Verbalizing Entities and Relations | 3.75 | 3.75 | 0.00 | [6, 3, 3, 3]
|
| 368 | Adaptive IMLE for Few-shot Image Synthesis | 4.80 | 4.80 | 0.00 | [6, 3, 3, 6, 6]
|
| 369 | Understanding the Covariance Structure of Convolutional Filters | 5.00 | 5.25 | 0.25 | [3, 6, 6, 6]
|
| 370 | Reinforcement Logic Rule Learning for Temporal Point Processes | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 371 | On Making Graph Continual Learning Easy, Fool-Proof, and Extensive: a Benchmark Framework and Scenarios | 3.40 | 3.40 | 0.00 | [5, 1, 5, 3, 3]
|
| 372 | Masked Distillation with Receptive Tokens | 6.33 | 7.00 | 0.67 | [8, 8, 5]
|
| 373 | Robust Multivariate Time-Series Forecasting: Adversarial Attacks and Defense Mechanisms | 6.00 | 6.25 | 0.25 | [8, 5, 6, 6]
|
| 374 | TextShield: Beyond Successfully Detecting Adversarial Sentences in NLP | 5.75 | 5.75 | 0.00 | [5, 8, 5, 5]
|
| 375 | Efficient Deep Reinforcement Learning Requires Regulating Statistical Overfitting | 6.67 | 7.33 | 0.67 | [8, 6, 8]
|
| 376 | Nuisances via Negativa: Adjusting for Spurious Correlations via Data Augmentation | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 377 | GNN Domain Adaptation using Optimal Transport | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 378 | Ask Me Anything: A simple strategy for prompting language models | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 379 | MixBin: Towards Budgeted Binarization | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 380 | Limits of Algorithmic Stability for Distributional Generalization | 4.75 | 4.75 | 0.00 | [3, 8, 5, 3]
|
| 381 | WikiWhy: Answering and Explaining Cause-and-Effect Questions | 7.50 | 7.50 | 0.00 | [8, 8, 6, 8]
|
| 382 | Offline Reinforcement Learning with Differentiable Function Approximation is Provably Efficient | 6.50 | 6.50 | 0.00 | [6, 8, 6, 6]
|
| 383 | Do We Really Need Graph Models for Skeleton-Based Action Recognition? A Topology-Agnostic Approach with Fully-Connected Networks | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 384 | An Integrated Multi-Label Multi-Modal Framework in Deep Metric Learning | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 385 | Proto-Value Networks: Scaling Representation Learning with Auxiliary Tasks | 6.50 | 6.75 | 0.25 | [8, 6, 8, 5]
|
| 386 | Conservative Exploration in Linear MDPs under Episode-wise Constraints | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 387 | Pseudometric guided online query and update for offline reinforcement learning | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 388 | Efficient Data Subset Selection to Generalize Training Across Models: Transductive and Inductive Networks | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 389 | Probe Into Multi-agent Adversarial Reinforcement Learning through Mean-Field Optimal Control | 3.00 | 3.00 | 0.00 | [3, 5, 1, 3]
|
| 390 | Robust Algorithms on Adaptive Inputs from Bounded Adversaries | 6.75 | 7.00 | 0.25 | [8, 6, 6, 8]
|
| 391 | Chasing All-Round Graph Representation Robustness: Model, Training, and Optimization | 6.75 | 6.75 | 0.00 | [8, 8, 3, 8]
|
| 392 | Training Neural Networks with Low-Precision Model Memory | 3.75 | 3.75 | 0.00 | [3, 3, 6, 3]
|
| 393 | Raisin: Residual Algorithms for Versatile Offline Reinforcement Learning | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 394 | VQR: Automated Software Vulnerability Repair Through Vulnerability Queries | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 395 | Corruption-free Single-view Self-supervised Learning on Graphs | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 396 | Fully Online Meta Learning | 4.75 | 4.75 | 0.00 | [5, 1, 5, 8]
|
| 397 | Learning Globally Smooth Functions on Manifolds | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 398 | On Representing Mixed-Integer Linear Programs by Graph Neural Networks | 5.00 | 5.00 | 0.00 | [5, 1, 8, 6]
|
| 399 | LEARNING DYNAMIC ABSTRACT REPRESENTATIONS FOR SAMPLE-EFFICIENT REINFORCEMENT LEARNING | 3.00 | 4.33 | 1.33 | [3, 5, 5]
|
| 400 | Fighting Fire with Fire: Contrastive Debiasing without Bias-free Data via Generative Bias-transformation | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 401 | On Representing Linear Programs by Graph Neural Networks | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 402 | On the Importance and Applicability of Pre-Training for Federated Learning | 6.50 | 6.50 | 0.00 | [8, 5, 8, 5]
|
| 403 | Scale-invariant Bayesian Neural Networks with Connectivity Tangent Kernel | 5.50 | 6.50 | 1.00 | [6, 8, 6, 6]
|
| 404 | Autoregressive Graph Network for Learning Multi-step Physics | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 405 | Simple initialization and parametrization of sinusoidal networks via their kernel bandwidth | 6.75 | 7.00 | 0.25 | [6, 8, 6, 8]
|
| 406 | Who are playing the games? | 3.25 | 3.25 | 0.00 | [3, 1, 3, 6]
|
| 407 | Quasiconvex Shallow Neural Network | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 408 | The Best of Both Worlds: Accurate Global and Personalized Models through Federated Learning with Data-Free Hyper-Knowledge Distillation | 6.00 | 6.25 | 0.25 | [5, 8, 6, 6]
|
| 409 | Minimalistic Unsupervised Learning with the Sparse Manifold Transform | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 410 | Over-Training with Mixup May Hurt Generalization | 6.00 | 6.00 | 0.00 | [6, 8, 5, 5]
|
| 411 | HiCLIP: Contrastive Language-Image Pretraining with Hierarchy-aware Attention | 5.75 | 6.25 | 0.50 | [6, 8, 5, 6]
|
| 412 | Quantile Risk Control: A Flexible Framework for Bounding the Probability of High-Loss Predictions | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 413 | Text-Conditioned Graph Generation Using Discrete Graph Variational Autoencoders | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 414 | Dynamic Neural Network is All You Need: Understanding the Robustness of Dynamic Mechanisms in Neural Networks | 5.00 | 5.00 | 0.00 | [6, 1, 8]
|
| 415 | AutoMoE: Neural Architecture Search for Efficient Sparsely Activated Transformers | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 416 | Learning Shareable Bases for Personalized Federated Image Classification | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 417 | Curriculum-inspired Training for Selective Neural Networks | 4.80 | 4.80 | 0.00 | [3, 5, 5, 5, 6]
|
| 418 | Layer-wise Balanced Activation Mechanism | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 419 | A Probabilistic Framework For Modular Continual Learning | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 420 | Knowledge-Grounded Reinforcement Learning | 3.80 | 3.80 | 0.00 | [3, 5, 5, 3, 3]
|
| 421 | Git Re-Basin: Merging Models modulo Permutation Symmetries | 8.67 | 8.67 | 0.00 | [8, 8, 10]
|
| 422 | The Tilted Variational Autoencoder: Improving Out-of-Distribution Detection | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 423 | The Role of Coverage in Online Reinforcement Learning | 7.00 | 7.00 | 0.00 | [8, 5, 8]
|
| 424 | Learning Mixture Models with Simultaneous Data Partitioning and Parameter Estimation | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 425 | Estimating Treatment Effects using Neurosymbolic Program Synthesis | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 426 | Stateful Active Facilitator: Coordination and Environmental Heterogeneity in Cooperative Multi-Agent Reinforcement Learning | 5.00 | 5.00 | 0.00 | [6, 3, 5, 6]
|
| 427 | UNDERSTANDING HTML WITH LARGE LANGUAGE MODELS | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 428 | KALM: Knowledge-Aware Integration of Local, Document, and Global Contexts for Long Document Understanding | 5.40 | 5.40 | 0.00 | [5, 5, 6, 5, 6]
|
| 429 | Kuiper: Moderated Asynchronous Federated Learning on Heterogeneous Mobile Devices with Non-IID Data | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 430 | Learning Achievement Structure for Structured Exploration in Domains with Sparse Reward | 6.50 | 6.50 | 0.00 | [5, 5, 8, 8]
|
| 431 | Semi-Autoregressive Energy Flows: Towards Determinant-Free Training of Normalizing Flows | 4.50 | 4.50 | 0.00 | [3, 6, 3, 6]
|
| 432 | PINTO: Faithful Language Reasoning Using Prompted-Generated Rationales | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 433 | State Decomposition for Model-free Partially observable Markov Decision Process | 1.50 | 1.50 | 0.00 | [1, 1, 3, 1]
|
| 434 | Game Theoretic Mixed Experts for Combinational Adversarial Machine Learning | 5.50 | 5.50 | 0.00 | [8, 6, 3, 5]
|
| 435 | Return Augmentation gives Supervised RL Temporal Compositionality | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 436 | Neural Integral Equations | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 437 | Excess Risk of Two-Layer ReLU Neural Networks in Teacher-Student Settings and its Superiority to Kernel Methods | 6.40 | 6.80 | 0.40 | [8, 8, 5, 5, 8]
|
| 438 | Automatic Data Augmentation via Invariance-Constrained Learning | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 439 | GEASS: Neural causal feature selection for high-dimensional biological data | 7.50 | 7.50 | 0.00 | [8, 6, 8, 8]
|
| 440 | Unsupervised 3D Scene Representation Learning via Movable Object Inference | 5.00 | 5.00 | 0.00 | [6, 6, 3, 5]
|
| 441 | FoveaTer: Foveated Transformer for Image Classification | 3.75 | 4.25 | 0.50 | [6, 5, 3, 3]
|
| 442 | Linearly Mapping from Image to Text Space | 6.25 | 6.25 | 0.00 | [6, 3, 8, 8]
|
| 443 | Actor-Critic Alignment for Offline-to-Online Reinforcement Learning | 4.80 | 4.80 | 0.00 | [6, 5, 3, 5, 5]
|
| 444 | Characterizing intrinsic compositionality in transformers with Tree Projections | 5.75 | 5.75 | 0.00 | [8, 6, 3, 6]
|
| 445 | What Do We Maximize in Self-Supervised Learning And Why Does Generalization Emerge? | 4.75 | 4.75 | 0.00 | [5, 5, 3, 6]
|
| 446 | SmartFRZ: An Efficient Training Framework using Attention-Based Layer Freezing | 6.20 | 6.20 | 0.00 | [8, 5, 5, 5, 8]
|
| 447 | Similarity-Based Cooperation | 5.00 | 5.25 | 0.25 | [5, 6, 5, 5]
|
| 448 | Consistent Data Distribution Sampling for Large-scale Retrieval | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 449 | NOVEL FEATURE REPRESENTATION STRATEGIES FOR TIME SERIES FORECASTING WITH PREDICTED FUTURE COVARIATES | 2.33 | 2.33 | 0.00 | [3, 1, 3]
|
| 450 | Augmentation Component Analysis: Modeling Similarity via the Augmentation Overlaps | 5.00 | 5.75 | 0.75 | [6, 3, 6, 8]
|
| 451 | Reproducible Bandits | 5.50 | 6.25 | 0.75 | [6, 6, 8, 5]
|
| 452 | Persistence-based Contrastive Learning with Graph Neural Recurrent Networks for Time-series Forecasting | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 453 | ACE-EM: Boosted ab initio Cryo-EM 3D Reconstruction with Asymmetric Complementary Autoencoder | 4.50 | 4.50 | 0.00 | [3, 3, 6, 6]
|
| 454 | Diffusion-based point cloud generation with smoothness constraints | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 455 | NEURAL HAMILTONIAN FLOWS IN GRAPH NEURAL NETWORKS | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 456 | Convergence Analysis of Split Learning on Non-IID Data | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 457 | Principal Trade-off Analysis | 6.00 | 6.00 | 0.00 | [8, 5, 3, 8]
|
| 458 | Neural Bregman Divergences for Distance Learning | 5.33 | 6.00 | 0.67 | [8, 3, 8, 5]
|
| 459 | Neural Autoregressive Refinement for Self-Supervised Outlier Detection beyond Images | 4.17 | 4.17 | 0.00 | [3, 6, 1, 5, 5, 5]
|
| 460 | Offline Reinforcement Learning from Heteroskedastic Data Via Support Constraints | 5.33 | 5.67 | 0.33 | [5, 6, 6]
|
| 461 | Finding Private Bugs: Debugging Implementations of Differentially Private Stochastic Gradient Descent | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 462 | Robust Generative Flows on Reliable Image Reconstruction without Training Data | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 463 | A Computationally Efficient Sparsified Online Newton Method | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 464 | TG-Gen: A Deep Generative Model Framework for Temporal Graphs | 3.75 | 3.75 | 0.00 | [3, 3, 6, 3]
|
| 465 | Solving Continual Learning via Problem Decomposition | 5.50 | 5.50 | 0.00 | [6, 3, 8, 5]
|
| 466 | Long Term Fairness via Performative Distributionally Robust Optimization | 5.25 | 5.25 | 0.00 | [5, 8, 3, 5]
|
| 467 | The In-Sample Softmax for Offline Reinforcement Learning | 7.33 | 7.33 | 0.00 | [8, 6, 8]
|
| 468 | LUNA: Language as Continuing Anchors for Referring Expression Comprehension | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 469 | Bias Propagation in Federated Learning | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 470 | A Study of Causal Confusion in Preference-Based Reward Learning | 5.20 | 5.40 | 0.20 | [3, 6, 5, 5, 8]
|
| 471 | UniKGQA: Unified Retrieval and Reasoning for Solving Multi-hop Question Answering Over Knowledge Graph | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 472 | Comparing Human and Machine Bias in Face Recognition | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 473 | Sufficient Subgraph Embedding Memory for Continual Graph Representation Learning | 4.75 | 4.75 | 0.00 | [3, 5, 8, 3]
|
| 474 | One cannot stand for everyone! Leveraging Multiple User Simulators to train Task-oriented Dialogue Systems | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 475 | Towards Out-of-Distribution Adversarial Robustness | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 476 | Is the Performance of My Deep Network Too Good to Be True? A Direct Approach to Estimating the Bayes Error in Binary Classification | 6.25 | 6.25 | 0.00 | [6, 8, 5, 6]
|
| 477 | Learning Deep Operator Networks: The Benefits of Over-Parameterization | 4.80 | 4.80 | 0.00 | [8, 5, 5, 3, 3]
|
| 478 | How Useful are Gradients for OOD Detection Really? | 5.50 | 5.50 | 0.00 | [6, 8, 3, 5]
|
| 479 | Many-Body Approximation for Tensors | 5.33 | 6.33 | 1.00 | [3, 8, 8]
|
| 480 | Faster Last-iterate Convergence of Policy Optimization in Zero-Sum Markov Games | 5.50 | 6.25 | 0.75 | [8, 6, 5, 6]
|
| 481 | Memorization Capacity of Neural Networks with Conditional Computation | 6.25 | 6.25 | 0.00 | [8, 8, 6, 3]
|
| 482 | On the Power of Pre-training for Generalization in RL: Provable Benefits and Hardness | 5.00 | 6.00 | 1.00 | [8, 5, 5]
|
| 483 | A Fast, Well-Founded Approximation to the Empirical Neural Tangent Kernel | 4.50 | 5.00 | 0.50 | [5, 5, 5, 5]
|
| 484 | Boosting Drug-Target Affinity Prediction from Nearest Neighbors | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 485 | Weighted Clock Logic Point Process | 6.50 | 6.50 | 0.00 | [5, 5, 8, 8]
|
| 486 | Simple Emergent Action Representations from Multi-Task Policy Training | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 487 | Iterative Task-adaptive Pretraining for Unsupervised Word Alignment | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 488 | Open-Set 3D Detection via Image-level Class and Debiased Cross-modal Contrastive Learning | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 489 | Tight Non-asymptotic Inference via Sub-Gaussian Intrinsic Moment Norm | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 490 | Interaction-Based Disentanglement of Entities for Object-Centric World Models | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 491 | CodeT5Mix: A Pretrained Mixture of Encoder-decoder Transformers for Code Understanding and Generation | 5.20 | 5.40 | 0.20 | [6, 3, 6, 6, 6]
|
| 492 | Neural Image-based Avatars: Generalizable Radiance Fields for Human Avatar Modeling | 6.25 | 6.25 | 0.00 | [8, 6, 3, 8]
|
| 493 | Federated Neural Bandits | 6.00 | 6.00 | 0.00 | [5, 6, 5, 8, 6]
|
| 494 | Compositional Task Representations for Large Language Models | 6.25 | 6.25 | 0.00 | [6, 5, 8, 6]
|
| 495 | What do large networks memorize? | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 496 | TILDE-Q: a Transformation Invariant Loss Function for Time-Series Forecasting | 5.20 | 5.20 | 0.00 | [1, 8, 8, 6, 3]
|
| 497 | Pretraining One Language Model for All With the Text-To-Text Framework Using Model-Generated Signals | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 498 | A Picture of the Space of Typical Learning Tasks | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 499 | Linear Mode Connectivity of Deep Neural Networks via Permutation Invariance and Renormalization | 5.33 | 5.67 | 0.33 | [8, 3, 6]
|
| 500 | Multi-View Masked Autoencoders for Visual Control | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 501 | Boosting Adversarial Training with Masked Adaptive Ensemble | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 502 | MILE: Memory-Interactive Learning Engine for Solving Mathematical Problems | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 503 | UNICO: Efficient Unified Hardware-Software Co-Optimization For Deep Neural Networks | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 504 | Diffusion-GAN: Training GANs with Diffusion | 7.00 | 7.00 | 0.00 | [8, 8, 6, 6]
|
| 505 | Contextual Subspace Approximation with Neural Householder Transforms | 6.00 | 6.00 | 0.00 | [5, 5, 8]
|
| 506 | Mind the Pool: Convolutional Neural Networks Can Overfit Input Size | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 507 | Towards Unsupervised Time Series Representation Learning: A Decomposition Perspective | 4.50 | 4.50 | 0.00 | [3, 3, 6, 6]
|
| 508 | Reparameterization through Spatial Gradient Scaling | 6.75 | 6.75 | 0.00 | [8, 6, 8, 5]
|
| 509 | Boomerang: Local sampling on image manifolds using diffusion models | 4.25 | 4.25 | 0.00 | [3, 8, 3, 3]
|
| 510 | TOWARD RELIABLE NEURAL SPECIFICATIONS | 4.75 | 4.75 | 0.00 | [3, 8, 5, 3]
|
| 511 | A second order regression model shows edge of stability behavior | 6.00 | 6.20 | 0.20 | [5, 6, 6, 8, 6]
|
| 512 | Learning Frequency-aware Network for Continual Learning | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 513 | Unsupervised Learning for Combinatorial Optimization Needs Meta Learning | 6.25 | 6.25 | 0.00 | [6, 5, 8, 6]
|
| 514 | Latent Topology Induction for Understanding Contextualized Representations | 4.25 | 4.25 | 0.00 | [5, 6, 1, 5]
|
| 515 | DyG2Vec: Representation Learning for Dynamic Graphs With Self-supervision | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 516 | Unsupervised Meta-learning via Few-shot Pseudo-supervised Contrastive Learning | 6.25 | 6.25 | 0.00 | [8, 3, 8, 6]
|
| 517 | PromptBoosting: Black-Box Text Classification with Ten Forward Passes | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 518 | Decepticons: Corrupted Transformers Breach Privacy in Federated Learning for Language Models | 6.25 | 6.60 | 0.35 | [8, 8, 8, 1, 8]
|
| 519 | Adaptive Optimization in the $\infty$-Width Limit | 5.75 | 6.50 | 0.75 | [8, 5, 8, 5]
|
| 520 | Pyramidal Denoising Diffusion Probabilistic Models | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 521 | Guiding Energy-based Models via Contrastive Latent Variables | 6.75 | 6.75 | 0.00 | [8, 5, 8, 6]
|
| 522 | Deep Watermarks for Attributing Generative Models | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 523 | Steerable Equivariant Representation Learning | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 524 | Differentially Private Diffusion Models | 5.33 | 5.33 | 0.00 | [3, 5, 8]
|
| 525 | Outlier-Robust Group Inference via Gradient Space Clustering | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 526 | Broken Neural Scaling Laws | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 527 | Learning to perceive objects by prediction | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 528 | Avoiding spurious correlations via logit correction | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 529 | LEARNING CONTEXT-AWARE ADAPTIVE SOLVERS TO ACCELERATE QUADRATIC PROGRAMMING | 6.00 | 6.00 | 0.00 | [8, 5, 5]
|
| 530 | Learning Latent Structural Causal Models | 5.00 | 5.00 | 0.00 | [3, 8, 3, 3, 8]
|
| 531 | Pre-Training for Robots: Leveraging Diverse Multitask Data via Offline Reinforcement Learning | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 532 | Safe Exploration Incurs Nearly No Additional Sample Complexity for Reward-Free RL | 5.25 | 5.25 | 0.00 | [5, 5, 3, 8]
|
| 533 | S$^6$-DAMON: Bridging Self-Supervised Speech Models and Real-time Speech Recognition | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 534 | Teaching Algorithmic Reasoning via In-context Learning | 5.33 | 5.33 | 0.00 | [8, 3, 5]
|
| 535 | Offline Q-learning on Diverse Multi-Task Data Both Scales And Generalizes | 7.25 | 8.00 | 0.75 | [8, 10, 6, 8]
|
| 536 | Disentangled Conditional Variational Autoencoder for Unsupervised Anomaly Detection | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 537 | Diffusion-based Image Translation using disentangled style and content representation | 6.50 | 6.50 | 0.00 | [6, 6, 6, 8]
|
| 538 | An Analytic Framework for Robust Training of Differentiable Hypothesis | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 539 | Federated Learning with Heterogeneous Label Noise: A Dual Structure Approach | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 540 | Correspondences between word learning in children and captioning models | 2.50 | 2.50 | 0.00 | [3, 1, 3, 3]
|
| 541 | Mixture of Quantized Experts (MoQE): Complementary Effect of Low-bit Quantization and Robustness | 4.00 | 4.00 | 0.00 | [5, 3, 3, 3, 6]
|
| 542 | Implicit Regularization for Group Sparsity | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 543 | Why do Models with Conditional Computation Learn Suboptimal Solutions? | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 544 | Stabilized training of joint energy-based models and its practical applications | 2.50 | 2.50 | 0.00 | [3, 1, 3, 3]
|
| 545 | HesScale: Scalable Computation of Hessian Diagonals | 5.50 | 6.00 | 0.50 | [8, 3, 5, 8]
|
| 546 | Adaptive Anchor for Robust Keypoint Localization | 4.25 | 4.25 | 0.00 | [5, 5, 1, 6]
|
| 547 | Divide-and-Cluster: Spatial Decomposition Based Hierarchical Clustering | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 548 | Implicit regularization in Heavy-ball momentum accelerated stochastic gradient descent | 6.25 | 7.00 | 0.75 | [8, 6, 8, 6]
|
| 549 | ORCA: Interpreting Prompted Language Models via Locating Supporting Evidence in the Ocean of Pretraining Data | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 550 | Getting away with more network pruning: From sparsity to geometry and linear regions | 4.25 | 4.25 | 0.00 | [5, 3, 8, 1]
|
| 551 | Real-time variational method for learning neural trajectory and its dynamics | 7.00 | 7.00 | 0.00 | [8, 6, 6, 8]
|
| 552 | Supervised Metric Learning for Retrieval via Contextual Similarity Optimization | 4.75 | 4.75 | 0.00 | [3, 5, 8, 3]
|
| 553 | Large Language Models are Human-Level Prompt Engineers | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 554 | Do Not Blindly Imitate the Teacher: Loss Perturbation for Knowledge Distillation | 4.67 | 4.67 | 0.00 | [8, 3, 3]
|
| 555 | Fast Yet Effective Graph Unlearning through Influence Analysis | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 556 | Faster Hyperparameter Search for GNNs via Calibrated Dataset Condensation | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 557 | FedTiny: Pruned Federated Learning Towards Specialized Tiny Models | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 558 | Spatiotemporal Modeling of Multivariate Signals with Graph Neural Networks and Structured State Space Models | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 559 | TI-VAE: A temporally independent VAE with applications to latent factor learning in neuroimaging | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 560 | Pruning Deep Neural Networks from a Sparsity Perspective | 6.25 | 6.25 | 0.00 | [5, 8, 6, 6]
|
| 561 | High-dimensional Continuum Armed and High-dimensional Contextual Bandit: with Applications to Assortment and Pricing | 4.25 | 4.75 | 0.50 | [6, 5, 3, 5]
|
| 562 | What learning algorithm is in-context learning? Investigations with linear models | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 563 | Learning to represent and predict evolving visual signals via polar straightening | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 564 | Protecting Bidder Information in Neural Auctions | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 565 | On Representation Learning Under Class Imbalance | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 566 | Gradient Descent Converges Linearly for Logistic Regression on Separable Data | 6.75 | 6.75 | 0.00 | [6, 8, 5, 8]
|
| 567 | Interpretable (meta)factorization of clinical questionnaires to identify general dimensions of psychopathology | 5.00 | 5.40 | 0.40 | [5, 8, 8, 3, 3]
|
| 568 | Enhancing Meta Learning via Multi-Objective Soft Improvement Functions | 5.67 | 5.67 | 0.00 | [6, 8, 3]
|
| 569 | Discrete Predictor-Corrector Diffusion Models for Image Synthesis | 7.33 | 7.33 | 0.00 | [8, 6, 8]
|
| 570 | Instruction-Following Agents with Jointly Pre-Trained Vision-Language Models | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 571 | Infusing Lattice Symmetry Priors in Neural Networks Using Soft Attention Masks | 5.40 | 5.40 | 0.00 | [6, 5, 5, 6, 5]
|
| 572 | Counterfactual Vision-Language Data Synthesis with Intra-Sample Contrast Learning | 2.00 | 2.00 | 0.00 | [1, 1, 3, 3]
|
| 573 | META-LEARNING FOR UNSUPERVISED OUTLIER DETECTION WITH OPTIMAL TRANSPORT | 3.00 | 3.00 | 0.00 | [3, 3, 1, 5]
|
| 574 | GPTQ: Accurate Quantization for Generative Pre-trained Transformers | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 575 | Domain-Invariant Auxiliary Learning for Robust Few-Shot Predictions from Noisy Data | 4.50 | 4.50 | 0.00 | [6, 6, 3, 3]
|
| 576 | Attentive MLP for Non-Autoregressive Generation | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 577 | ConserWeightive Behavioral Cloning for Reliable Offline Reinforcement Learning | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 578 | Dynamics Model Based Adversarial Training For Competitive Reinforcement Learning | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 579 | ADVL: Adaptive Distillation for Vision-Language Tasks | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 580 | A new characterization of the edge of stability based on a sharpness measure aware of batch gradient distribution | 5.33 | 5.67 | 0.33 | [5, 6, 6]
|
| 581 | Finding the smallest tree in the forest: Monte Carlo Forest Search for UNSAT solving | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 582 | $\mathrm{SE}(3)$-Equivariant Attention Networks for Shape Reconstruction in Function Space | 6.00 | 6.25 | 0.25 | [6, 8, 6, 5]
|
| 583 | PBES: PCA Based Exemplar Sampling Algorithm for Continual Learning | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 584 | 3D-IntPhys: Learning 3D Visual Intuitive Physics for Fluids, Rigid Bodies, and Granular Materials | 5.25 | 5.25 | 0.00 | [3, 5, 3, 10]
|
| 585 | Continual Post-Training of Language Models | 5.33 | 4.75 | -0.58 | [3, 5, 3, 8]
|
| 586 | Min-Max Multi-objective Bilevel Optimization with Applications in Robust Machine Learning | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 587 | The Plug and Play of Language Models for Text-to-image Generation | 5.00 | 5.00 | 0.00 | [6, 3, 6, 5]
|
| 588 | Learning Arborescence with An Efficient Inference Algorithm | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 589 | Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning | 8.25 | 8.25 | 0.00 | [5, 10, 10, 8]
|
| 590 | A Score-Based Model for Learning Neural Wavefunctions | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 591 | Benchmarking Algorithms for Domain Generalization in Federated Learning | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 592 | The Vendi Score: A Diversity Evaluation Metric for Machine Learning | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 593 | How Can GANs Learn Hierarchical Generative Models for Real-World Distributions | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 594 | Spotlight: Mobile UI Understanding using Vision-Language Models with a Focus | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 595 | A Control-Centric Benchmark for Video Prediction | 5.75 | 5.75 | 0.00 | [6, 8, 3, 6]
|
| 596 | Continual Learning Based on Sub-Networks and Task Similarity | 5.25 | 4.75 | -0.50 | [5, 3, 6, 5]
|
| 597 | A Stable and Scalable Method for Solving Initial Value PDEs with Neural Networks | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 598 | Shallow Learning In Materio. | 2.00 | 2.00 | 0.00 | [3, 1, 1, 3]
|
| 599 | How Can Deep Learning Performs Deep (Hierarchical) Learning | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 600 | Data Subset Selection via Machine Teaching | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 601 | Do Summarization Models Synthesize? | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 602 | CHiLS: Zero-Shot Image Classification with Hierarchical Label Sets | 4.00 | 4.75 | 0.75 | [5, 6, 3, 5]
|
| 603 | Multi-Grid Tensorized Fourier Neural Operator for High Resolution PDEs | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 604 | $\beta$-Stochastic Sign SGD: A Byzantine Resilient and Differentially Private Gradient Compressor for Federated Learning | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 605 | Sequential Brick Assembly with Efficient Constraint Satisfaction | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 606 | Cross-Domain Self-Supervised Deep Learning for Robust Alzheimer"s Disease Progression Modeling | 3.00 | 3.00 | 0.00 | [5, 1, 3, 3]
|
| 607 | Data-Efficient Finetuning Using Cross-Task Nearest Neighbors | 5.75 | 5.75 | 0.00 | [6, 8, 3, 6]
|
| 608 | Heavy-tailed Noise Does Not Explain the Gap Between SGD and Adam, but Sign Descent Might | 5.25 | 5.75 | 0.50 | [6, 5, 6, 6]
|
| 609 | BiAdam: Fast Adaptive Bilevel Optimization Methods | 6.00 | 6.00 | 0.00 | [3, 5, 8, 8]
|
| 610 | Building Normalizing Flows with Stochastic Interpolants | 5.50 | 5.50 | 0.00 | [3, 6, 5, 8]
|
| 611 | Elicitation Inference Optimization for Multi-Principal-Agent Alignment | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 612 | Dual Student Networks for Data-Free Model Stealing | 5.00 | 5.00 | 0.00 | [6, 3, 3, 8]
|
| 613 | Augmentation Curriculum Learning For Generalization in RL | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 614 | Composite Slice Transformer: An Efficient Transformer with Composition of Multi-Scale Multi-Range Attentions | 6.25 | 6.25 | 0.00 | [5, 8, 6, 6]
|
| 615 | Graph Fourier MMD for signals on data graphs | 4.25 | 4.25 | 0.00 | [3, 5, 3, 6]
|
| 616 | Equal Improvability: A New Fairness Notion Considering the Long-term Impact | 5.00 | 5.00 | 0.00 | [6, 3, 6, 5]
|
| 617 | Does progress on ImageNet transfer to real world datasets? | 5.50 | 5.50 | 0.00 | [5, 6, 8, 3]
|
| 618 | Competitive Physics Informed Networks | 5.50 | 6.25 | 0.75 | [3, 8, 6, 8]
|
| 619 | Decomposed Prompting: A Modular Approach for Solving Complex Tasks | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 620 | Designing and Using Goal-Conditioned Tools | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 621 | Post-mortem on a deep learning contest: a Simpson’s paradox and the complementary roles of scale metrics versus shape metrics | 3.25 | 3.25 | 0.00 | [6, 1, 3, 3]
|
| 622 | ProtFIM: Fill-in-Middle Protein Sequence Design via Protein Language Models | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 623 | Beyond Deep Learning: An Evolutionary Feature Engineering Approach to Tabular Data Classification | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 624 | Proportional Multicalibration | 4.25 | 4.25 | 0.00 | [6, 3, 3, 5]
|
| 625 | On The Impact of Machine Learning Randomness on Group Fairness | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 626 | Using the Training History to Detect and Prevent Overfitting in Deep Learning Models | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 627 | Multi-scale Sinusoidal Embeddings Enable Learning on High Resolution Mass Spectrometry Data | 3.67 | 3.67 | 0.00 | [1, 5, 5]
|
| 628 | Self-Ensemble Protection: Training Checkpoints Are Good Data Protectors | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 629 | Efficient parametric approximations of neural net function space distance | 5.25 | 5.75 | 0.50 | [5, 5, 5, 8]
|
| 630 | Systematic Generalization and Emergent Structures in Transformers Trained on Structured Tasks | 3.00 | 3.00 | 0.00 | [3, 1, 5]
|
| 631 | Energy-Inspired Self-Supervised Pretraining for Vision Models | 5.50 | 6.83 | 1.33 | [8, 6, 10, 6, 5, 6]
|
| 632 | Effectively Modeling Time Series with Simple Discrete State Spaces | 4.25 | 4.25 | 0.00 | [8, 3, 3, 3]
|
| 633 | Forgetful causal masking makes causal language models better zero-shot learners | 4.00 | 4.50 | 0.50 | [3, 6, 6, 3]
|
| 634 | When and why Vision-Language Models behave like Bags-of-Words, and what to do about it? | 7.00 | 7.00 | 0.00 | [8, 8, 6, 6]
|
| 635 | A Time Series is Worth 64 Words: Long-term Forecasting with Transformers | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 636 | Protecting DNN from Evasion Attacks using Ensemble of High Focal Diversity | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 637 | Fantastic Rewards and How to Tame Them: A Case Study on Reward Learning for Task-Oriented Dialogue Systems | 6.33 | 6.25 | -0.08 | [6, 5, 8, 6]
|
| 638 | Efficient Stochastic Optimization for Attacking Randomness Involved Inference | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 639 | Supervision Complexity and its Role in Knowledge Distillation | 6.33 | 6.33 | 0.00 | [6, 5, 8]
|
| 640 | GLINKX: A Scalable Unified Framework For Homophilous and Heterophilous Graphs | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 641 | Marich: A Query-efficient & Online Model Extraction Attack using Public Data | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 642 | CORE-PERIPHERY PRINCIPLE GUIDED REDESIGN OF SELF-ATTENTION IN TRANSFORMERS | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 643 | Lovasz Theta Contrastive Learning | 6.00 | 6.00 | 0.00 | [3, 6, 10, 5]
|
| 644 | Transferable Unlearnable Examples | 5.67 | 5.50 | -0.17 | [5, 6, 5, 6]
|
| 645 | MUG: Interactive Multimodal Grounding on User Interfaces | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 646 | Tabular Deep Learning when $d \gg n$ by Using an Auxiliary Knowledge Graph | 4.25 | 4.25 | 0.00 | [8, 5, 3, 1]
|
| 647 | Random Laplacian Features for Learning with Hyperbolic Space | 5.67 | 5.67 | 0.00 | [3, 8, 6]
|
| 648 | Replay Memory as An Empirical MDP: Combining Conservative Estimation with Experience Replay | 5.50 | 6.00 | 0.50 | [6, 5, 5, 8]
|
| 649 | Neural Causal Models for Counterfactual Identification and Estimation | 6.33 | 7.33 | 1.00 | [8, 8, 6]
|
| 650 | Connecting representation and generation via masked vision-language transformer | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 651 | Is margin all you need? An extensive empirical study of active learning on tabular data | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 652 | Momentum Stiefel Optimizer, with Applications to Suitably-Orthogonal Attention, and Optimal Transport | 6.75 | 6.75 | 0.00 | [10, 6, 5, 6]
|
| 653 | Target Conditioned Representation Independence (TCRI); from Domain-Invariant to Domain-General Representations | 5.00 | 5.00 | 0.00 | [6, 6, 3, 5]
|
| 654 | Multi-Task Option Learning and Discovery for Stochastic Path Planning | 5.00 | 5.00 | 0.00 | [6, 6, 3, 5]
|
| 655 | MolEBM: Molecule Generation and Design by Latent Space Energy-Based Modeling | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 656 | Information-Theoretic Diffusion | 6.25 | 6.25 | 0.00 | [8, 6, 6, 5]
|
| 657 | Bandwith Enables Generalization in Quantum Kernel Models | 5.00 | 5.00 | 0.00 | [3, 8, 6, 3]
|
| 658 | Giving Robots a Hand: Broadening Generalization via Hand-Centric Human Video Demonstrations | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 659 | SpENCNN: Orchestrating Encoding and Sparsity for Fast Homomorphically Encrypted Neural Network Inference | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 660 | No Pairs Left Behind: Improving Metric Learning with Regularized Triplet Objective | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 661 | Minimal Value-Equivalent Partial Models for Scalable and Robust Planning in Lifelong Reinforcement Learning | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 662 | Gradient Preconditioning for Non-Lipschitz smooth Nonconvex Optimization | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 663 | Predictive Coding with Approximate Laplace Monte Carlo | 3.75 | 3.75 | 0.00 | [3, 3, 6, 3]
|
| 664 | What Spurious Features Can Pretrained Language Models Combat? | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 665 | SIMPLE: A Gradient Estimator for k-Subset Sampling | 4.50 | 5.25 | 0.75 | [6, 6, 3, 6]
|
| 666 | Transformers Implement First-Order Logic with Majority Quantifiers | 5.00 | 5.00 | 0.00 | [3, 5, 6, 3, 8]
|
| 667 | Robustness Evaluation Using Local Substitute Networks | 2.50 | 2.50 | 0.00 | [3, 1, 3, 3]
|
| 668 | Learning Iterative Neural Optimizers for Image Steganography | 7.00 | 7.00 | 0.00 | [8, 8, 6, 6]
|
| 669 | Graph Neural Networks as Multi-View Learning | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 670 | Cramming: Training a language model on a single GPU in one day | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 671 | BertNet: Harvesting Knowledge Graphs from Pretrained Language Models | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 672 | How Hard is Trojan Detection in DNNs? Fooling Detectors With Evasive Trojans | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 673 | Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 674 | Label-Free Synthetic Pretraining of Object Detectors | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 675 | Confidence-Conditioned Value Functions for Offline Reinforcement Learning | 5.50 | 6.25 | 0.75 | [5, 6, 8, 6]
|
| 676 | Current Anomaly Detectors are Anomalous: On Semantic Treatment of OOD Inputs | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 677 | FedX: Federated Learning for Compositional Pairwise Risk Optimization | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 678 | On the Sensitivity of Reward Inference to Misspecified Human Models | 6.75 | 6.75 | 0.00 | [8, 3, 8, 8]
|
| 679 | DeepDFA: Dataflow Analysis-Guided Efficient Graph Learning for Vulnerability Detection | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 680 | Probability flow solution of the Fokker-Planck equation | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 681 | Binding Language Models in Symbolic Languages | 7.33 | 8.00 | 0.67 | [8, 8, 8]
|
| 682 | Probabilistic Categorical Adversarial Attack and Adversarial Training | 5.25 | 5.25 | 0.00 | [3, 5, 5, 8]
|
| 683 | Multi-Sample Contrastive Neural Topic Model as Multi-Task Learning | 5.00 | 5.00 | 0.00 | [6, 3, 8, 3]
|
| 684 | Time Will Tell: New Outlooks and A Baseline for Temporal Multi-View 3D Object Detection | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 685 | Less Is More: Training on Low-Fidelity Images Improves Robustness to Adversarial Attacks | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 686 | Greedy Information Maximization for Online Feature Selection | 4.50 | 4.50 | 0.00 | [5, 5, 3, 3, 5, 6]
|
| 687 | Towards Fair Classification against Poisoning Attacks | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 688 | Unveiling Transformers with LEGO: A Synthetic Reasoning Task | 5.75 | 5.75 | 0.00 | [6, 6, 3, 8]
|
| 689 | How Much Data Are Augmentations Worth? An Investigation into Scaling Laws, Invariance, and Implicit Regularization | 6.50 | 6.75 | 0.25 | [8, 5, 8, 6]
|
| 690 | Spatial Reasoning Network for Zero-shot Constrained Scene Generation | 3.00 | 3.00 | 0.00 | [3, 1, 5]
|
| 691 | Robust Graph Dictionary Learning | 6.25 | 6.75 | 0.50 | [8, 5, 6, 8]
|
| 692 | Matrix factorization under the constraint of connectivity between observed and source data ~ Muscle synergy analysis based on connectivity between muscle and brain activities ~ | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 693 | Fundamental limits on the robustness of image classifiers | 6.40 | 7.00 | 0.60 | [8, 8, 5, 6, 8]
|
| 694 | Stochastic Constrained DRO with a Complexity Independent of Sample Size | 5.50 | 5.50 | 0.00 | [6, 8, 5, 3]
|
| 695 | Evolve Smoothly, Fit Consistently: Learning Smooth Latent Dynamics For Advection-Dominated Systems | 7.33 | 7.33 | 0.00 | [6, 8, 8]
|
| 696 | Dissecting adaptive methods in GANs | 5.25 | 5.25 | 0.00 | [3, 5, 5, 8]
|
| 697 | Recycling Scraps: Improving Private Learning by Leveraging Intermediate Checkpoints | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 698 | Understanding Influence Functions and Datamodels via Harmonic Analysis | 6.25 | 6.25 | 0.00 | [5, 6, 6, 8]
|
| 699 | BC-IRL: Learning Generalizable Reward Functions from Demonstrations | 5.33 | 6.33 | 1.00 | [8, 8, 3]
|
| 700 | TextGrad: Advancing Robustness Evaluation in NLP by Gradient-Driven Optimization | 6.25 | 6.25 | 0.00 | [5, 8, 6, 6]
|
| 701 | Robustness for Free: Adversarially Robust Anomaly Detection Through Diffusion Model | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 702 | Optimal control neural networks for data-driven discovery of gradient flows. | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 703 | ErrorAug: Making Errors to Find Errors in Semantic Segmentation | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 704 | Kernel Regression with Infinite-Width Neural Networks on Millions of Examples | 5.50 | 5.50 | 0.00 | [6, 5, 3, 8]
|
| 705 | Information Plane Analysis for Dropout Neural Networks | 6.00 | 6.00 | 0.00 | [3, 8, 8, 5]
|
| 706 | Fed-Cor: Federated Correlation Test with Secure Aggregation | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 707 | Feasible Adversarial Robust Reinforcement Learning for Underspecified Environments | 5.00 | 5.00 | 0.00 | [8, 6, 3, 3]
|
| 708 | Dynamical systems embedding with a physics-informed convolutional network | 6.25 | 6.25 | 0.00 | [6, 6, 8, 5]
|
| 709 | Learning Harmonic Molecular Representations on Riemannian Manifold | 6.00 | 6.50 | 0.50 | [6, 6, 6, 8]
|
| 710 | When is Offline Hyperparameter Selection Feasible for Reinforcement Learning? | 5.25 | 5.50 | 0.25 | [6, 5, 5, 6]
|
| 711 | Plansformer: Generating Multi-Domain Symbolic Plans using Transformers | 5.00 | 4.25 | -0.75 | [5, 3, 6, 3]
|
| 712 | Greedy Actor-Critic: A New Conditional Cross-Entropy Method for Policy Improvement | 6.00 | 6.33 | 0.33 | [5, 8, 6]
|
| 713 | VISION TRANSFORMER FOR MULTIVARIATE TIME- SERIES CLASSIFICATION (VITMTSC) | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 714 | Multi-Environment Pretraining Enables Transfer to Action Limited Datasets | 5.00 | 5.00 | 0.00 | [8, 3, 5, 3, 6]
|
| 715 | Preserving In-Context Learning Ability in Large Language Model Fine-tuning | 4.25 | 4.25 | 0.00 | [3, 5, 3, 6]
|
| 716 | Efficiently Controlling Multiple Risks with Pareto Testing | 5.75 | 5.75 | 0.00 | [3, 6, 8, 6]
|
| 717 | Graph Mixup with Soft Alignments | 4.60 | 4.60 | 0.00 | [5, 3, 6, 6, 3]
|
| 718 | CNN Compression and Search Using Set Transformations with Width Modifiers on Network Architectures | 2.33 | 2.33 | 0.00 | [3, 3, 1]
|
| 719 | Event-former: A Self-supervised Learning Paradigm for Temporal Point Processes | 4.00 | 4.00 | 0.00 | [6, 6, 1, 3]
|
| 720 | Learning Interpretable Dynamics from Images of a Freely Rotating 3D Rigid Body | 6.25 | 6.25 | 0.00 | [8, 6, 5, 6]
|
| 721 | NOTELA: A Generalizable Method for Source Free Domain Adaptation | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 722 | Characteristic Neural Ordinary Differential Equation | 6.25 | 6.25 | 0.00 | [8, 6, 5, 6]
|
| 723 | Fast Sampling of Diffusion Models with Exponential Integrator | 5.00 | 5.50 | 0.50 | [5, 5, 6, 6]
|
| 724 | STay-On-the-Ridge (STON"R): Guaranteed Convergence to Local Minimax Equilibrium in Nonconvex-Nonconcave Games | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 725 | Federated Representation Learning via Maximal Coding Rate Reduction | 3.00 | 3.00 | 0.00 | [3, 5, 3, 1]
|
| 726 | 3D Surface Reconstruction in the Wild by Deforming Shape Priors from Synthetic Data | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 727 | gDDIM: Generalized denoising diffusion implicit models | 7.25 | 7.25 | 0.00 | [5, 8, 8, 8]
|
| 728 | Panning for Gold in Federated Learning: Targeted Text Extraction under Arbitrarily Large-Scale Aggregation | 5.40 | 5.40 | 0.00 | [6, 6, 6, 6, 3]
|
| 729 | Artificial Neuronal Ensembles with Learned Context Dependent Gating | 6.50 | 6.50 | 0.00 | [8, 5, 8, 5]
|
| 730 | Linkless Link Prediction via Relational Distillation | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 731 | Controllable Concept Transfer of Intermediate Representations | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 732 | A Differentiable Loss Function for Learning Heuristics in A* | 4.75 | 5.50 | 0.75 | [6, 5, 3, 8]
|
| 733 | Understanding Multi-Task Scaling in Machine Translation | 6.00 | 6.00 | 0.00 | [5, 5, 6, 8]
|
| 734 | Learning Language Representations with Logical Inductive Bias | 7.33 | 7.33 | 0.00 | [8, 8, 6]
|
| 735 | AsymQ: Asymmetric Q-loss to mitigate overestimation bias in off-policy reinforcement learning | 4.75 | 4.75 | 0.00 | [3, 8, 3, 5]
|
| 736 | Movement-to-Action Transformer Networks for Temporal Action Proposal Generation | 5.00 | 5.00 | 0.00 | [8, 6, 3, 3]
|
| 737 | INSPIRE: A Framework for Integrating Individual User Preferences in Recourse | 5.60 | 5.60 | 0.00 | [8, 6, 6, 5, 3]
|
| 738 | How Does Self-supervised Learning Work? A Representation Learning Perspective | 4.67 | 6.33 | 1.67 | [5, 8, 6]
|
| 739 | Empowering Graph Representation Learning with Test-Time Graph Transformation | 5.50 | 5.40 | -0.10 | [5, 8, 3, 6, 5]
|
| 740 | Provable Robustness against Wasserstein Distribution Shifts via Input Randomization | 5.33 | 5.67 | 0.33 | [6, 6, 5]
|
| 741 | GROOT: Corrective Reward Optimization for Generative Sequential Labeling | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 742 | Interpretations of Domain Adaptations via Layer Variational Analysis | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 743 | Forget Unlearning: Towards True Data-Deletion in Machine Learning | 6.25 | 6.25 | 0.00 | [6, 5, 6, 8]
|
| 744 | Meta-Learning with Explicit Task Information | 4.25 | 4.25 | 0.00 | [3, 1, 5, 8]
|
| 745 | Evaluating Unsupervised Denoising Requires Unsupervised Metrics | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 746 | Denoising Diffusion Samplers | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 747 | How I Learned to Stop Worrying and Love Retraining | 6.33 | 6.33 | 0.00 | [5, 8, 6]
|
| 748 | The Value of Out-of-distribution Data | 5.50 | 5.50 | 0.00 | [3, 6, 3, 10]
|
| 749 | Recursive Neural Programs: Variational Learning of Image Grammars and Part-Whole Hierarchies | 3.60 | 3.60 | 0.00 | [3, 3, 3, 6, 3]
|
| 750 | SaiT: Sparse Vision Transformers through Adaptive Token Pruning | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 751 | Cooperation or Competition: Avoiding Player Domination for Multi-target Robustness by Adaptive Budgets | 4.25 | 4.25 | 0.00 | [6, 3, 3, 5]
|
| 752 | Image Classification by Throwing Quantum Kitchen Sinks at Tensor Networks | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 753 | Cross-Domain Few-Shot Relation Extraction via Representation Learning and Domain Adaptation | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 754 | Factors Influencing Generalization in Chaotic Dynamical Systems | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 755 | Interpretable Geometric Deep Learning via Learnable Randomness Injection | 7.00 | 7.00 | 0.00 | [6, 6, 8, 8]
|
| 756 | Koopman Operator Learning for Accelerating Quantum Optimization and Machine Learning | 4.50 | 4.50 | 0.00 | [3, 6, 3, 6]
|
| 757 | GOGGLE: Generative Modelling for Tabular Data by Learning Relational Structure | 5.67 | 6.33 | 0.67 | [8, 3, 8]
|
| 758 | Query by Self | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 759 | A Reproducible and Realistic Evaluation of Partial Domain Adaptation Methods | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 760 | Progressive Prompts: Continual Learning for Language Models without Forgetting | 5.00 | 5.00 | 0.00 | [6, 3, 6, 5]
|
| 761 | Differentiable Rendering with Reparameterized Volume Sampling | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 762 | Deep Learning From Crowdsourced Labels: Coupled Cross-Entropy Minimization, Identifiability, and Regularization | 5.33 | 5.67 | 0.33 | [5, 6, 6]
|
| 763 | Maximum Likelihood Learning of Energy-Based Models for Simulation-Based Inference | 5.40 | 5.40 | 0.00 | [6, 5, 5, 8, 3]
|
| 764 | Just Avoid Robust Inaccuracy: Boosting Robustness Without Sacrificing Accuracy | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 765 | Projective Proximal Gradient Descent for Nonconvex Nonsmooth Optimization: Fast Convergence Without Kurdyka-Lojasiewicz (KL) Property | 4.50 | 4.50 | 0.00 | [3, 6, 6, 3]
|
| 766 | First Steps Toward Understanding the Extrapolation of Nonlinear Models to Unseen Domains | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 767 | A Kernel-Based View of Language Model Fine-Tuning | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 768 | Variable Compositionality Reliably Emerges in Neural Networks | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 769 | Systematic Rectification of Language Models via Dead-end Analysis | 6.33 | 6.33 | 0.00 | [6, 5, 8]
|
| 770 | Model-free Reinforcement Learning that Transfers Using Random Reward Features | 5.25 | 5.25 | 0.00 | [8, 5, 3, 5]
|
| 771 | Differentiable Channel Selection for Self-Attention | 4.25 | 4.25 | 0.00 | [5, 3, 3, 6]
|
| 772 | Membership Inference Attacks Against Text-to-image Generation Models | 4.25 | 4.25 | 0.00 | [3, 3, 5, 6]
|
| 773 | Multiple sequence alignment as a sequence-to-sequence learning problem | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 774 | Fair Graph Message Passing with Transparency | 4.25 | 4.25 | 0.00 | [3, 3, 5, 6]
|
| 775 | FedExP: Speeding up Federated Averaging via Extrapolation | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 776 | Graph Neural Networks Are More Powerful Than we Think | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 777 | A Mixture-of-Expert Approach to RL-based Dialogue Management | 6.20 | 6.20 | 0.00 | [8, 6, 3, 6, 8]
|
| 778 | A Retrieve-and-Read Framework for Knowledge Graph Reasoning | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 779 | f-DM: A Multi-stage Diffusion Model via Progressive Signal Transformation | 6.33 | 6.33 | 0.00 | [5, 8, 6]
|
| 780 | An Empirical Study of the Neural Contextual Bandit Algorithms | 2.50 | 3.00 | 0.50 | [3, 3, 3, 3]
|
| 781 | Backpropagation at the Infinitesimal Inference Limit of Energy-Based Models: Unifying Predictive Coding, Equilibrium Propagation, and Contrastive Hebbian Learning | 6.50 | 7.00 | 0.50 | [8, 6, 8, 6]
|
| 782 | A Theoretical Framework for Inference and Learning in Predictive Coding Networks | 7.25 | 7.25 | 0.00 | [8, 10, 3, 8]
|
| 783 | Causally-guided Regularization of Graph Attention improves Generalizability | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 784 | On a Benefit of Masked Language Model Pretraining: Robustness to Simplicity Bias | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 785 | FLGAME: A Game-theoretic Defense against Backdoor Attacks In Federated Learning | 3.50 | 3.50 | 0.00 | [3, 5, 1, 5]
|
| 786 | DeepReShape: Redesigning Neural Networks for Private Inference | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 787 | The Onset of Variance-Limited Behavior for Networks in the Lazy and Rich Regimes | 7.25 | 7.50 | 0.25 | [8, 6, 8, 8]
|
| 788 | Semi-Supervised Single Domain Generalization with Label-Free Adversarial Data Augmentation | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 789 | A Simple Approach for Visual Room Rearrangement: 3D Mapping and Semantic Search | 6.00 | 6.67 | 0.67 | [6, 8, 6]
|
| 790 | Memory Efficient Dynamic Sparse Training | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 791 | Accelerated Training via Principled Methods for Incrementally Growing Neural Networks | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 792 | Progressive Mix-Up for Few-Shot Supervised Multi-Source Domain Transfer | 5.33 | 5.25 | -0.08 | [5, 6, 5, 5]
|
| 793 | Mitigating Propagation Failures in PINNs using Evolutionary Sampling | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 794 | Revisiting Information-Based Clustering with Pseudo-Posterior Models | 3.33 | 3.33 | 0.00 | [3, 6, 1]
|
| 795 | Neural Compositional Rule Learning for Knowledge Graph Reasoning | 6.00 | 6.00 | 0.00 | [8, 5, 8, 3]
|
| 796 | Temporal Change Sensitive Representation for Reinforcement Learing | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 797 | Provably Efficient Reinforcement Learning for Online Adaptive Influence Maximization | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 798 | Fairness via Adversarial Attribute Neighbourhood Robust Learning | 4.40 | 4.40 | 0.00 | [3, 5, 6, 5, 3]
|
| 799 | Efficient approximation of neural population structure and correlations with probabilistic circuits | 6.00 | 6.00 | 0.00 | [5, 5, 6, 8]
|
| 800 | Exploring perceptual straightness in learned visual representations | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 801 | Improving Subgraph Representation Learning via Multi-View Augmentation | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 802 | Efficient Proxy for NAS is Extensible Now | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 803 | System identification of neural systems: If we got it right, would we know? | 4.67 | 4.67 | 0.00 | [3, 3, 8]
|
| 804 | TKIL: Tangent Kernel Optimization for Class Balanced Incremental Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 805 | Is Forgetting Less a Good Inductive Bias for Forward Transfer? | 5.00 | 6.50 | 1.50 | [6, 6, 6, 8]
|
| 806 | High-Precision Regressors for Particle Physics | 3.50 | 3.50 | 0.00 | [3, 5, 5, 1]
|
| 807 | Learning Structured Representations by Embedding Class Hierarchy | 5.75 | 5.75 | 0.00 | [5, 5, 5, 8]
|
| 808 | Promptagator: Few-shot Dense Retrieval From 8 Examples | 6.75 | 6.75 | 0.00 | [8, 8, 6, 5]
|
| 809 | Balance is Essence: Accelerating Sparse Training via Adaptive Gradient Correction | 4.75 | 5.00 | 0.25 | [5, 6, 3, 6]
|
| 810 | Brain-like representational straightening of natural movies in robust feedforward neural networks | 5.25 | 5.25 | 0.00 | [6, 6, 3, 6]
|
| 811 | FunkNN: Neural Interpolation for Functional Generation | 5.75 | 5.75 | 0.00 | [6, 6, 6, 5]
|
| 812 | A Framework for Comprehensive Evaluations of Graph Neural Network based Community Detection using Node Clustering | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 813 | TEXTCRAFT: ZERO-SHOT GENERATION OF HIGH FIDELITY AND DIVERSE SHAPES FROM TEXT | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 814 | CrystalBox: Efficient Model-Agnostic Explanations for Deep RL Controllers | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 815 | Label Propagation with Weak Supervision | 6.75 | 6.75 | 0.00 | [5, 6, 8, 8]
|
| 816 | TypeT5: Seq2seq Type Inference using Static Analysis | 5.60 | 6.40 | 0.80 | [6, 6, 6, 8, 6]
|
| 817 | Approximating any Function via Coreset for Radial Basis Functions: Towards Provable Data Subset Selection For Efficient Neural Networks training | 5.75 | 5.75 | 0.00 | [6, 6, 6, 5]
|
| 818 | Axiomatic Explainer Locality With Optimal Transport | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 819 | Fine-Tuning Offline Policies With Optimistic Action Selection | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 820 | Improving the Strength of Human-Like Models in Chess | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 821 | Test-Time Training on Video Streams | 3.50 | 3.50 | 0.00 | [1, 5, 3, 5]
|
| 822 | AGRO: Adversarial discovery of error-prone Groups for Robust Optimization | 6.00 | 6.00 | 0.00 | [8, 5, 5, 6]
|
| 823 | Learning Multiobjective Program Through Online Learning | 5.33 | 5.33 | 0.00 | [8, 5, 3]
|
| 824 | Dichotomy of Control: Separating What You Can Control from What You Cannot | 6.50 | 6.50 | 0.00 | [5, 8, 5, 8]
|
| 825 | Progressive Knowledge Distillation: Constructing Ensembles for Efficient Inference | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 826 | Efficient Approximations of Complete Interatomic Potentials for Crystal Property Prediction | 3.67 | 4.67 | 1.00 | [5, 6, 3]
|
| 827 | LogicDP: Creating Labels for Graph Data via Inductive Logic Programming | 5.50 | 5.50 | 0.00 | [8, 3, 5, 6]
|
| 828 | Simulating Environments for Evaluating Scarce Resource Allocation Policies | 5.00 | 4.25 | -0.75 | [1, 5, 3, 8]
|
| 829 | Domain Transfer with Large Dynamics Shift in Offline Reinforcement Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 830 | Learning to reason with relational abstractions | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 831 | A Simple Approach for State-Action Abstraction using a Learned MDP Homomorphism | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 832 | RankMe: Assessing the Downstream Performance of Pretrained Self-Supervised Representations by Their Rank | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 833 | Less is More: Task-aware Layer-wise Distillation for Language Model Compression | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 834 | Revisiting Curiosity for Exploration in Procedurally Generated Environments | 5.00 | 5.40 | 0.40 | [8, 5, 3, 8, 3]
|
| 835 | Online Learning for Obstacle Avoidance | 4.20 | 4.20 | 0.00 | [1, 5, 6, 6, 3]
|
| 836 | Transformer-based World Models Are Happy With 100k Interactions | 4.75 | 4.75 | 0.00 | [5, 3, 3, 8]
|
| 837 | Can Neural Networks Learn Implicit Logic from Physical Reasoning? | 6.20 | 6.20 | 0.00 | [8, 5, 6, 6, 6]
|
| 838 | Blockwise self-supervised learning with Barlow Twins | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 839 | DIGEST: FAST AND COMMUNICATION EFFICIENT DECENTRALIZED LEARNING WITH LOCAL UPDATES | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 840 | Learning to Improve Code Efficiency | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 841 | Real Data Distributions Prefer Simplicity and So Do Our Models: Why Machine Learning and Model Selection Are Possible | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 842 | ESCHER: Eschewing Importance Sampling in Games by Computing a History Value Function to Estimate Regret | 5.33 | 5.67 | 0.33 | [6, 5, 6]
|
| 843 | On Achieving Optimal Adversarial Test Error | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 844 | General Policy Evaluation and Improvement by Learning to Identify Few But Crucial States | 4.25 | 4.25 | 0.00 | [3, 5, 6, 3]
|
| 845 | Serving Graph Compression for Graph Neural Networks | 6.25 | 6.25 | 0.00 | [8, 8, 3, 6]
|
| 846 | Optimal Data Sampling for Training Neural Surrogates of Programs | 5.67 | 5.67 | 0.00 | [1, 8, 8]
|
| 847 | Towards Understanding GD with Hard and Conjugate Pseudo-labels for Test-Time Adaptation | 5.75 | 5.75 | 0.00 | [3, 8, 6, 6]
|
| 848 | Achieving Communication-Efficient Policy Evaluation for Multi-Agent Reinforcement Learning: Local TD-Steps or Batching? | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 849 | Learning where and when to reason in neuro-symbolic inference | 6.25 | 7.00 | 0.75 | [8, 6, 8, 6]
|
| 850 | Aging with GRACE: Lifelong Model Editing with Key-Value Adaptors | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 851 | A VAE for Transformers with Nonparametric Variational Information Bottleneck | 5.50 | 5.50 | 0.00 | [5, 6, 6, 5]
|
| 852 | Learning MLPs on Graphs: A Unified View of Effectiveness, Robustness, and Efficiency | 6.75 | 7.50 | 0.75 | [6, 8, 8, 8]
|
| 853 | On The Specialization of Neural Modules | 6.00 | 6.33 | 0.33 | [8, 5, 6]
|
| 854 | HomoDistil: Homotopic Task-Agnostic Distillation of Pre-trained Transformers | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 855 | Information-Theoretic Underpinnings of Generalization and Translation in Emergent Communication | 5.50 | 5.50 | 0.00 | [5, 8, 3, 6]
|
| 856 | Optimal Transport-Based Supervised Graph Summarization | 4.50 | 4.50 | 0.00 | [6, 6, 3, 3]
|
| 857 | Contrastive Vision Transformer for Self-supervised Out-of-distribution Detection | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 858 | Does the Half Adversarial Robustness Represent the Whole? It Depends... A Theoretical Perspective of Subnetwork Robustness | 4.25 | 4.25 | 0.00 | [5, 3, 6, 3]
|
| 859 | Using Both Demonstrations and Language Instructions to Efficiently Learn Robotic Tasks | 5.25 | 6.00 | 0.75 | [8, 6, 5, 5]
|
| 860 | Improving Accuracy and Explainability of Online Handwriting Recognition | 2.00 | 2.00 | 0.00 | [3, 1, 3, 1]
|
| 861 | On the duality between contrastive and non-contrastive self-supervised learning | 7.75 | 7.75 | 0.00 | [10, 8, 5, 8]
|
| 862 | Few-Shot Incremental Learning Using HyperTransformers | 4.25 | 4.25 | 0.00 | [6, 3, 3, 5]
|
| 863 | The Brainy Student: Scalable Unlearning by Selectively Disobeying the Teacher | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 864 | FIGARO: Controllable Music Generation using Learned and Expert Features | 6.25 | 6.25 | 0.00 | [8, 6, 6, 5]
|
| 865 | A Neural PDE Solver with Temporal Stencil Modeling | 5.50 | 5.50 | 0.00 | [3, 6, 8, 5]
|
| 866 | The Right Losses for the Right Gains: Improving the Semantic Consistency of Deep Text-to-Image Generation with Distribution-Sensitive Losses | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 867 | Selection Collider Bias in Large Language Models | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 868 | CausalBench: A Large-scale Benchmark for Network Inference from Single-cell Perturbation Data | 3.50 | 3.50 | 0.00 | [1, 3, 5, 5]
|
| 869 | Language models are multilingual chain-of-thought reasoners | 6.00 | 6.00 | 0.00 | [5, 6, 6, 5, 8, 6]
|
| 870 | DreamFusion: Text-to-3D using 2D Diffusion | 8.00 | 8.00 | 0.00 | [8, 8, 8, 8]
|
| 871 | Recitation-Augmented Language Models | 5.50 | 5.75 | 0.25 | [6, 6, 6, 5]
|
| 872 | Continual Active Learning | 3.00 | 3.00 | 0.00 | [1, 3, 5, 3]
|
| 873 | KwikBucks: Correlation Clustering with Cheap-Weak and Expensive-Strong Signals | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 874 | Credible, Sealed-bid, Optimal Repeated Auctions With Differentiable Economics | 5.50 | 5.50 | 0.00 | [3, 8, 8, 3]
|
| 875 | The Power of Feel-Good Thompson Sampling: A Unified Framework for Linear Bandits | 5.00 | 5.33 | 0.33 | [5, 5, 6]
|
| 876 | Two-Tailed Averaging: Anytime Adaptive Once-in-a-while Optimal Iterate Averaging for Stochastic Optimization | 4.67 | 4.67 | 0.00 | [3, 3, 8]
|
| 877 | Reward Design with Language Models | 5.00 | 5.50 | 0.50 | [5, 3, 6, 8]
|
| 878 | Calibrating the Rigged Lottery: Making All Tickets Reliable | 5.25 | 5.25 | 0.00 | [5, 5, 3, 8]
|
| 879 | Replay Buffer with Local Forgetting for Adaptive Deep Model-Based Reinforcement Learning | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 880 | Contrastive Audio-Visual Masked Autoencoder | 5.60 | 5.60 | 0.00 | [8, 6, 3, 6, 5]
|
| 881 | Pessimistic Model-Based Actor-Critic for Offline Reinforcement Learning: Theory and Algorithms | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 882 | The Asymmetric Maximum Margin Bias of Quasi-Homogeneous Neural Networks | 7.25 | 8.00 | 0.75 | [6, 8, 10, 8]
|
| 883 | Soft Diffusion: Score Matching For General Corruptions | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 884 | Open-Vocabulary Panoptic Segmentation MaskCLIP | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 885 | Robust Federated Learning with Majority Adversaries via Projection-based Re-weighting | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 886 | Double Wins: Boosting Accuracy and Efficiency of Graph Neural Networks by Reliable Knowledge Distillation | 4.50 | 4.50 | 0.00 | [3, 6, 3, 6]
|
| 887 | A Statistical Framework for Personalized Federated Learning and Estimation: Theory, Algorithms, and Privacy | 5.75 | 5.75 | 0.00 | [6, 6, 6, 5]
|
| 888 | Invariant Aggregator for Defending against Federated Backdoor Attacks | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 889 | Improving Adversarial Robustness of Deep Neural Networks via Self-adaptive Margin Defense | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 890 | Laser: Latent Set Representations for 3D Generative Modeling | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 891 | Towards Efficient Gradient-Based Meta-Learning in Heterogenous Environments | 5.50 | 5.50 | 0.00 | [3, 8, 6, 5]
|
| 892 | Knowledge Cascade: Reverse Knowledge Distillation | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 893 | Optimal Transport for Offline Imitation Learning | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 894 | FedorAS: Federated Architecture Search under system heterogeneity | 5.50 | 5.50 | 0.00 | [5, 6, 6, 5]
|
| 895 | Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization | 7.00 | 7.00 | 0.00 | [8, 8, 6, 6]
|
| 896 | Towards A Unified View of Sparse Feed-Forward Network in Transformer | 5.50 | 5.75 | 0.25 | [8, 6, 6, 3]
|
| 897 | Learning multi-scale local conditional probability models of images | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 898 | Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions | 7.50 | 7.50 | 0.00 | [8, 8, 8, 6]
|
| 899 | Online Continual Learning with Feedforward Adaptation | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 900 | Understanding ReLU Network Robustness Through Test Set Certification Performance | 2.75 | 2.75 | 0.00 | [3, 6, 1, 1]
|
| 901 | Mind the Privacy Budget: How Generative Models Spend their Privacy Budgets | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 902 | Resource Efficient Self-Supervised Learning for Speech Recognition | 4.75 | 4.75 | 0.00 | [3, 5, 5, 6]
|
| 903 | Subsampling in Large Graphs Using Ricci Curvature | 6.00 | 6.00 | 0.00 | [8, 6, 5, 5]
|
| 904 | Membership Leakage in Pre-trained Language Models | 3.00 | 3.00 | 0.00 | [5, 1, 3]
|
| 905 | DSI++: Updating Transformer Memory with New Documents | 5.00 | 5.00 | 0.00 | [3, 6, 5, 6]
|
| 906 | Universal Few-shot Learning of Dense Prediction Tasks with Visual Token Matching | 8.00 | 8.00 | 0.00 | [6, 8, 10]
|
| 907 | The Game of Hidden Rules: A New Challenge for Machine Learning | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 908 | Motif-based Graph Representation Learning with Application to Chemical Molecules | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 909 | Graph schemas as abstractions for transfer learning, inference, and planning | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 910 | Conservative Bayesian Model-Based Value Expansion for Offline Policy Optimization | 6.50 | 6.50 | 0.00 | [6, 6, 8, 6]
|
| 911 | Beam Tree Recursive Cells | 4.50 | 4.75 | 0.25 | [6, 3, 5, 5]
|
| 912 | The Ultimate Combo: Boosting Adversarial Example Transferability by Composing Data Augmentations | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 913 | In-Time Refining Optimization Trajectories Toward Improved Robust Generalization | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 914 | Scaling up and Stabilizing Differentiable Planning with Implicit Differentiation | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 915 | Improving Aspect Ratio Distribution Fairness in Detector Pretraining via Cooperating RPN’s | 3.75 | 3.75 | 0.00 | [1, 5, 6, 3]
|
| 916 | Learning parsimonious dynamics for generalization in reinforcement learning | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 917 | DECODING LAYER SALIENCY IN TRANSFORMERS | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 918 | UNDERSTANDING THE ROLE OF POSITIONAL ENCODINGS IN SENTENCE REPRESENTATIONS | 4.00 | 4.25 | 0.25 | [6, 3, 5, 3]
|
| 919 | Artificial Replay: A Meta-Algorithm for Harnessing Historical Data in Bandits | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 920 | Score-based Continuous-time Discrete Diffusion Models | 6.00 | 6.00 | 0.00 | [3, 10, 6, 5]
|
| 921 | Decision Transformer under Random Frame Dropping | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 922 | Semi-supervised consistency regularization for accurate cell type fraction and gene expression estimation | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 923 | Adversarial Imitation Learning with Preferences | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 924 | How to Do a Vocab Swap? A Study of Embedding Replacement for Pre-trained Transformers | 3.75 | 3.75 | 0.00 | [6, 3, 3, 3]
|
| 925 | Attribution Scores are Redundant: Explaining Feature Contribution By Trajectories | 4.00 | 4.00 | 0.00 | [3, 5, 6, 3, 3]
|
| 926 | SuperFed: Weight Shared Federated Learning | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 927 | Is Model Ensemble Necessary? Model-based RL via a Single Model with Lipschitz Regularized Value Function | 6.25 | 6.25 | 0.00 | [6, 8, 3, 8]
|
| 928 | Recurrent Back-Projection Generative Adversarial Network for Video Super Resolution | 1.50 | 1.50 | 0.00 | [1, 3, 1, 1]
|
| 929 | Neural Networks as Paths through the Space of Representations | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 930 | From Points to Functions: Infinite-dimensional Representations in Diffusion Models | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 931 | Disentangling with Biological Constraints: A Theory of Functional Cell Types | 6.75 | 7.50 | 0.75 | [8, 6, 6, 10]
|
| 932 | ESEAD: An Enhanced Simple Ensemble and Distillation Framework for Natural Language Processing | 2.00 | 2.00 | 0.00 | [1, 1, 3, 3]
|
| 933 | Efficient One-Shot Neural Architecture Search With Progressive Choice Freezing Evolutionary Search | 4.25 | 4.25 | 0.00 | [3, 3, 8, 3]
|
| 934 | Synthetic Data Generation of Many-to-Many Datasets via Random Graph Generation | 5.67 | 6.00 | 0.33 | [6, 6, 6]
|
| 935 | Learning rigid dynamics with face interaction graph networks | 7.00 | 7.00 | 0.00 | [6, 6, 10, 6]
|
| 936 | On the Importance of Contrastive Loss in Multimodal Learning | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 937 | MAD for Robust Reinforcement Learning in Machine Translation | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 938 | An Exploration of Conditioning Methods in Graph Neural Networks | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 939 | Speed Up Iterative Non-Autoregressive Transformers by Distilling Multiple Steps | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 940 | Global View For GCN: Why Go Deep When You Can Be Shallow? | 2.50 | 2.50 | 0.00 | [1, 5, 1, 3]
|
| 941 | Cross-Silo Training of Differentially Private Models with Secure Multiparty Computation | 4.50 | 4.50 | 0.00 | [3, 6, 6, 3]
|
| 942 | HyperTime: Implicit Neural Representations for Time Series Generation | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 943 | Generative Adversarial Federated Model | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 944 | Unsupervised Pretraining for Neural Value Approximation | 4.75 | 4.75 | 0.00 | [3, 8, 3, 5]
|
| 945 | Homotopy Learning of Parametric Solutions to Constrained Optimization Problems | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 946 | When Rigid Coherency Hurts: Distributional Coherency Regularization for Probabilistic Hierarchical Time Series Forecasting | 5.00 | 5.00 | 0.00 | [5, 1, 6, 8]
|
| 947 | EENet: Learning to Early Exit for Adaptive Inference | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 948 | MALIBO: Meta-Learning for Likelihood-free Bayesian Optimization | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 949 | Finding and only finding local Nash equilibria by both pretending to be a follower | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 950 | Learning Low Dimensional State Spaces with Overparameterized Recurrent Neural Networks | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 951 | Images as Weight Matrices: Sequential Image Generation Through Synaptic Learning Rules | 5.50 | 5.75 | 0.25 | [5, 6, 6, 6]
|
| 952 | SurCo: Learning Linear Surrogates for Combinatorial Nonlinear Optimization Problems | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 953 | DT+GNN: A Fully Explainable Graph Neural Network using Decision Trees | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 954 | Why (and When) does Local SGD Generalize Better than SGD? | 7.00 | 7.00 | 0.00 | [8, 8, 5]
|
| 955 | Function-space regularized Rényi divergences | 5.67 | 5.67 | 0.00 | [6, 3, 8]
|
| 956 | Constant-Factor Approximation Algorithms for Socially Fair $k$-Clustering | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 957 | Re-calibrated Wasserstein GAN for large-scale imputation with informative missing | 3.67 | 3.50 | -0.17 | [3, 3, 5, 3]
|
| 958 | Implicit Bias of Large Depth Networks: a Notion of Rank for Nonlinear Functions | 7.20 | 7.33 | 0.13 | [8, 5, 8, 5, 8, 10]
|
| 959 | Depth Separation with Multilayer Mean-Field Networks | 7.20 | 7.20 | 0.00 | [8, 8, 6, 8, 6]
|
| 960 | Robust Policy Optimization in Deep Reinforcement Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 961 | Analogical Networks for Memory-Modulated 3D Parsing | 6.00 | 6.75 | 0.75 | [6, 8, 8, 5]
|
| 962 | Fake It Until You Make It : Towards Accurate Near-Distribution Novelty Detection | 5.25 | 5.25 | 0.00 | [6, 6, 3, 6]
|
| 963 | Injecting knowledge into language generation: a case study in auto-charting after-visit care instructions from medical dialogue | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 964 | DySR: Adaptive Super-Resolution via Algorithm and System Co-design | 6.00 | 6.00 | 0.00 | [8, 5, 6, 5]
|
| 965 | Domain Invariant Q-Learning for model-free robust continuous control under visual distractions | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 966 | Continual Learning with Soft-Masking of Parameter-Level Gradient Flow | 4.67 | 5.00 | 0.33 | [6, 3, 6]
|
| 967 | Asynchronous Message Passing: A new Framework for Learning in Graphs | 4.75 | 4.75 | 0.00 | [5, 6, 3, 5]
|
| 968 | Integrating Symmetry into Differentiable Planning with Steerable Convolutions | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 969 | MolJET: Multimodal Joint Embedding Transformer for Conditional de novo Molecular Design and Multi-Property Optimization | 5.00 | 4.67 | -0.33 | [3, 8, 8, 3, 3, 3]
|
| 970 | The Challenges of Exploration for Offline Reinforcement Learning | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 971 | SGD with large step sizes learns sparse features | 5.50 | 5.50 | 0.00 | [6, 8, 5, 3]
|
| 972 | Synergies Between Disentanglement and Sparsity: a Multi-Task Learning Perspective | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 973 | Discerning Hydroclimatic Behavior with a Deep Convolutional Residual Regressive Neural Network | 2.33 | 2.33 | 0.00 | [1, 3, 3]
|
| 974 | Causal Reasoning in the Presence of Latent Confounders via Neural ADMG Learning | 6.00 | 6.00 | 0.00 | [5, 8, 5, 6]
|
| 975 | ESC: A Benchmark For Multi-Domain End-to-End Speech Recognition | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 976 | Mitigating Gradient Bias in Multi-objective Learning: A Provably Convergent Approach | 5.33 | 8.00 | 2.67 | [8, 8, 8]
|
| 977 | Pareto Rank-Preserving Supernetwork for HW-NAS | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 978 | ProSampler: Improving Contrastive Learning by Better Mini-batch Sampling | 5.50 | 5.50 | 0.00 | [3, 5, 6, 8]
|
| 979 | $O(T^{-1})$ Convergence of Optimistic-Follow-the-Regularized-Leader in Two-Player Zero-Sum Markov Games | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 980 | Bispectral Neural Networks | 6.33 | 6.33 | 0.00 | [8, 6, 5]
|
| 981 | Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 982 | Beyond Lipschitz: Sharp Generalization and Excess Risk Bounds for Full-Batch GD | 6.00 | 6.00 | 0.00 | [5, 5, 6, 8]
|
| 983 | Zero-Shot Retrieval with Search Agents and Hybrid Environments | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 984 | Hyper-Decision Transformer for Efficient Online Policy Adaptation | 6.25 | 6.25 | 0.00 | [8, 8, 3, 6]
|
| 985 | Deep Learning of Intrinsically Motivated Options in the Arcade Learning Environment | 2.00 | 2.00 | 0.00 | [3, 3, 1, 1]
|
| 986 | Solving Continuous Control via Q-learning | 6.25 | 6.25 | 0.00 | [6, 6, 5, 8]
|
| 987 | Make-A-Video: Text-to-Video Generation without Text-Video Data | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 988 | EiX-GNN : Concept-level eigencentrality explainer for graph neural networks | 3.00 | 3.00 | 0.00 | [3, 3, 5, 1]
|
| 989 | Unsupervised Adaptation for Fairness under Covariate Shift | 4.67 | 4.67 | 0.00 | [3, 3, 8]
|
| 990 | Pushing the limits of self-supervised learning: Can we outperform supervised learning without labels? | 6.00 | 6.00 | 0.00 | [5, 8, 6, 5]
|
| 991 | Towards Dynamic Sparsification by Iterative Prune-Grow LookAheads | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 992 | Learning Useful Representations for Shifting Tasks and Distributions | 3.67 | 4.00 | 0.33 | [5, 3, 5, 3]
|
| 993 | Personalized Reward Learning with Interaction-Grounded Learning (IGL) | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 994 | From Adaptive Query Release to Machine Unlearning | 4.75 | 5.00 | 0.25 | [5, 6, 3, 6]
|
| 995 | ReAct: Synergizing Reasoning and Acting in Language Models | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 996 | Towards convergence to Nash equilibria in two-team zero-sum games | 4.67 | 5.00 | 0.33 | [6, 3, 6]
|
| 997 | Ensemble Homomorphic Encrypted Data Classification | 1.50 | 1.50 | 0.00 | [1, 1, 1, 3]
|
| 998 | Generative Pretraining for Black-Box Optimization | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 999 | Meta-Learning Black-Box Optimization via Black-Box Optimization | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 1000 | The Use of Open-Source Boards for Data Collection and Machine Learning in Remote Deployments | 1.50 | 1.00 | -0.50 | [1, 1, 1, 1]
|
| 1001 | Rhino: Deep Causal Temporal Relationship Learning with History-dependent Noise | 6.25 | 7.00 | 0.75 | [6, 6, 8, 8]
|
| 1002 | DensePure: Understanding Diffusion Models towards Adversarial Robustness | 6.00 | 6.00 | 0.00 | [5, 5, 6, 8]
|
| 1003 | Towards Understanding How Machines Can Learn Causal Overhypotheses | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 1004 | Grounding Graph Network Simulators using Physical Sensor Observations | 5.67 | 5.67 | 0.00 | [6, 8, 3]
|
| 1005 | Skill Decision Transformer | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 1006 | Architectural Backdoors in Neural Networks | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1007 | In-distribution and Out-of-distribution Generalization for Graph Neural Networks | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 1008 | Where to Diffuse, How to Diffuse and How to get back: Learning in Multivariate Diffusions | 6.33 | 6.33 | 0.00 | [8, 8, 3]
|
| 1009 | Contrastive Corpus Attribution for Explaining Representations | 7.33 | 7.33 | 0.00 | [6, 8, 8]
|
| 1010 | The ethical ambiguity of AI data enrichment: Measuring gaps in research ethics norms and practices | 5.25 | 5.25 | 0.00 | [10, 3, 5, 3]
|
| 1011 | Spatio-temporal point processes with deep non-stationary kernels | 5.75 | 5.75 | 0.00 | [6, 6, 6, 5]
|
| 1012 | Federated Learning from Small Datasets | 5.00 | 5.00 | 0.00 | [3, 6, 5, 6, 5]
|
| 1013 | Zero-shot Human-Object Interaction Recognition by Bridging Generative and Contrastive Image-Language Models | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 1014 | Explainable Machine Learning Predictions for the Long-term Performance of Brain-Computer Interfaces | 5.00 | 5.00 | 0.00 | [3, 6, 3, 8]
|
| 1015 | The Minimal Feature Removal Problem in Neural Networks | 3.00 | 3.00 | 0.00 | [1, 5, 3]
|
| 1016 | Effectively using public data in privacy preserving Machine learning | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 1017 | Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation | 7.25 | 7.25 | 0.00 | [8, 8, 8, 5]
|
| 1018 | Illusory Adversarial Attacks on Sequential Decision-Makers and Countermeasures | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 1019 | Prompt Tuning with Prompt-aligned Gradient for Vision-Language Models | 5.40 | 5.40 | 0.00 | [6, 6, 3, 6, 6]
|
| 1020 | Relative Behavioral Attributes: Filling the Gap between Symbolic Goal Specification and Reward Learning from Human Preferences | 6.33 | 6.67 | 0.33 | [8, 6, 6]
|
| 1021 | DINO as a von Mises-Fisher mixture model | 6.75 | 7.25 | 0.50 | [8, 8, 5, 8]
|
| 1022 | Continuous Depth Recurrent Neural Differential Equations | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1023 | Optimal Membership Inference Bounds for Adaptive Composition of Sampled Gaussian Mechanisms | 4.75 | 4.75 | 0.00 | [3, 3, 5, 8]
|
| 1024 | Advantage Constrained Proximal Policy Optimization in Multi-Agent Reinforcement Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1025 | Scalable Batch-Mode Deep Bayesian Active Learning via Equivalence Class Annealing | 6.75 | 6.75 | 0.00 | [5, 6, 8, 8]
|
| 1026 | Neural multi-event forecasting on spatio-temporal point processes using probabilistically enriched transformers | 5.25 | 5.25 | 0.00 | [8, 3, 5, 5]
|
| 1027 | Associative Memory Augmented Asynchronous Spatiotemporal Representation Learning for Event-based Perception | 6.50 | 6.50 | 0.00 | [6, 6, 8, 6]
|
| 1028 | Detecting Small Query Graphs in A Large Graph via Neural Subgraph Search | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 1029 | Can we achieve robustness from data alone? | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1030 | Catastrophic overfitting is a bug but it is caused by features | 4.50 | 4.50 | 0.00 | [3, 6, 3, 6]
|
| 1031 | Semi Parametric Inducing Point Networks | 6.50 | 6.50 | 0.00 | [6, 6, 6, 8]
|
| 1032 | Perceptual Grouping in Vision-Language Models | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1033 | CADet: Fully Self-Supervised Anomaly Detection With Contrastive Learning | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 1034 | SPRINT: Scalable Semantic Policy Pre-training via Language Instruction Relabeling | 4.75 | 5.00 | 0.25 | [3, 6, 6, 5]
|
| 1035 | SMART: Self-supervised Multi-task pretrAining with contRol Transformers | 7.50 | 7.50 | 0.00 | [6, 8, 8, 8]
|
| 1036 | Evaluation of Active Feature Acquisition Methods under Missing Data | 5.80 | 5.80 | 0.00 | [3, 6, 6, 8, 6]
|
| 1037 | DAG Learning via Sparse Relaxations | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 1038 | Explicitly Minimizing the Blur Error of Variational Autoencoders | 6.33 | 6.33 | 0.00 | [6, 5, 8]
|
| 1039 | GraphEditor: An Efficient Graph Representation Learning and Unlearning Approach | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 1040 | 3D Equivariant Diffusion for Target-Aware Molecule Generation and Affinity Prediction | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 1041 | PGASL: Predictive and Generative Adversarial Semi-supervised Learning for imbalanced data | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 1042 | Towards a More Rigorous Science of Blindspot Discovery in Image Models | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 1043 | How gradient estimator variance and bias impact learning in neural networks | 6.00 | 6.00 | 0.00 | [6, 8, 5, 5]
|
| 1044 | Automatically Auditing Large Language Models via Discrete Optimization | 6.00 | 6.00 | 0.00 | [8, 6, 5, 5]
|
| 1045 | Do We Really Need Complicated Model Architectures For Temporal Networks? | 7.00 | 7.00 | 0.00 | [5, 8, 8]
|
| 1046 | Synthetic Pre-Training Tasks for Neural Machine Translation | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 1047 | On the System-Level Effectiveness of Physical Object-Hiding Adversarial Attack in Autonomous Driving | 5.50 | 5.50 | 0.00 | [5, 6, 6, 5]
|
| 1048 | BIG-Graph: Brain Imaging Genetics by Graph Neural Network | 2.50 | 2.50 | 0.00 | [3, 3, 3, 1]
|
| 1049 | Optimizing the Performance of Text Classification Models by Improving the Isotropy of the Embeddings using a Joint Loss Function | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 1050 | Data Feedback Loops: Model-driven Amplification of Dataset Biases | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 1051 | A $2$-parameter Persistence Layer for Learning | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 1052 | Is Conditional Generative Modeling all you need for Decision Making? | 5.50 | 5.50 | 0.00 | [3, 5, 8, 6]
|
| 1053 | META-STORM: Generalized Fully-Adaptive Variance Reduced SGD for Unbounded Functions | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 1054 | TEMPERA: Test-Time Prompt Editing via Reinforcement Learning | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 1055 | Combining pretrained speech and text encoders for spoken language processing | 2.50 | 2.50 | 0.00 | [1, 3, 3, 3]
|
| 1056 | A Large Scale Sample Complexity Analysis of Neural Policies in the Low-Data Regime | 4.75 | 4.75 | 0.00 | [5, 3, 3, 8]
|
| 1057 | Evaluating Representations with Readout Model Switching | 5.40 | 5.60 | 0.20 | [3, 6, 6, 5, 8]
|
| 1058 | Provable Defense Against Geometric Transformations | 6.75 | 6.75 | 0.00 | [8, 8, 5, 6]
|
| 1059 | Augmentation with Projection: Towards an Effective and Efficient Data Augmentation Paradigm for Distillation | 6.50 | 6.50 | 0.00 | [6, 6, 8, 6]
|
| 1060 | Pseudoinverse-Guided Diffusion Models for Inverse Problems | 6.25 | 6.25 | 0.00 | [8, 6, 6, 5]
|
| 1061 | Autoregressive Diffusion Model for Graph Generation | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 1062 | Contrastive introspection (ConSpec) to rapidly identify invariant steps for success | 5.00 | 5.00 | 0.00 | [6, 5, 6, 3]
|
| 1063 | Self-supervised video pretraining yields strong image representations | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 1064 | Planning with Language Models through Iterative Energy Minimization | 5.25 | 5.25 | 0.00 | [6, 3, 6, 6]
|
| 1065 | The Union of Manifolds Hypothesis | 4.67 | 4.67 | 0.00 | [3, 8, 3]
|
| 1066 | Last Layer Re-Training is Sufficient for Robustness to Spurious Correlations | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 1067 | UniS-MMC: Learning Unimodality-supervised Multimodal Contrastive Representations | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 1068 | Progressive Data Dropout: An Adaptive Training Strategy for Large-Scale Supervised Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1069 | Error Sensitivity Modulation based Experience Replay: Mitigating Abrupt Representation Drift in Continual Learning | 6.33 | 6.33 | 0.00 | [5, 8, 6]
|
| 1070 | Panoptically guided Image Inpainting with Image-level and Object-level Semantic Discriminators | 5.00 | 5.00 | 0.00 | [6, 3, 6, 5]
|
| 1071 | Auditing Fairness Online through Interactive Refinement | 4.00 | 3.80 | -0.20 | [3, 3, 5, 5, 3]
|
| 1072 | REM: Routing Entropy Minimization for Capsule Networks | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 1073 | Don’t forget the nullspace! Nullspace occupancy as a mechanism for out of distribution failure | 5.75 | 5.75 | 0.00 | [5, 8, 5, 5]
|
| 1074 | Variational Classification | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 1075 | ContraNorm: A Contrastive Learning Perspective on Oversmoothing and Beyond | 5.00 | 5.00 | 0.00 | [3, 6, 6, 5]
|
| 1076 | Accelerated Single-Call Methods for Constrained Min-Max Optimization | 5.33 | 5.33 | 0.00 | [5, 8, 3]
|
| 1077 | Towards Interpretable Deep Reinforcement Learning with Human-Friendly Prototypes | 5.75 | 6.50 | 0.75 | [6, 6, 8, 6]
|
| 1078 | Distributed Extra-gradient with Optimal Complexity and Communication Guarantees | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 1079 | "I pick you choose": Joint human-algorithm decision making in multi-armed bandits | 2.00 | 2.00 | 0.00 | [3, 1, 1, 3]
|
| 1080 | UnDiMix: Hard Negative Sampling Strategies for Contrastive Representation Learning | 3.75 | 3.75 | 0.00 | [5, 6, 3, 1]
|
| 1081 | What Matters In The Structured Pruning of Generative Language Models? | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 1082 | MaxMin-Novelty: Maximizing Novelty via Minimizing the State-Action Values in Deep Reinforcement Learning | 3.50 | 4.00 | 0.50 | [5, 5, 3, 3]
|
| 1083 | Complete Likelihood Objective for Latent Variable Models | 3.25 | 3.25 | 0.00 | [8, 1, 3, 1]
|
| 1084 | The Surprising Effectiveness of Equivariant Models in Domains with Latent Symmetry | 7.50 | 7.50 | 0.00 | [6, 8, 8, 8]
|
| 1085 | Performance Bounds for Model and Policy Transfer in Hidden-parameter MDPs | 5.67 | 6.33 | 0.67 | [6, 8, 5]
|
| 1086 | Parallel $Q$-Learning: Scaling Off-policy Reinforcement Learning | 5.50 | 5.50 | 0.00 | [6, 3, 8, 5]
|
| 1087 | Emergence of shared sensory-motor graphical language from visual input | 4.60 | 4.60 | 0.00 | [6, 5, 3, 6, 3]
|
| 1088 | Compositional Task Generalization with Discovered Successor Feature Modules | 5.75 | 5.75 | 0.00 | [3, 8, 6, 6]
|
| 1089 | DexDeform: Dexterous Deformable Object Manipulation with Human Demonstrations and Differentiable Physics | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 1090 | NAG-GS: semi-implicit, accelerated and robust stochastic optimizer. | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 1091 | Loop Unrolled Shallow Equilibrium Regularizer (LUSER) - A Memory-Efficient Inverse Problem Solver | 4.25 | 4.25 | 0.00 | [5, 3, 3, 6]
|
| 1092 | Robust Universal Adversarial Perturbations | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 1093 | Understanding the Complexity Gains of Contextual Multi-task RL with Curricula | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 1094 | The Lie Derivative for Measuring Learned Equivariance | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 1095 | Effective passive membership inference attacks in federated learning against overparameterized models | 5.67 | 5.67 | 0.00 | [8, 3, 6]
|
| 1096 | Optimizing Bi-Encoder for Named Entity Recognition via Contrastive Learning | 5.50 | 5.50 | 0.00 | [3, 8, 6, 5]
|
| 1097 | Handling Covariate Shifts in Federated Learning with Generalization Guarantees | 3.50 | 4.25 | 0.75 | [3, 5, 3, 6]
|
| 1098 | Agree to Disagree: Diversity through Disagreement for Better Transferability | 8.00 | 8.00 | 0.00 | [8, 8, 8, 8]
|
| 1099 | Expected Probabilistic Hierarchies | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 1100 | Taking a Step Back with KCal: Multi-Class Kernel-Based Calibration for Deep Neural Networks | 6.75 | 7.00 | 0.25 | [8, 8, 6, 6]
|
| 1101 | A distinct unsupervised reference model from the environment helps continual learning | 4.80 | 4.80 | 0.00 | [3, 5, 6, 5, 5]
|
| 1102 | The Crossword Puzzle: Simplifying Deep Neural Network Pruning with Fabulous Coordinates | 3.20 | 3.20 | 0.00 | [3, 1, 1, 5, 6]
|
| 1103 | Learning the Visualness of Text Using Large Vision-Language Models | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 1104 | SemPPL: Predicting Pseudo-Labels for Better Contrastive Representations | 5.60 | 5.60 | 0.00 | [6, 5, 5, 6, 6]
|
| 1105 | Differentially Private Adaptive Optimization with Delayed Preconditioners | 5.50 | 5.50 | 0.00 | [5, 6, 8, 3]
|
| 1106 | Towards a Mathematics Formalisation Assistant using Large Language Models | 3.00 | 3.00 | 0.00 | [3, 5, 1, 3]
|
| 1107 | Learning Robust Representations via Nuisance-extended Information Bottleneck | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 1108 | FedLite: Improving Communication Efficiency in Federated Split Learning | 4.25 | 4.25 | 0.00 | [3, 5, 6, 3]
|
| 1109 | Adversarial Policies Beat Professional-Level Go AIs | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 1110 | Phenaki: Variable Length Video Generation from Open Domain Textual Descriptions | 5.75 | 5.75 | 0.00 | [6, 8, 6, 3]
|
| 1111 | Long Range Language Modeling via Gated State Spaces | 5.50 | 5.75 | 0.25 | [6, 6, 5, 6]
|
| 1112 | On the (Non-)Robustness of Two-Layer Neural Networks in Different Learning Regimes | 5.75 | 5.75 | 0.00 | [6, 8, 3, 6]
|
| 1113 | Task-customized Masked Autoencoder via Mixture of Cluster-conditional Experts | 5.50 | 5.75 | 0.25 | [6, 6, 5, 6]
|
| 1114 | A Deep Dive into Dataset Imbalance and Bias in Face Identification | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1115 | Causally Constrained Data Synthesis For Private Data Release | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1116 | Modeling the Data-Generating Process is Necessary for Out-of-Distribution Generalization | 7.00 | 7.00 | 0.00 | [6, 6, 8, 8]
|
| 1117 | Bayes-MIL: A New Probabilistic Perspective on Attention-based Multiple Instance Learning for Whole Slide Images | 6.33 | 6.33 | 0.00 | [6, 5, 8]
|
| 1118 | Exploring Connections Between Memorization And Membership Inference | 3.75 | 3.75 | 0.00 | [3, 3, 3, 6]
|
| 1119 | Action Matching: A Variational Method for Learning Stochastic Dynamics from Samples | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 1120 | Pre-train Graph Neural Networks for Brain Network Analysis | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 1121 | Investigating Multi-task Pretraining and Generalization in Reinforcement Learning | 5.50 | 5.50 | 0.00 | [3, 8, 6, 5]
|
| 1122 | FIT: A Metric for Model Sensitivity | 6.00 | 6.00 | 0.00 | [6, 5, 3, 8, 8]
|
| 1123 | Transfer Learning with Deep Tabular Models | 6.50 | 6.50 | 0.00 | [5, 8, 8, 5]
|
| 1124 | An Empirical Study on the Efficacy of Deep Active Learning Techniques | 4.75 | 4.75 | 0.00 | [5, 3, 5, 6]
|
| 1125 | CrAM: A Compression-Aware Minimizer | 5.75 | 5.75 | 0.00 | [6, 3, 6, 8]
|
| 1126 | Using Language to Extend to Unseen Domains | 6.33 | 6.33 | 0.00 | [6, 5, 8]
|
| 1127 | Can We Find Nash Equilibria at a Linear Rate in Markov Games? | 8.00 | 8.00 | 0.00 | [8, 8, 8, 8]
|
| 1128 | Speeding up Policy Optimization with Vanishing Hypothesis and Variable Mini-Batch Size | 1.50 | 1.50 | 0.00 | [3, 1, 1, 1]
|
| 1129 | Understanding Train-Validation Split in Meta-Learning with Neural Networks | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 1130 | Revisiting Robustness in Graph Machine Learning | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 1131 | Variational Information Pursuit for Interpretable Predictions | 7.33 | 7.33 | 0.00 | [6, 8, 8]
|
| 1132 | Grammar-Induced Geometry for Data-Efficient Molecular Property Prediction | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 1133 | EF21-P and Friends: Improved Theoretical Communication Complexity for Distributed Optimization with Bidirectional Compression | 4.75 | 3.00 | -1.75 | [5, 5, 1, 1]
|
| 1134 | Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints | 6.75 | 6.75 | 0.00 | [6, 8, 8, 5]
|
| 1135 | A simple Training-Free Method for Rejection Option | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 1136 | Self-Programming Artificial Intelligence Using Code-Generating Language Models | 2.60 | 2.60 | 0.00 | [1, 3, 3, 3, 3]
|
| 1137 | Lossless Adaptation of Pretrained Vision Models For Robotic Manipulation | 6.00 | 6.25 | 0.25 | [5, 8, 6, 6]
|
| 1138 | Branch-Train-Merge: Embarrassingly Parallel Training of Expert Language Models | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 1139 | Logical Message Passing Networks with One-hop Inference on Atomic Formulas | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 1140 | Noise-Robust De-Duplication at Scale | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 1141 | P2PRISM - Peer to peer learning with individual prism for secure aggregation | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 1142 | Multi-scale Attention for Diabetic Retinopathy Detection in Retinal Fundus Images | 2.33 | 2.33 | 0.00 | [1, 3, 3]
|
| 1143 | Blessing from Experts: Super Reinforcement Learning in Confounded Environments | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 1144 | Unscented Autoencoder | 4.00 | 4.00 | 0.00 | [6, 6, 3, 1]
|
| 1145 | Reinforcement Learning for Bandits with Continuous Actions and Large Context Spaces | 4.25 | 3.75 | -0.50 | [6, 3, 3, 3]
|
| 1146 | Explanation Uncertainty with Decision Boundary Awareness | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1147 | Hierarchical Neural Program Synthesis | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 1148 | SARNET: SARCASM VS TRUE-HATE DETECTION NETWORK | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 1149 | Learning Portable Skills by Identifying Generalizing Features with an Attention-Based Ensemble | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1150 | Few-shot Backdoor Attacks via Neural Tangent Kernels | 4.67 | 5.00 | 0.33 | [3, 6, 6]
|
| 1151 | Quantitative Universal Approximation Bounds for Deep Belief Networks | 6.20 | 6.20 | 0.00 | [6, 8, 3, 6, 8]
|
| 1152 | Hyperparameter Optimization through Neural Network Partitioning | 5.50 | 6.00 | 0.50 | [5, 6, 5, 8]
|
| 1153 | DiscoBAX - Discovery of optimal intervention sets in genomic experiment design | 4.25 | 4.25 | 0.00 | [3, 3, 5, 6]
|
| 1154 | How to Enable Uncertainty Estimation in Proximal Policy Optimization | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 1155 | Joint-Predictive Representations for Multi-Agent Reinforcement Learning | 5.25 | 5.25 | 0.00 | [3, 6, 6, 6]
|
| 1156 | Symmetries, Flat Minima and the Conserved Quantities of Gradient Flow | 6.00 | 6.00 | 0.00 | [5, 6, 8, 5]
|
| 1157 | DP-SGD-LF: Improving Utility under Differentially Private Learning via Layer Freezing | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 1158 | Explainability as statistical inference | 6.33 | 6.33 | 0.00 | [6, 8, 5]
|
| 1159 | Concept-based Explanations for Out-of-Distribution Detectors | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 1160 | FaDIn: Fast Discretized Inference for Hawkes Processes with General Parametric Kernels | 4.20 | 4.20 | 0.00 | [3, 5, 5, 5, 3]
|
| 1161 | Summarization Programs: Interpretable Abstractive Summarization with Neural Modular Trees | 5.75 | 5.75 | 0.00 | [6, 8, 3, 6]
|
| 1162 | Planning with Large Language Models for Code Generation | 4.25 | 4.25 | 0.00 | [3, 8, 3, 3]
|
| 1163 | Unleash Model Capacity for Universal Dense Retrieval by Task Specialty Optimization | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 1164 | Training Equilibria in Reinforcement Learning | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 1165 | Hebbian Deep Learning Without Feedback | 5.75 | 6.50 | 0.75 | [6, 8, 6, 6]
|
| 1166 | A Simulation-based Framework for Robust Federated Learning to Training-time Attacks | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 1167 | Key Design Choices for Double-transfer in Source-free Unsupervised Domain Adaptation | 4.75 | 4.75 | 0.00 | [5, 3, 5, 6]
|
| 1168 | PALM: Preference-based Adversarial Manipulation against Deep Reinforcement Learning | 5.00 | 5.60 | 0.60 | [6, 6, 5, 5, 6]
|
| 1169 | Architectural optimization over subgroups of equivariant neural networks | 5.50 | 5.75 | 0.25 | [6, 6, 6, 5]
|
| 1170 | Unsupervised Non-Parametric Signal Separation Using Bayesian Neural Networks | 2.00 | 2.00 | 0.00 | [3, 1, 1, 3]
|
| 1171 | SPIDER: Searching Personalized Neural Architecture for Federated Learning | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 1172 | On Gradient Descent Convergence beyond the Edge of Stability | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 1173 | Synaptic Dynamics Realize First-order Adaptive Learning and Weight Symmetry | 6.00 | 6.00 | 0.00 | [6, 5, 8, 5]
|
| 1174 | FedAvg Converges to Zero Training Loss Linearly: The Power of Overparameterized Multi-Layer Neural Networks | 3.75 | 3.75 | 0.00 | [6, 3, 3, 3]
|
| 1175 | Robustifying Language Models via Adversarial Training with Masked Gradient | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 1176 | Robust Graph Representation Learning via Predictive Coding | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 1177 | Accelerating Hamiltonian Monte Carlo via Chebyshev Integration Time | 5.50 | 5.50 | 0.00 | [3, 5, 6, 8]
|
| 1178 | PromptCAL: Contrastive Affinity Learning via Auxiliary Prompts for Generalized Category Discovery | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 1179 | Multi-Hypothesis 3D human pose estimation metrics favor miscalibrated distributions | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 1180 | Learning to Abstain from Uninformative Data | 5.75 | 5.75 | 0.00 | [5, 5, 5, 8]
|
| 1181 | Order Matters: Agent-by-agent Policy Optimization | 6.00 | 5.60 | -0.40 | [8, 6, 5, 6, 3]
|
| 1182 | AQuaMaM: An Autoregressive, Quaternion Manifold Model for Rapidly Estimating Complex SO(3) Distributions | 4.00 | 4.67 | 0.67 | [6, 3, 5]
|
| 1183 | Conformal Prediction is Robust to Label Noise | 4.25 | 4.25 | 0.00 | [3, 5, 6, 3]
|
| 1184 | $\Phi$-DVAE: Learning Physically Interpretable Representations with Nonlinear Filtering | 4.75 | 4.75 | 0.00 | [5, 3, 5, 6]
|
| 1185 | Revisiting Structured Dropout | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 1186 | Reducing the Capacity Gap via Spherical Knowledge Distillation | 3.67 | 3.67 | 0.00 | [1, 5, 5]
|
| 1187 | Flatter, Faster: Scaling Momentum for Optimal Speedup of SGD | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 1188 | Learning implicit hidden Markov models using neural likelihood-free inference | 5.25 | 5.50 | 0.25 | [5, 8, 6, 3]
|
| 1189 | Brain Signal Generation and Data Augmentation with a Single-Step Diffusion Probabilistic Model | 3.50 | 3.50 | 0.00 | [5, 3, 5, 1]
|
| 1190 | Know Your Boundaries: The Advantage of Explicit Behavior Cloning in Offline RL | 5.75 | 5.75 | 0.00 | [6, 8, 6, 3]
|
| 1191 | On the Convergence of AdaGrad on $\mathbb{R}^d$: Beyond Convexity, Non-Asymptotic Rate and Acceleration | 6.00 | 6.67 | 0.67 | [8, 6, 6]
|
| 1192 | Bounded Attacks and Robustness in Image Transform Domains | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 1193 | SP2 : A Second Order Stochastic Polyak Method | 5.33 | 5.67 | 0.33 | [5, 6, 6]
|
| 1194 | Multi-Objective GFlowNets | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 1195 | Making Better Decision by Directly Planning in Continuous Control | 5.25 | 6.75 | 1.50 | [8, 3, 8, 8]
|
| 1196 | Large language models are not zero-shot communicators | 6.00 | 6.50 | 0.50 | [8, 5, 8, 5]
|
| 1197 | Data dependent frequency sensitivity of convolutional neural networks | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1198 | Is end-to-end learning enough for fitness activity recognition? | 3.00 | 3.00 | 0.00 | [3, 1, 3, 3, 3, 5, 3, 3, 3]
|
| 1199 | Efficient Exploration using Model-Based Quality-Diversity with Gradients | 3.50 | 3.75 | 0.25 | [3, 6, 3, 3]
|
| 1200 | ResFed: Communication Efficient Federated Learning by Transmitting Deep Compressed Residuals | 3.75 | 3.75 | 0.00 | [6, 3, 3, 3]
|
| 1201 | HiT-MDP: Learning the SMDP option framework on MDPs with Hidden Temporal Variables | 5.50 | 5.50 | 0.00 | [5, 3, 8, 6]
|
| 1202 | Improved Group Robustness via Classifier Retraining on Independent Splits | 5.33 | 5.67 | 0.33 | [5, 6, 6]
|
| 1203 | (Certified!!) Adversarial Robustness for Free! | 7.00 | 7.00 | 0.00 | [6, 8, 6, 8]
|
| 1204 | URVoice: An Akl-Toussaint/ Graham- Sklansky Approach towards Convex Hull Computation for Sign Language Interpretation | 1.50 | 1.50 | 0.00 | [1, 1, 3, 1]
|
| 1205 | Gaussian-Bernoulli RBMs Without Tears | 5.67 | 5.67 | 0.00 | [3, 8, 6]
|
| 1206 | Image Emotion Recognition using Cognitive Contextual Summarization Framework | 2.50 | 2.50 | 0.00 | [1, 3, 3, 3]
|
| 1207 | PES: Probabilistic Exponential Smoothing for Time Series Forecasting | 2.33 | 2.33 | 0.00 | [3, 3, 1]
|
| 1208 | Efficient Conditionally Invariant Representation Learning | 7.00 | 7.33 | 0.33 | [8, 6, 8]
|
| 1209 | Distinguishing Feature Model for Ranking From Pairwise Comparisons | 3.00 | 3.50 | 0.50 | [5, 1, 5, 3]
|
| 1210 | Heterogeneous Neuronal and Synaptic Dynamics for Spike-Efficient Unsupervised Learning: Theory and Design Principles | 5.25 | 5.25 | 0.00 | [5, 3, 8, 5]
|
| 1211 | MMVAE+: Enhancing the Generative Quality of Multimodal VAEs without Compromises | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 1212 | Forget to Learn (F2L): Rethinking Replay Loss in Unsupervised Continuous Domain Adaptation | 3.00 | 3.00 | 0.00 | [1, 5, 3]
|
| 1213 | A probabilistic framework for task-aligned intra- and inter-area neural manifold estimation | 7.25 | 7.25 | 0.00 | [8, 8, 5, 8]
|
| 1214 | Applying Second Order Optimization to Deep Transformers with Parameter-Efficient Tuning | 3.50 | 4.00 | 0.50 | [5, 5, 3, 3]
|
| 1215 | Density Sketches for Sampling and Estimation | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 1216 | Mask-tuning: Towards Improving Pre-trained Language Models" Generalization | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 1217 | Meta-Learning via Classifier(-free) Guidance | 3.25 | 3.25 | 0.00 | [3, 6, 3, 1]
|
| 1218 | Tiered Pruning for Efficient Differentialble Inference-Aware Neural Architecture Search | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 1219 | MyoDex: Generalizable Representations for Dexterous Physiological Manipulation | 4.25 | 4.25 | 0.00 | [3, 3, 5, 6]
|
| 1220 | Do We Really Need Labels for Backdoor Defense? | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 1221 | Metadata Archaeology: Unearthing Data Subsets by Leveraging Training Dynamics | 6.75 | 7.25 | 0.50 | [8, 5, 8, 8]
|
| 1222 | Single SMPC Invocation DPHelmet: Differentially Private Distributed Learning on a Large Scale | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1223 | A Scalable Training Strategy for Blind Multi-Distribution Noise Removal | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 1224 | $\ell$Gym: Natural Language Visual Reasoning with Reinforcement Learning | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 1225 | Re-Benchmarking Out-of-Distribution Detection in Deep Neural Networks | 2.00 | 2.00 | 0.00 | [3, 1, 1, 3]
|
| 1226 | Towards Antisymmetric Neural Ansatz Separation | 4.67 | 5.00 | 0.33 | [6, 6, 3]
|
| 1227 | Multi-instance Interactive Segmentation with Self-Supervised Transformer | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 1228 | Triplet learning of task representations in latent space for continual learning | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 1229 | Spurious Features in Continual Learning | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 1230 | Time Series Subsequence Anomaly Detection via Graph Neural Networks | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 1231 | Aligning Model and Macaque Inferior Temporal Cortex Representations Improves Model-to-Human Behavioral Alignment and Adversarial Robustness | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 1232 | Improving Generalization of Motor-Imagery Brainwave Decoding via Dynamic Convolutions | 3.67 | 3.67 | 0.00 | [1, 5, 5]
|
| 1233 | On the Expressive Power of Geometric Graph Neural Networks | 4.25 | 4.25 | 0.00 | [3, 3, 8, 3]
|
| 1234 | Fusion over the Grassmann Manifold for Incomplete-Data Clustering | 5.50 | 5.50 | 0.00 | [1, 8, 8, 5]
|
| 1235 | Off Policy Average Reward Actor Critic with Deterministic Policy Search | 3.40 | 3.60 | 0.20 | [3, 5, 6, 3, 1]
|
| 1236 | Why Did This Model Forecast This Future? Information-Theoretic Temporal Saliency for Counterfactual Explanations of Probabilistic Forecasts | 3.67 | 3.50 | -0.17 | [3, 5, 3, 3]
|
| 1237 | CLMIU: Commonsense Learning in Multimodal Image Understanding. | 3.67 | 4.25 | 0.58 | [6, 3, 3, 5]
|
| 1238 | Topological Data Analysis-Deep Learning Framework for Predicting Cancer Phenotypes | 3.50 | 3.50 | 0.00 | [5, 5, 3, 1]
|
| 1239 | In-Situ Text-Only Adaptation of Speech Models with Low-Overhead Speech Imputations | 6.75 | 6.75 | 0.00 | [8, 8, 6, 5]
|
| 1240 | Rethinking Uniformity in Self-Supervised Representation Learning | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 1241 | Proposal-Contrastive Pretraining for Object Detection from Fewer Data | 5.67 | 5.67 | 0.00 | [3, 8, 6]
|
| 1242 | SkillS: Adaptive Skill Sequencing for Efficient Temporally-Extended Exploration | 5.00 | 5.00 | 0.00 | [3, 8, 6, 3]
|
| 1243 | Bridging between Pool- and Stream-Based Active Learning with Temporal Data Coherence | 3.67 | 3.67 | 0.00 | [5, 1, 5]
|
| 1244 | The Robustness Limits of SoTA Vision Models to Natural Variation | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 1245 | Scaling Laws For Deep Learning Based Image Reconstruction | 5.40 | 5.60 | 0.20 | [8, 6, 5, 3, 6]
|
| 1246 | Robust Exploration via Clustering-based Online Density Estimation | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1247 | Meta Learning to Bridge Vision and Language Models for Multimodal Few-Shot Learning | 5.75 | 5.75 | 0.00 | [6, 8, 6, 3]
|
| 1248 | DLP: Data-Driven Label-Poisoning Backdoor Attack | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 1249 | AlphaFold Distillation for Improved Inverse Protein Folding | 5.00 | 5.00 | 0.00 | [3, 8, 3, 6]
|
| 1250 | Convexifying Transformers: Improving optimization and understanding of transformer networks | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 1251 | Unsupervised Model-based Pre-training for Data-efficient Control from Pixels | 5.50 | 5.50 | 0.00 | [6, 5, 3, 8]
|
| 1252 | A Cognitive-inspired Multi-Module Architecture for Continual Learning | 5.00 | 5.25 | 0.25 | [5, 6, 5, 5]
|
| 1253 | Shuffled Transformers for Blind Training | 5.25 | 5.25 | 0.00 | [5, 8, 5, 3]
|
| 1254 | Non-Gaussian Process Regression | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 1255 | ImageNet-X: Understanding Model Mistakes with Factor of Variation Annotations | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 1256 | Hardware-aware compression with Random Operation Access Specific Tile (ROAST) hashing | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 1257 | SoftZoo: A Soft Robot Co-design Benchmark For Locomotion In Diverse Environments | 7.33 | 7.33 | 0.00 | [8, 6, 8]
|
| 1258 | Smooth Mathematical Functions from Compact Neural Networks | 2.00 | 2.00 | 0.00 | [1, 3, 1, 3]
|
| 1259 | Self-Supervised Learning of Maximum Manifold Capacity Representations | 4.75 | 5.25 | 0.50 | [5, 6, 5, 5]
|
| 1260 | PMI-guided Masking Strategy to Enable Few-shot Learning for Genomic Applications | 4.75 | 4.75 | 0.00 | [3, 8, 3, 5]
|
| 1261 | TOWARDS AN OBJECTIVE EVALUATION OF THE TRUSTWORTHINESS OF CLASSIFIERS | 4.25 | 4.25 | 0.00 | [5, 8, 3, 1]
|
| 1262 | Fine-grain Inference on Out-of-Distribution Data with Hierarchical Classification | 5.50 | 5.50 | 0.00 | [5, 6, 8, 3]
|
| 1263 | ResGrad: Residual Denoising Diffusion Probabilistic Models for Text to Speech | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 1264 | The Adversarial Regulation of the Temporal Difference Loss Costs More Than Expected | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 1265 | Beyond Link Prediction: On Pre-Training Knowledge Graph Embeddings | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 1266 | SYNC: Efficient Neural Code Search Through Structurally Guided Hard Negative Curricula | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 1267 | Masked Siamese ConvNets: Towards an Effective Masking Strategy for General-purpose Siamese Networks | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 1268 | Canary in a Coalmine: Better Membership Inference with Ensembled Adversarial Queries | 7.00 | 8.00 | 1.00 | [8, 8, 8]
|
| 1269 | Maximum Entropy Information Bottleneck for Confidence-aware Stochastic Embedding | 5.75 | 5.75 | 0.00 | [5, 5, 8, 5]
|
| 1270 | Reprogramming Large Pretrained Language Models for Antibody Sequence Infilling | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 1271 | Optimal Scalarizations for Provable Multiobjective Optimization | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 1272 | Using semantic distance for diverse and sample efficient genetic programming | 3.00 | 3.00 | 0.00 | [5, 3, 1]
|
| 1273 | Semi-parametric Prompt-Generation for Model Editing | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 1274 | Fast Bayesian Updates for Deep Learning with a Use Case in Active Learning | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 1275 | Improved Learning-augmented Algorithms for k-means and k-medians Clustering | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 1276 | A Subspace Correction Method for ReLU Neural Networks for Solving PDEs | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1277 | Neural Implicit Shape Editing using Boundary Sensitivity | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 1278 | Amortised Invariance Learning for Contrastive Self-Supervision | 5.25 | 5.25 | 0.00 | [8, 3, 5, 5]
|
| 1279 | Direct-Effect Risk Minimization | 4.25 | 4.25 | 0.00 | [3, 5, 6, 3]
|
| 1280 | DIFFUSION GENERATIVE MODELS ON SO(3) | 6.00 | 6.00 | 0.00 | [5, 5, 8]
|
| 1281 | Certifiably Robust Transformers with 1-Lipschitz Self-Attention | 5.75 | 5.75 | 0.00 | [6, 6, 6, 5]
|
| 1282 | Revisiting Populations in multi-agent Communication | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 1283 | Univariate vs Multivariate Time Series Forecasting with Transformers | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 1284 | Semantic Transformation-based Data Augmentation for Few-Shot Learning | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 1285 | Sequential Gradient Coding For Straggler Mitigation | 6.25 | 6.25 | 0.00 | [5, 6, 6, 8]
|
| 1286 | TTN: A Domain-Shift Aware Batch Normalization in Test-Time Adaptation | 5.50 | 6.00 | 0.50 | [5, 8, 6, 5]
|
| 1287 | Choreographer: Learning and Adapting Skills in Imagination | 6.75 | 7.00 | 0.25 | [6, 8, 8, 6]
|
| 1288 | Disentanglement of Correlated Factors via Hausdorff Factorized Support | 7.33 | 7.33 | 0.00 | [8, 6, 8]
|
| 1289 | TimeSeAD: Benchmarking Deep Time-Series Anomaly Detection | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 1290 | On the optimization and generalization of overparameterized implicit neural networks | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 1291 | Differentially Private Conditional Text Generation For Synthetic Data Production | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 1292 | Multi-Task Structural Learning using Local Task Similarity induced Neuron Creation and Removal | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 1293 | Generating Sequences by Learning to Self-Correct | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 1294 | Bringing robotics taxonomies to continuous domains via GPLVM on hyperbolic manifolds | 6.33 | 6.33 | 0.00 | [5, 8, 6]
|
| 1295 | COC curve: operating neural networks at high accuracy and low manual effort | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 1296 | Learning to Unlearn: Instance-wise Unlearning for Pre-trained Classifiers | 5.33 | 5.33 | 0.00 | [3, 5, 8]
|
| 1297 | Repository-Level Prompt Generation for Large Language Models of Code | 5.50 | 5.50 | 0.00 | [5, 3, 6, 8]
|
| 1298 | Predicting Out-of-Domain Generalization with Local Manifold Smoothness | 4.25 | 4.25 | 0.00 | [3, 3, 8, 3]
|
| 1299 | FP_AINet: Fusion Prototype with Adaptive Induction Network for Few-Shot Learning | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 1300 | CLUSTERBERT: MULTI-STAGE FINE-TUNING OF TRANSFORMERS FOR DEEP TEXT CLUSTERING | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 1301 | Neural Network Differential Equation Solvers allow unsupervised error estimation and correction | 5.67 | 5.50 | -0.17 | [5, 3, 8, 6]
|
| 1302 | Wide Attention is the Way Forward for Transformers | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 1303 | Variational Prompt Tuning Improves Generalization of Vision-Language Models | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 1304 | DCT-DiffStride: Differentiable Strides with Real-Valued Data | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 1305 | Interneurons accelerate learning dynamics in recurrent neural networks for statistical adaptation | 6.50 | 6.50 | 0.00 | [8, 8, 5, 5]
|
| 1306 | Burstormer: Burst Image Restoration and Enhancement Transformer | 4.25 | 4.25 | 0.00 | [3, 8, 3, 3]
|
| 1307 | Understanding DDPM Latent Codes Through Optimal Transport | 6.25 | 6.25 | 0.00 | [8, 6, 6, 5]
|
| 1308 | Soft Sampling for Efficient Training of Deep Neural Networks on Massive Data | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1309 | Learning About Progress From Experts | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 1310 | Learning Fair Graph Representations via Automated Data Augmentations | 7.00 | 7.00 | 0.00 | [6, 6, 8, 8]
|
| 1311 | FUN: Filter-based Unlearnable Datasets | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 1312 | A new photoreceptor-inspired CNN layer enables deep learning models of retina to generalize across lighting conditions | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 1313 | 3D Neural Embedding Likelihood for Robust Sim-to-Real Transfer in Inverse Graphics | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 1314 | Dynamic Scheduled Sampling with Imitation Loss for Neural Text Generation | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 1315 | Emergence of Maps in the Memories of Blind Navigation Agents | 8.50 | 8.50 | 0.00 | [10, 8, 8, 8]
|
| 1316 | Latent Neural ODEs with Sparse Bayesian Multiple Shooting | 7.00 | 7.50 | 0.50 | [6, 6, 10, 8]
|
| 1317 | $\mathcal{O}$-GNN: incorporating ring priors into molecular modeling | 4.33 | 5.67 | 1.33 | [8, 3, 6]
|
| 1318 | MACTA: A Multi-agent Reinforcement Learning Approach for Cache Timing Attacks and Detection | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 1319 | Training Normalizing Flows from Dependent Data | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 1320 | Spectral Augmentation for Self-Supervised Learning on Graphs | 5.67 | 6.25 | 0.58 | [8, 3, 6, 8]
|
| 1321 | An ensemble view on mixup | 5.25 | 5.25 | 0.00 | [5, 8, 5, 3]
|
| 1322 | Improving Adversarial Robustness by Contrastive Guided Diffusion Process | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1323 | $\sigma$Reparam: Stable Transformer Training with Spectral Reparametrization | 4.25 | 4.25 | 0.00 | [3, 8, 3, 3]
|
| 1324 | Towards Multi-spatiotemporal-scale Generalized PDE Modeling | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 1325 | PAC Reinforcement Learning for Predictive State Representations | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 1326 | Federated Learning on Adaptively Weighted Nodes by Bilevel Optimization | 4.25 | 4.25 | 0.00 | [3, 3, 5, 6]
|
| 1327 | Removing Structured Noise with Diffusion Models | 4.75 | 4.75 | 0.00 | [5, 3, 8, 3]
|
| 1328 | Stein Variational Goal Generation for adaptive Exploration in Multi-Goal Reinforcement Learning | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 1329 | Fourier PINNs: From Strong Boundary Conditions to Adaptive Fourier Bases | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1330 | Distributed Graph Neural Network Training with Periodic Stale Representation Synchronization | 6.00 | 6.00 | 0.00 | [5, 8, 5, 6]
|
| 1331 | SAGE: Semantic-Aware Global Explanations for Named Entity Recognition | 4.00 | 4.00 | 0.00 | [3, 3, 6, 3, 5]
|
| 1332 | Decentralized Optimistic Hyperpolicy Mirror Descent: Provably No-Regret Learning in Markov Games | 7.00 | 7.00 | 0.00 | [6, 6, 8, 8]
|
| 1333 | Graph Contrastive Learning with Model Perturbation | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 1334 | Robust Scheduling with GFlowNets | 8.00 | 8.00 | 0.00 | [8, 8, 8, 8]
|
| 1335 | Pareto Manifold Learning: Tackling multiple tasks via ensembles of single-task models | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1336 | Autoregressive Conditional Neural Processes | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 1337 | Exploring Methods for Parsing Movie Scripts - Feature Extraction for Further Social Injustice Analysis | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 1338 | MultiQuan RDP: Rate-Distortion-Perception Coding via Offset Quantizers | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 1339 | $k$NN Prompting: Learning Beyond the Context with Nearest Neighbor Inference | 5.75 | 5.75 | 0.00 | [3, 8, 6, 6]
|
| 1340 | Closed-loop Transcription via Convolutional Sparse Coding | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 1341 | Transformers Learn Shortcuts to Automata | 8.00 | 8.00 | 0.00 | [6, 10, 8]
|
| 1342 | Efficient neural representation in the cognitive neuroscience domain: Manifold Capacity in One-vs-rest Recognition Limit | 5.20 | 5.20 | 0.00 | [3, 6, 3, 8, 6]
|
| 1343 | ULF: UNSUPERVISED LABELING FUNCTION CORRECTION USING CROSS-VALIDATION FOR WEAK SUPERVISION | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 1344 | Islands of Confidence: Robust Neural Network Classification with Uncertainty Quantification | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 1345 | REST: REtrieve & Self-Train for generative action recognition | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 1346 | Quantization-aware Policy Distillation (QPD) | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 1347 | Conceptual Behavior and Human-Likeness in Vision-and-Language Models | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1348 | Highly Parallel Deep Ensemble Learning | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1349 | On the Forward Invariance of Neural ODEs | 4.00 | 4.00 | 0.00 | [6, 6, 1, 3]
|
| 1350 | Obtaining More Generalizable Fair Classifiers on Imbalanced Datasets | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 1351 | GMML is All you Need | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 1352 | Understanding The Robustness of Self-supervised Learning Through Topic Modeling | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 1353 | Temporal Disentanglement of Representations for Improved Generalisation in Reinforcement Learning | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 1354 | Distilling Pre-trained Knowledge in Chemical Reactions for Molecular Property Prediction | 3.75 | 3.75 | 0.00 | [6, 3, 3, 3]
|
| 1355 | Provably Efficient Neural Offline Reinforcement Learning via Perturbed Rewards | 7.50 | 7.50 | 0.00 | [6, 8, 8, 8]
|
| 1356 | Learning Debiased Representations via Conditional Attribute Interpolation | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 1357 | Active Learning at the ImageNet Scale | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 1358 | Deep Probabilistic Time Series Forecasting over Long Horizons | 4.67 | 4.67 | 0.00 | [3, 8, 3]
|
| 1359 | Revealing Dominant Eigendirections via Spectral Non-Robustness Analysis in the Deep Reinforcement Learning Policy Manifold | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3, 3]
|
| 1360 | MC-SSL: Towards Multi-Concept Self-Supervised Learning | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 1361 | Latent Hierarchical Imitation Learning for Stochastic Environments | 4.75 | 4.75 | 0.00 | [3, 3, 5, 8]
|
| 1362 | Trimsformer: Trimming Transformer via Searching for Low-Rank Structure | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 1363 | Exploring the Limits of Differentially Private Deep Learning with Group-wise Clipping | 7.33 | 7.33 | 0.00 | [8, 8, 6]
|
| 1364 | Continual Zero-shot Learning through Semantically Guided Generative Random Walks | 5.25 | 5.25 | 0.00 | [5, 3, 8, 5]
|
| 1365 | Mesh-free Eulerian Physics-Informed Neural Networks | 4.83 | 4.83 | 0.00 | [5, 6, 3, 6, 3, 6]
|
| 1366 | Self-supervised learning with rotation-invariant kernels | 6.25 | 6.25 | 0.00 | [6, 5, 8, 6]
|
| 1367 | Strong inductive biases provably prevent harmless interpolation | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 1368 | Active Learning based Structural Inference | 5.67 | 5.67 | 0.00 | [3, 8, 6]
|
| 1369 | Batch Normalization Explained | 3.75 | 3.75 | 0.00 | [3, 3, 6, 3]
|
| 1370 | AN OPERATOR NORM BASED PASSIVE FILTER PRUNING METHOD FOR EFFICIENT CNNS | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 1371 | Neuromechanical Autoencoders: Learning to Couple Elastic and Neural Network Nonlinearity | 7.25 | 7.25 | 0.00 | [8, 5, 8, 8]
|
| 1372 | Temporal Dynamics Aware Adversarial Attacks On Discrete-Time Graph Models | 4.60 | 4.60 | 0.00 | [5, 6, 6, 5, 1]
|
| 1373 | Automatic Curriculum Generation for Reinforcement Learning in Zero-Sum Games | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 1374 | Internet-augmented language models through few-shot prompting for open-domain question answering | 4.50 | 4.50 | 0.00 | [3, 3, 6, 6]
|
| 1375 | Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training | 7.00 | 7.00 | 0.00 | [6, 8, 6, 8]
|
| 1376 | Language Modeling Using Tensor Trains | 3.67 | 3.67 | 0.00 | [5, 5, 1]
|
| 1377 | Bridging the Gap to Real-World Object-Centric Learning | 5.50 | 5.50 | 0.00 | [5, 6, 8, 3]
|
| 1378 | Towards a Unified Theoretical Understanding of Non-contrastive Learning via Rank Differential Mechanism | 5.33 | 5.67 | 0.33 | [5, 6, 6]
|
| 1379 | Weighted Regularization for Efficient Neural Network Compression | 4.67 | 4.67 | 0.00 | [3, 3, 8]
|
| 1380 | Stay Moral and Explore: Learn to Behave Morally in Text-based Games | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 1381 | Efficient Discovery of Dynamical Laws in Symbolic Form | 4.75 | 4.75 | 0.00 | [3, 5, 3, 8]
|
| 1382 | Brain2GAN; Reconstructing perceived faces from the primate brain via StyleGAN3 | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1383 | Self-Guided Diffusion Models | 5.25 | 4.80 | -0.45 | [3, 5, 5, 5, 6]
|
| 1384 | Optimistic Exploration with Learned Features Provably Solves Markov Decision Processes with Neural Dynamics | 5.00 | 5.67 | 0.67 | [8, 6, 3]
|
| 1385 | Removing Backdoors in Pre-trained Models by Regularized Continual Pre-training | 4.25 | 4.25 | 0.00 | [5, 3, 3, 6]
|
| 1386 | Would decentralization hurt generalization? | 3.67 | 3.67 | 0.00 | [5, 3, 5, 1, 3, 5]
|
| 1387 | Variational Pseudo Labels for Meta Test-time Adaptation | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 1388 | No-Regret Learning in Strongly Monotone Games Converges to a Nash Equilibrium | 5.67 | 5.00 | -0.67 | [5, 3, 6, 6]
|
| 1389 | Generalized Belief Transport | 4.50 | 4.50 | 0.00 | [1, 6, 6, 5]
|
| 1390 | Adversarial Cheap Talk | 6.00 | 6.25 | 0.25 | [6, 6, 5, 8]
|
| 1391 | Multi-stationary point losses for robust model | 4.00 | 4.00 | 0.00 | [8, 3, 1]
|
| 1392 | Learning Stackelberg Equilibria and Applications to Economic Design Games | 4.00 | 4.00 | 0.00 | [6, 6, 1, 3]
|
| 1393 | Learning to Induce Causal Structure | 5.80 | 6.20 | 0.40 | [8, 5, 5, 5, 8]
|
| 1394 | Attention Based Models for Cell Type Classification on Single-Cell RNA-Seq Data | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 1395 | Personalized federated composite learning with forward-backward envelopes | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 1396 | Tackling Imbalanced Class in Federated Learning via Class Distribution Estimation | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 1397 | Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning | 7.25 | 7.50 | 0.25 | [8, 8, 8, 6]
|
| 1398 | Sublinear Algorithms for Kernel Matrices via Kernel Density Estimation | 6.67 | 8.00 | 1.33 | [8, 8, 8]
|
| 1399 | CASA: Bridging the Gap between Policy Improvement and Policy Evaluation with Conflict Averse Policy Iteration | 3.75 | 4.25 | 0.50 | [6, 3, 3, 5]
|
| 1400 | Achieve Near-Optimal Individual Regret & Low Communications in Multi-Agent Bandits | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 1401 | Online Boundary-Free Continual Learning by Scheduled Data Prior | 6.00 | 6.20 | 0.20 | [6, 6, 8, 6, 5]
|
| 1402 | HypeR: Multitask Hyper-Prompted Training Enables Large-Scale Retrieval Generalization | 6.50 | 7.00 | 0.50 | [8, 6, 6, 8]
|
| 1403 | HiT-DVAE: Human Motion Generation via Hierarchical Transformer Dynamical VAE | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 1404 | Efficient Learning of Rationalizable Equilibria in General-Sum Games | 7.25 | 7.25 | 0.00 | [5, 8, 8, 8]
|
| 1405 | A Higher Precision Algorithm for Computing the $1$-Wasserstein Distance | 7.00 | 8.00 | 1.00 | [8, 8, 8]
|
| 1406 | Energy-Based Test Sample Adaptation for Domain Generalization | 5.50 | 6.00 | 0.50 | [6, 5, 8, 5]
|
| 1407 | Representation Power of Graph Convolutions : Neural Tangent Kernel Analysis | 4.40 | 4.40 | 0.00 | [8, 3, 3, 5, 3]
|
| 1408 | Bidirectional Language Models Are Also Few-shot Learners | 6.25 | 6.75 | 0.50 | [8, 8, 5, 6]
|
| 1409 | Revisiting adapters with adversarial training | 6.00 | 6.00 | 0.00 | [5, 5, 6, 8]
|
| 1410 | Human-AI Coordination via Human-Regularized Search and Learning | 4.75 | 4.75 | 0.00 | [5, 3, 3, 8]
|
| 1411 | Solving Math Word Problems with Process-based and Outcome-based Feedback | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1412 | EPISODE: Episodic Gradient Clipping with Periodic Resampled Corrections for Federated Learning with Heterogeneous Data | 6.25 | 6.25 | 0.00 | [6, 5, 6, 8]
|
| 1413 | Memory-Efficient Reinforcement Learning with Priority based on Surprise and On-policyness | 5.25 | 5.25 | 0.00 | [3, 8, 5, 5]
|
| 1414 | Uncovering Directions of Instability via Quadratic Approximation of Deep Neural Loss in Reinforcement Learning | 5.75 | 5.75 | 0.00 | [5, 5, 5, 8]
|
| 1415 | Marginal Probability Explanation: A Saliency Map with Closed-loop Validation | 3.25 | 3.25 | 0.00 | [1, 6, 5, 1]
|
| 1416 | A Theory of Dynamic Benchmarks | 6.33 | 6.67 | 0.33 | [6, 6, 8]
|
| 1417 | On the Trade-Off between Actionable Explanations and the Right to be Forgotten | 6.50 | 6.50 | 0.00 | [8, 6, 6, 6]
|
| 1418 | Learning to Cooperate and Communicate Over Imperfect Channels | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1419 | A GENERAL SCENARIO-AGNOSTIC REINFORCEMENT LEARNING FOR TRAFFIC SIGNAL CONTROL | 5.50 | 5.50 | 0.00 | [5, 6, 6, 5]
|
| 1420 | Uncertainty-aware off policy learning | 5.25 | 5.25 | 0.00 | [5, 8, 5, 3]
|
| 1421 | Renamer: A Transformer Architecture In-variant to Variable Renaming | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 1422 | Learning What and Where - Unsupervised Disentangling Location and Identity Tracking | 6.50 | 6.75 | 0.25 | [8, 8, 5, 6]
|
| 1423 | BALTO: efficient tensor program optimization with diversity-based active learning | 5.50 | 5.50 | 0.00 | [5, 8, 3, 6]
|
| 1424 | RoCourseNet: Distributionally Robust Training of a Prediction Aware Recourse Model | 3.75 | 3.75 | 0.00 | [6, 3, 3, 3]
|
| 1425 | Inducing Meaningful Units from Character Sequences with Dynamic Capacity Slot Attention | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 1426 | Enhanced Spatio-Temporal Image Encoding for Online Human Activity Recognition | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1427 | In-context Reinforcement Learning with Algorithm Distillation | 6.75 | 7.25 | 0.50 | [5, 6, 8, 10]
|
| 1428 | BiasPAD: A Bias-Progressive Auto-Debiasing Framework | 3.33 | 3.33 | 0.00 | [6, 1, 3]
|
| 1429 | Computing all Optimal Partial Transports | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 1430 | Towards Federated Learning of Deep Graph Neural Networks | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1431 | CounterNet: End-to-End Training of Prediction Aware Counterfactual Explanations | 4.75 | 4.75 | 0.00 | [3, 3, 10, 3]
|
| 1432 | SmilesFormer: Language Model for Molecular Design | 3.00 | 3.00 | 0.00 | [5, 3, 1]
|
| 1433 | Continuously Parameterized Mixture Models | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 1434 | AE-FLOW: Autoencoders with Normalizing Flows for Medical Images Anomaly Detection | 5.33 | 6.67 | 1.33 | [8, 6, 6]
|
| 1435 | Learning a Domain-Agnostic Policy through Adversarial Representation Matching for Cross-Domain Policy Transfer | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 1436 | A Self-Attention Ansatz for Ab-initio Quantum Chemistry | 6.00 | 6.25 | 0.25 | [6, 5, 6, 8]
|
| 1437 | Probabilistically Robust Recourse: Navigating the Trade-offs between Costs and Robustness in Algorithmic Recourse | 6.25 | 6.25 | 0.00 | [5, 6, 8, 6]
|
| 1438 | How robust is unsupervised representation learning to distribution shift? | 5.50 | 5.50 | 0.00 | [6, 8, 5, 3]
|
| 1439 | Autoregressive Generative Modeling with Noise Conditional Maximum Likelihood Estimation | 5.50 | 5.50 | 0.00 | [3, 3, 8, 8]
|
| 1440 | Multi-Behavior Dynamic Contrastive Learning for Recommendation | 6.00 | 6.00 | 0.00 | [6, 5, 5, 8]
|
| 1441 | Analyzing diffusion as serial reproduction | 5.25 | 5.25 | 0.00 | [5, 8, 5, 3]
|
| 1442 | Pseudo-label Training and Model Inertia in Neural Machine Translation | 5.25 | 5.25 | 0.00 | [3, 8, 5, 5]
|
| 1443 | Adaptive Smoothing Gradient Learning for Spiking Neural Networks | 4.75 | 4.75 | 0.00 | [5, 3, 3, 8]
|
| 1444 | Going Beyond Approximation: Encoding Constraints for Explainable Multi-hop Inference via Differentiable Combinatorial Solvers | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 1445 | Robust and accelerated single-spike spiking neural network training with applicability to challenging temporal tasks | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 1446 | Using Planning to Improve Semantic Parsing of Instructional Texts | 3.00 | 3.00 | 0.00 | [5, 1, 3, 3]
|
| 1447 | A NEW PARADIGM FOR CROSS-MODALITY PERSON RE-IDENTIFICATION | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1448 | Causal Mean Field Multi-Agent Reinforcement Learning | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 1449 | Hidden Markov Mixture of Gaussian Process Functional Regression: Utilizing Multi-Scale Structure for Time-Series Forecasting | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1450 | HyperDeepONet: learning operator with complex target function space using the limited resources via hypernetwork | 6.00 | 6.67 | 0.67 | [8, 6, 6]
|
| 1451 | CLAS: Central Latent Action Spaces for Coordinated Multi-Robot Manipulation | 4.25 | 4.75 | 0.50 | [5, 5, 6, 3]
|
| 1452 | Edge Guided GANs with Contrastive Learning for Semantic Image Synthesis | 5.50 | 5.50 | 0.00 | [8, 6, 5, 3]
|
| 1453 | Towards Reliable Link Prediction with Robust Graph Information Bottleneck | 5.00 | 5.00 | 0.00 | [3, 5, 6, 6]
|
| 1454 | Enforcing Delayed-Impact Fairness Guarantees | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 1455 | Affinity-Aware Graph Networks | 5.50 | 5.50 | 0.00 | [5, 6, 6, 5]
|
| 1456 | Few-shot Lifelong Reinforcement Learning with Generalization Guarantees: An Empirical PAC-Bayes Approach | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1457 | Towards the Detection of Diffusion Model Deepfakes | 6.00 | 6.00 | 0.00 | [6, 5, 8, 5, 6]
|
| 1458 | Global-Scale Species Mapping From Crowdsourced Data | 3.75 | 3.75 | 0.00 | [6, 3, 3, 3]
|
| 1459 | CANIFE: Crafting Canaries for Empirical Privacy Measurement in Federated Learning | 6.50 | 6.50 | 0.00 | [5, 5, 8, 8]
|
| 1460 | Multivariate Time Series Forecasting By Graph Attention Networks With Theoretical Guarantees | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 1461 | Maximal Correlation-Based Post-Nonlinear Learning for Bivariate Causal Discovery | 4.50 | 4.50 | 0.00 | [3, 3, 6, 6]
|
| 1462 | A View From Somewhere: Human-Centric Face Representations | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 1463 | Identifiability Results for Multimodal Contrastive Learning | 6.00 | 5.80 | -0.20 | [5, 5, 5, 6, 8]
|
| 1464 | Task-Agnostic Unsupervised Robust Representation Learning | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 1465 | Federated Learning as Variational Inference: A Scalable Expectation Propagation Approach | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 1466 | Latent Graph Inference using Product Manifolds | 5.67 | 5.67 | 0.00 | [6, 8, 3]
|
| 1467 | UNICORN: A Unified Backdoor Trigger Inversion Framework | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 1468 | DBA: Efficient Transformer with Dynamic Bilinear Low-Rank Attention | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 1469 | On the Robustness of Dataset Inference | 5.33 | 5.33 | 0.00 | [5, 8, 3]
|
| 1470 | Client-agnostic Learning and Zero-shot Adaptation for Federated Domain Generalization | 4.75 | 5.00 | 0.25 | [3, 5, 6, 6]
|
| 1471 | Towards Robust Model Watermark via Reducing Parametric Vulnerability | 5.33 | 5.33 | 0.00 | [8, 5, 3]
|
| 1472 | DP-InstaHide: Data Augmentations Provably Enhance Guarantees Against Dataset Manipulations | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 1473 | This Looks Like It Rather Than That: ProtoKNN For Similarity-Based Classifiers | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 1474 | SEQuence-rPPG: A Fast BVP Signal Extraction Method From Frame Sequences | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1475 | Understanding weight-magnitude hyperparameters in training binary networks | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 1476 | Sample-efficient multi-objective molecular optimization with GFlowNets | 4.25 | 4.25 | 0.00 | [1, 5, 8, 3]
|
| 1477 | Learning Robust Kernel Ensembles with Kernel Average Pooling | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 1478 | Affinity-VAE for clustering and classification of objects in multidimensional image data | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 1479 | Model Stealing Attacks Against Vision-Language Models | 3.00 | 3.00 | 0.00 | [3, 3, 1, 5]
|
| 1480 | Causal Attention to Exploit Transient Emergence of Causal Effect | 6.00 | 6.00 | 0.00 | [5, 5, 8]
|
| 1481 | A Simple Nadaraya-Watson Head for Explainable and Calibrated Classification | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 1482 | Imitating Human Behaviour with Diffusion Models | 7.00 | 7.00 | 0.00 | [8, 6, 6, 8]
|
| 1483 | Learning Privacy-Preserving Graph Embeddings Against Sensitive Attributes Inference | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 1484 | InteriorSim: A Photorealistic Simulator for Embodied AI | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 1485 | Prompt-Based Metric Learning for Few-Shot NER | 4.75 | 4.75 | 0.00 | [5, 3, 6, 5]
|
| 1486 | MetaPhysiCa: Causality-aware Robustness to OOD Initial Conditions in Physics-informed Machine Learning | 4.75 | 5.00 | 0.25 | [6, 3, 5, 6, 5]
|
| 1487 | Representation Balancing with Decomposed Patterns for Treatment Effect Estimation | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 1488 | Selection-Inference: Exploiting Large Language Models for Interpretable Logical Reasoning | 7.60 | 7.60 | 0.00 | [8, 6, 8, 8, 8]
|
| 1489 | Guided Safe Shooting: model based reinforcement learning with safety constraints | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 1490 | Contrastive Meta-Learning for Partially Observable Few-Shot Learning | 5.00 | 5.25 | 0.25 | [6, 6, 3, 6]
|
| 1491 | Analyzing Transformers in Embedding Space | 5.00 | 5.00 | 0.00 | [6, 3, 3, 8]
|
| 1492 | Enhancing the Inductive Biases of Graph Neural ODE for Modeling Dynamical Systems | 5.50 | 6.25 | 0.75 | [8, 6, 5, 6]
|
| 1493 | Efficient Planning in a Compact Latent Action Space | 6.33 | 6.33 | 0.00 | [8, 6, 5]
|
| 1494 | Improved Stein Variational Gradient Descent with Importance Weights | 3.00 | 3.00 | 0.00 | [1, 5, 3]
|
| 1495 | Correlative Information Maximization Based Biologically Plausible Neural Networks for Correlated Source Separation | 6.00 | 6.33 | 0.33 | [6, 8, 5]
|
| 1496 | Simplicity bias leads to amplified performance disparities | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 1497 | Annealed Fisher Implicit Sampler | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 1498 | Do You Remember? Overcoming Catastrophic Forgetting for Fake Audio Detection | 5.00 | 5.00 | 0.00 | [6, 6, 3, 5]
|
| 1499 | Towards Conditionally Dependent Masked Language Models | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 1500 | Leveraging Importance Weights in Subset Selection | 5.75 | 5.75 | 0.00 | [3, 6, 6, 8]
|
| 1501 | Interactive Sequential Generative Models | 4.50 | 4.25 | -0.25 | [6, 3, 5, 3]
|
| 1502 | Gradient flow in the gaussian covariate model: exact solution of learning curves and multiple descent structures | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 1503 | Copy is All You Need | 6.00 | 6.00 | 0.00 | [8, 5, 5, 6]
|
| 1504 | Graph Backup: Data Efficient Backup Exploiting Markovian Transitions | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 1505 | Finding Generalization Measures by Contrasting Signal and Noise | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 1506 | Linearised Implicit Variational Inference | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1507 | Adversarial Driving Policy Learning by Misunderstanding the Traffic Flow | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 1508 | Differentiable and transportable structure learning | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 1509 | Distributed Inference and Fine-tuning of Large Language Models Over The Internet | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 1510 | Association Rules in QUBO Samples and Where to Find Them | 4.50 | 4.50 | 0.00 | [6, 3]
|
| 1511 | Why adversarial training can hurt robust accuracy | 6.00 | 6.00 | 0.00 | [8, 5, 3, 8]
|
| 1512 | ExpressivE: A Spatio-Functional Embedding For Knowledge Graph Completion | 7.25 | 8.00 | 0.75 | [6, 10, 8, 8]
|
| 1513 | Counterfactual Explanation via Search in Gaussian Mixture Distributed Latent Space | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 1514 | FedPD: Defying data heterogeneity through privacy distillation | 2.50 | 2.50 | 0.00 | [3, 3, 3, 1]
|
| 1515 | Harnessing Client Drift with Decoupled Gradient Dissimilarity | 3.75 | 4.25 | 0.50 | [3, 3, 6, 5]
|
| 1516 | SeKron: A Decomposition Method Supporting Many Factorization Structures | 4.00 | 4.00 | 0.00 | [5, 6, 1]
|
| 1517 | Localized Randomized Smoothing for Collective Robustness Certification | 6.33 | 7.33 | 1.00 | [6, 8, 8]
|
| 1518 | Learning Dictionaries over Datasets through Wasserstein Barycenters | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 1519 | Spatial Entropy as an Inductive Bias for Vision Transformers | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 1520 | Learning Interpretable Neural Discrete Representation for Time Series Classification | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 1521 | Representational Dissimilarity Metric Spaces for Stochastic Neural Networks | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 1522 | Hierarchical Prototypes for Unsupervised Dynamics Generalization in Model-Based Reinforcement Learning | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1523 | MILAN: Masked Image Pretraining on Language Assisted Representation | 5.75 | 5.75 | 0.00 | [5, 5, 8, 5]
|
| 1524 | Irregularity Reflection Neural Network for Time Series Forecasting | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 1525 | Sequential Learning of Neural Networks for Prequential MDL | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 1526 | Reducing Communication Entropy in Multi-Agent Reinforcement Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1527 | Relaxed Attention for Transformer Models | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 1528 | SynBench: Task-Agnostic Benchmarking of Pretrained Representations using Synthetic Data | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 1529 | Learning topology-preserving data representations | 5.75 | 5.75 | 0.00 | [3, 6, 8, 6]
|
| 1530 | Interpreting Class Conditional GANs with Channel Awareness | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 1531 | Escaping saddle points in zeroth-order optimization: two function evaluations suffice | 4.60 | 5.20 | 0.60 | [3, 6, 3, 6, 8]
|
| 1532 | Vector Quantization and Shifting: Exploiting Latent Properties to Optimize Neural Codecs | 4.50 | 5.00 | 0.50 | [8, 3, 3, 6]
|
| 1533 | Time-Myopic Go-Explore: Learning A State Representation for the Go-Explore Paradigm | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1534 | Mastering Spatial Graph Prediction of Road Networks | 5.50 | 5.50 | 0.00 | [3, 6, 8, 5]
|
| 1535 | A Simple Framework for Low-Resolution Detection with High-resolution Knowledge | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 1536 | Learning Probabilistic Topological Representations Using Discrete Morse Theory | 5.67 | 5.67 | 0.00 | [3, 6, 8]
|
| 1537 | Zero-Label Prompt Selection | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 1538 | The Curious Case of Benign Memorization | 5.75 | 6.25 | 0.50 | [8, 6, 5, 6]
|
| 1539 | A Connection between One-Step Regularization and Critic Regularization in Reinforcement Learning | 5.50 | 5.50 | 0.00 | [6, 8, 5, 3]
|
| 1540 | Deep Class Conditional Gaussians for Continual Learning | 4.00 | 4.67 | 0.67 | [3, 6, 5]
|
| 1541 | AGREE: A Simple Aggregator of Detectors’ Decisions | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 1542 | Unbiased Supervised Contrastive Learning | 6.33 | 6.33 | 0.00 | [6, 8, 5]
|
| 1543 | ReaKE: Contrastive Molecular Representation Learning with Chemical Synthetic Knowledge Graph | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 1544 | Graph MLP-Mixer | 5.00 | 5.25 | 0.25 | [5, 5, 5, 6]
|
| 1545 | Multivariate Gaussian Representation of Previous Tasks for Continual Learning | 2.50 | 2.50 | 0.00 | [3, 3, 3, 1]
|
| 1546 | Learning to Register Unbalanced Point Pairs | 4.50 | 4.50 | 0.00 | [5, 1, 6, 6]
|
| 1547 | On Feature Diversity in Energy-based Models | 4.00 | 3.80 | -0.20 | [3, 5, 1, 5, 5]
|
| 1548 | Physics Model-based Autoencoding for Magnetic Resonance Fingerprinting | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1549 | Compositional Prompt Tuning with Motion Cues for Open-vocabulary Video Relation Detection | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 1550 | Multi-objective optimization via equivariant deep hypervolume approximation | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 1551 | Conditional Execution Of Cascaded Models Improves The Accuracy-Efficiency Trade-Off | 4.25 | 4.25 | 0.00 | [3, 8, 3, 3]
|
| 1552 | Adversarial Text to Continuous Image Generation | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 1553 | Fine-grained Few-shot Recognition by Deep Object Parsing | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 1554 | Can Wikipedia Help Offline Reinforcement Learning? | 5.75 | 5.75 | 0.00 | [6, 3, 6, 8]
|
| 1555 | Lightweight Equivariant Graph Representation Learning for Protein Engineering | 3.00 | 3.67 | 0.67 | [5, 3, 3]
|
| 1556 | DiffusER: Diffusion via Edit-based Reconstruction | 7.33 | 7.33 | 0.00 | [8, 8, 6]
|
| 1557 | Modeling Temporal Data as Continuous Functions with Process Diffusion | 5.75 | 5.75 | 0.00 | [6, 6, 6, 5]
|
| 1558 | KeyCLD: Learning Constrained Lagrangian Dynamics in Keypoint Coordinates from Images | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 1559 | DynaMS: Dyanmic Margin Selection for Efficient Deep Learning | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 1560 | TANGOS: Regularizing Tabular Neural Networks through Gradient Orthogonalization and Specialization | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 1561 | How does Uncertainty-aware Sample-selection Help Decision against Action Noise? | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 1562 | SPC-Net: A New Scalable Point Cloud Compression Framework for Both Machine and Human Vision Tasks | 3.60 | 3.60 | 0.00 | [3, 3, 6, 3, 3]
|
| 1563 | Inversely Eliciting Numerical Reasoning in Language Models via Solving Linear Systems | 5.50 | 5.50 | 0.00 | [5, 6, 3, 8]
|
| 1564 | Model-based Causal Bayesian Optimization | 5.75 | 6.50 | 0.75 | [5, 5, 8, 8]
|
| 1565 | Targeted Attacks on Timeseries Forecasting | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 1566 | QuAFL: Federated Averaging Made Asynchronous and Communication-Efficient | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 1567 | Random Matrix Analysis to Balance between Supervised and Unsupervised Learning under the Low Density Separation Assumption | 5.67 | 5.67 | 0.00 | [3, 6, 8]
|
| 1568 | Learning to Solve Constraint Satisfaction Problems with Recurrent Transformers | 5.00 | 5.00 | 0.00 | [6, 8, 3, 3]
|
| 1569 | MARLlib: Extending RLlib for Multi-agent Reinforcement Learning | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 1570 | Improving the imputation of missing data with Markov Blanket discovery | 6.00 | 6.50 | 0.50 | [5, 8, 8, 5]
|
| 1571 | Boosting the Cycle Counting Power of Graph Neural Networks with I$^2$-GNNs | 6.60 | 6.60 | 0.00 | [8, 6, 6, 5, 8]
|
| 1572 | Optimizing Connectivity through Network Gradients for the Restricted Machine | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1573 | Energy Consumption-Aware Tabular Benchmarks for Neural Architecture Search | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 1574 | Fundamental Limits in Formal Verification of Message-Passing Neural Networks | 7.25 | 7.25 | 0.00 | [8, 10, 8, 3]
|
| 1575 | Score Matching via Differentiable Physics | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 1576 | QUIC-FL: : Quick Unbiased Compression for Federated Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1577 | FedMEKT: Split Multimodal Embedding Knowledge Transfer in Federated Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1578 | Short-Term Memory Convolutions | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 1579 | End-to-End Speech Synthesis Based on Deep Conditional Schrödinger Bridges | 3.00 | 3.00 | 0.00 | [3, 1, 5, 3]
|
| 1580 | LexMAE: Lexicon-Bottlenecked Pretraining for Large-Scale Retrieval | 7.00 | 7.00 | 0.00 | [6, 6, 8, 8]
|
| 1581 | A GNN-Guided Predict-and-Search Framework for Mixed-Integer Linear Programming | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 1582 | Parameter Averaging for SGD Stabilizes the Implicit Bias towards Flat Regions | 5.25 | 5.25 | 0.00 | [5, 3, 5, 8]
|
| 1583 | On Explaining Neural Network Robustness with Activation Path | 5.50 | 5.75 | 0.25 | [6, 5, 6, 6]
|
| 1584 | Flareon: Stealthy Backdoor Injection via Poisoned Augmentation | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 1585 | Dimensionless instance segmentation by learning graph representations of point clouds | 4.25 | 4.25 | 0.00 | [3, 3, 8, 3]
|
| 1586 | Structure by Architecture: Structured Representations without Regularization | 5.50 | 5.50 | 0.00 | [3, 5, 8, 6]
|
| 1587 | Understanding Neural Coding on Latent Manifolds by Sharing Features and Dividing Ensembles | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 1588 | Learning Fast and Slow for Time Series Forecasting | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 1589 | Perturbation Defocusing for Adversarial Defense | 3.67 | 3.67 | 0.00 | [5, 1, 5]
|
| 1590 | Accuracy Boosters: Epoch-Driven Mixed-Mantissa Block Floating-Point for DNN Training | 4.40 | 4.40 | 0.00 | [3, 3, 8, 3, 5]
|
| 1591 | Compressing multidimensional weather and climate data into neural networks | 6.33 | 8.00 | 1.67 | [8, 8, 8]
|
| 1592 | Guess the Instruction! Making Language Models Stronger Zero-Shot Learners | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 1593 | Probabilistic Imputation for Time-series Classification with Missing Data | 5.75 | 5.75 | 0.00 | [8, 5, 5, 5]
|
| 1594 | Delve into the Layer Choice of BP-based Attribution Explanations | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 1595 | Timing is Everything: Learning to Act Selectively with Costly Actions and Budgetary Constraints | 5.75 | 5.75 | 0.00 | [3, 8, 6, 6]
|
| 1596 | Multi-Head State Space Model for Sequence Modeling | 4.00 | 4.00 | 0.00 | [6, 1, 6, 3]
|
| 1597 | A Weight Variation-Aware Training Method for Hardware Neuromorphic Chips | 4.75 | 4.75 | 0.00 | [3, 5, 5, 6]
|
| 1598 | Semantic Prior for Weakly Supervised Class-Incremental Segmentation | 4.25 | 4.25 | 0.00 | [6, 3, 3, 5]
|
| 1599 | A Mutual Information Duality Algorithm for Multi-Agent Specialization | 4.62 | 4.88 | 0.25 | [5, 6, 5, 6, 6, 5, 3, 3]
|
| 1600 | DECAP: Decoding CLIP Latents for Zero-shot Captioning | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6, 6, 5]
|
| 1601 | Heterogeneous Loss Function with Aggressive Rejection for Contaminated data in anomaly detection | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 1602 | Biological Factor Regulatory Neural Network | 4.25 | 4.25 | 0.00 | [5, 3, 6, 3]
|
| 1603 | Preserving Semantics in Textual Adversarial Attacks | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 1604 | Unbiased Decisions Reduce Regret: Adversarial Optimism for the Bank Loan Problem | 4.67 | 5.33 | 0.67 | [6, 5, 5]
|
| 1605 | That Label"s got Style: Handling Label Style Bias for Uncertain Image Segmentation | 6.33 | 6.67 | 0.33 | [6, 8, 6]
|
| 1606 | Prompt Injection: Parameterization of Fixed Inputs | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 1607 | Holistic Adversarially Robust Pruning | 5.00 | 5.75 | 0.75 | [6, 3, 6, 8]
|
| 1608 | PASHA: Efficient HPO and NAS with Progressive Resource Allocation | 5.40 | 5.40 | 0.00 | [5, 3, 6, 5, 8]
|
| 1609 | Thinking fourth dimensionally: Treating Time as a Random Variable in EBMs | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 1610 | Diversity of Generated Unlabeled Data Matters for Few-shot Hypothesis Adaptation | 4.67 | 4.67 | 0.00 | [3, 8, 3]
|
| 1611 | StableDR: Stabilized Doubly Robust Learning for Recommendation on Data Missing Not at Random | 6.33 | 7.00 | 0.67 | [8, 5, 8]
|
| 1612 | Hybrid-Regressive Neural Machine Translation | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 1613 | Variational Causal Dynamics: Discovering Modular World Models from Interventions | 4.60 | 4.60 | 0.00 | [5, 3, 6, 3, 6]
|
| 1614 | Query The Agent: Improving Sample Efficiency Through Epistemic Uncertainty Estimation | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 1615 | Differentiable Logic Programming for Probabilistic Reasoning | 4.25 | 4.25 | 0.00 | [3, 5, 3, 6]
|
| 1616 | Rewiring with Positional Encodings for GNNs | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 1617 | Automatic Dictionary Generation: Could Brothers Grimm Create a Dictionary with BERT? | 2.50 | 2.50 | 0.00 | [3, 3, 3, 1]
|
| 1618 | Feed-Forward Latent Domain Adaptation | 4.60 | 4.60 | 0.00 | [8, 6, 3, 3, 3]
|
| 1619 | Sampling-based inference for large linear models, with application to linearised Laplace | 7.00 | 7.50 | 0.50 | [6, 8, 8, 8]
|
| 1620 | Defending against Adversarial Audio via Diffusion Model | 6.00 | 6.00 | 0.00 | [5, 8, 5, 6]
|
| 1621 | Text-Guided Diffusion Image Style Transfer with Contrastive Loss Fine-tuning | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 1622 | FedProp: Cross-client Label Propagation for Federated Semi-supervised Learning | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1623 | Test-Time Adaptation for Real-World Denoising Networks via Noise-Aware Image Generation | 4.25 | 4.25 | 0.00 | [3, 5, 3, 6]
|
| 1624 | Gated Inference Network: Inferencing and Learning State-Space Models | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 1625 | Theoretical Characterization of the Generalization Performance of Overfitted Meta-Learning | 6.00 | 6.00 | 0.00 | [6, 5, 8, 5]
|
| 1626 | Cold Posteriors through PAC-Bayes | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 1627 | Learning 3D Point Cloud Embeddings using Optimal Transport | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 1628 | Training language models for deeper understanding improves brain alignment | 6.50 | 6.50 | 0.00 | [8, 5, 8, 5]
|
| 1629 | DeNF: Unsupervised Scene-Decompositional Normalizing Flows | 3.80 | 3.80 | 0.00 | [3, 5, 3, 3, 5]
|
| 1630 | VQ-TR: Vector Quantized Attention for Time Series Forecasting | 3.75 | 3.75 | 0.00 | [1, 6, 3, 5]
|
| 1631 | Local KL Convergence Rate for Stein Variational Gradient Descent with Reweighted Kernel | 5.67 | 5.67 | 0.00 | [3, 6, 8]
|
| 1632 | A Decomposition Based Dual Projection Model for Multivariate Time Series Forecasting and Anomaly Detection | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 1633 | LEXA: Language-agnostic Cross-consistency Training for Question Answering Tasks | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 1634 | FedHPO-Bench: A Benchmark Suite for Federated Hyperparameter Optimization | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 1635 | CCT: Cross-consistency training for Clone Detection and Code Search Tasks | 3.00 | 3.00 | 0.00 | [1, 3, 3, 5]
|
| 1636 | Robust Explanation Constraints for Neural Networks | 5.50 | 5.75 | 0.25 | [8, 6, 6, 3]
|
| 1637 | Cyclophobic Reinforcement Learning | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1638 | Emergent collective intelligence from massive-agent cooperation and competition | 3.75 | 3.75 | 0.00 | [1, 5, 6, 3]
|
| 1639 | Offline Reinforcement Learning via High-Fidelity Generative Behavior Modeling | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 1640 | GraphVF: Controllable Protein-Specific 3D Molecule Generation with Variational Flow | 3.00 | 2.50 | -0.50 | [3, 1, 3, 3]
|
| 1641 | Graph Neural Networks as Gradient Flows: understanding graph convolutions via energy | 4.25 | 4.25 | 0.00 | [5, 3, 3, 6]
|
| 1642 | CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers | 5.60 | 5.60 | 0.00 | [6, 5, 8, 3, 6]
|
| 1643 | Revisit Finetuning strategy for Few-Shot Learning to Strengthen the Equivariance of Emdeddings | 5.20 | 5.20 | 0.00 | [5, 3, 6, 6, 6]
|
| 1644 | Memory Learning of Multivariate Asynchronous Time Series | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 1645 | Scalable Multi-Modal Continual Meta-Learning | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 1646 | Optimizing Spca-based Continual Learning: A Theoretical Approach | 4.00 | 7.00 | 3.00 | [6, 8, 8, 6]
|
| 1647 | Value Memory Graph: A Graph-Structured World Model for Offline Reinforcement Learning | 6.25 | 6.25 | 0.00 | [5, 6, 8, 6]
|
| 1648 | CAKE: CAusal and collaborative proxy-tasKs lEarning for Semi-Supervised Domain Adaptation | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 1649 | RulE: Neural-Symbolic Knowledge Graph Reasoning with Rule Embedding | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 1650 | Sampling-free Inference for Ab-Initio Potential Energy Surface Networks | 6.50 | 6.75 | 0.25 | [5, 6, 8, 8]
|
| 1651 | PET-NeuS: Positional Encoding Triplanes for Neural Surfaces | 4.75 | 4.75 | 0.00 | [3, 3, 8, 5]
|
| 1652 | Hidden Schema Networks | 5.50 | 5.50 | 0.00 | [8, 8, 3, 3]
|
| 1653 | A New Hierarchy of Expressivity for Graph Neural Networks | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 1654 | Learning Input-agnostic Manipulation Directions in StyleGAN with Text Guidance | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 1655 | Learning Task Agnostic Temporal Consistency Correction | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 1656 | Does Structural Information have been Fully Exploited in Graph Data? | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1657 | Prescribed Safety Performance Imitation Learning from A Single Expert Dataset | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 1658 | End-to-end Invariance Learning with Relational Inductive Biases in Multi-Object Robotic Manipulation | 4.40 | 4.40 | 0.00 | [3, 3, 5, 6, 5]
|
| 1659 | DAVA: Disentangling Adversarial Variational Autoencoder | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 1660 | Comparing Auxiliary Tasks for Learning Representations for Reinforcement Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1661 | TDR-CL: Targeted Doubly Robust Collaborative Learning for Debiased Recommendations | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 1662 | Dynamic-Aware GANs: Time-Series Generation with Handy Self-Supervision | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 1663 | Learning Gradient-based Mixup towards Flatter Minima for Domain Generalization | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 1664 | DeepGRAND: Deep Graph Neural Diffusion | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 1665 | Learning Discrete Representation with Optimal Transport Quantized Autoencoders | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 1666 | How to Keep Cool While Training | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 1667 | Learning System Dynamics from Sensory Input under Optimal Control Principles | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 1668 | Dual Algorithmic Reasoning | 7.00 | 8.00 | 1.00 | [8, 8, 8]
|
| 1669 | Lmser-pix2seq: Learning Stable Sketch Representations For Sketch Healing | 5.25 | 5.25 | 0.00 | [3, 5, 5, 8]
|
| 1670 | UnifySpeech: A Unified Framework for Zero-shot Text-to-Speech and Voice Conversion | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1671 | Toward Effective Deep Reinforcement Learning for 3D Robotic Manipulation: End-to-End Learning from Multimodal Raw Sensory Data | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 1672 | Domain Generalisation via Domain Adaptation: An Adversarial Fourier Amplitude Approach | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 1673 | Improving Generative Flow Networks with Path Regularization | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 1674 | On the Shortcut Learning in Multilingual Neural Machine Translation | 3.67 | 3.50 | -0.17 | [3, 5, 3, 3]
|
| 1675 | Confidential-PROFITT: Confidential PROof of FaIr Training of Trees | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 1676 | Consolidator: Mergable Adapter with Group Connections for Vision Transformer | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 1677 | Statistical Theory of Differentially Private Marginal-based Data Synthesis Algorithms | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 1678 | Homotopy-based training of NeuralODEs for accurate dynamics discovery | 4.40 | 4.40 | 0.00 | [5, 6, 3, 5, 3]
|
| 1679 | Transformers with Multiresolution Attention Heads | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 1680 | Anti-Symmetric DGN: a stable architecture for Deep Graph Networks | 5.50 | 5.50 | 0.00 | [8, 6, 3, 5]
|
| 1681 | Contrastive Learning for Unsupervised Domain Adaptation of Time Series | 6.25 | 6.25 | 0.00 | [6, 3, 8, 8]
|
| 1682 | Model-Based Decentralized Policy Optimization | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 1683 | CLIP model is an Efficient Continual Learner | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 1684 | Online Low Rank Matrix Completion | 5.33 | 7.33 | 2.00 | [8, 8, 6]
|
| 1685 | Modality Complementariness: Towards Understanding Multi-modal Robustness | 5.00 | 5.00 | 0.00 | [8, 3, 3, 6]
|
| 1686 | Effective Offline Reinforcement Learning via Conservative State Value Estimation | 4.75 | 4.75 | 0.00 | [3, 5, 3, 8]
|
| 1687 | ChemAlgebra : Algebraic Reasoning on Chemical Reactions | 4.50 | 4.80 | 0.30 | [6, 6, 3, 3, 6]
|
| 1688 | A Primal-Dual Framework for Transformers and Neural Networks | 5.75 | 5.80 | 0.05 | [6, 8, 6, 3, 6]
|
| 1689 | Explaining RL Decisions with Trajectories | 5.25 | 5.50 | 0.25 | [5, 6, 5, 6]
|
| 1690 | Reinforcement Learning using a Molecular Fragment Based Approach for Reaction Discovery | 4.00 | 4.00 | 0.00 | [5, 6, 3, 3, 3]
|
| 1691 | Keypoint Matching via Random Network Consensus | 5.33 | 5.33 | 0.00 | [8, 5, 3]
|
| 1692 | Visually-augmented pretrained language models for NLP Tasks without Images | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 1693 | Calibration for Decision Making via Empirical Risk Minimization | 4.25 | 4.25 | 0.00 | [6, 3, 3, 5]
|
| 1694 | Improving Adversarial Robustness via Frequency Regularization | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 1695 | I Speak, You Verify: Toward Trustworthy Neural Program Synthesis | 3.67 | 3.67 | 0.00 | [5, 1, 5]
|
| 1696 | FastFill: Efficient Compatible Model Update | 5.50 | 5.50 | 0.00 | [8, 5, 6, 3]
|
| 1697 | Learnable Graph Convolutional Attention Networks | 6.33 | 6.67 | 0.33 | [8, 6, 6]
|
| 1698 | Indoor Localisation for Detecting Medication Use in Parkinson"s Disease | 2.50 | 2.50 | 0.00 | [3, 3, 3, 1]
|
| 1699 | Scaffolding a Student to Instill Knowledge | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 1700 | User-Interactive Offline Reinforcement Learning | 6.75 | 6.75 | 0.00 | [10, 6, 3, 8]
|
| 1701 | No-regret Learning in Repeated First-Price Auctions with Budget Constraints | 5.00 | 5.00 | 0.00 | [8, 3, 6, 5, 5, 3]
|
| 1702 | Server Aggregation as Linear Regression: Reformulation for Federated Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1703 | Private and Efficient Meta-Learning with Low Rank and Sparse decomposition | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 1704 | $\omega$GNNs: Deep Graph Neural Networks Enhanced by Multiple Propagation Operators | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 1705 | Few-bit Backward: Quantized Gradients of Activation Functions for Memory Footprint Reduction | 4.67 | 5.00 | 0.33 | [3, 6, 6]
|
| 1706 | SLTUNET: A Simple Unified Model for Sign Language Translation | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 1707 | Pruning by Active Attention Manipulation | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 1708 | Robustness of Unsupervised Representation Learning without Labels | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 1709 | Understanding the Generalization of Adam in Learning Neural Networks with Proper Regularization | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 1710 | ACQL: An Adaptive Conservative Q-Learning Framework for Offline Reinforcement Learning | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 1711 | Fisher-Legendre (FishLeg) optimization of deep neural networks | 6.25 | 6.25 | 0.00 | [6, 8, 5, 6]
|
| 1712 | A law of adversarial risk, interpolation, and label noise | 6.25 | 6.38 | 0.12 | [6, 6, 5, 6, 6, 6, 8, 8]
|
| 1713 | Lossy Image Compression with Conditional Diffusion Models | 5.20 | 5.20 | 0.00 | [5, 5, 6, 5, 5]
|
| 1714 | Invariance Makes a Difference: Disentangling the Role of Invariance and Equivariance in Representations | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 1715 | Improving the generalization ability of the chaotic time-series classification models by residual component extraction | 3.50 | 3.50 | 0.00 | [5, 3, 1, 5]
|
| 1716 | Learning DAGs from Fourier-Sparse Data | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 1717 | ASIF: coupled data turns unimodal models to multimodal without training | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1718 | Momentum Boosted Episodic Memory for Improving Learning in Long-Tailed RL Environments | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 1719 | ProtoGNN: Prototype-Assisted Message Passing Framework for Non-Homophilous Graphs | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 1720 | MonoFlow: A Unified Generative Modeling Framework for GAN Variants | 5.67 | 5.67 | 0.00 | [6, 8, 3]
|
| 1721 | The Effective coalitions of Shapley value For Integrated Gradients | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1722 | Cold Rao-Blackwellized Straight-Through Gumbel-Softmax Gradient Estimator | 4.75 | 5.00 | 0.25 | [6, 3, 6, 5]
|
| 1723 | Generative Spoken Language Model based on continuous word-sized audio tokens | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 1724 | Tree-structure segmentation for logistic regression | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1725 | Neural Image Compression with a Diffusion-based Decoder | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 1726 | Learning ReLU networks to high uniform accuracy is intractable | 6.17 | 6.17 | 0.00 | [6, 8, 6, 3, 6, 8]
|
| 1727 | GAML: geometry-aware meta-learning via a fully adaptive preconditioner | 3.75 | 3.75 | 0.00 | [5, 3, 1, 6]
|
| 1728 | Caption supervision enables robust learners: a controlled study of distributionally robust model training | 3.75 | 4.00 | 0.25 | [5, 3, 5, 1, 6]
|
| 1729 | Active Learning for Object Detection with Evidential Deep Learning and Hierarchical Uncertainty Aggregation | 5.20 | 5.20 | 0.00 | [5, 6, 6, 3, 6]
|
| 1730 | How Sharpness-Aware Minimization Minimizes Sharpness? | 6.33 | 6.33 | 0.00 | [6, 8, 5]
|
| 1731 | Learning to solve the Hidden Clique Problem with Graph Neural Networks | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1732 | On discrete symmetries of robotics systems: A group-theoretic and data-driven analysis | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 1733 | The Implicit Bias of Minima Stability in Multivariate Shallow ReLU Networks | 6.67 | 7.00 | 0.33 | [8, 6, 8, 6]
|
| 1734 | Out-of-Domain Intent Detection Considering Multi-turn Dialogue Contexts | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 1735 | Consciousness-Aware Multi-Agent Reinforcement Learning | 3.50 | 3.50 | 0.00 | [5, 3, 5, 1]
|
| 1736 | Better with Less: Data-Active Pre-training of Graph Neural Networks | 5.00 | 5.00 | 0.00 | [3, 8, 6, 3]
|
| 1737 | MAST: Masked Augmentation Subspace Training for Generalizable Self-Supervised Priors | 5.75 | 5.75 | 0.00 | [6, 3, 6, 8]
|
| 1738 | Pseudo-Edge: Semi-Supervised Link Prediction with Graph Neural Networks | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 1739 | Graph-based Deterministic Policy Gradient for Repetitive Combinatorial Optimization Problems | 5.67 | 5.67 | 0.00 | [3, 8, 6]
|
| 1740 | Lower Bounds on the Depth of Integral ReLU Neural Networks via Lattice Polytopes | 6.75 | 6.75 | 0.00 | [8, 5, 6, 8]
|
| 1741 | Contextual Transformer for Offline Reinforcement Learning | 4.25 | 4.25 | 0.00 | [6, 3, 3, 5]
|
| 1742 | Two-Dimensional Weisfeiler-Lehman Graph Neural Networks for Link Prediction | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 1743 | Wasserstein Auto-encoded MDPs: Formal Verification of Efficiently Distilled RL Policies with Many-sided Guarantees | 6.50 | 6.50 | 0.00 | [8, 8, 5, 5]
|
| 1744 | Efficient Controllable Generation with Guarantee | 3.67 | 3.67 | 0.00 | [5, 1, 5]
|
| 1745 | Towards graph-level anomaly detection via deep evolutionary mapping | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 1746 | Global Explainability of GNNs via Logic Combination of Learned Concepts | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 1747 | Pessimistic Policy Iteration for Offline Reinforcement Learning | 4.00 | 4.00 | 0.00 | [5, 3, 3, 6, 3]
|
| 1748 | BO-Muse: A Human expert and AI teaming framework for accelerated experimental design | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 1749 | Coordination Scheme Probing for Generalizable Multi-Agent Reinforcement Learning | 5.67 | 5.50 | -0.17 | [5, 6, 8, 3]
|
| 1750 | Generalization error bounds for Neural Networks with ReLU activation | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 1751 | Two Birds, One Stone: An Equivalent Transformation for Hyper-relational Knowledge Graph Modeling | 5.25 | 5.25 | 0.00 | [5, 5, 3, 8]
|
| 1752 | Gradient Gating for Deep Multi-Rate Learning on Graphs | 4.80 | 4.80 | 0.00 | [5, 6, 5, 3, 5]
|
| 1753 | Self-Supervised Extreme Compression of Gigapixel Images | 4.80 | 4.80 | 0.00 | [5, 3, 6, 5, 5]
|
| 1754 | Combating noisy labels with stochastic noise-tolerated supervised contrastive learning | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5, 5]
|
| 1755 | MAESTRO: Open-Ended Environment Design for Multi-Agent Reinforcement Learning | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 1756 | Capturing the Motion of Every Joint: 3D Human Pose and Shape Estimation with Independent Tokens | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 1757 | Almost Linear Constant-Factor Sketching for $\ell_1$ and Logistic Regression | 7.00 | 7.00 | 0.00 | [5, 8, 8]
|
| 1758 | Neural-based classification rule learning for sequential data | 5.67 | 6.67 | 1.00 | [8, 6, 6]
|
| 1759 | Q-learning Decision Transformer: Leveraging Dynamic Programming for Conditional Sequence Modelling in Offline RL | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 1760 | $\epsilon$-Invariant Hierarchical Reinforcement Learning for Building Generalizable Policy | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 1761 | Learning Control by Iterative Inversion | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 1762 | DetectBench: An Object Detection Benchmark for OOD Generalization Algorithms | 5.50 | 5.50 | 0.00 | [6, 8, 3, 5]
|
| 1763 | Generalization Bounds with Arbitrary Complexity Measures | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 1764 | Graphics Capsule: Learning hierarchical 3D representations from 2D images and its application on human faces | 5.00 | 5.00 | 0.00 | [3, 5, 6, 5, 6, 5]
|
| 1765 | Weak Supervision Variational Auto-Encoder | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 1766 | Object Detection with OOD Generalizable Neural Architecture Search | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1767 | Learning To Invert: Simple Adaptive Attacks for Gradient Inversion in Federated Learning | 4.40 | 4.40 | 0.00 | [3, 5, 3, 6, 5]
|
| 1768 | Leveraging Unlabeled Data to Track Memorization | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 1769 | CCIL: Context-conditioned imitation learning for urban driving | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 1770 | Improving Continual Learning by Accurate Gradient Reconstructions of the Past | 4.25 | 4.25 | 0.00 | [3, 5, 3, 6]
|
| 1771 | Revisiting Dense Retrieval with Unaswerable Counterfactuals | 6.25 | 6.25 | 0.00 | [5, 6, 6, 8]
|
| 1772 | Group-wise Verifiable Distributed Computing for Machine Learning under Adversarial Attacks | 5.00 | 5.00 | 0.00 | [3, 8, 3, 6]
|
| 1773 | Extending graph transformers with quantum computed aggregation | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 1774 | Policy-Based Self-Competition for Planning Problems | 5.33 | 7.00 | 1.67 | [8, 5, 8]
|
| 1775 | Can Fair Federated Learning reduce the need for personalization? | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 1776 | Efficient Out-of-Distribution Detection based on In-Distribution Data Patterns Memorization with Modern Hopfield Energy | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 1777 | Conditional Policy Similarity: An Overlooked Factor in Zero-Shot Coordination | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 1778 | Pareto-Efficient Decision Agents for Offline Multi-Objective Reinforcement Learning | 6.25 | 6.25 | 0.00 | [6, 6, 5, 8]
|
| 1779 | Learning from Asymmetrically-corrupted Data in Regression for Sensor Magnitude | 4.50 | 4.50 | 0.00 | [5, 6, 1, 6]
|
| 1780 | NAGphormer: A Tokenized Graph Transformer for Node Classification in Large Graphs | 5.50 | 6.00 | 0.50 | [5, 8, 5, 6]
|
| 1781 | Bayesian Oracle for bounding information gain in neural encoding models | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 1782 | Near Optimal Private and Robust Linear Regression | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 1783 | From Distance to Dependency: A Paradigm Shift of Full-reference Image Quality Assessment | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 1784 | Inverse Learning with Extremely Sparse Feedback for Recommendation | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 1785 | Instance-Specific Augmentation: Capturing Local Invariances | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 1786 | Spectral Subgraph Localization | 7.00 | 7.00 | 0.00 | [5, 8, 8]
|
| 1787 | Dynamical Signatures of Learning in Recurrent Networks | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 1788 | Shifts 2.0: Extending The Dataset of Real Distributional Shifts | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 1789 | $\Lambda$-DARTS: Mitigating Performance Collapse by Harmonizing Operation Selection among Cells | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 1790 | Prototypical Context-aware Dynamics Generalization for High-dimensional Model-based Reinforcement Learning | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 1791 | Efficient Hyperparameter Optimization Through Tensor Completion | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 1792 | Learning Vortex Dynamics for Fluid Inference and Prediction | 6.75 | 6.75 | 0.00 | [6, 8, 8, 5]
|
| 1793 | Self-Supervised SVDE from Videos with Depth Variance to Shifted Positional Information | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1794 | Discovering Generalizable Multi-agent Coordination Skills from Multi-task Offline Data | 6.75 | 6.75 | 0.00 | [8, 6, 5, 8]
|
| 1795 | MATA*: Combining Learnable Node Matching with A* Algorithm for Approximate Graph Edit Distance Computation | 4.20 | 4.20 | 0.00 | [5, 3, 5, 5, 3]
|
| 1796 | On student-teacher deviations in distillation: does it pay to disobey? | 5.25 | 5.25 | 0.00 | [3, 5, 8, 5]
|
| 1797 | Quantum Vision Transformers | 5.75 | 5.75 | 0.00 | [5, 3, 10, 5]
|
| 1798 | Merging Models Pre-Trained on Different Features with Consensus Graph | 5.25 | 5.25 | 0.00 | [3, 8, 5, 5]
|
| 1799 | Unsupervised Performance Predictor for Architecture Search | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 1800 | Efficient recurrent architectures through activity sparsity and sparse back-propagation through time | 7.33 | 7.33 | 0.00 | [8, 8, 6]
|
| 1801 | Quality-Similar Diversity via Population Based Reinforcement Learning | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 1802 | PREDICTION OF TOURISM FLOW WITH SPARSE DATA INCORPORATING TOURIST GEOLOCATIONS | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1803 | Uncertainty-oriented Order Learning for Facial Beauty Prediction | 5.00 | 5.00 | 0.00 | [6, 6, 5, 3]
|
| 1804 | Modeling the Uncertainty with Maximum Discrepant Students for Semi-supervised 2D Pose Estimation | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 1805 | UTS: When Monotonic Value Factorisation Meets Non-monotonic and Stochastic Targets | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 1806 | TransLog: A Unified Transformer-based Framework for Log Anomaly Detection | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1807 | Meta-learning with Auto-generated Tasks for Predicting Human Behaviour in Normal Form Games | 3.67 | 3.00 | -0.67 | [1, 3, 3, 5]
|
| 1808 | Are Graph Attention Networks Attentive Enough? Rethinking Graph Attention by Capturing Homophily and Heterophily | 3.33 | 3.33 | 0.00 | [1, 6, 3]
|
| 1809 | FairGrad: Fairness Aware Gradient Descent | 4.25 | 4.75 | 0.50 | [5, 3, 6, 5]
|
| 1810 | Better Teacher Better Student: Dynamic Prior Knowledge for Knowledge Distillation | 6.00 | 6.00 | 0.00 | [5, 5, 8]
|
| 1811 | Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 1812 | Inequality phenomenon in $l_{\infty}$-adversarial training, and its unrealized threats | 6.00 | 7.25 | 1.25 | [8, 5, 8, 8]
|
| 1813 | Tensor-Based Sketching Method for the Low-Rank Approximation of Data Streams. | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 1814 | CRISP: Curriculum based Sequential neural decoders for Polar code family | 6.25 | 6.25 | 0.00 | [8, 6, 6, 5]
|
| 1815 | A Mathematical Framework for Characterizing Dependency Structures of Multimodal Learning | 4.25 | 4.25 | 0.00 | [5, 5, 1, 6]
|
| 1816 | Language Models are Realistic Tabular Data Generators | 6.25 | 6.75 | 0.50 | [5, 6, 8, 8]
|
| 1817 | Data augmentation alone can improve adversarial training | 5.50 | 5.75 | 0.25 | [6, 6, 6, 5]
|
| 1818 | Learning Rotation-Equivariant Features for Visual Correspondence | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 1819 | Learning Diffusion Bridges on Constrained Domains | 6.25 | 6.75 | 0.50 | [6, 6, 5, 10]
|
| 1820 | Revisiting Uncertainty Estimation for Node Classification: New Benchmark and Insights | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 1821 | CUTS: Neural Causal Discovery from Unstructured Time-Series Data | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 1822 | Multi-Source Transfer Learning for Deep Model-Based Reinforcement Learning | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1823 | Balancing MSE against Abrupt Changes for Time-Series Forecasting | 4.00 | 4.00 | 0.00 | [3, 3, 3, 5, 6]
|
| 1824 | PAVI: Plate-Amortized Variational Inference | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 1825 | Near-optimal Coresets for Robust Clustering | 7.50 | 7.50 | 0.00 | [6, 8, 8, 8]
|
| 1826 | CLUTR: Curriculum Learning via Unsupervised Task Representation Learning | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 1827 | Test-time Adaptation for Segmentation via Image Synthesis | 4.60 | 4.60 | 0.00 | [5, 3, 6, 6, 3]
|
| 1828 | On the Importance of In-distribution Class Prior for Out-of-distribution Detection | 5.25 | 5.25 | 0.00 | [6, 6, 3, 6]
|
| 1829 | Quantized Compressed Sensing with Score-Based Generative Models | 6.33 | 6.33 | 0.00 | [6, 8, 5]
|
| 1830 | Unbiased Representation of Electronic Health Records for Patient Outcome Prediction | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 1831 | Valid P-Value for Deep Learning-driven Salient Region | 5.50 | 5.60 | 0.10 | [6, 6, 5, 6, 5]
|
| 1832 | Unsupervised Semantic Segmentation with Self-supervised Object-centric Representations | 6.75 | 6.75 | 0.00 | [8, 6, 8, 5]
|
| 1833 | Skill Graph for Real-world Quadrupedal Robot Reinforcement Learning | 2.50 | 2.50 | 0.00 | [3, 1, 3, 3]
|
| 1834 | Pre-training Protein Structure Encoder via Siamese Diffusion Trajectory Prediction | 5.75 | 5.75 | 0.00 | [5, 5, 8, 5]
|
| 1835 | Indiscriminate Poisoning Attacks on Unsupervised Contrastive Learning | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 1836 | Decompositional Generation Process for Instance-Dependent Partial Label Learning | 6.75 | 6.75 | 0.00 | [8, 8, 8, 3]
|
| 1837 | Multimodal Masked Autoencoders Learn Transferable Representations | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 1838 | Adversarial Causal Augmentation for Graph Covariate Shift | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 1839 | Learning from conflicting data with hidden contexts | 5.50 | 5.50 | 0.00 | [3, 8, 8, 3]
|
| 1840 | Building a Subspace of Policies for Scalable Continual Learning | 6.75 | 7.20 | 0.45 | [6, 6, 8, 8, 8]
|
| 1841 | Test-Time AutoEval with Supporting Self-supervision | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 1842 | Complexity-Based Prompting for Multi-step Reasoning | 6.00 | 6.00 | 0.00 | [8, 3, 5, 8]
|
| 1843 | ECLAD: Extracting Concepts with Local Aggregated Descriptors | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 1844 | Not All Tasks Are Born Equal: Understanding Zero-Shot Generalization | 6.00 | 6.00 | 0.00 | [8, 5, 5, 6]
|
| 1845 | MA2QL: A Minimalist Approach to Fully Decentralized Multi-Agent Reinforcement Learning | 4.00 | 3.75 | -0.25 | [3, 6, 3, 3]
|
| 1846 | Learning Asymmetric Visual Semantic Embedding for Image-Text Retrieval | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 1847 | Representation Interference Suppression via Non-linear Value Factorization for Indecomposable Markov Games | 3.25 | 3.25 | 0.00 | [1, 6, 5, 1]
|
| 1848 | On Threshold Functions in Learning to Generate Feasible Solutions of Mixed Integer Programs | 4.67 | 4.67 | 0.00 | [8, 3, 3]
|
| 1849 | SDAC: Efficient Safe Reinforcement Learning with Low-Biased Distributional Actor-Critic | 4.75 | 5.00 | 0.25 | [6, 5, 3, 6]
|
| 1850 | So-TVAE: Sentiment-oriented Transformer-based Variational Autoencoder Network for Live Video Commenting | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 1851 | SoTeacher: Toward Student-oriented Teacher Network Training for Knowledge Distillation | 5.00 | 5.00 | 0.00 | [3, 6, 6, 5]
|
| 1852 | GuardHFL: Privacy Guardian for Heterogeneous Federated Learning | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 1853 | Class-wise Visual Explanations for Deep Neural Networks | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 1854 | Decentralized Policy Optimization | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1855 | Identification of the Adversary from a Single Adversarial Example | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 1856 | Similarity of Neural Architectures Based on Input Gradient Transferability | 4.60 | 4.60 | 0.00 | [8, 6, 1, 3, 5]
|
| 1857 | Image Segmentation using Transfer Learning with DeepLabv3 to Facilitate Photogrammetric Limb Scanning | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1858 | G-Censor: Graph Contrastive Learning with Task-Oriented Counterfactual Views | 3.80 | 3.80 | 0.00 | [3, 3, 5, 5, 3]
|
| 1859 | Unsupervised 3d object learning through neuron activity aware plasticity | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 1860 | Visually-Augmented Language Modeling | 6.75 | 6.75 | 0.00 | [6, 10, 5, 6]
|
| 1861 | A HIERARCHICAL FRAGMENT-BASED MODEL FOR 3D DRUG-LIKE MOLECULE GENERATION | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 1862 | Multi-Layered 3D Garments Animation | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 1863 | Preventing Mode Collapse When Imitating Latent Policies from Observations | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 1864 | Unsupervised Learning of Structured Representations via Closed-Loop Transcription | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 1865 | DETRDistill: A Simple Knowledge Distillation Framework for DETR-Families | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 1866 | Closed Boundary Learning for NLP Classification Tasks with the Universum Class | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 1867 | Solving Constrained Variational Inequalities via a First-order Interior Point-based Method | 6.50 | 6.50 | 0.00 | [6, 8, 6, 6]
|
| 1868 | MeGraph: Graph Representation Learning on Connected Multi-scale Graphs | 5.50 | 5.50 | 0.00 | [3, 8, 8, 3]
|
| 1869 | Learning Reduced Fluid Dynamics | 5.33 | 5.33 | 0.00 | [8, 5, 3]
|
| 1870 | Symmetric Pruning in Quantum Neural Networks | 7.33 | 8.00 | 0.67 | [8, 8, 8]
|
| 1871 | Managing Temporal Resolution in Continuous Value Estimation: A Fundamental Trade-off | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 1872 | On the Robustness of Randomized Ensembles to Adversarial Perturbations | 4.50 | 4.50 | 0.00 | [3, 3, 6, 6]
|
| 1873 | Minimum Variance Unbiased N:M Sparsity for the Neural Gradients | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 1874 | Incremental Learning of Structured Memory via Closed-Loop Transcription | 7.33 | 7.33 | 0.00 | [8, 6, 8]
|
| 1875 | Curved Data Representations in Deep Learning | 5.25 | 5.25 | 0.00 | [3, 5, 5, 8]
|
| 1876 | When Data Geometry Meets Deep Function: Generalizing Offline Reinforcement Learning | 5.00 | 5.00 | 0.00 | [3, 5, 6, 6]
|
| 1877 | Self-supervised debiasing using low rank regularization | 5.50 | 5.50 | 0.00 | [8, 5, 6, 3]
|
| 1878 | Wasserstein Gradient Flows for Optimizing GMM-based Policies | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 1879 | Compositional Image Generation and Manipulation with Latent Diffusion Models | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 1880 | Neural Unbalanced Optimal Transport via Cycle-Consistent Semi-Couplings | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 1881 | Prompt Tuning for Graph Neural Networks | 4.75 | 4.75 | 0.00 | [3, 5, 3, 8]
|
| 1882 | Budgeted Training for Vision Transformer | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 1883 | Knowledge-in-Context: Towards Knowledgeable Semi-Parametric Language Models | 6.25 | 6.25 | 0.00 | [5, 6, 8, 6]
|
| 1884 | Understanding and Mitigating Robust Overfitting through the Lens of Feature Dynamics | 5.20 | 5.20 | 0.00 | [5, 6, 3, 6, 6]
|
| 1885 | Augmentative Topology Agents For Open-Ended Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1886 | Partial Differential Equation-Regularized Neural Networks: An Application to Image Classification | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 1887 | Learning to Boost Resilience of Complex Networks via Neural Edge Rewiring | 4.75 | 4.75 | 0.00 | [3, 5, 3, 8]
|
| 1888 | Deep Transformer Q-Networks for Partially Observable Reinforcement Learning | 4.50 | 4.50 | 0.00 | [1, 5, 6, 6]
|
| 1889 | Mind"s Eye: Grounded Language Model Reasoning through Simulation | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 1890 | Visual Expertise and the Log-Polar Transform Explain Image Inversion Effects | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 1891 | Cross-Protein Wasserstein Transformer for Protein-Protein Interactions | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 1892 | What Do Self-Supervised Vision Transformers Learn? | 6.00 | 6.00 | 0.00 | [8, 8, 3, 5]
|
| 1893 | Continuous Monte Carlo Graph Search | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1894 | Confident Sinkhorn Allocation for Pseudo-Labeling | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 1895 | Rank-1 Matrix Completion with Gradient Descent and Small Random Initialization | 3.25 | 3.25 | 0.00 | [3, 6, 3, 1]
|
| 1896 | Adversarial Robustness based on Randomized Smoothing in Quantum Machine Learning | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 1897 | Multi-Vector Retrieval as Sparse Alignment | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 1898 | Sampled Transformer for Point Sets | 6.00 | 6.00 | 0.00 | [6, 8, 5, 5]
|
| 1899 | Scaling Laws in Mean-Field Games | 5.75 | 5.75 | 0.00 | [8, 3, 6, 6]
|
| 1900 | PartAfford: Part-level Affordance Discovery | 6.25 | 6.25 | 0.00 | [8, 8, 6, 3]
|
| 1901 | On The Relative Error of Random Fourier Features for Preserving Kernel Distance | 6.33 | 6.33 | 0.00 | [3, 8, 8]
|
| 1902 | UTC-IE: A Unified Token-pair Classification Architecture for Information Extraction | 5.33 | 5.33 | 0.00 | [8, 5, 3]
|
| 1903 | Robust Quantity-Aware Aggregation for Federated Learning | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1904 | Efficient debiasing with contrastive weight pruning | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 1905 | Linear Convergence of Decentralized FedAvg for Non-Convex Objectives: The Interpolation Regime | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 1906 | Rethinking Missing Modality Learning: From a Decoding View | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 1907 | Global Nash Equilibrium in a Class of Nonconvex N-player Games | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 1908 | UNDERSTANDING PURE CLIP GUIDANCE FOR VOXEL GRID NERF MODELS | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 1909 | Neural Semi-Counterfactual Risk Minimization | 4.50 | 4.50 | 0.00 | [1, 3, 6, 8]
|
| 1910 | Task-Agnostic Online Meta-Learning in Non-stationary Environments | 5.00 | 5.00 | 0.00 | [6, 6, 3, 5, 5]
|
| 1911 | Meta-Weighted Language Model Tuning for Augmentation-Enhanced Few-Shot Learning | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 1912 | Online Reinforcement Learning via Posterior Sampling of Policy | 2.00 | 2.00 | 0.00 | [3, 3, 1, 1]
|
| 1913 | NewModel: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing | 6.25 | 6.25 | 0.00 | [5, 6, 8, 6]
|
| 1914 | Weakly Supervised Neuro-Symbolic Image Manipulation via Multi-Hop Complex Instructions | 6.33 | 6.33 | 0.00 | [8, 5, 6]
|
| 1915 | Graph Neural Networks for Aerodynamic Flow Reconstruction from Sparse Sensing | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 1916 | Learning Binary Networks on Long-Tailed Distributions | 5.25 | 5.25 | 0.00 | [3, 5, 5, 8]
|
| 1917 | Backdoor Mitigation by Correcting Activation Distribution Alteration | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 1918 | Pose Transfer using a Single Spatial Transformation | 3.67 | 3.67 | 0.00 | [5, 1, 5]
|
| 1919 | Local Distance Preserving Auto-encoders using Continuous k-Nearest Neighbours Graphs | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 1920 | Clustering for directed graphs using parametrized random walk diffusion kernels | 5.75 | 5.75 | 0.00 | [6, 6, 6, 5]
|
| 1921 | Poisoning Generative Models to Promote Catastrophic Forgetting | 4.25 | 4.25 | 0.00 | [3, 3, 5, 6]
|
| 1922 | Squeeze Training for Adversarial Robustness | 6.00 | 6.50 | 0.50 | [6, 8, 6, 6]
|
| 1923 | Concealing Sensitive Samples for Enhanced Privacy in Federated Learning | 5.25 | 5.25 | 0.00 | [5, 8, 5, 3]
|
| 1924 | Knowledge Unlearning for Mitigating Privacy Risks in Language Models | 5.50 | 6.25 | 0.75 | [5, 6, 6, 8]
|
| 1925 | Understanding Graph Contrastive Learning From A Statistical Perspective | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 1926 | Revisiting the Activation Function for Federated Image Classification | 3.75 | 3.75 | 0.00 | [5, 6, 3, 1]
|
| 1927 | Rethinking Knowledge Distillation with Raw Features for Semantic Segmentation | 4.40 | 4.40 | 0.00 | [5, 5, 1, 6, 5]
|
| 1928 | Open-domain Visual Entity Linking | 5.50 | 5.50 | 0.00 | [8, 6, 3, 5]
|
| 1929 | Robustify Transformers with Robust Kernel Density Estimation | 4.40 | 4.40 | 0.00 | [5, 3, 5, 6, 3]
|
| 1930 | Pushing the Accuracy-Fairness Tradeoff Frontier with Introspective Self-play | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 1931 | Learning to Predict Parameter for Unseen Data | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 1932 | PADDLES: Phase-Amplitude Spectrum Disentangled Early Stopping for Learning with Noisy Labels | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 1933 | UNREAL: Unlabeled Nodes Retrieval and Labeling for Heavily-imbalanced Node Classification | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 1934 | Textless Phrase Structure Induction from Visually-Grounded Speech | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 1935 | On Nullspace of Vision Transformers and What Does it Tell Us? | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 1936 | Max-Margin Works while Large Margin Fails: Generalization without Uniform Convergence | 6.25 | 6.25 | 0.00 | [5, 6, 8, 6]
|
| 1937 | The batch size can affect inference results | 2.33 | 2.33 | 0.00 | [3, 1, 3]
|
| 1938 | Asymptotic Instance-Optimal Algorithms for Interactive Decision Making | 8.00 | 8.00 | 0.00 | [6, 8, 10, 8, 8]
|
| 1939 | GRAPHSENSOR: A Graph Attention Network for Time-Series Sensor Data | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 1940 | ProsodyBERT: Self-Supervised Prosody Representation for Style-Controllable TTS | 5.75 | 5.75 | 0.00 | [5, 3, 10, 5]
|
| 1941 | FedDebias: Reducing the Local Learning Bias Improves Federated Learning on Heterogeneous Data | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 1942 | CRISP: Curriculum inducing Primitive Informed Subgoal Prediction for Hierarchical Reinforcement Learning | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 1943 | Near-Optimal Deployment Efficiency in Reward-Free Reinforcement Learning with Linear Function Approximation | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 1944 | Mitigating Out-of-Distribution Data Density Overestimation in Energy-Based Models | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 1945 | Provably efficient multi-task Reinforcement Learning in large state spaces | 6.00 | 6.00 | 0.00 | [8, 5, 5]
|
| 1946 | An Equal-Size Hard EM Algorithm for Diverse Dialogue Generation | 4.67 | 5.00 | 0.33 | [6, 6, 5, 3]
|
| 1947 | NeuralEQ: Neural-Network-Based Equalizer for High-Speed Wireline Communication | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 1948 | Which is Better for Learning with Noisy Labels: The Semi-supervised Method or Modeling Label Noise? | 4.00 | 4.20 | 0.20 | [5, 5, 3, 5, 3]
|
| 1949 | The hidden uniform cluster prior in self-supervised learning | 5.75 | 6.00 | 0.25 | [6, 6, 6, 6]
|
| 1950 | Revisiting Over-smoothing in Graph Neural Networks | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1951 | Optical Flow Regularization of Implicit Neural Representations for Video Frame Interpolation | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 1952 | Mosaic Representation Learning for Self-supervised Visual Pre-training | 5.67 | 6.33 | 0.67 | [8, 5, 6]
|
| 1953 | Inverse Optimal Transport with Application to Contrastive Learning | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 1954 | Learning Multi-Object Positional Relationships via Emergent Communication | 6.00 | 6.00 | 0.00 | [8, 3, 5, 8]
|
| 1955 | FluidLab: A Differentiable Environment for Benchmarking Complex Fluid Manipulation | 7.00 | 7.00 | 0.00 | [5, 5, 8, 10]
|
| 1956 | Route, Interpret, Repeat: Blurring the Line Between Posthoc Explainability and Interpretable Models | 3.75 | 3.75 | 0.00 | [6, 1, 5, 3]
|
| 1957 | On Regularization for Explaining Graph Neural Networks: An Information Theory Perspective | 4.33 | 4.33 | 0.00 | [6, 1, 6]
|
| 1958 | The Dark Side of Invariance: Revisiting the Role of Augmentations in Contrastive Learning | 6.00 | 6.00 | 0.00 | [8, 6, 5, 5]
|
| 1959 | Language model with Plug-in Knowldge Memory | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 1960 | Hierarchical Gaussian Mixture based Task Generative Model for Robust Meta-Learning | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 1961 | Game-Theoretic Understanding of Misclassification | 4.20 | 4.20 | 0.00 | [1, 6, 6, 5, 3]
|
| 1962 | The Final Ascent: When Bigger Models Generalize Worse on Noisy-Labeled Data | 5.50 | 5.50 | 0.00 | [6, 8, 3, 5]
|
| 1963 | Long-Tailed Partial Label Learning via Dynamic Rebalancing | 6.00 | 6.00 | 0.00 | [5, 5, 8, 6]
|
| 1964 | Task Ambiguity in Humans and Language Models | 5.00 | 5.67 | 0.67 | [6, 3, 8]
|
| 1965 | Equivariant Disentangled Transformation for Domain Generalization under Combination Shift | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 1966 | Best Possible Q-Learning | 4.50 | 4.50 | 0.00 | [3, 6, 6, 3]
|
| 1967 | Analysis of Radio Localiser Networks under Distribution Shift | 3.75 | 3.75 | 0.00 | [6, 3, 3, 3]
|
| 1968 | Winning Both the Accuracy of Floating Point Activation and the Simplicity of Integer Arithmetic | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 1969 | Tensor Decompositions For Temporal Knowledge Graph Completion with Time Perspective | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 1970 | Preference Transformer: Modeling Human Preferences using Transformers for RL | 6.25 | 6.25 | 0.00 | [8, 6, 6, 5]
|
| 1971 | Flow Matching for Generative Modeling | 7.75 | 7.75 | 0.00 | [5, 8, 8, 10]
|
| 1972 | Graph-informed Neural Point Process With Monotonic Nets | 4.75 | 4.75 | 0.00 | [5, 3, 6, 5]
|
| 1973 | Targeted Hyperparameter Optimization with Lexicographic Preferences Over Multiple Objectives | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 1974 | Learning to Decouple Complex System for Sequential Data | 4.75 | 4.75 | 0.00 | [3, 3, 5, 8]
|
| 1975 | Restoration based Generative Models | 5.00 | 5.50 | 0.50 | [6, 5, 5, 6]
|
| 1976 | How hard are computer vision datasets? Calibrating dataset difficulty to viewing time | 6.00 | 6.00 | 0.00 | [6, 5, 8, 5]
|
| 1977 | Self-Supervised Logit Adjustment | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 1978 | Proportional Amplitude Spectrum Training Augmentation for Synthetic-to-Real Domain Generalization | 5.50 | 5.50 | 0.00 | [6, 8, 5, 3]
|
| 1979 | More Centralized Training, Still Decentralized Execution: Multi-Agent Conditional Policy Factorization | 5.67 | 5.50 | -0.17 | [5, 6, 5, 6]
|
| 1980 | StepGCN: Step-oriented Graph Convolutional Networks in Representation Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1981 | GAPS: Few-Shot Incremental Semantic Segmentation via Guided Copy-Paste Synthesis | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 1982 | Edgeformers: Graph-Empowered Transformers for Representation Learning on Textual-Edge Networks | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 1983 | How Distinguishable Are Vocoder Models? Analyzing Vocoder Fingerprints for Fake Audio | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 1984 | Hierarchical Multi-Resolution Graph Generation Networks | 2.50 | 2.50 | 0.00 | [3, 3, 1, 3]
|
| 1985 | Any-scale Balanced Samplers for Discrete Space | 5.67 | 5.67 | 0.00 | [6, 8, 3]
|
| 1986 | Stochastic Optimization under Strongly Convexity and Lipschitz Hessian: Minimax Sample Complexity | 5.25 | 4.00 | -1.25 | [6, 3, 6, 1]
|
| 1987 | BinSGDM: Extreme One-Bit Quantization for Communication Efficient Large-Scale Distributed Training | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 1988 | Gradient-based Algorithms for Pessimistic Bilevel Optimization | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1989 | Equivariant Shape-Conditioned Generation of 3D Molecules for Ligand-Based Drug Design | 5.50 | 5.75 | 0.25 | [6, 6, 5, 6]
|
| 1990 | Leaves: Learning Views for Time-Series Data in Contrastive Learning | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 1991 | The Eigenlearning Framework: A Conservation Law Perspective on Kernel Ridge Regression and Wide Neural Networks | 5.00 | 5.00 | 0.00 | [3, 5, 6, 6]
|
| 1992 | Imbalanced Semi-supervised Learning with Bias Adaptive Classifier | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 1993 | COMNET : CORTICAL MODULES ARE POWERFUL | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 1994 | A Multi-objective Perspective towards Improving Meta-Generalization | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 1995 | Do We Always Need to Penalize Variance of Losses for Learning with Label Noise? | 6.00 | 6.00 | 0.00 | [5, 5, 8]
|
| 1996 | DeepGuiser: Learning to Disguise Neural Architectures for Impeding Adversarial Transfer Attacks | 4.50 | 4.50 | 0.00 | [6, 3, 6, 3]
|
| 1997 | Network Controllability Perspectives on Graph Representation | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 1998 | FACS: FAST ADAPTIVE CHANNEL SQUEEZING | 4.00 | 4.50 | 0.50 | [5, 5, 5, 3]
|
| 1999 | Pre-trained Language Models can be Fully Zero-Shot Learners | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 2000 | On Compositional Uncertainty Quantification for Seq2seq Graph Parsing | 7.00 | 7.00 | 0.00 | [10, 3, 8]
|
| 2001 | Generative Gradual Domain Adaptation with Optimal Transport | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 2002 | ENHANCING THE PRIVACY OF FEDERATED LEARNING THROUGH DATA SYNTHESIS | 3.00 | 3.00 | 0.00 | [5, 3, 3, 1]
|
| 2003 | Free Lunch for Domain Adversarial Training: Environment Label Smoothing | 5.33 | 5.67 | 0.33 | [5, 6, 6]
|
| 2004 | DYNAMIC ENSEMBLE FOR PROBABILISTIC TIME- SERIES FORECASTING VIA DEEP REINFORCEMENT LEARNING | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 2005 | Scaling Forward Gradient With Local Losses | 7.33 | 8.00 | 0.67 | [8, 8, 8]
|
| 2006 | Recommendation with User Active Disclosing Willingness | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2007 | PAC-NeRF: Physics Augmented Continuum Neural Radiance Fields for Geometry-Agnostic System Identification | 7.50 | 7.50 | 0.00 | [8, 8, 8, 6]
|
| 2008 | Linearly Constrained Bilevel Optimization: A Smoothed Implicit Gradient Approach | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 2009 | Mastering the Game of No-Press Diplomacy via Human-Regularized Reinforcement Learning and Planning | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 2010 | Understanding Embodied Reference with Touch-Line Transformer | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 2011 | Evaluating Robustness of Cooperative MARL: A Model-based Approach | 4.80 | 4.80 | 0.00 | [6, 5, 5, 5, 3]
|
| 2012 | The Emergence of Prototypicality: Unsupervised Feature Learning in Hyperbolic Space | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2013 | Rethinking Symbolic Regression Datasets and Benchmarks for Scientific Discovery | 5.00 | 5.33 | 0.33 | [5, 5, 6]
|
| 2014 | The Cost of Privacy in Fair Machine Learning | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 2015 | Coordinated Strategy Identification Multi-Agent Reinforcement Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2016 | VARIATIONAL ADAPTIVE GRAPH TRANSFORMER FOR MULTIVARIATE TIME SERIES MODELING | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 2017 | One-Vs-All AUC Maximization: an effective solution to the low-resource named entity recognition problem | 5.33 | 5.33 | 0.00 | [8, 5, 3]
|
| 2018 | Efficient Large-scale Transformer Training via Random and Layerwise Token Dropping | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 2019 | Towards Robust Dataset Learning | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 2020 | Demystifying black-box DNN training processes through Concept-Monitor | 3.50 | 3.00 | -0.50 | [1, 5, 5, 1, 3]
|
| 2021 | Generalization Mechanics in Deep Learning | 1.50 | 1.50 | 0.00 | [1, 1, 3, 1]
|
| 2022 | Large Language Models Can Self-improve | 4.67 | 4.67 | 0.00 | [8, 3, 3]
|
| 2023 | Calibration Matters: Tackling Maximization Bias in Large-scale Advertising Recommendation Systems | 6.50 | 6.50 | 0.00 | [6, 6, 6, 8]
|
| 2024 | Excess risk analysis for epistemic uncertainty with application to variational inference | 6.33 | 6.33 | 0.00 | [8, 8, 3]
|
| 2025 | Memorization-Dilation: Modeling Neural Collapse Under Noise | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 2026 | Spacetime Representation Learning | 5.75 | 5.75 | 0.00 | [6, 3, 6, 8]
|
| 2027 | Meta-Learning General-Purpose Learning Algorithms with Transformers | 6.33 | 6.33 | 0.00 | [6, 8, 5]
|
| 2028 | Learning to Extrapolate: A Transductive Approach | 5.33 | 5.33 | 0.00 | [3, 8, 5]
|
| 2029 | Label-free Concept Bottleneck Models | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 2030 | COMBAT: Alternated Training for Near-Perfect Clean-Label Backdoor Attacks | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 2031 | Multi-level Protein Structure Pre-training via Prompt Learning | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 2032 | CLIP-Dissect: Automatic Description of Neuron Representations in Deep Vision Networks | 5.75 | 6.50 | 0.75 | [6, 8, 6, 6]
|
| 2033 | GLM-130B: An Open Bilingual Pre-trained Model | 7.50 | 7.50 | 0.00 | [6, 8, 8, 8]
|
| 2034 | Causal Estimation for Text Data with (Apparent) Overlap Violations | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 2035 | Understanding Pruning at Initialization: An Effective Node-Path Balancing Perspective | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 2036 | Intrinsic Computational Complexity of Equivariant Neural Networks | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 2037 | Data Continuity Matters: Improving Sequence Modeling with Lipschitz Regularizer | 6.50 | 6.50 | 0.00 | [8, 6, 6, 6]
|
| 2038 | MoDem: Accelerating Visual Model-Based Reinforcement Learning with Demonstrations | 6.25 | 6.25 | 0.00 | [8, 6, 5, 6]
|
| 2039 | Improving the Estimation of Instance-dependent Transition Matrix by using Self-supervised Learning | 3.50 | 3.50 | 0.00 | [5, 3, 5, 1]
|
| 2040 | Holographic-(V)AE: an end-to-end SO(3)-Equivariant (Variational) Autoencoder in Fourier Space | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 2041 | A general differentially private learning framework for decentralized data | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2042 | Wasserstein Barycenter-based Model Fusion and Linear Mode Connectivity of Neural Networks | 3.67 | 4.00 | 0.33 | [5, 3, 3, 5]
|
| 2043 | Evaluating Robustness of Generative Models with Adversarial Networks | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2044 | Weakly-Supervised Domain Adaptation in Federated Learning | 4.33 | 4.50 | 0.17 | [5, 5, 5, 3]
|
| 2045 | PD-MORL: Preference-Driven Multi-Objective Reinforcement Learning Algorithm | 6.25 | 6.25 | 0.00 | [3, 6, 8, 8]
|
| 2046 | When Majorities Prevent Learning: Eliminating Bias to Improve Worst-group and Out-of-distribution Generalization | 4.33 | 4.50 | 0.17 | [5, 5, 5, 3]
|
| 2047 | Precautionary Unfairness in Self-Supervised Contrastive Pre-training | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 2048 | Understanding the Role of Nonlinearity in Training Dynamics of Contrastive Learning | 6.75 | 6.75 | 0.00 | [8, 8, 6, 5]
|
| 2049 | Oracle-oriented Robustness: Robust Image Model Evaluation with Pretrained Models as Surrogate Oracle | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 2050 | Certified Robustness on Structural Graph Matching | 5.67 | 5.50 | -0.17 | [5, 5, 6, 6]
|
| 2051 | CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis | 6.75 | 7.50 | 0.75 | [6, 8, 8, 8]
|
| 2052 | Bayesian Optimal Experimental Design for the Survey Bandit Setting | 3.75 | 3.75 | 0.00 | [3, 3, 3, 6]
|
| 2053 | Deep Contrastive Learning Approximates Ensembles of One-Class SVMs with Neural Tangent Kernels | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 2054 | Synchronized Contrastive Pruning for Efficient Self-Supervised Learning | 5.20 | 5.20 | 0.00 | [5, 3, 5, 8, 5]
|
| 2055 | VEHICLE-INFRASTRUCTURE COOPERATIVE 3D DETECTION VIA FEATURE FLOW PREDICTION | 5.00 | 5.00 | 0.00 | [6, 5, 6, 3]
|
| 2056 | M-L2O: Towards Generalizable Learning-to-Optimize by Test-Time Fast Self-Adaptation | 4.40 | 6.40 | 2.00 | [6, 8, 8, 5, 5]
|
| 2057 | ReG-NAS: Graph Neural Network Architecture Search using Regression Proxy Task | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2058 | Mesh-Independent Operator Learning for PDEs using Set Representations | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 2059 | ROSCOE: A Suite of Metrics for Scoring Step-by-Step Reasoning | 6.40 | 7.00 | 0.60 | [8, 5, 8, 6, 8]
|
| 2060 | Robust Multi-Agent Reinforcement Learning against Adversaries on Observation | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 2061 | Limitations of Piecewise Linearity for Efficient Robustness Certification | 4.25 | 4.25 | 0.00 | [3, 5, 3, 6]
|
| 2062 | Forces are not Enough: Benchmark and Critical Evaluation for Machine Learning Force Fields with Molecular Simulations | 4.80 | 5.80 | 1.00 | [6, 5, 6, 6, 6]
|
| 2063 | Hypothetical Training for Robust Machine Reading Comprehension of Tabular Context | 4.75 | 4.75 | 0.00 | [8, 3, 3, 5]
|
| 2064 | FlexRound: Learnable Rounding by Element-wise Division for Post-Training Quantization | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 2065 | Re-calibrating Feature Attributions for Model Interpretation | 6.33 | 6.33 | 0.00 | [3, 8, 8]
|
| 2066 | Adversarial Diversity in Hanabi | 6.00 | 6.67 | 0.67 | [6, 8, 6]
|
| 2067 | 3D UX-Net: A Large Kernel Volumetric ConvNet Modernizing Hierarchical Transformer for Medical Image Segmentation | 6.33 | 6.33 | 0.00 | [3, 8, 8]
|
| 2068 | Multi-Reward Fusion: Learning from Other Policies by Distilling | 2.33 | 2.33 | 0.00 | [3, 1, 3]
|
| 2069 | Push and Pull: Competing Feature-Prototype Interactions Improve Semi-supervised Semantic Segmentation | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 2070 | MaskNeRF: Masked Neural Radiance Fields for Sparse View Synthesis | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2071 | Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small | 5.50 | 5.50 | 0.00 | [8, 8, 3, 3]
|
| 2072 | Equivariant Descriptor Fields: SE(3)-Equivariant Energy-Based Models for End-to-End Visual Robotic Manipulation Learning | 4.60 | 4.60 | 0.00 | [6, 6, 5, 3, 3]
|
| 2073 | Anatomical Structure-Aware Image Difference Graph Learning for Difference-Aware Medical Visual Question Answering | 5.33 | 5.33 | 0.00 | [5, 3, 8]
|
| 2074 | Explaining Temporal Graph Models through an Explorer-Navigator Framework | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 2075 | Tackling Diverse Tasks via Cross-Modal Transfer Learning | 5.40 | 6.00 | 0.60 | [8, 6, 6, 5, 5]
|
| 2076 | Leveraged Asymmetric Loss with Disambiguation for Multi-label Recognition with One-Positive Annotations | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 2077 | Self-supervised Learning for Cell Segmentation and Quantification in Digital Pathology Images | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 2078 | Mitigating Demographic Bias of Federated Learning Models via Global Domain Smoothing | 4.00 | 4.00 | 0.00 | [1, 6, 5]
|
| 2079 | Safe Reinforcement Learning with Contrastive Risk Prediction | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 2080 | Analysis of differentially private synthetic data: a general measurement error approach | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 2081 | Imbalanced Lifelong Learning with AUC Maximization | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 2082 | On the Efficacy of Server-Aided Federated Learning against Partial Client Participation | 4.75 | 4.25 | -0.50 | [3, 5, 6, 3]
|
| 2083 | Soft Neighbors are Positive Supporters in Contrastive Visual Representation Learning | 7.33 | 7.33 | 0.00 | [8, 6, 8]
|
| 2084 | LA-BALD: An Information-Theoretic Image Labeling Task Sampler | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 2085 | Text and Patterns: For Effective Chain of Thought It Takes Two to Tango | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 2086 | Offline RL for Natural Language Generation with Implicit Language Q Learning | 6.33 | 6.33 | 0.00 | [3, 8, 8]
|
| 2087 | MoCa: Cognitive Scaffolding for Language Models in Causal and Moral Judgment Tasks | 4.67 | 4.67 | 0.00 | [8, 3, 3]
|
| 2088 | Anchor Sampling for Federated Learning with Partial Client Participation | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 2089 | Lattice Convolutional Networks for Learning Ground States of Quantum Many-Body Systems | 4.67 | 4.67 | 0.00 | [3, 8, 3]
|
| 2090 | CLIPSep: Learning Text-queried Sound Separation with Noisy Unlabeled Videos | 6.00 | 6.40 | 0.40 | [6, 6, 6, 6, 8]
|
| 2091 | On the Soft-Subnetwork for Few-Shot Class Incremental Learning | 5.67 | 5.67 | 0.00 | [8, 6, 3]
|
| 2092 | Fairness-Aware Model-Based Multi-Agent Reinforcement Learning for Traffic Signal Control | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 2093 | Approximating How Single Head Attention Learns | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2094 | Efficient Attention via Control Variates | 7.00 | 7.50 | 0.50 | [8, 6, 8, 8]
|
| 2095 | Pathfinding Neural Cellular Automata | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 2096 | Learning to Optimize Quasi-Newton Methods | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 2097 | Toxicity in Multilingual Machine Translation at Scale | 4.75 | 4.75 | 0.00 | [3, 3, 5, 8]
|
| 2098 | An Adaptive Policy to Employ Sharpness-Aware Minimization | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 2099 | FedMT: Federated Learning with Mixed-type Labels | 5.50 | 5.50 | 0.00 | [3, 5, 8, 6]
|
| 2100 | A Note on Quantifying the Influence of Energy Regularization for Imbalanced Classification | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2101 | Penalizing the High-likelihood: A Novel Sampling Method for Open-ended Neural Text Generation via Inverse Probability Weighting | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2102 | Unlearning with Fisher Masking | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 2103 | Augmented Lagrangian is Enough for Optimal Offline RL with General Function Approximation and Partial Coverage | 7.00 | 7.50 | 0.50 | [8, 8, 8, 6]
|
| 2104 | Bandit Learning with General Function Classes: Heteroscedastic Noise and Variance-dependent Regret Bounds | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 2105 | A Semantic Hierarchical Graph Neural Network for Text Classification | 4.25 | 4.25 | 0.00 | [3, 3, 3, 8]
|
| 2106 | Injecting Image Details into CLIP"s Feature Space | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2107 | Adaptive Sparse Softmax: An Effective and Efficient Softmax Variant for Text Classification | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 2108 | Stochastic Bridges as Effective Regularizers for Parameter-Efficient Tuning | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 2109 | Continuous Goal Sampling: A Simple Technique to Accelerate Automatic Curriculum Learning | 4.75 | 4.75 | 0.00 | [5, 5, 3, 6]
|
| 2110 | What do Vision Transformers Learn? A Visual Exploration | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 2111 | When do Convolutional Neural Networks Stop Learning? | 2.80 | 2.80 | 0.00 | [1, 1, 6, 3, 3]
|
| 2112 | Detecting and Mitigating Indirect Stereotypes in Word Embeddings | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 2113 | OCIM : Object-centric Compositional Imagination for Visual Abstract Reasoning | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2114 | How Weakly Supervised Information helps Contrastive Learning | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 2115 | A computational framework to unify representation similarity and function in biological and artificial neural networks | 5.25 | 5.25 | 0.00 | [5, 5, 8, 3]
|
| 2116 | Fairness and Accuracy under Domain Generalization | 6.33 | 6.67 | 0.33 | [8, 6, 6]
|
| 2117 | DROP: Conservative Model-based Optimization for Offline Reinforcement Learning | 4.25 | 5.00 | 0.75 | [6, 3, 5, 6]
|
| 2118 | Language Models Can Teach Themselves to Program Better | 6.25 | 6.25 | 0.00 | [5, 6, 6, 8]
|
| 2119 | Adaptive Kernel Selection for Convolutional Neural Network | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 2120 | MVP: Multi-task Supervised Pre-training for Natural Language Generation | 3.00 | 3.00 | 0.00 | [3, 1, 5]
|
| 2121 | Learning Unified Representations for Multi-Resolution Face Recognition | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 2122 | Latent Bottlenecked Attentive Neural Processes | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 2123 | Improving Inductive Link Prediction through Learning Generalizable Node Representations | 3.00 | 3.00 | 0.00 | [5, 1, 3, 3]
|
| 2124 | VoLTA: Vision-Language Transformer with Weakly-Supervised Local-Feature Alignment | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 2125 | Online Min-max Optimization: Nonconvexity, Nonstationarity, and Dynamic Regret | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 2126 | Embed to Control Partially Observed Systems: Representation Learning with Provable Sample Efficiency | 5.00 | 5.00 | 0.00 | [6, 5, 6, 3]
|
| 2127 | Towards Better Selective Classification | 4.75 | 4.75 | 0.00 | [8, 5, 3, 3]
|
| 2128 | Offline Equilibrium Finding | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 2129 | ASGNN: Graph Neural Networks with Adaptive Structure | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 2130 | Iteratively Learning Novel Strategies with Diversity Measured in State Distances | 6.33 | 6.33 | 0.00 | [6, 8, 5]
|
| 2131 | Learning Kernelized Contextual Bandits in a Distributed and Asynchronous Environment | 6.25 | 6.25 | 0.00 | [6, 5, 6, 8]
|
| 2132 | ATTRIBUTES RECONSTRUCTION IN HETEROGENEOUS NETWORKS VIA GRAPH AUGMENTATION | 3.00 | 3.00 | 0.00 | [3, 1, 5]
|
| 2133 | Graph Signal Sampling for Inductive One-Bit Matrix Completion: a Closed-form Solution | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 2134 | DocPrompting: Generating Code by Retrieving the Docs | 7.00 | 7.50 | 0.50 | [6, 8, 8, 8]
|
| 2135 | Comparing semantic and morphological analogy completion in word embeddings | 2.00 | 2.00 | 0.00 | [3, 1, 3, 1]
|
| 2136 | LipsFormer: Introducing Lipschitz Continuity to Vision Transformers | 5.75 | 5.75 | 0.00 | [6, 6, 8, 3]
|
| 2137 | Automatic Chain of Thought Prompting in Large Language Models | 5.75 | 6.25 | 0.50 | [8, 6, 8, 3]
|
| 2138 | Enforcing zero-Hessian in meta-learning | 4.00 | 4.00 | 0.00 | [3, 1, 5, 6, 5]
|
| 2139 | An efficient encoder-decoder architecture with top-down attention for speech separation | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 2140 | Treatment Effect Estimation with Collider Bias and Confounding Bias | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 2141 | Adaptive Weight Decay: On The Fly Weight Decay Tuning for Improving Robustness | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 2142 | Annealed Training for Combinatorial Optimization on Graphs | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 2143 | Machine Unlearning of Federated Clusters | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 2144 | Semi-Supervised Segmentation-Guided Tumor-Aware Generative Adversarial Network for Multi-Modality Brain Tumor Translation | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 2145 | Brainformers: Trading Simplicity for Efficiency | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 2146 | Control Graph as Unified IO for Morphology-Task Generalization | 6.50 | 6.50 | 0.00 | [5, 8, 8, 5]
|
| 2147 | Learning to Generate Pseudo Anomalies | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 2148 | Effective Self-Supervised Transformers For Sparse Time Series Data | 4.75 | 4.75 | 0.00 | [5, 3, 5, 6]
|
| 2149 | | 5.00 | 5.00 | 0.00 | [6, 5, 6, 3]
|
| 2150 | Scalable feature selection via sparse learnable masks | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2151 | On the Interplay Between Misspecification and Sub-optimality Gap: From Linear Contextual Bandits to Linear MDPs | 5.40 | 5.40 | 0.00 | [6, 5, 6, 5, 5]
|
| 2152 | HSVC: Transformer-based Hierarchical Distillation for Software Vulnerability Classification | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 2153 | HAS IT REALLY IMPROVED? KNOWLEDGE GRAPH BASED SEPARATION AND FUSION FOR RECOMMENDATION | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2154 | Counterfactual Contrastive Learning for Robust Text Classification | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 2155 | SAM as an Optimal Relaxation of Bayes | 6.75 | 6.75 | 0.00 | [6, 5, 8, 8]
|
| 2156 | Denoising MCMC for Accelerating Diffusion-Based Generative Models | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 2157 | Learning on Large-scale Text-attributed Graphs via Variational Inference | 7.25 | 7.25 | 0.00 | [8, 8, 8, 5]
|
| 2158 | Efficient Shapley Values Estimation by Amortization for Text Classification | 4.75 | 4.75 | 0.00 | [3, 5, 3, 8]
|
| 2159 | SplitMixer: Fat Trimmed From MLP-like Models | 3.50 | 3.50 | 0.00 | [5, 5, 3, 1]
|
| 2160 | Multimedia Generative Script Learning for Task Planning | 5.33 | 5.33 | 0.00 | [8, 3, 5]
|
| 2161 | On Assimilating Learned Views in Contrastive Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2162 | Upcycled-FL: Improving Accuracy and Privacy with Less Computation in Federated Learning | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 2163 | Dataset Projection: Finding Target-aligned Subsets of Auxiliary Data | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 2164 | Rethinking Identity in Knowledge Graph Embedding | 5.00 | 5.00 | 0.00 | [3, 5, 6, 6]
|
| 2165 | Eigen Memory Trees | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 2166 | Energy-based Predictive Representation for Reinforcement Learning | 5.00 | 5.00 | 0.00 | [3, 8, 6, 3]
|
| 2167 | Which Invariance Should We Transfer? A Causal Minimax Learning Approach | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 2168 | Exclusive Supermask Subnetwork Training for Continual Learning | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 2169 | Dual personalization for federated recommendation on devices | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 2170 | Unsupervised Manifold Linearizing and Clustering | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 2171 | Moderate Coreset: A Universal Method of Data Selection for Real-world Data-efficient Deep Learning | 6.25 | 6.25 | 0.00 | [8, 6, 5, 6]
|
| 2172 | Effectively Clarify Confusion via Visualized Aggregation and Separation of Deep Representation | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2173 | Time-Transformer AAE: Connecting Temporal Convolutional Networks and Transformer for Time Series Generation | 5.00 | 5.00 | 0.00 | [6, 6, 5, 3]
|
| 2174 | A comparison of dataset distillation and active learning in text classification | 1.00 | 1.00 | 0.00 | [1, 1, 1]
|
| 2175 | Temporally Consistent Video Transformer for Long-Term Video Prediction | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 2176 | Extreme Q-Learning: MaxEnt RL without Entropy | 7.25 | 7.50 | 0.25 | [6, 10, 6, 8]
|
| 2177 | Autoencoding Hyperbolic Representation for Adversarial Generation | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 2178 | CAREER: Transfer Learning for Economic Prediction of Labor Data | 6.00 | 6.00 | 0.00 | [8, 5, 5]
|
| 2179 | Federated Nearest Neighbor Machine Translation | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 2180 | Latent Variable Representation for Reinforcement Learning | 5.75 | 5.75 | 0.00 | [6, 8, 6, 3]
|
| 2181 | Look in The Mirror: Molecular Graph Contrastive Learning with Line Graph | 4.60 | 5.60 | 1.00 | [6, 5, 3, 8, 6]
|
| 2182 | Precision Collaboration for Federated Learning | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 2183 | RLSBench: A Large-Scale Empirical Study of Domain Adaptation Under Relaxed Label Shift | 5.00 | 5.00 | 0.00 | [3, 6, 5, 6]
|
| 2184 | ROCO: A General Framework for Evaluating Robustness of Combinatorial Optimization Solvers on Graphs | 6.00 | 6.00 | 0.00 | [8, 6, 5, 5]
|
| 2185 | Spatial reasoning as Object Graph Energy Minimization | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 2186 | Words are all you need? Language as an approximation for representational similarity | 7.00 | 7.00 | 0.00 | [10, 5, 8, 5]
|
| 2187 | Graph Contrastive Learning with Reinforced Augmentation | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 2188 | A Novel Fast Exact Subproblem Solver for Stochastic Quasi-Newton Cubic Regularized Optimization | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 2189 | Block-Diagonal Structure Learning for Subspace Clustering | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2190 | Decentralized Federated Learning via Overlapping Data Augmentation | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 2191 | Offline RL of the Underlying MDP from Heterogeneous Data Sources | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 2192 | An interpretable contrastive logical knowledge learning method for sentiment analysis | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2193 | FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning | 7.00 | 7.00 | 0.00 | [8, 5, 8]
|
| 2194 | The Impact of Neighborhood Distribution in Graph Convolutional Networks | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2195 | Training image classifiers using Semi-Weak Label Data | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 2196 | Confidence Estimation Using Unlabeled Data | 5.50 | 5.50 | 0.00 | [3, 6, 5, 8]
|
| 2197 | Towards Class-Balanced Transductive Few-Shot Learning | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 2198 | Spectral Decomposition Representation for Reinforcement Learning | 7.00 | 7.00 | 0.00 | [5, 8, 8]
|
| 2199 | On Accelerated Perceptrons and Beyond | 7.00 | 7.00 | 0.00 | [5, 8, 8]
|
| 2200 | DITTO: Offline Imitation Learning with World Models | 5.25 | 5.50 | 0.25 | [5, 5, 6, 6]
|
| 2201 | BAT-Chain: Bayesian-Aware Transport Chain for Topic Hierarchies Discovery | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 2202 | On the Importance of Calibration in Semi-supervised Learning | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 2203 | SoftMatch: Addressing the Quantity-Quality Tradeoff in Semi-supervised Learning | 5.75 | 6.50 | 0.75 | [6, 6, 6, 8]
|
| 2204 | Unleashing the Potential of Data Sharing in Ensemble Deep Reinforcement Learning | 3.75 | 3.75 | 0.00 | [1, 6, 5, 3]
|
| 2205 | Certifiably Robust Policy Learning against Adversarial Multi-Agent Communication | 7.00 | 7.00 | 0.00 | [5, 8, 8]
|
| 2206 | Node Importance Specific Meta Learning in Graph Neural Networks | 4.40 | 4.40 | 0.00 | [3, 3, 6, 5, 5]
|
| 2207 | Attention-Guided Backdoor Attacks against Transformers | 5.75 | 5.75 | 0.00 | [5, 8, 5, 5]
|
| 2208 | Disentangling the Mechanisms Behind Implicit Regularization in SGD | 5.25 | 5.75 | 0.50 | [6, 6, 6, 5]
|
| 2209 | Seq2Seq Pre-training with Dual-channel Recombination for Translation | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2210 | Oracles and Followers: Stackelberg Equilibria in Deep Multi-Agent Reinforcement Learning | 4.67 | 4.25 | -0.42 | [3, 5, 3, 6]
|
| 2211 | Structural Code Representation Learning for Auto-Vectorization | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 2212 | Overthinking the Truth: Understanding how Language Models process False Demonstrations | 5.75 | 5.75 | 0.00 | [5, 5, 8, 5]
|
| 2213 | Sequential Attention for Feature Selection | 5.50 | 5.50 | 0.00 | [8, 5, 6, 3]
|
| 2214 | Trusted Aggregation (TAG): Model Filtering Backdoor Defense In Federated Learning | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 2215 | What Deep Representations Should We Learn? -- A Neural Collapse Perspective | 4.25 | 4.25 | 0.00 | [5, 3, 6, 3]
|
| 2216 | Improved Sample Complexity for Reward-free Reinforcement Learning under Low-rank MDPs | 4.75 | 4.75 | 0.00 | [5, 5, 3, 6]
|
| 2217 | Re-Imagen: Retrieval-Augmented Text-to-Image Generator | 5.75 | 5.75 | 0.00 | [6, 6, 6, 5]
|
| 2218 | BiViT: Exploring Binary Vision Transformers | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 2219 | Magnum: Tackling High-Dimensional Structures with Self-Organization | 3.67 | 3.67 | 0.00 | [5, 5, 1]
|
| 2220 | Provably Efficient Lifelong Reinforcement Learning with Linear Representation | 5.25 | 5.50 | 0.25 | [5, 5, 6, 6]
|
| 2221 | Towards Adversarially Robust Deepfake Detection: An Ensemble Approach | 4.25 | 5.50 | 1.25 | [8, 8, 3, 3]
|
| 2222 | Fast Adaptation via Human Diagnosis of Task Distribution Shift | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 2223 | Link Prediction with Non-Contrastive Learning | 4.50 | 4.75 | 0.25 | [5, 6, 5, 3]
|
| 2224 | Distributed Differential Privacy in Multi-Armed Bandits | 5.67 | 6.67 | 1.00 | [8, 6, 6]
|
| 2225 | Thrust: Adaptively Propels Large Language Models with External Knowledge | 3.00 | 3.00 | 0.00 | [1, 5, 3, 3]
|
| 2226 | Progress measures for grokking via mechanistic interpretability | 7.33 | 7.33 | 0.00 | [8, 8, 6]
|
| 2227 | Deep Bayesian Active Learning for Accelerating Stochastic Simulation | 5.00 | 4.50 | -0.50 | [3, 6, 6, 3]
|
| 2228 | On the Mysterious Optimization Geometry of Deep Neural Networks | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 2229 | Implicit regularization via Spectral Neural Networks and non-linear matrix sensing | 5.75 | 5.75 | 0.00 | [8, 3, 6, 6]
|
| 2230 | Goal-Space Planning with Subgoal Models | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 2231 | MET : Masked Encoding for Tabular data | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 2232 | Shortcut Learning Through the Lens of Early Training Dynamics | 4.75 | 4.75 | 0.00 | [6, 6, 6, 1]
|
| 2233 | On $\mathcal{O}(1/K)$ Convergence and Low Sample Complexity for Single-Timescale Policy Evaluation with Nonlinear Function Approximation | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 2234 | Generating Features with Increased Crop-Related Diversity for Few-shot Object Detection | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 2235 | On the Implicit Bias Towards Depth Minimization in Deep Neural Networks | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 2236 | Prometheus: Endowing Low Sample and Communication Complexities to Constrained Decentralized Stochastic Bilevel Learning | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 2237 | SGD and Weight Decay Provably Induce a Low-Rank Bias in Neural Networks | 3.00 | 3.00 | 0.00 | [5, 3, 3, 1]
|
| 2238 | MobileViTv3: Mobile-Friendly Vision Transformer with Simple and Effective Fusion of Local, Global and Input Features | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 2239 | PiFold: Toward effective and efficient protein inverse folding | 6.00 | 6.67 | 0.67 | [6, 6, 8]
|
| 2240 | A Theoretical Understanding of Vision Transformers: Learning, Generalization, and Sample Complexity | 5.00 | 5.00 | 0.00 | [6, 6, 5, 3]
|
| 2241 | AlphaDesign: A graph protein design method and benchmark on AlphaFold DB | 4.25 | 4.25 | 0.00 | [5, 6, 1, 5]
|
| 2242 | Transfer Learning with Context-aware Feature Compensation | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2243 | Contrastive Learning Can Find An Optimal Basis For Approximately View-Invariant Functions | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 2244 | Learning Unsupervised Forward Models from Object Keypoints | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 2245 | K-SAM: Sharpness-Aware Minimization at the Speed of SGD | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 2246 | Copula Conformal Prediction for Multi-step Time Series Forecasting | 5.25 | 5.25 | 0.00 | [6, 6, 6, 3]
|
| 2247 | Multi-Epoch Matrix Factorization Mechanisms for Private Machine Learning | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 2248 | Quantum 3D graph structure learning with applications to molecule computing | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 2249 | Distributional Signals for Node Classification in Graph Neural Networks | 6.00 | 5.33 | -0.67 | [5, 6, 5]
|
| 2250 | Vector Quantized Wasserstein Auto-Encoder | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 2251 | Exact Representation of Sparse Networks with Symmetric Nonnegative Embeddings | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 2252 | Skill-Based Reinforcement Learning with Intrinsic Reward Matching | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 2253 | A New Path: Scaling Vision-and-Language Navigation with Synthetic Instructions and Imitation Learning | 5.75 | 5.75 | 0.00 | [5, 5, 8, 5]
|
| 2254 | TuneUp: A Training Strategy for Improving Generalization of Graph Neural Networks | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2255 | Collecting The Puzzle Pieces: Disentangled Self-Driven Human Pose Transfer by Permuting Textures | 4.75 | 4.75 | 0.00 | [5, 3, 3, 8]
|
| 2256 | A Scalable and Exact Gaussian Process Sampler via Kernel Packets | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 2257 | Model ChangeLists: Characterizing Changes in ML Prediction APIs | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 2258 | Provably Auditing Ordinary Least Squares in Low Dimensions | 7.50 | 7.50 | 0.00 | [8, 6, 8, 8]
|
| 2259 | Exploring semantic information in disease: Simple Data Augmentation Techniques for Chinese Disease Normalization | 3.25 | 3.25 | 0.00 | [3, 6, 1, 3]
|
| 2260 | Live in the Moment: Learning Dynamics Model Adapted to Evolving Policy | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 2261 | Planning Goals for Exploration | 6.00 | 7.20 | 1.20 | [8, 8, 6, 8, 6]
|
| 2262 | Learning Sparse Group Models Through Boolean Relaxation | 7.00 | 7.50 | 0.50 | [8, 8, 8, 6]
|
| 2263 | LVQ-VAE:End-to-end Hyperprior-based Variational Image Compression with Lattice Vector Quantization | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 2264 | Direct Embedding of Temporal Network Edges via Time-Decayed Line Graphs | 6.38 | 6.38 | 0.00 | [5, 6, 6, 8, 3, 5, 8, 10]
|
| 2265 | Neural DAG Scheduling via One-Shot Priority Sampling | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 2266 | TrajGRU-Attention-ODE: Novel Spatiotemporal Predictive Models | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 2267 | Learning-Based Radiomic Prediction of Type 2 Diabetes Mellitus Using Image-Derived Phenotypes | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 2268 | Efficiently Computing Nash Equilibria in Adversarial Team Markov Games | 6.33 | 7.00 | 0.67 | [5, 8, 8]
|
| 2269 | Meta Temporal Point Processes | 4.50 | 4.75 | 0.25 | [5, 5, 6, 3]
|
| 2270 | EmbedDistill: A geometric knowledge distillation for information retrieval | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 2271 | Graph Neural Network-Inspired Kernels for Gaussian Processes in Semi-Supervised Learning | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 2272 | Deconstructing Distributions: A Pointwise Framework of Learning | 7.00 | 7.00 | 0.00 | [8, 6, 6, 8]
|
| 2273 | Logical view on fairness of a binary classification task | 3.00 | 3.00 | 0.00 | [3, 5, 1]
|
| 2274 | Revisiting Instance-Reweighted Adversarial Training | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2275 | Diffusion Models for Causal Discovery via Topological Ordering | 6.25 | 5.50 | -0.75 | [8, 3, 5, 6]
|
| 2276 | Scalable and Equivariant Spherical CNNs by Discrete-Continuous (DISCO) Convolutions | 6.00 | 6.00 | 0.00 | [5, 5, 8, 6]
|
| 2277 | Towards Solving Industrial Sequential Decision-making Tasks under Near-predictable Dynamics via Reinforcement Learning: an Implicit Corrective Value Estimation Approach | 4.00 | 4.50 | 0.50 | [5, 5, 3, 5]
|
| 2278 | Graph Convolutional Normalizing Flows for Semi-Supervised Classification and Clustering | 5.75 | 5.75 | 0.00 | [5, 5, 5, 8]
|
| 2279 | Weakly Supervised Explainable Phrasal Reasoning with Neural Fuzzy Logic | 5.75 | 6.50 | 0.75 | [6, 6, 8, 6]
|
| 2280 | Simplified State Space Layers for Sequence Modeling | 7.33 | 8.00 | 0.67 | [8, 8, 8]
|
| 2281 | Learning Listwise Domain-Invariant Representations for Ranking | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 2282 | DCI-ES: An Extended Disentanglement Framework with Connections to Identifiability | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 2283 | Eigenvalue Initialisation and Regularisation for Koopman Autoencoders | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 2284 | Learning from Labeled Images and Unlabeled Videos for Video Segmentation | 4.75 | 4.75 | 0.00 | [3, 3, 8, 5]
|
| 2285 | Score-based Generative 3D Mesh Modeling | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 2286 | Faster federated optimization under second-order similarity | 5.20 | 5.20 | 0.00 | [5, 5, 6, 5, 5]
|
| 2287 | Assessing Neural Network Robustness via Adversarial Pivotal Tuning of Real Images | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 2288 | REV: Information-Theoretic Evaluation of Free-Text Rationales | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 2289 | Examining the Difference Among Transformers and CNNs with Explanation Methods | 3.50 | 3.50 | 0.00 | [5, 5, 1, 3]
|
| 2290 | A Quasistatic Derivation of Optimization Algorithms" Exploration on Minima Manifolds | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 2291 | Mutual Partial Label Learning with Competitive Label Noise | 5.67 | 5.67 | 0.00 | [6, 8, 3]
|
| 2292 | The Graph Learning Attention Mechanism: Learnable Sparsification Without Heuristics | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 2293 | Partial Label Unsupervised Domain Adaptation with Class-Prototype Alignment | 6.75 | 6.75 | 0.00 | [6, 8, 8, 5]
|
| 2294 | Why Self Attention is Natural for Sequence-to-Sequence Problems? A Perspective from Symmetries | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 2295 | simpleKT: A Simple But Tough-to-Beat Baseline for Knowledge Tracing | 5.67 | 5.67 | 0.00 | [6, 8, 3]
|
| 2296 | Exp-$\alpha$: Beyond Proportional Aggregation in Federated Learning | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 2297 | Learning Efficient Hybrid Particle-continuum Representations of Non-equilibrium N-body Systems | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 2298 | Towards Large Scale Transfer Learning for Differentially Private Image Classification | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 2299 | Neural Network Approximation of Lipschitz Functions in High Dimensions with Applications to Inverse Problems | 6.00 | 6.00 | 0.00 | [8, 5, 5, 6]
|
| 2300 | Weighted Ensemble Self-Supervised Learning | 5.75 | 5.75 | 0.00 | [6, 8, 6, 3]
|
| 2301 | Partially Observable RL with B-Stability: Unified Structural Condition and Sharp Sample-Efficient Algorithms | 7.33 | 7.33 | 0.00 | [8, 8, 6]
|
| 2302 | Bias Amplification Improves Worst-Group Accuracy without Group Information | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 2303 | Actionable Recourse Guided by User Preference | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 2304 | Large Learning Rate Matters for Non-Convex Optimization | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 2305 | A Deep Learning Framework for Musical Acoustics Simulations | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 2306 | Domain Generalization via Heckman-type Selection Models | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 2307 | Moving Forward by Moving Backward: Embedding Action Impact over Action Semantics | 6.75 | 6.75 | 0.00 | [8, 8, 5, 6]
|
| 2308 | Guiding Safe Exploration with Weakest Preconditions | 5.50 | 5.50 | 0.00 | [5, 6, 8, 3]
|
| 2309 | MetaMD: Principled Optimiser Meta-Learning for Deep Learning | 6.25 | 6.25 | 0.00 | [3, 8, 8, 6]
|
| 2310 | A Sample Based Method for Understanding The Decisions of Neural Networks Semantically | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 2311 | Deep Biological Pathway Informed Pathology-Genomic Multimodal Survival Prediction | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2312 | A CMDP-within-online framework for Meta-Safe Reinforcement Learning | 5.33 | 5.33 | 0.00 | [8, 5, 3]
|
| 2313 | Active Sampling for Node Attribute Completion on Graphs | 3.00 | 3.00 | 0.00 | [5, 1, 3, 3]
|
| 2314 | Effects of Graph Convolutions in Multi-layer Networks | 7.50 | 7.50 | 0.00 | [6, 8, 8, 8]
|
| 2315 | SimPer: Simple Self-Supervised Learning of Periodic Targets | 6.33 | 7.33 | 1.00 | [8, 6, 8]
|
| 2316 | Explaining Patterns in Data with Language Models via Interpretable Autoprompting | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 2317 | Lipschitz regularized gradient flows and latent generative particles | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 2318 | Post-hoc Concept Bottleneck Models | 7.33 | 8.00 | 0.67 | [8, 8, 8]
|
| 2319 | Undersampling is a Minimax Optimal Robustness Intervention in Nonparametric Classification | 6.75 | 6.75 | 0.00 | [5, 6, 8, 8]
|
| 2320 | Emb-GAM: an Interpretable and Efficient Predictor using Pre-trained Language Models | 3.00 | 3.00 | 0.00 | [5, 1, 3]
|
| 2321 | When Source-Free Domain Adaptation Meets Learning with Noisy Labels | 6.25 | 6.00 | -0.25 | [6, 6, 6, 6]
|
| 2322 | Is a Caption Worth a Thousand Images? A Study on Representation Learning | 5.25 | 5.25 | 0.00 | [3, 5, 5, 8]
|
| 2323 | Parameter-Efficient Fine-Tuning Design Spaces | 5.25 | 5.25 | 0.00 | [5, 5, 8, 3]
|
| 2324 | Concept Gradient: Concept-based Interpretation Without Linear Assumption | 6.25 | 6.25 | 0.00 | [6, 8, 5, 6]
|
| 2325 | FedCUAU: Clustered Federated Learning using weight divergence | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2326 | Constraining Representations Yields Models That Know What They Don"t Know | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 2327 | Neural Networks Efficiently Learn Low-Dimensional Representations with SGD | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 2328 | Mixed Federated Learning: Joint Decentralized and Centralized Learning | 4.25 | 4.25 | 0.00 | [3, 5, 6, 3]
|
| 2329 | OTCOP: Learning optimal transport maps via constraint optimizations | 4.50 | 4.50 | 0.00 | [3, 3, 6, 6]
|
| 2330 | An Extensible Multi-modal Multi-task Object Dataset with Materials | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 2331 | Sampling with Mollified Interaction Energy Descent | 6.75 | 6.75 | 0.00 | [5, 8, 6, 8]
|
| 2332 | Does Zero-Shot Reinforcement Learning Exist? | 6.75 | 7.25 | 0.50 | [10, 8, 3, 8]
|
| 2333 | Few-Shot Text Classification with Dual Contrastive Consistency Training | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2334 | Self-Stabilization: The Implicit Bias of Gradient Descent at the Edge of Stability | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 2335 | Toward Discovering Options that Achieve Faster Planning | 4.25 | 4.25 | 0.00 | [5, 3, 3, 6]
|
| 2336 | Conditional Permutation Invariant Flows | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 2337 | TILP: Differentiable Learning of Temporal Logical Rules on Knowledge Graphs | 5.75 | 5.75 | 0.00 | [8, 5, 5, 5]
|
| 2338 | Hyperbolic Deep Reinforcement Learning | 6.67 | 8.00 | 1.33 | [10, 8, 6]
|
| 2339 | Learning Controllable Adaptive Simulation for Multi-scale Physics | 5.00 | 5.50 | 0.50 | [8, 6, 5, 3]
|
| 2340 | Gated Neural ODEs: Trainability, Expressivity and Interpretability | 5.50 | 5.50 | 0.00 | [5, 6, 8, 3]
|
| 2341 | Value-Based Membership Inference Attack on Actor-Critic Reinforcement Learning | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 2342 | Open-Vocabulary Object Detection upon Frozen Vision and Language Models | 7.33 | 7.33 | 0.00 | [8, 6, 8]
|
| 2343 | Learned Neural Network Representations are Spread Diffusely with Redundancy | 5.33 | 5.67 | 0.33 | [6, 5, 6]
|
| 2344 | Neural DAEs: Constrained neural networks | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2345 | Revisiting the Assumption of Latent Separability for Backdoor Defenses | 5.67 | 5.00 | -0.67 | [3, 6, 6, 5]
|
| 2346 | Restricted Strong Convexity of Deep Learning Models with Smooth Activations | 6.50 | 6.50 | 0.00 | [6, 6, 6, 8]
|
| 2347 | Koopman Neural Operator Forecaster for Time-series with Temporal Distributional Shifts | 6.50 | 6.50 | 0.00 | [8, 5, 8, 5]
|
| 2348 | Uncertainty-Driven Exploration for Generalization in Reinforcement Learning | 4.75 | 5.25 | 0.50 | [5, 6, 5, 5]
|
| 2349 | SPIDR: SDF-based Neural Point Fields for Illumination and Deformation | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2350 | On Convergence of Federated Averaging Langevin Dynamics | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 2351 | Posthoc Privacy guarantees for neural network queries | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 2352 | MetaGL: Evaluation-Free Selection of Graph Learning Models via Meta-Learning | 6.25 | 6.25 | 0.00 | [8, 5, 6, 6]
|
| 2353 | FOCUS: Fairness via Agent-Awareness for Federated Learning on Heterogeneous Data | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 2354 | A Simple Unsupervised Data Depth-based Method to Detect Adversarial Images | 3.75 | 3.75 | 0.00 | [3, 8, 1, 3]
|
| 2355 | Co-Evolution As More Than a Scalable Alternative for Multi-Agent Reinforcement Learning | 2.00 | 2.00 | 0.00 | [1, 1, 3, 3]
|
| 2356 | Adaptive Parametric Prototype Learning for Cross-Domain Few-Shot Classification | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 2357 | Minimum Description Length Control | 6.00 | 6.25 | 0.25 | [6, 5, 8, 6]
|
| 2358 | RainProof: An Umbrella to Shield Text Generator from Out-Of-Distribution Data | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 2359 | Variance Double-Down: The Small Batch Size Anomaly in Multistep Deep Reinforcement Learning | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 2360 | PerFedMask: Personalized Federated Learning with Optimized Masking Vectors | 4.67 | 5.00 | 0.33 | [6, 3, 6]
|
| 2361 | Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP | 5.75 | 5.75 | 0.00 | [5, 8, 5, 5]
|
| 2362 | Variational Latent Branching Model for Off-Policy Evaluation | 5.25 | 5.50 | 0.25 | [6, 6, 5, 5]
|
| 2363 | Building compact representations for image-language learning | 4.75 | 4.75 | 0.00 | [3, 5, 3, 8]
|
| 2364 | Discretization Invariant Learning on Neural Fields | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 2365 | Dynamic Pretraining of Vision-Language Models | 4.75 | 4.75 | 0.00 | [5, 3, 6, 5]
|
| 2366 | HEAV: Hierarchical Ensembling of Augmented Views for Image Captioning | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 2367 | Tuning Frequency Bias in Neural Network Training with Nonuniform Data | 6.00 | 6.00 | 0.00 | [5, 8, 5, 6]
|
| 2368 | Global Counterfactual Explanations Are Reliable Or Efficient, But Not Both | 5.00 | 5.00 | 0.00 | [5, 6, 8, 1, 5]
|
| 2369 | Learning Multimodal Data Augmentation in Feature Space | 5.50 | 5.75 | 0.25 | [6, 8, 3, 6]
|
| 2370 | Where to Begin? Exploring the Impact of Pre-Training and Initialization in Federated | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 2371 | BigVGAN: A Universal Neural Vocoder with Large-Scale Training | 7.60 | 7.60 | 0.00 | [6, 8, 8, 8, 8]
|
| 2372 | PaLI: A Jointly-Scaled Multilingual Language-Image Model | 6.75 | 6.75 | 0.00 | [6, 8, 8, 5]
|
| 2373 | Achieving Sub-linear Regret in Infinite Horizon Average Reward Constrained MDP with Linear Function Approximation | 5.50 | 5.50 | 0.00 | [5, 3, 8, 6]
|
| 2374 | Causal Imitation Learning via Inverse Reinforcement Learning | 6.33 | 6.50 | 0.17 | [6, 6, 8, 6]
|
| 2375 | Amos: An Adam-style Optimizer with Adaptive Weight Decay towards Model-Oriented Scale | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 2376 | The Surprising Computational Power of Nondeterministic Stack RNNs | 6.50 | 7.00 | 0.50 | [6, 8, 6, 8]
|
| 2377 | Critical Initialization of Wide and Deep Neural Networks through Partial Jacobians: General Theory and Applications | 6.25 | 6.25 | 0.00 | [8, 3, 8, 6]
|
| 2378 | Agnostic Learning of General ReLU Activation Using Gradient Descent | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 2379 | Parametrizing Product Shape Manifolds by Composite Networks | 7.00 | 7.00 | 0.00 | [5, 8, 8]
|
| 2380 | CURE: A Pre-training Framework on Large-scale Patient Data for Treatment Effect Estimation | 5.75 | 5.75 | 0.00 | [5, 8, 5, 5]
|
| 2381 | A Probabilistic Approach to Self-Supervised Learning using Cyclical Stochastic Gradient MCMC | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2382 | Tabular Data to Image Generation: Benchmark Data, Approaches, and Evaluation | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2383 | Learning Hyper Label Model for Programmatic Weak Supervision | 7.00 | 6.25 | -0.75 | [8, 6, 6, 5]
|
| 2384 | SlenderGNN: Accurate, Robust, and Interpretable GNN, and the Reasons for its Success | 5.00 | 5.00 | 0.00 | [6, 6, 5, 3]
|
| 2385 | FedFA: Federated Feature Augmentation | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 2386 | Capsa: A Unified Framework for Quantifying Risk in Deep Neural Networks | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2387 | Show and Write: Entity-aware Article Generation with Image Information | 4.83 | 4.83 | 0.00 | [5, 6, 3, 6, 6, 3]
|
| 2388 | Noise$^+$2Noise: Co-taught De-noising Autoencoders for Time-Series Data | 5.00 | 5.00 | 0.00 | [3, 5, 6, 6]
|
| 2389 | Adversarial Representation Learning for Canonical Correlation Analysis | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 2390 | BYPASSING THE STABILITY-PLASTICITY TRADEOFF TO REDUCE PREDICTIVE CHURN | 4.00 | 4.80 | 0.80 | [3, 5, 3, 8, 5]
|
| 2391 | Neural Implicit Manifold Learning for Topology-Aware Generative Modelling | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 2392 | LT-SNN: Self-Adaptive Spiking Neural Network for Event-based Classification and Object Detection | 5.40 | 5.40 | 0.00 | [3, 8, 3, 5, 8]
|
| 2393 | Characterizing neural representation of cognitively-inspired deep RL agents during an evidence accumulation task | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 2394 | Epistemological Bias As a Means for the Automated Detection of Injustices in News Media | 4.75 | 4.75 | 0.00 | [5, 3, 8, 3]
|
| 2395 | Neural Constraint Inference: Inferring Energy Constraints in Interacting Systems | 5.00 | 4.75 | -0.25 | [5, 6, 3, 5]
|
| 2396 | Self-supervised Continual Learning based on Batch-mode Novelty Detection | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2397 | Stable Optimization of Gaussian Likelihoods | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 2398 | Break the Wall Between Homophily and Heterophily for Graph Representation Learning | 2.33 | 2.33 | 0.00 | [1, 3, 3]
|
| 2399 | Representing Latent Dimensions Using Compressed Number Lines | 3.00 | 3.75 | 0.75 | [6, 3, 5, 1]
|
| 2400 | Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance | 4.25 | 4.25 | 0.00 | [3, 3, 5, 6]
|
| 2401 | Cortically motivated recurrence enables task extrapolation | 5.00 | 5.00 | 0.00 | [6, 3, 5, 6]
|
| 2402 | Learning Object-Centric Dynamic Modes from Video and Emerging Properties | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 2403 | Is Adversarial Training Really a Silver Bullet for Mitigating Data Poisoning? | 6.00 | 6.00 | 0.00 | [5, 10, 6, 3]
|
| 2404 | Offline Congestion Games: How Feedback Type Affects Data Coverage Requirement | 6.75 | 6.75 | 0.00 | [5, 8, 6, 8]
|
| 2405 | Learning with Stochastic Orders | 6.75 | 6.75 | 0.00 | [8, 5, 6, 8]
|
| 2406 | A Deep Reinforcement Learning Approach for Finding Non-Exploitable Strategies in Two-Player Atari Games | 3.50 | 3.50 | 0.00 | [3, 5, 5, 1]
|
| 2407 | MEDFAIR: BENCHMARKING FAIRNESS FOR MEDICAL IMAGEING | 6.00 | 6.75 | 0.75 | [8, 8, 5, 6]
|
| 2408 | Does Decentralized Learning with Non-IID Unlabeled Data Benefit from Self Supervision? | 6.00 | 6.00 | 0.00 | [6, 5, 5, 8]
|
| 2409 | Polarity is all you need to learn and transfer faster | 5.25 | 5.25 | 0.00 | [8, 5, 5, 3]
|
| 2410 | On the Geometry of Reinforcement Learning in Continuous State and Action Spaces | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 2411 | Deep Invertible Approximation of Topologically Rich Maps between Manifolds | 3.00 | 3.00 | 0.00 | [3, 5, 1, 3]
|
| 2412 | Malign Overfitting: Interpolation and Invariance are Fundamentally at Odds | 5.60 | 6.00 | 0.40 | [6, 5, 6, 5, 8]
|
| 2413 | Exploring and Exploiting Decision Boundary Dynamics for Adversarial Robustness | 6.00 | 6.80 | 0.80 | [6, 8, 10, 5, 5]
|
| 2414 | Countering the Attack-Defense Complexity Gap for Robust Classifiers | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 2415 | Evaluating Counterfactual Explainers | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 2416 | SMART: Sentences as Basic Units for Text Evaluation | 6.00 | 6.25 | 0.25 | [6, 5, 8, 6]
|
| 2417 | A Reinforcement Learning Approach to Estimating Long-term Treatment Effects | 4.25 | 4.75 | 0.50 | [5, 5, 3, 6]
|
| 2418 | Sample-Efficient Reinforcement Learning by Breaking the Replay Ratio Barrier | 6.67 | 8.00 | 1.33 | [8, 8, 8]
|
| 2419 | Explaining Image Classification through Knowledge-aware Neuron Interpretation | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2420 | Tier Balancing: Towards Dynamic Fairness over Underlying Causal Factors | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 2421 | Anamnesic Neural Differential Equations with Orthogonal Polynomial Projections | 4.33 | 4.33 | 0.00 | [6, 6, 1]
|
| 2422 | Neural Design for Genetic Perturbation Experiments | 6.00 | 6.25 | 0.25 | [5, 6, 8, 6]
|
| 2423 | Conceptual SCAN: Learning With and About Rules | 4.67 | 4.25 | -0.42 | [3, 3, 6, 5]
|
| 2424 | An alternative approach to train neural networks using monotone variational inequality | 4.80 | 4.80 | 0.00 | [5, 3, 5, 5, 6]
|
| 2425 | Have Missing Data? Make It Miss More! Imputing Tabular Data with Masked Autoencoding | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 2426 | Invertible normalizing flow neural networks by JKO scheme | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 2427 | Unsupervised learning of features and object boundaries from local prediction | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 2428 | Towards Causal Concepts for Explaining Language Models | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 2429 | TRIDE: A Temporal, Robust, and Informative Data Augmentation Framework for Disease Progression Modeling | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2430 | Multi-Segmental Informational Coding for Self-Supervised Representation Learning | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 2431 | Rule-based policy regularization for reinforcement learning-based building control | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 2432 | Neural Graphical Models | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2433 | AUGMENTING ZERO-SHOT DENSE RETRIEVERS WITH PLUG-IN MIXTURE-OF-MEMORIES | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 2434 | Efficient Discrete Multi Marginal Optimal Transport Regularization | 6.33 | 6.33 | 0.00 | [6, 8, 5]
|
| 2435 | AutoTransfer: AutoML with Knowledge Transfer - An Application to Graph Neural Networks | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 2436 | Meta-learning from demonstrations improves compositional generalization | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2437 | Deep Dependency Networks for Action Classification in Video | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 2438 | Temporal Dependencies in Feature Importance for Time Series Prediction | 7.33 | 7.33 | 0.00 | [8, 8, 6]
|
| 2439 | Peaks2Image: Reconstructing fMRI Statistical Maps from Peaks | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 2440 | Bridging the Gap between Semi-supervised and Supervised Continual Learning via Data Programming | 5.75 | 5.75 | 0.00 | [5, 5, 8, 5]
|
| 2441 | Characterizing the spectrum of the NTK via a power series expansion | 5.67 | 5.67 | 0.00 | [8, 6, 3]
|
| 2442 | Unmasking the Lottery Ticket Hypothesis: What"s Encoded in a Winning Ticket"s Mask? | 7.50 | 8.00 | 0.50 | [6, 10, 8, 8]
|
| 2443 | A critical look at evaluation of GNNs under heterophily: Are we really making progress? | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 2444 | Dr.Spider: A Diagnostic Evaluation Benchmark towards Text-to-SQL Robustness | 8.00 | 8.00 | 0.00 | [8, 8, 8, 8]
|
| 2445 | A Non-monotonic Self-terminating Language Model | 6.50 | 7.00 | 0.50 | [8, 6, 6, 8]
|
| 2446 | Counterfactual Memorization in Neural Language Models | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 2447 | TT-Rules: Extracting & Optimizing Exact Rules of a CNN-Based Model - Application to Fairness | 2.50 | 2.50 | 0.00 | [3, 1, 3, 3]
|
| 2448 | uGLAD: A deep learning model to recover conditional independence graphs | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 2449 | Quantifying Memorization Across Neural Language Models | 6.00 | 6.00 | 0.00 | [6, 8, 5, 5]
|
| 2450 | Powderworld: A Platform for Understanding Generalization via Rich Task Distributions | 6.75 | 8.00 | 1.25 | [8, 8, 8, 8]
|
| 2451 | Federated Self-supervised Learning for Heterogeneous Clients | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 2452 | ContraSim -- A Similarity Measure Based on Contrastive Learning | 5.00 | 5.00 | 0.00 | [3, 3, 6, 8]
|
| 2453 | Learning to Segment from Noisy Annotations: A Spatial Correction Approach | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 2454 | PointConvFormer: Revenge of the Point-Based Convolution | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2455 | Measuring Forgetting of Memorized Training Examples | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 2456 | Leveraging Human Features at Test-Time | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 2457 | Graduated Non-Convexity for Robust Self-Trained Language Understanding | 4.50 | 4.50 | 0.00 | [3, 6, 6, 3]
|
| 2458 | On the Activation Function Dependence of the Spectral Bias of Neural Networks | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 2459 | MaskViT: Masked Visual Pre-Training for Video Prediction | 6.25 | 7.25 | 1.00 | [5, 8, 8, 8]
|
| 2460 | Text Summarization with Oracle Expectation | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 2461 | MERMADE: $K$-shot Robust Adaptive Mechanism Design via Model-Based Meta-Learning | 4.25 | 4.75 | 0.50 | [6, 3, 5, 5]
|
| 2462 | Continuous-time identification of dynamic state-space models by deep subspace encoding | 5.20 | 5.20 | 0.00 | [5, 5, 3, 8, 5]
|
| 2463 | Waveformer: Linear-Time Attention with Forward and Backward Wavelet Transform | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 2464 | SemSup-XC: Semantic Supervision for Extreme Classification | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 2465 | SaMoE: Parameter Efficient MoE Language Models via Self-Adaptive Expert Combination | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 2466 | How to Train your HIPPO: State Space Models with Generalized Orthogonal Basis Projections | 6.25 | 6.25 | 0.00 | [5, 6, 6, 8]
|
| 2467 | Interpretable Debiasing of Vectorized Language Representations with Iterative Orthogonalization | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 2468 | Communication-Optimal Distributed Graph Clustering under Duplication Models | 3.00 | 3.00 | 0.00 | [5, 3, 1]
|
| 2469 | Unpacking Large Language Models with Conceptual Consistency | 4.25 | 4.25 | 0.00 | [3, 3, 3, 8]
|
| 2470 | Graph in Graph Neural Network | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 2471 | LSTM-BASED-AUTO-BI-LSTM for Remaining Useful Life (RUL) Prediction: the first round of test results | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2472 | Recurrent Real-valued Neural Autoregressive Density Estimator for Online Density Estimation and Classification of Streaming Data | 3.67 | 3.67 | 0.00 | [5, 3, 5, 3, 3, 3]
|
| 2473 | Out-of-Distribution Detection and Selective Generation for Conditional Language Models | 6.67 | 7.33 | 0.67 | [8, 6, 8]
|
| 2474 | Layer Grafted Pre-training: Bridging Contrastive Learning And Masked Image Modeling For Better Representations | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 2475 | Structural Adversarial Objectives for Self-Supervised Representation Learning | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 2476 | VIMA: General Robot Manipulation with Multimodal Prompts | 5.50 | 5.50 | 0.00 | [8, 5, 6, 3]
|
| 2477 | Discovering Latent Knowledge in Language Models Without Supervision | 5.00 | 6.00 | 1.00 | [6, 6, 6, 6]
|
| 2478 | ModReduce: A Multi-Knowledge Distillation Framework with Online Learning | 3.00 | 3.00 | 0.00 | [1, 3, 5, 3]
|
| 2479 | Prefix Conditioning Unifies Language and Label Supervision | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 2480 | Defending against Reconstruction attacks using Rényi Differential Privacy | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 2481 | Diffusion Adversarial Representation Learning for Self-supervised Vessel Segmentation | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 2482 | Reconciling Security and Communication Efficiency in Federated Learning | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 2483 | Semantic Image Manipulation with Background-guided Internal Learning | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 2484 | Pretraining the Vision Transformer using self-supervised methods for vision based Deep Reinforcement Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3, 3]
|
| 2485 | Noise Injection Node Regularization for Robust Learning | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 2486 | Q-Ensemble for Offline RL: Don"t Scale the Ensemble, Scale the Batch Size | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 2487 | Efficient Edge Inference by Selective Query | 5.75 | 5.75 | 0.00 | [3, 6, 8, 6]
|
| 2488 | Learning Intuitive Policies Using Action Features | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 2489 | Differentially Private $L_2$-Heavy Hitters in the Sliding Window Model | 6.50 | 6.50 | 0.00 | [5, 5, 8, 8]
|
| 2490 | Scaling Convex Neural Networks with Burer-Monteiro Factorization | 5.40 | 5.40 | 0.00 | [5, 3, 8, 5, 6]
|
| 2491 | Human-level Atari 200x faster | 6.33 | 6.33 | 0.00 | [8, 8, 3]
|
| 2492 | Wide Graph Neural Network | 4.50 | 4.50 | 0.00 | [6, 1, 5, 6]
|
| 2493 | Taming the Long Tail of Deep Probabilistic Forecasting | 4.75 | 4.75 | 0.00 | [5, 6, 3, 5]
|
| 2494 | Approximate Conditional Coverage via Neural Model Approximations | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2495 | AUTOJOIN: EFFICIENT ADVERSARIAL TRAINING FOR ROBUST MANEUVERING VIA DENOISING AUTOEN- CODER AND JOINT LEARNING | 5.50 | 5.50 | 0.00 | [5, 6, 6, 5]
|
| 2496 | Private Data Stream Analysis for Universal Symmetric Norm Estimation | 5.00 | 5.00 | 0.00 | [3, 6, 8, 3]
|
| 2497 | StarGraph: Knowledge Representation Learning based on Incomplete Two-hop Subgraph | 4.25 | 5.00 | 0.75 | [3, 8, 6, 3]
|
| 2498 | Temporal Domain Generalization with Drift-Aware Dynamic Neural Networks | 6.33 | 6.33 | 0.00 | [5, 8, 6]
|
| 2499 | Leveraging Incompatibility to Defend Against Backdoor Poisoning | 5.00 | 5.00 | 0.00 | [6, 3, 5, 6]
|
| 2500 | Towards Representative Subset Selection for Self-Supervised Speech Recognition | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2501 | Enforcing Hard Constraints with Soft Barriers: Safe Reinforcement Learning in Unknown Stochastic Environments | 5.75 | 6.00 | 0.25 | [5, 5, 8, 6]
|
| 2502 | Integrating Episodic and Global Novelty Bonuses for Efficient Exploration | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 2503 | A Unified Approach to Reinforcement Learning, Quantal Response Equilibria, and Two-Player Zero-Sum Games | 6.00 | 6.00 | 0.00 | [3, 8, 8, 5]
|
| 2504 | Dynamics-aware Skill Generation from Behaviourally Diverse Demonstrations | 4.50 | 4.50 | 0.00 | [3, 6, 3, 6]
|
| 2505 | DiP-GNN: Discriminative Pre-Training of Graph Neural Networks | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 2506 | Learning to Act through Activation Function Optimization in Random Networks | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 2507 | Safer Reinforcement Learning with Counterexample-guided Offline Training | 3.75 | 3.75 | 0.00 | [6, 3, 3, 3]
|
| 2508 | Pitfalls of Gaussians as a noise distribution in NCE | 6.60 | 7.00 | 0.40 | [8, 5, 8, 6, 8]
|
| 2509 | Scaling Laws for a Multi-Agent Reinforcement Learning Model | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 2510 | Risk Control for Online Learning Models | 4.75 | 4.75 | 0.00 | [3, 5, 8, 3]
|
| 2511 | Generative Adversarial Training for Neural Combinatorial Optimization Models | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 2512 | Federated Learning with Openset Noisy Labels | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 2513 | Perfectly Secure Steganography Using Minimum Entropy Coupling | 5.25 | 5.25 | 0.00 | [6, 1, 8, 6]
|
| 2514 | The power of choices in decision tree learning | 5.50 | 5.50 | 0.00 | [5, 8, 3, 6]
|
| 2515 | Identifiability of Label Noise Transition Matrix | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 2516 | Learning from Others: Similarity-based Regularization for Mitigating Artifacts | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 2517 | Calibrating Transformers via Sparse Gaussian Processes | 4.50 | 5.00 | 0.50 | [8, 3, 6, 3]
|
| 2518 | Representation Learning via Consistent Assignment of Views over Random Partitions | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2519 | Model Transferability with Responsive Decision Subjects | 5.75 | 5.75 | 0.00 | [8, 5, 5, 5]
|
| 2520 | Red PANDA: Disambiguating Anomaly Detection by Removing Nuisance Factors | 4.00 | 4.00 | 0.00 | [3, 6, 1, 6]
|
| 2521 | Abstracting Imperfect Information Away from Two-Player Zero-Sum Games | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 2522 | Is Attention All That NeRF Needs? | 6.75 | 6.75 | 0.00 | [8, 5, 6, 8]
|
| 2523 | STOCHASTIC NO-REGRET LEARNING FOR GENERAL GAMES WITH VARIANCE REDUCTION | 7.00 | 7.00 | 0.00 | [6, 8, 6, 8]
|
| 2524 | The Dark Side of AutoML: Towards Architectural Backdoor Search | 6.00 | 6.00 | 0.00 | [6, 5, 5, 8]
|
| 2525 | Generalization and Estimation Error Bounds for Model-based Neural Networks | 6.25 | 7.00 | 0.75 | [6, 6, 8, 8]
|
| 2526 | Isometric Representations in Neural Networks Improve Robustness | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2527 | Memory-efficient Trajectory Matching for Scalable Dataset Distillation | 4.25 | 4.25 | 0.00 | [5, 3, 6, 3]
|
| 2528 | TAN without a burn: Scaling laws of DP-SGD | 7.00 | 7.00 | 0.00 | [6, 6, 8, 8]
|
| 2529 | A sampling framework for value-based reinforcement learning | 2.50 | 2.50 | 0.00 | [3, 3, 3, 1]
|
| 2530 | Enhancing Cross-Category Learning in Recommendation Systems with Multi-Layer Embedding Training | 3.75 | 3.75 | 0.00 | [3, 3, 3, 6]
|
| 2531 | StructViT: Learning Correlation Structures for Vision Transformers | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 2532 | The Curse of Low Task Diversity: On the Failure of Transfer Learning to Outperform MAML and their Empirical Equivalence | 3.25 | 3.25 | 0.00 | [6, 3, 1, 3]
|
| 2533 | Bi-Stride Multi-Scale Graph Neural Network for Mesh-Based Physical Simulation | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 2534 | Spatially Resolved Temporal Networks: Online Unsupervised Representation Learning of High Frequency Time Series | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 2535 | ChordMixer: A Scalable Neural Attention Model for Sequences with Different Length | 5.67 | 5.67 | 0.00 | [8, 3, 6]
|
| 2536 | Boosting Adversarial Transferability using Dynamic Cues | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 2537 | Taming Policy Constrained Offline Reinforcement Learning for Non-expert Demonstrations | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 2538 | Static Prediction of Runtime Errors by Learning to Execute Programs with External Resource Descriptions | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 2539 | Attentional Context Alignment for Multimodal Sequential Learning | 4.25 | 4.25 | 0.00 | [6, 3, 3, 5]
|
| 2540 | Matching receptor to odorant with protein language and graph neural networks | 6.33 | 6.33 | 0.00 | [5, 8, 6]
|
| 2541 | REAP: A Large-Scale Realistic Adversarial Patch Benchmark | 4.25 | 4.25 | 0.00 | [3, 3, 5, 6]
|
| 2542 | How does overparametrization affect performance on minority groups? | 4.33 | 3.80 | -0.53 | [3, 3, 5, 3, 5]
|
| 2543 | Federated Training of Dual Encoding Models on Small Non-IID Client Datasets | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 2544 | Offline Policy Comparison with Confidence: Benchmarks and Baselines | 5.00 | 5.00 | 0.00 | [3, 5, 6, 6]
|
| 2545 | PRANC: Pseudo RAndom Networks for Compacting deep models | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2546 | SGDA with shuffling: faster convergence for nonconvex-PŁ minimax optimization | 6.25 | 6.25 | 0.00 | [6, 8, 5, 6]
|
| 2547 | NTFields: Neural Time Fields for Physics-Informed Robot Motion Planning | 5.75 | 6.50 | 0.75 | [6, 8, 6, 6]
|
| 2548 | MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 2549 | Biological connectomes as a representation for the architecture of artificial neural networks | 3.50 | 3.50 | 0.00 | [3, 1, 5, 5]
|
| 2550 | MSQ-BioBERT: Ambiguity Resolution to Enhance BioBERT Medical Question-Answering | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 2551 | Part-Based Models Improve Adversarial Robustness | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 2552 | Asymmetric Certified Robustness via Feature-Convex Neural Networks | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 2553 | PGrad: Learning Principal Gradients For Domain Generalization | 6.33 | 6.33 | 0.00 | [8, 3, 8]
|
| 2554 | Learning Efficient Models From Few Labels By Distillation From Multiple Tasks | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 2555 | Extremely Simple Activation Shaping for Out-of-Distribution Detection | 5.50 | 5.50 | 0.00 | [3, 6, 8, 5]
|
| 2556 | ZiCo: Zero-shot NAS via inverse Coefficient of Variation on Gradients | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 2557 | Statistical Guarantees for Consensus Clustering | 6.33 | 6.33 | 0.00 | [6, 5, 8]
|
| 2558 | Perceive, Ground, Reason, and Act: A Benchmark for General-purpose Visual Representation | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 2559 | Expressive Monotonic Neural Networks | 6.33 | 6.33 | 0.00 | [3, 8, 8]
|
| 2560 | Active Image Indexing | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 2561 | Towards Explaining Distribution Shifts | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 2562 | Perturbation Analysis of Neural Collapse | 4.75 | 4.75 | 0.00 | [5, 6, 3, 5]
|
| 2563 | Learning Simultaneous Navigation and Construction in Grid Worlds | 5.75 | 6.75 | 1.00 | [8, 8, 6, 5]
|
| 2564 | Learning to CROSS exchange to solve min-max vehicle routing problems | 6.33 | 6.33 | 0.00 | [8, 8, 3]
|
| 2565 | PandA: Unsupervised Learning of Parts and Appearances in the Feature Maps of GANs | 5.75 | 5.75 | 0.00 | [6, 6, 6, 5]
|
| 2566 | Compositional Law Parsing with Latent Random Functions | 6.20 | 6.20 | 0.00 | [6, 6, 5, 6, 8]
|
| 2567 | Pink Noise Is All You Need: Colored Noise Exploration in Deep Reinforcement Learning | 7.00 | 8.00 | 1.00 | [8, 8, 8]
|
| 2568 | LilNetX: Lightweight Networks with EXtreme Model Compression and Structured Sparsification | 6.25 | 6.25 | 0.00 | [8, 6, 5, 6]
|
| 2569 | First-order Context-based Adaptation for Generalizing to New Dynamical Systems | 6.00 | 6.00 | 0.00 | [5, 5, 8]
|
| 2570 | CBP-QSNN: Spiking Neural Networks Quantized Using Constrained Backpropagation | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2571 | Leveraging the Third Dimension in Contrastive Learning | 4.75 | 4.75 | 0.00 | [3, 5, 5, 6]
|
| 2572 | O-ViT: Orthogonal Vision Transformer | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2573 | STaSy: Score-based Tabular data Synthesis | 7.25 | 7.25 | 0.00 | [8, 8, 8, 5]
|
| 2574 | REDUCING OVERSMOOTHING IN GRAPH NEURAL NETWORKS BY CHANGING THE ACTIVATION FUNCTION | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 2575 | Disentangled (Un)Controllable Features | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2576 | Visual Prompt Tuning For Test-time Domain Adaptation | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 2577 | Mitigating Dataset Bias by Using Per-Sample Gradient | 6.33 | 7.33 | 1.00 | [6, 8, 8]
|
| 2578 | CAMA: A New Framework for Safe Multi-Agent Reinforcement Learning Using Constraint Augmentation | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 2579 | CWATR: Generating Richer Captions with Object Attributes | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2580 | Internal Purity: A Differential Entropy based Internal Validation Index for Clustering Validation | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 2581 | Task Regularized Hybrid Knowledge Distillation For Continual Object Detection | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 2582 | Efficient Model Updates for Approximate Unlearning of Graph-Structured Data | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 2583 | Risk-aware Bayesian RL for Cautious Exploration | 4.80 | 4.80 | 0.00 | [3, 5, 10, 3, 3]
|
| 2584 | Change Detection for bi-temporal images classification based on Siamese Variational AutoEncoder and Transfer Learning | 2.50 | 2.50 | 0.00 | [3, 3, 1, 3]
|
| 2585 | G-CEALS: Gaussian Cluster Embedding in Autoencoder Latent Space for Tabular Data Representation | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 2586 | Learning Top-k Classification with Label Ranking | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 2587 | QUANTIZATION AWARE FACTORIZATION FOR DEEP NEURAL NETWORK COMPRESSION | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2588 | Populating memory in Continual Learning with Consistency Aware Sampling | 3.75 | 3.75 | 0.00 | [6, 3, 3, 3]
|
| 2589 | Fairness of Federated Learning with Dynamic Participants | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2590 | A Unified Algebraic Perspective on Lipschitz Neural Networks | 7.00 | 7.50 | 0.50 | [8, 8, 8, 6]
|
| 2591 | AudioGen: Textually Guided Audio Generation | 8.00 | 8.00 | 0.00 | [8, 8, 8, 8]
|
| 2592 | Faster Reinforcement Learning with Value Target Lower Bounding | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 2593 | Hebbian and Gradient-based Plasticity Enables Robust Memory and Rapid Learning in RNNs | 5.50 | 5.75 | 0.25 | [6, 5, 6, 6]
|
| 2594 | Towards Minimax Optimal Reward-free Reinforcement Learning in Linear MDPs | 5.75 | 6.25 | 0.50 | [6, 6, 5, 8]
|
| 2595 | PromptSum: Planning with Mixed Prompts for Parameter-Efficient Controllable Abstractive Summarization | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 2596 | Context and History Aware Other-Shaping | 3.00 | 4.00 | 1.00 | [5, 5, 3, 3]
|
| 2597 | ReD-GCN: Revisit the Depth of Graph Convolutional Network | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 2598 | The Influence of Learning Rule on Representation Dynamics in Wide Neural Networks | 6.75 | 8.00 | 1.25 | [8, 8, 8, 8]
|
| 2599 | Multiple Modes for Continual Learning | 6.33 | 5.50 | -0.83 | [3, 10, 6, 3]
|
| 2600 | A Theory of Equivalence-Preserving Program Embeddings | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 2601 | Multimodal Open-Vocabulary Video Classification via Vision and Language Models | 4.50 | 4.50 | 0.00 | [3, 3, 6, 6]
|
| 2602 | On the Data-Efficiency with Contrastive Image Transformation in Reinforcement Learning | 6.00 | 6.00 | 0.00 | [8, 5, 5, 6]
|
| 2603 | Energy-based Out-of-Distribution Detection for Graph Neural Networks | 6.00 | 6.75 | 0.75 | [6, 8, 5, 8]
|
| 2604 | Theoretical Characterization of Neural Network Generalization with Group Imbalance | 6.60 | 6.60 | 0.00 | [5, 5, 8, 5, 10]
|
| 2605 | SDMuse: Stochastic Differential Music Editing and Generation via Hybrid Representation | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2606 | Masked Autoencoders Enable Efficient Knowledge Distillers | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2607 | Formal Interpretability with Merlin-Arthur Classifiers | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 2608 | Quasi-optimal Learning with Continuous Treatments | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 2609 | Generalization Bounds for Federated Learning: Fast Rates, Unparticipating Clients and Unbounded Losses | 5.83 | 5.71 | -0.12 | [5, 5, 8, 6, 5, 6, 5]
|
| 2610 | Contrastive Unsupervised Learning of World Model with Invariant Causal Features | 3.25 | 3.25 | 0.00 | [6, 3, 1, 3]
|
| 2611 | GOING BEYOND 1-WL EXPRESSIVE POWER WITH 1-LAYER GRAPH NEURAL NETWORKS | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2612 | System Identification as a Reinforcement Learning Problem | 3.75 | 3.75 | 0.00 | [6, 1, 3, 5]
|
| 2613 | When to Trust Aggregated Gradients: Addressing Negative Client Sampling in Federated Learning | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 2614 | More ConvNets in the 2020s: Scaling up Kernels Beyond 51x51 using Sparsity | 6.80 | 6.80 | 0.00 | [5, 6, 10, 8, 5]
|
| 2615 | Language-Aware Soft Prompting for Vision & Language Foundation Models | 4.75 | 4.75 | 0.00 | [5, 3, 5, 6]
|
| 2616 | On Structural Expressive Power of Graph Transformers | 5.33 | 5.33 | 0.00 | [3, 5, 8]
|
| 2617 | Projected Latent Distillation for Data-Agnostic Consolidation in Multi-Agent Continual Learning | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 2618 | Few-shot Cross-domain Image Generation via Inference-time Latent-code Learning | 7.50 | 8.00 | 0.50 | [8, 8, 8, 8]
|
| 2619 | RLx2: Training a Sparse Deep Reinforcement Learning Model from Scratch | 6.75 | 6.75 | 0.00 | [8, 8, 6, 5]
|
| 2620 | Black-Box Adversarial Attack Guided by Model Behavior for Programming Pre-trained Language Models | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 2621 | Learning Critically in Federated Learning with Noisy and Heterogeneous Clients | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 2622 | Rethinking Positive Sampling for Contrastive Learning with Kernel | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 2623 | Stationary Deep Reinforcement Learning with Quantum K-spin Hamiltonian Equation | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2624 | Performance Disparities Between Accents in Automatic Speech Recognition | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 2625 | Do Perceptually Aligned Gradients Imply Robustness? | 5.00 | 5.00 | 0.00 | [6, 5, 3, 5, 6]
|
| 2626 | Sparsity May Cry: Let Us Fail (Current) Sparse Neural Networks Together! | 6.75 | 7.25 | 0.50 | [5, 8, 8, 8]
|
| 2627 | Multitask Reinforcement Learning by Optimizing Neural Pathways | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 2628 | Input Perturbation Reduces Exposure Bias in Diffusion Models | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 2629 | Pruning Parameterization with Bi-level Optimization for Efficient Semantic Segmentation on the Edge | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 2630 | How deep convolutional neural networks lose spatial information with training | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 2631 | Which Layer is Learning Faster? A Systematic Exploration of Layer-wise Convergence Rate for Deep Neural Networks | 5.75 | 6.25 | 0.50 | [5, 6, 6, 8]
|
| 2632 | Joint Embedding Self-Supervised Learning in the Kernel Regime | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 2633 | Linear convergence for natural policy gradient with log-linear policy parametrization | 4.60 | 4.60 | 0.00 | [3, 5, 5, 5, 5]
|
| 2634 | A non-asymptotic analysis of oversmoothing in Graph Neural Networks | 5.67 | 5.67 | 0.00 | [3, 6, 8]
|
| 2635 | Class-Incremental Learning with Repetition | 5.67 | 5.67 | 0.00 | [8, 3, 6]
|
| 2636 | Scaleformer: Iterative Multi-scale Refining Transformers for Time Series Forecasting | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 2637 | Theoretical Characterization of How Neural Network Pruning Affects its Generalization | 4.75 | 4.75 | 0.00 | [5, 5, 3, 6]
|
| 2638 | Backdoors Stuck At The Frontdoor: Multi-Agent Backdoor Attacks That Backfire | 3.50 | 3.50 | 0.00 | [3, 5, 5, 1]
|
| 2639 | Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs | 7.50 | 7.50 | 0.00 | [6, 8, 8, 8]
|
| 2640 | Interpolating Compressed Parameter Subspaces | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2641 | Liquid Structural State-Space Models | 6.25 | 6.25 | 0.00 | [8, 6, 8, 3]
|
| 2642 | Equivariant Hypergraph Diffusion Neural Operators | 5.50 | 5.75 | 0.25 | [6, 6, 5, 6]
|
| 2643 | Ollivier-Ricci Curvature for Hypergraphs: A Unified Framework | 6.25 | 6.25 | 0.00 | [6, 5, 8, 6]
|
| 2644 | gGN: learning to represent nodes in directed graphs as low-rank Gaussian distributions | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 2645 | Domain-Unified Prompt Representations for Source-Free Domain Generalization | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 2646 | Biases in Evaluation of Molecular Optimization Methods and Bias Reduction Strategies | 5.50 | 5.75 | 0.25 | [8, 6, 6, 3]
|
| 2647 | Sharper Analysis of Sparsely Activated Wide Neural Networks with Trainable Biases | 5.00 | 5.00 | 0.00 | [6, 6, 5, 3]
|
| 2648 | Hard-Meta-Dataset++: Towards Understanding Few-Shot Performance on Difficult Tasks | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 2649 | REVISITING PRUNING AT INITIALIZATION THROUGH THE LENS OF RAMANUJAN GRAPH | 6.33 | 6.33 | 0.00 | [5, 8, 6]
|
| 2650 | Self-supervised Speech Enhancement using Multi-Modal Data | 4.40 | 4.40 | 0.00 | [5, 3, 6, 5, 3]
|
| 2651 | Sparse MoE with Random Routing as the New Dropout: Training Bigger and Self-Scalable Models | 5.75 | 6.75 | 1.00 | [8, 6, 5, 8]
|
| 2652 | Compositional Semantic Parsing with Large Language Models | 6.00 | 6.00 | 0.00 | [8, 6, 5, 5]
|
| 2653 | TiAda: A Time-scale Adaptive Algorithm For Nonconvex Minimax Optimization | 6.25 | 6.25 | 0.00 | [6, 8, 5, 6]
|
| 2654 | Generalization Properties of Retrieval-based Models | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 2655 | Semi-Variance Reduction for Fair Federated Learning | 5.00 | 5.00 | 0.00 | [3, 6, 5, 6]
|
| 2656 | Multi-Modality Alone is Not Enough: Generating Scene Graphs using Cross-Relation-Modality Tokens | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2657 | FaiREE: fair classification with finite-sample and distribution-free guarantee | 5.25 | 5.50 | 0.25 | [5, 3, 6, 8]
|
| 2658 | Bidirectional global to local attention for deep metric learning. | 3.00 | 3.00 | 0.00 | [3, 1, 5, 3]
|
| 2659 | Deep Evidential Reinforcement Learning for Dynamic Recommendations | 5.33 | 5.33 | 0.00 | [5, 8, 3]
|
| 2660 | Exponential Generalization Bounds with Near-Optimal Rates for $L_q$-Stable Algorithms | 7.60 | 7.60 | 0.00 | [8, 8, 8, 6, 8]
|
| 2661 | Disentangling Learning Representations with Density Estimation | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 2662 | Coarse-to-fine Knowledge Graph Domain Adaptation based on Distantly-supervised Iterative Training | 2.50 | 2.50 | 0.00 | [3, 3, 3, 1]
|
| 2663 | Teacher Guided Training: An Efficient Framework for Knowledge Transfer | 6.25 | 6.25 | 0.00 | [8, 5, 6, 6]
|
| 2664 | Neural Agents Struggle to Take Turns in Bidirectional Emergent Communication | 5.50 | 5.50 | 0.00 | [5, 3, 6, 8]
|
| 2665 | Class Interference of Deep Networks | 3.67 | 3.00 | -0.67 | [1, 5, 3]
|
| 2666 | Observational Robustness and Invariances in Reinforcement Learning via Lexicographic Objectives | 5.50 | 5.67 | 0.17 | [6, 6, 5, 8, 3, 6]
|
| 2667 | SeedGNN: Graph Neural Network for Supervised Seeded Graph Matching | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 2668 | Siamese DETR | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 2669 | Provable Sharpness-Aware Minimization with Adaptive Learning Rate | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 2670 | Prompting GPT-3 To Be Reliable | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 2671 | Contrastive Graph Few-Shot Learning | 4.40 | 4.40 | 0.00 | [3, 5, 3, 5, 6]
|
| 2672 | Domain Generalization in Regression | 3.75 | 3.75 | 0.00 | [3, 3, 6, 3]
|
| 2673 | Adversarial Training of Self-supervised Monocular Depth Estimation against Physical-World Attacks | 6.25 | 6.25 | 0.00 | [6, 6, 5, 8]
|
| 2674 | Sparsity-Constrained Optimal Transport | 7.25 | 7.60 | 0.35 | [6, 6, 8, 8, 10]
|
| 2675 | A Risk-Averse Equilibrium for Multi-Agent Systems | 4.50 | 4.50 | 0.00 | [3, 6, 3, 6]
|
| 2676 | SuperWeight Ensembles: Automated Compositional Parameter Sharing Across Diverse Architechtures | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 2677 | Human alignment of neural network representations | 3.33 | 4.33 | 1.00 | [6, 1, 6]
|
| 2678 | Imitation Learning for Mean Field Games with Correlated Equilibria | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 2679 | EFFECTIVE FREQUENCY-BASED BACKDOOR ATTACKS WITH LOW POISONING RATIOS | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2680 | Turning the Curse of Heterogeneity in Federated Learning into a Blessing for Out-of-Distribution Detection | 5.50 | 5.50 | 0.00 | [8, 5, 3, 6]
|
| 2681 | Clustering and Ordering Variable-Sized Sets: The Catalog Problem | 3.67 | 3.50 | -0.17 | [3, 3, 3, 5]
|
| 2682 | RangeAugment: Efficient Online Augmentation with Range Learning | 4.25 | 4.25 | 0.00 | [8, 3, 3, 3]
|
| 2683 | How Predictors Affect Search Strategies in Neural Architecture Search? | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 2684 | Unbiased Stochastic Proximal Solver for Graph Neural Networks with Equilibrium States | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 2685 | Energy Transformer | 5.80 | 5.80 | 0.00 | [5, 6, 8, 5, 5]
|
| 2686 | Privacy-Preserving Vision Transformer on Permutation-Encrypted Images | 4.25 | 4.25 | 0.00 | [6, 5, 1, 5]
|
| 2687 | Lightweight CNNs Under A Unifying Tensor View | 2.33 | 2.33 | 0.00 | [3, 1, 3]
|
| 2688 | DiGress: Discrete Denoising diffusion for graph generation | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 2689 | Sample Relationships through the Lens of Learning Dynamics with Label Information | 5.80 | 5.80 | 0.00 | [5, 6, 5, 5, 8]
|
| 2690 | Geometric Networks Induced by Energy Constrained Diffusion | 8.00 | 8.00 | 0.00 | [10, 8, 6, 8]
|
| 2691 | Neural Lagrangian Schr\"{o}dinger Bridge: Diffusion Modeling for Population Dynamics | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 2692 | Jump-Start Reinforcement Learning | 5.75 | 5.75 | 0.00 | [3, 6, 8, 6]
|
| 2693 | KerDEQ: Optimization induced Deep Equilibrium models via Gaussian Kernel | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 2694 | AD-NEGF: An End-to-End Differentiable Quantum Transport Simulator for Sensitivity Analysis and Inverse Problems | 4.75 | 4.75 | 0.00 | [5, 3, 5, 6]
|
| 2695 | Incomplete to complete multiphysics forecasting - a hybrid approach for learning unknown phenomena | 5.00 | 5.00 | 0.00 | [3, 8, 6, 3]
|
| 2696 | Bi-Level Dynamic Parameter Sharing among Individuals and Teams for Promoting Collaborations in Multi-Agent Reinforcement Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2697 | TCNL: Transparent and Controllable Network Learning Via Embedding Human-Guided Concepts | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 2698 | How to prepare your task head for finetuning | 5.60 | 5.80 | 0.20 | [6, 6, 5, 6, 6]
|
| 2699 | Gradient-based optimization is not necessary for generalization in neural networks | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 2700 | Uplift Modelling based on Graph Neural Network Combined with Causal Knowledge | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2701 | Sequence to sequence text generation with diffusion models | 5.75 | 5.75 | 0.00 | [8, 6, 6, 3]
|
| 2702 | Rethinking Deep Spiking Neural Networks: A Multi-Layer Perceptron Approach | 3.40 | 3.40 | 0.00 | [3, 3, 3, 3, 5]
|
| 2703 | Collaborative Symmetricity Exploitation for Offline Learning of Hardware Design Solver | 4.75 | 4.75 | 0.00 | [5, 3, 5, 6]
|
| 2704 | From ChebNet to ChebGibbsNet | 3.67 | 3.50 | -0.17 | [3, 3, 3, 5]
|
| 2705 | Policy Expansion for Bridging Offline-to-Online Reinforcement Learning | 4.75 | 4.75 | 0.00 | [5, 6, 3, 5]
|
| 2706 | On The Implicit Bias of Weight Decay in Shallow Univariate ReLU Networks | 5.25 | 5.25 | 0.00 | [5, 5, 3, 8]
|
| 2707 | Mitigating Memorization of Noisy Labels via Regularization between Representations | 5.00 | 5.00 | 0.00 | [5, 8, 3, 3, 6]
|
| 2708 | Graph Neural Networks are Inherently Good Generalizers: Insights by Bridging GNNs and Multi-Layer Perceptrons | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 2709 | Learning Cut Selection for Mixed-Integer Linear Programming via Hierarchical Sequence Model | 6.33 | 6.33 | 0.00 | [6, 8, 5]
|
| 2710 | BSTT: A Bayesian Spatial-Temporal Transformer for Sleep Staging | 5.75 | 5.75 | 0.00 | [5, 5, 5, 8]
|
| 2711 | Self-Guided Noise-Free Data Generation for Efficient Zero-Shot Learning | 6.50 | 6.50 | 0.00 | [5, 8, 8, 5]
|
| 2712 | Beyond re-balancing: distributionally robust augmentation against class-conditional distribution shift in long-tailed recognition | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 2713 | Improving Deep Policy Gradients with Value Function Search | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 2714 | MEDICAL IMAGE UNDERSTANDING WITH PRETRAINED VISION LANGUAGE MODELS: A COMPREHENSIVE STUDY | 6.00 | 7.00 | 1.00 | [6, 8, 8, 6]
|
| 2715 | SPI-GAN: Denoising Diffusion GANs with Straight-Path Interpolations | 5.17 | 5.17 | 0.00 | [6, 3, 6, 8, 3, 5]
|
| 2716 | Temporal Coherent Test Time Optimization for Robust Video Classification | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 2717 | Offline Communication Learning with Multi-source Datasets | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 2718 | A Learning Based Hypothesis Test for Harmful Covariate Shift | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 2719 | Less is More: Rethinking Few-Shot Learning and Recurrent Neural Nets | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2720 | SynMotor: A Benchmark Suite for Object Attribute Regression and Multi-task Learning | 3.00 | 3.00 | 0.00 | [5, 3, 1]
|
| 2721 | Training via Confidence Ranking | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 2722 | Deep Transformers without Shortcuts: Modifying Self-attention for Faithful Signal Propagation | 5.75 | 6.50 | 0.75 | [6, 8, 6, 6]
|
| 2723 | Towards Understanding Robust Memorization in Adversarial Training | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2724 | Self-supervised Geometric Correspondence for Category-level 6D Object Pose Estimation in the Wild | 6.25 | 6.25 | 0.00 | [8, 5, 6, 6]
|
| 2725 | Incorporating Explicit Uncertainty Estimates into Deep Offline Reinforcement Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2726 | Non-parametric Outlier Synthesis | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 2727 | SC2EGSet: StarCraft II Esport Replay and Game-state Dataset | 2.33 | 2.33 | 0.00 | [3, 1, 3]
|
| 2728 | Latent-space disentanglement with untrained generator networks allows to isolate different motion types in video data | 3.75 | 3.75 | 0.00 | [5, 6, 3, 1]
|
| 2729 | FV-MgNet: Fully Connected V-cycle MgNet for Interpretable Time Series Forecasting | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2730 | Prosody-TTS: Self-Supervised Prosody Pretraining with Latent Diffusion For Text-to-Speech | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 2731 | Robust Self-Supervised Learning with Lie Groups | 5.33 | 5.33 | 0.00 | [8, 3, 5]
|
| 2732 | Self-Paced Learning Enhanced Physics-informed Neural Networks for Solving Partial Differential Equations | 2.00 | 2.00 | 0.00 | [1, 3, 3, 1]
|
| 2733 | Moving Beyond Handcrafted Architectures in Self-Supervised Learning | 4.50 | 4.50 | 0.00 | [3, 6, 3, 6]
|
| 2734 | Approximation and non-parametric estimation of functions over high-dimensional spheres via deep ReLU networks | 5.67 | 6.67 | 1.00 | [8, 6, 6]
|
| 2735 | Embedding Fourier for Ultra-High-Definition Low-Light Image Enhancement | 7.00 | 7.00 | 0.00 | [6, 8, 8, 6]
|
| 2736 | Population-Based Reinforcement Learning for Combinatorial Optimization Problems | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 2737 | Adversarial Attack Detection Through Network Transport Dynamics | 6.00 | 6.00 | 0.00 | [5, 5, 8]
|
| 2738 | On the Relationship Between Adversarial Robustness and Decision Region in Deep Neural Networks | 4.50 | 4.75 | 0.25 | [5, 5, 3, 6]
|
| 2739 | Confounder Identification-free Causal Visual Feature Learning | 4.75 | 4.75 | 0.00 | [8, 5, 5, 1]
|
| 2740 | Enhanced Temporal Knowledge Embeddings with Contextualized Language Representations | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 2741 | Learning Adversarial Linear Mixture Markov Decision Processes with Bandit Feedback and Unknown Transition | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 2742 | Weakly Supervised Knowledge Transfer with Probabilistic Logical Reasoning for Object Detection | 5.25 | 6.25 | 1.00 | [5, 6, 8, 6]
|
| 2743 | A Call to Reflect on Evaluation Practices for Failure Detection in Image Classification | 8.00 | 8.67 | 0.67 | [8, 10, 8]
|
| 2744 | Signs in the Lottery: Structural Similarities Between Winning Tickets | 3.00 | 3.00 | 0.00 | [3, 5, 1, 3]
|
| 2745 | Computational Doob h-transforms for Online Filtering of Discretely Observed Diffusions | 4.00 | 4.00 | 0.00 | [5, 1, 5, 5]
|
| 2746 | Adversarial Attack Detection Under Realistic Constraints | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 2747 | Reconciling feature sharing and multiple predictions with MIMO Vision Transformers | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 2748 | A Neural Mean Embedding Approach for Back-door and Front-door Adjustment | 4.75 | 4.75 | 0.00 | [8, 5, 5, 1]
|
| 2749 | Chopping Formers is what you need in Vision | 4.60 | 4.60 | 0.00 | [5, 3, 6, 6, 3]
|
| 2750 | Towards Estimating Transferability using Hard Subsets | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 2751 | Data Pricing Mechanism Based on Property Rights Compensation Distribution | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 2752 | Knowledge-Driven Active Learning | 6.00 | 6.00 | 0.00 | [8, 6, 6, 5, 5]
|
| 2753 | FastDiff 2: Dually Incorporating GANs into Diffusion Models for High-Quality Speech Synthesis | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 2754 | When Neural ODEs meet Neural Operators | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2755 | TranSpeech: Speech-to-Speech Translation With Bilateral Perturbation | 5.67 | 6.33 | 0.67 | [6, 5, 8]
|
| 2756 | D4FT: A Deep Learning Approach to Kohn-Sham Density Functional Theory | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 2757 | FFCV: Accelerating Training by Removing Data Bottlenecks | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 2758 | Warping the Space: Weight Space Rotation for Class-Incremental Few-Shot Learning | 5.50 | 5.50 | 0.00 | [8, 6, 3, 5]
|
| 2759 | Learning to Reason and Act in Cascading Processes | 5.67 | 5.67 | 0.00 | [6, 8, 3]
|
| 2760 | Noether Embeddings: Fast Temporal Association Mining | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 2761 | Searching optimal adjustment features for treatment effect estimation | 2.00 | 2.00 | 0.00 | [1, 1, 3, 3]
|
| 2762 | Over-parameterized Model Optimization with Polyak-{\L}ojasiewicz Condition | 5.25 | 6.00 | 0.75 | [8, 3, 8, 5]
|
| 2763 | Differentially private Bias-Term Only Fine-tuning of Foundation Models | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 2764 | Jointly Learning Visual and Auditory Speech Representations from Raw Data | 5.50 | 6.25 | 0.75 | [6, 6, 5, 8]
|
| 2765 | Diminishing Return of Value Expansion Methods in Model-Based Reinforcement Learning | 5.75 | 5.75 | 0.00 | [5, 5, 8, 5]
|
| 2766 | Differentially Private Optimization on Large Model at Small Cost | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 2767 | Universal Graph Neural Networks without Message Passing | 2.80 | 2.80 | 0.00 | [1, 1, 6, 5, 1]
|
| 2768 | CLIP-ViP: Adapting Pre-trained Image-Text Model to Video-Language Alignment | 6.00 | 6.00 | 0.00 | [6, 8, 6, 5, 5]
|
| 2769 | Pre-training via Denoising for Molecular Property Prediction | 7.33 | 7.33 | 0.00 | [8, 8, 6]
|
| 2770 | Equivariant Energy-Guided SDE for Inverse Molecular Design | 5.75 | 6.00 | 0.25 | [5, 6, 5, 8]
|
| 2771 | Contrastive Value Learning: Implicit Models for Simple Offline RL | 5.33 | 5.33 | 0.00 | [5, 8, 3]
|
| 2772 | CLIPPING: Distilling CLIP-based Models for Video-Language Understanding | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 2773 | To be private and robust: Differentially Private Optimizers Can Learn Adversarially Robust Models | 3.00 | 3.00 | 0.00 | [3, 3, 1, 3, 5]
|
| 2774 | Vectorial Graph Convolutional Networks | 1.67 | 1.67 | 0.00 | [1, 1, 3]
|
| 2775 | Traversing Between Modes in Function Space for Fast Ensembling | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 2776 | Poisson Process for Bayesian Optimization | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 2777 | DPMAC: Differentially Private Communication for Cooperative Multi-Agent Reinforcement Learning | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 2778 | $Q$-learning with regularization converges with non-linear non-stationary features | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 2779 | Polite Teacher: Semi-Supervised Instance Segmentation with Mutual Learning and Pseudo-Label Thresholding | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2780 | Reducing Forgetting In Federated Learning with Truncated Cross-Entropy | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2781 | On the Convergence and Calibration of Deep Learning with Differential Privacy | 4.25 | 4.00 | -0.25 | [3, 3, 3, 6, 5]
|
| 2782 | On the Feasibility of Cross-Task Transfer with Model-Based Reinforcement Learning | 5.50 | 5.75 | 0.25 | [6, 6, 6, 5]
|
| 2783 | Fast and Precise: Adjusting Planning Horizon with Adaptive Subgoal Search | 6.75 | 6.75 | 0.00 | [8, 6, 5, 8]
|
| 2784 | A Simple Yet Powerful Deep Active Learning With Snapshots Ensembles | 6.25 | 6.25 | 0.00 | [3, 8, 6, 8]
|
| 2785 | Normalizing Flows for Interventional Density Estimation | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 2786 | Backdoor or Feature? A New Perspective on Data Poisoning | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 2787 | A Curriculum Perspective to Robust Loss Functions | 5.25 | 5.25 | 0.00 | [6, 6, 6, 3]
|
| 2788 | Decoupled Training for Long-Tailed Classification With Stochastic Representations | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 2789 | IT-NAS: Integrating Lite-Transformer into NAS for Architecture Seletion | 5.25 | 5.25 | 0.00 | [6, 6, 3, 6]
|
| 2790 | Fine-Grained Source Code Vulnerability Detection via Graph Neural Networks | 3.00 | 3.00 | 0.00 | [3, 5, 3, 1]
|
| 2791 | Reduce, Reuse, Recycle: Compositional Generation with Energy-Based Diffusion Models and MCMC | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 2792 | Randomized Adversarial Style Perturbations for Domain Generalization | 4.75 | 4.75 | 0.00 | [5, 5, 3, 6]
|
| 2793 | Martingale Posterior Neural Processes | 8.00 | 8.67 | 0.67 | [10, 8, 8]
|
| 2794 | GuoFeng: A Discourse-aware Evaluation Benchmark for Language Understanding, Translation and Generation | 5.33 | 5.33 | 0.00 | [5, 3, 8]
|
| 2795 | Multi-View Independent Component Analysis with Shared and Individual Sources | 4.75 | 4.75 | 0.00 | [5, 3, 8, 3]
|
| 2796 | Centralized Training with Hybrid Execution in Multi-Agent Reinforcement Learning | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 2797 | Towards Open Temporal Graph Neural Networks | 6.25 | 6.50 | 0.25 | [8, 6, 6, 6]
|
| 2798 | FedMAE: Federated Self-Supervised Learning with One-Block Masked Auto-Encoder | 3.75 | 3.75 | 0.00 | [3, 3, 6, 3]
|
| 2799 | Learning Discriminative Representations for Chromosome Classification with Small Datasets | 1.67 | 1.67 | 0.00 | [3, 1, 1]
|
| 2800 | APLA: Class-imbalanced Semi-supervised Learning with Adapative Pseudo-labeling and Loss Adjustment | 3.00 | 3.00 | 0.00 | [5, 3, 1]
|
| 2801 | Label-Efficient Online Continual Object Detection in Streaming Video | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 2802 | ViewCo: Discovering Text-Supervised Segmentation Masks via Multi-View Semantic Consistency | 6.33 | 5.50 | -0.83 | [3, 3, 8, 8]
|
| 2803 | Simplicity bias in $1$-hidden layer neural networks | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 2804 | FedEED: Efficient Federated Distillation with Ensemble of Aggregated Models | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 2805 | Critical Batch Size Minimizes Stochastic First-Order Oracle Complexity of Deep Learning Optimizer using Hyperparameters Close to One | 4.25 | 4.75 | 0.50 | [3, 3, 5, 8]
|
| 2806 | Jointist: Simultaneous Improvement of Multi-instrument Transcription and Music Source Separation via Joint Training | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 2807 | Where prior learning can and can"t work in unsupervised inverse problems | 4.50 | 4.50 | 0.00 | [3, 3, 6, 6]
|
| 2808 | When are smooth-ReLUs ReLU-like? | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 2809 | Hypernetwork approach to Bayesian MAML | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2810 | SpectraNet: multivariate forecasting and imputation under distribution shifts and missing data | 5.33 | 5.33 | 0.00 | [3, 5, 8]
|
| 2811 | An Evolutionary Approach to Dynamic Introduction of Tasks in Large-scale Multitask Learning Systems | 4.50 | 4.50 | 0.00 | [5, 6, 6, 1]
|
| 2812 | Uncertainty and Traffic Light Aware Pedestrian Crossing Intention Prediction | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 2813 | Benchmarking Constraint Inference in Inverse Reinforcement Learning | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 2814 | Forward and Backward Lifelong Learning with Time-dependent Tasks | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 2815 | Memory Gym: Partially Observable Challenges to Memory-Based Agents | 5.25 | 5.25 | 0.00 | [3, 5, 8, 5]
|
| 2816 | Token-level Fitting Issues of Seq2seq Models | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 2817 | Worst-case Few-shot Evaluation: Are Neural Networks Robust Few-shot Learners? | 3.67 | 3.67 | 0.00 | [5, 5, 1]
|
| 2818 | Learning Sampling Policy to Achieve Fewer Queries for Zeroth-Order Optimization | 3.75 | 3.75 | 0.00 | [1, 3, 6, 5]
|
| 2819 | Discovering Policies with DOMiNO | 5.50 | 6.00 | 0.50 | [6, 6, 6, 6]
|
| 2820 | SpeedyZero: Mastering Atari with Limited Data and Time | 4.00 | 5.67 | 1.67 | [6, 6, 5]
|
| 2821 | HT-Net: Hierarchical Transformer based Operator Learning Model for Multiscale PDEs | 7.00 | 7.00 | 0.00 | [5, 8, 10, 5]
|
| 2822 | Multi-Agent Multi-Game Entity Transformer | 4.75 | 5.50 | 0.75 | [5, 6, 5, 6]
|
| 2823 | On the Convergence of Gradient Flow on Multi-layer Linear Models | 5.67 | 5.67 | 0.00 | [3, 6, 8]
|
| 2824 | Variational Counterfactual Prediction under Runtime Domain Corruption | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 2825 | Neural Architecture Design and Robustness: A Dataset | 6.33 | 6.67 | 0.33 | [6, 8, 6]
|
| 2826 | Does Deep Learning Learn to Abstract? A Systematic Probing Framework | 6.75 | 7.75 | 1.00 | [8, 8, 5, 10]
|
| 2827 | Learning to mine approximate network motifs | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 2828 | Automatic Clipping: Differentially Private Deep Learning Made Easier and Stronger | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 2829 | Trust Your $\nabla$: Gradient-based Intervention Targeting for Causal Discovery | 4.33 | 4.50 | 0.17 | [5, 3, 5, 5]
|
| 2830 | Improving Out-of-distribution Generalization with Indirection Representations | 5.50 | 5.75 | 0.25 | [8, 3, 6, 6]
|
| 2831 | Accelerating Guided Diffusion Sampling with Splitting Numerical Methods | 5.00 | 5.00 | 0.00 | [6, 3, 6, 5]
|
| 2832 | RealSinger: Ultra-Realistic Singing Voice Generation via Stochastic Differential Equations | 4.75 | 4.75 | 0.00 | [5, 8, 3, 3]
|
| 2833 | Homeomorphism Alignment in Two Spaces for Unsupervised Domain Adaptation | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 2834 | Demystifying Approximate RL with $\epsilon$-greedy Exploration: A Differential Inclusion View | 5.75 | 5.75 | 0.00 | [5, 5, 5, 8]
|
| 2835 | Batch Multivalid Conformal Prediction | 6.25 | 6.25 | 0.00 | [5, 6, 6, 8]
|
| 2836 | Leveraging Online Semantic Point Fusion for 3D-Aware Object Goal Navigation | 3.67 | 3.67 | 0.00 | [1, 5, 5]
|
| 2837 | Transferring Pretrained Diffusion Probabilistic Models | 6.00 | 6.00 | 0.00 | [8, 6, 5, 5]
|
| 2838 | ELBO-ing Stein Mixtures | 4.67 | 4.67 | 0.00 | [8, 3, 3]
|
| 2839 | Source-Target Coordinated Training with Multi-head Hybrid-Attention for Domain Adaptive Semantic Segmentation | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 2840 | On the Role of Self-supervision in Deep Multi-view Clustering | 4.75 | 4.75 | 0.00 | [3, 5, 8, 3]
|
| 2841 | Schedule-Robust Online Continual Learning | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 2842 | On the Usefulness of Embeddings, Clusters and Strings for Text Generation Evaluation | 7.00 | 7.00 | 0.00 | [6, 8, 8, 6]
|
| 2843 | A Simple, Yet Effective Approach to Finding Biases in Code Generation | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2844 | Attention Enables Zero Approximation Error | 4.80 | 4.80 | 0.00 | [5, 6, 3, 5, 5]
|
| 2845 | Revisiting Activation Function Design for Improving Adversarial Robustness at Scale | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 2846 | Contrastive Hierarchical Clustering | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 2847 | What Does Vision Supervision Bring to Language Models? A Case Study of CLIP | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 2848 | Accurate Bayesian Meta-Learning by Accurate Task Posterior Inference | 7.00 | 7.00 | 0.00 | [6, 6, 8, 8]
|
| 2849 | Learning to Decompose Visual Features with Latent Textual Prompts | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 2850 | ML-ViG: Multi-Label Image Recognition with Vision Graph Convolutional Network | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2851 | Skill Machines: Temporal Logic Composition in Reinforcement Learning | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 2852 | Surrogate Gradient Design for LIF networks | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2853 | Context-enriched molecule representations improve few-shot drug discovery | 7.00 | 7.00 | 0.00 | [6, 6, 8, 8]
|
| 2854 | The Multiple Subnetwork Hypothesis: Enabling Multidomain Learning by Isolating Task-Specific Subnetworks in Feedforward Neural Networks | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2855 | Warped Convolutional Networks: Bridge Homography to $\mathfrak{sl}(3)$ algebra by Group Convolution | 5.33 | 5.33 | 0.00 | [8, 5, 3]
|
| 2856 | Delving into the Openness of CLIP | 5.75 | 5.75 | 0.00 | [8, 5, 5, 5]
|
| 2857 | Test-Time Adaptation via Self-Training with Nearest Neighbor Information | 6.00 | 6.00 | 0.00 | [6, 5, 8, 5]
|
| 2858 | Learning to Counter: Stochastic Feature-based Learning for Diverse Counterfactual Explanations | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 2859 | Accurate Neural Training with 4-bit Matrix Multiplications at Standard Formats | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 2860 | SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient | 5.50 | 5.50 | 0.00 | [3, 8, 6, 5, 3, 8]
|
| 2861 | Relative representations enable zero-shot latent space communication | 8.00 | 8.00 | 0.00 | [8, 6, 10]
|
| 2862 | oViT: An Accurate Second-Order Pruning Framework for Vision Transformers | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 2863 | Learning Basic Interpretable Factors from Temporal Signals via Physics Symmetry | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 2864 | Addressing High-dimensional Continuous Action Space via Decomposed Discrete Policy-Critic | 3.60 | 3.60 | 0.00 | [3, 3, 3, 3, 6]
|
| 2865 | Unsupervised Manifold Alignment with Joint Multidimensional Scaling | 5.75 | 5.75 | 0.00 | [6, 6, 3, 8]
|
| 2866 | Can Single-Pass Contrastive Learning Work for Both Homophilic and Heterophilic Graph? | 4.75 | 4.75 | 0.00 | [3, 5, 8, 3]
|
| 2867 | TOAST: Topological Algorithm for Singularity Tracking | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 2868 | Robust Manifold Estimation Approach for Evaluating Fidelity and Diversity | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 2869 | Disentangling Writer and Character Styles for Handwriting Generation | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 2870 | Exploiting Certified Defences to Attack Randomised Smoothing | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 2871 | Simple and Scalable Nearest Neighbor Machine Translation | 5.00 | 5.00 | 0.00 | [6, 3, 6, 5]
|
| 2872 | On the effectiveness of out-of-distribution data in self-supervised long-tail learning. | 5.25 | 6.00 | 0.75 | [5, 8, 6, 5]
|
| 2873 | Dynamic Update-to-Data Ratio: Minimizing World Model Overfitting | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 2874 | Deep Leakage from Model in Federated Learning | 3.00 | 3.00 | 0.00 | [1, 5, 3]
|
| 2875 | A Universal 3D Molecular Representation Learning Framework | 7.00 | 7.75 | 0.75 | [8, 10, 8, 5]
|
| 2876 | CAPE: Channel-Attention-Based PDE Parameter Embeddings for SciML | 3.67 | 4.00 | 0.33 | [5, 5, 3, 3]
|
| 2877 | Topic and Hyperbolic Transformer to Handle Multi-modal Dependencies | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 2878 | Variance Covariance Regularization Enforces Pairwise Independence in Self-Supervised Representations | 4.60 | 4.60 | 0.00 | [6, 5, 3, 6, 3]
|
| 2879 | DEP-RL: Embodied Exploration for Reinforcement Learning in Overactuated and Musculoskeletal Systems | 8.50 | 8.50 | 0.00 | [8, 8, 8, 10]
|
| 2880 | Restricted Generative Projection for One-Class Classification and Anomaly detection | 4.25 | 4.25 | 0.00 | [6, 3, 3, 5]
|
| 2881 | Name Your Colour For the Task: Artificially Discover Colour Naming via Colour Quantisation Transformer | 5.00 | 5.00 | 0.00 | [6, 6, 5, 3]
|
| 2882 | The Generalized Eigenvalue Problem as a Nash Equilibrium | 7.00 | 7.50 | 0.50 | [8, 8, 6, 8]
|
| 2883 | learning hierarchical multi-agent cooperation with long short-term intention | 4.25 | 4.25 | 0.00 | [5, 3, 3, 6]
|
| 2884 | FEAT: A general framework for Feature-aware Multivariate Time-series Representation Learning | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 2885 | Learning with Auxiliary Activation for Memory-Efficient Training | 5.75 | 6.50 | 0.75 | [8, 6, 6, 6]
|
| 2886 | Equivariant 3D-Conditional Diffusion Models for Molecular Linker Design | 6.25 | 6.25 | 0.00 | [6, 8, 3, 8]
|
| 2887 | Existence of a bad local minimum of neural networks with general smooth activation functions | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2888 | Language Modelling with Pixels | 7.00 | 7.00 | 0.00 | [8, 6, 6, 8]
|
| 2889 | Sinkhorn Discrepancy for Counterfactual Generalization | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 2890 | Massively Scaling Heteroscedastic Classifiers | 6.00 | 6.17 | 0.17 | [6, 8, 6, 3, 8, 6]
|
| 2891 | Vera Verto: Multimodal Hijacking Attack | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 2892 | On Incremental Learning with Long Short Term Strategy | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 2893 | Joint Attention-Driven Domain Fusion and Noise-Tolerant Learning for Multi-Source Domain Adaptation | 5.33 | 5.25 | -0.08 | [5, 5, 3, 8]
|
| 2894 | Efficient Point Cloud Geometry Compression Through Neighborhood Point Transformer | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 2895 | EA-HAS-Bench: Energy-aware Hyperparameter and Architecture Search Benchmark | 6.50 | 6.50 | 0.00 | [6, 8, 6, 6]
|
| 2896 | Breaking the Curse of Dimensionality for Parametric Elliptic PDEs | 4.67 | 4.67 | 0.00 | [10, 3, 1]
|
| 2897 | UniFormerV2: Spatiotemporal Learning by Arming Image ViTs with Video UniFormer | 6.25 | 6.25 | 0.00 | [8, 3, 6, 8]
|
| 2898 | Dynamical Equations With Bottom-up Self-Organizing Properties Learn Accurate Dynamical Hierarchies Without Any Loss Function | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 2899 | Multi-Label Knowledge Distillation | 4.60 | 4.60 | 0.00 | [3, 8, 6, 3, 3]
|
| 2900 | How and Why We Detect Distribution Shift: Critical Analysis of Methods and Benchmarks | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 2901 | ADVERSARY-AWARE PARTIAL LABEL LEARNING WITH LABEL DISTILLATION | 3.00 | 3.00 | 0.00 | [5, 3, 1, 3]
|
| 2902 | Structural Privacy in Graphs | 2.33 | 2.33 | 0.00 | [1, 3, 3]
|
| 2903 | KnowDA: All-in-One Knowledge Mixture Model for Data Augmentation in Low-Resource NLP | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 2904 | Learning Graph Neural Network Topologies | 3.75 | 3.75 | 0.00 | [3, 3, 6, 3]
|
| 2905 | Finding the global semantic representation in GAN through Fréchet Mean | 5.75 | 5.75 | 0.00 | [6, 6, 3, 8]
|
| 2906 | Identical Initialization: A Universal Approach to Fast and Stable Training of Neural Networks | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2907 | Addressing Parameter Choice Issues in Unsupervised Domain Adaptation by Aggregation | 6.25 | 6.50 | 0.25 | [6, 6, 6, 8]
|
| 2908 | MARS: Meta-learning as Score Matching in the Function Space | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 2909 | Faster Gradient-Free Methods for Escaping Saddle Points | 7.00 | 7.50 | 0.50 | [6, 8, 8, 8]
|
| 2910 | $\textrm{D}^3\textrm{Former}$: Debiased Dual Distilled Transformer for Incremental Learning | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 2911 | Symmetrical SyncMap for Imbalanced General Chunking Problems | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 2912 | Solving Partial Label Learning Problem with Multi-Agent Reinforcement Learning | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 2913 | Uncovering the Effectiveness of Calibration on Open Intent Classification | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 2914 | PMixUp: Simultaneous Utilization of Part-of-Speech Replacement and Feature Space Interpolation for Text Data Augmentation | 5.67 | 5.67 | 0.00 | [3, 8, 6]
|
| 2915 | SDT: Specific Domain Training in Domain Generalization | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 2916 | Lossy Compression with Gaussian Diffusion | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 2917 | Score-Based Graph Generative Modeling with Self-Guided Latent Diffusion | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 2918 | Gradient-Informed Quality Diversity for the Illumination of Discrete Spaces | 3.50 | 3.50 | 0.00 | [6, 1, 6, 1]
|
| 2919 | Deep Generative Wasserstein Gradient Flows | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 2920 | Linear Scalarization for Byzantine-Robust Learning on non-IID data | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2921 | Where to Go Next for Recommender Systems? ID- vs. Modality-based recommender models revisited | 5.20 | 5.40 | 0.20 | [5, 6, 5, 8, 3]
|
| 2922 | Pixel-Level Task Helps Pruned Network Transfer to Downstream Tasks | 4.25 | 4.25 | 0.00 | [6, 3, 3, 5]
|
| 2923 | Is Class Incremental Learning Truly Learning Representations Continually? | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2924 | Optimising 2D Pose Representation: Improving Accuracy, Stability and Generalisability inUnsupervised 2D-3D Human Pose Estimation | 5.20 | 5.20 | 0.00 | [5, 5, 5, 8, 3]
|
| 2925 | Model Obfuscation for Securing Deployed Neural Networks | 5.25 | 5.25 | 0.00 | [5, 3, 8, 5]
|
| 2926 | Optimising Event-Driven Spiking Neural Network with Regularisation and Cutoff | 5.00 | 5.20 | 0.20 | [3, 6, 6, 6, 5]
|
| 2927 | ESP: Exponential Smoothing on Perturbations for Increasing Robustness to Data Corruptions | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 2928 | MATS: Memory Attention for Time-Series forecasting | 6.33 | 6.33 | 0.00 | [8, 5, 6]
|
| 2929 | MultiViz: Towards Visualizing and Understanding Multimodal Models | 5.25 | 5.25 | 0.00 | [8, 6, 6, 1]
|
| 2930 | How Informative is the Approximation Error from Tensor Decomposition for Neural Network Compression? | 5.00 | 5.50 | 0.50 | [6, 3, 5, 8]
|
| 2931 | DISCO-DANCE: Learning to Discover Skills with Guidance | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 2932 | Exploring Generalization of Non-Contrastive self-supervised Learning | 2.60 | 2.60 | 0.00 | [3, 1, 3, 3, 3]
|
| 2933 | Architecture-Agnostic Masked Image Modeling -- From ViT back to CNN | 5.25 | 5.25 | 0.00 | [5, 3, 8, 5]
|
| 2934 | Blurring Diffusion Models | 6.00 | 6.00 | 0.00 | [8, 6, 5, 5]
|
| 2935 | BrGANs: Stabilizing GANs" Training Process with Brownian Motion Control | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 2936 | Detecting Backdoor Attacks via Layer-wise Feature Analysis | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2937 | Hyperbolic Self-paced Learning for Self-supervised Skeleton-based Action Representations | 6.00 | 6.00 | 0.00 | [8, 5, 5, 6]
|
| 2938 | Unfair geometries: exactly solvable data model with fairness implications | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 2939 | DropAut: Automatic Dropout Approaches to learn and adapt Drop Rates | 4.40 | 4.40 | 0.00 | [3, 5, 3, 6, 5]
|
| 2940 | Understanding Adversarial Transferability in Federated Learning | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 2941 | RankCSE: Unsupervised Sentence Representations Learning via Learning to Rank | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 2942 | Efficient Offline Policy Optimization with a Learned Model | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 2943 | New Insights for the Stability-Plasticity Dilemma in Online Continual Learning | 5.25 | 6.00 | 0.75 | [6, 5, 8, 5]
|
| 2944 | MixPro: Data Augmentation with MaskMix and Progressive Attention Labeling for Vision Transformer | 6.33 | 6.33 | 0.00 | [8, 6, 5]
|
| 2945 | Multiple Invertible and Equivariant Transformation for Disentanglement in VAEs | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 2946 | StyleMorph: Disentangling Shape, Pose and Appearance through 3D Morphable Image and Geometry Generation | 6.20 | 6.20 | 0.00 | [6, 6, 8, 8, 3]
|
| 2947 | Accelerated Riemannian Optimization: Handling Constraints to Bound Geometric Penalties | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 2948 | Searching Lottery Tickets in Graph Neural Networks: A Dual Perspective | 5.60 | 5.60 | 0.00 | [6, 5, 8, 3, 6]
|
| 2949 | Video Scene Graph Generation from Single-Frame Weak Supervision | 4.75 | 4.75 | 0.00 | [5, 3, 5, 6]
|
| 2950 | Planning With Uncertainty: Deep Exploration in Model-Based Reinforcement Learning | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 2951 | Unsupervised visualization of image datasets using contrastive learning | 6.25 | 6.75 | 0.50 | [6, 5, 10, 6]
|
| 2952 | On the Expressive Equivalence Between Graph Convolution and Attention Models | 5.00 | 5.00 | 0.00 | [1, 8, 3, 8]
|
| 2953 | Contrastive Consistent Representation Distillation | 4.75 | 4.75 | 0.00 | [3, 5, 5, 6]
|
| 2954 | PowerQuant: Automorphism Search for Non-Uniform Quantization | 5.67 | 6.00 | 0.33 | [6, 6, 6]
|
| 2955 | CLEEGN: A Convolutional Neural Network for Plug-and-Play Automatic EEG Reconstruction | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 2956 | Neural Layered Min-sum Decoders for Algebraic Codes | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 2957 | On Uni-modal Feature Learning in Multi-modal Learning | 6.00 | 6.00 | 0.00 | [5, 8, 6, 5]
|
| 2958 | Unified neural representation model for physical and conceptual spaces | 4.75 | 4.75 | 0.00 | [5, 3, 3, 8]
|
| 2959 | Symbolic Physics Learner: Discovering governing equations via Monte Carlo tree search | 7.50 | 7.50 | 0.00 | [6, 8, 8, 8]
|
| 2960 | The Dynamic of Consensus in Deep Networks and the Identification of Noisy Labels | 4.80 | 4.80 | 0.00 | [5, 5, 6, 3, 5]
|
| 2961 | Efficient block contrastive learning via parameter-free meta-node approximation | 4.25 | 4.25 | 0.00 | [3, 5, 3, 6]
|
| 2962 | Attribute Alignment and Enhancement for Generalized Zero-Shot Learning | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 2963 | BAYES RISK CTC: CONTROLLABLE CTC ALIGNMENT IN SEQUENCE-TO-SEQUENCE TASKS | 7.25 | 7.25 | 0.00 | [8, 8, 5, 8]
|
| 2964 | A Convergent Single-Loop Algorithm for Gromov-Wasserstein in Graph Data | 7.25 | 7.25 | 0.00 | [5, 8, 8, 8]
|
| 2965 | The Importance of Suppressing Complete Reconstruction in Autoencoders for Unsupervised Outlier Detection | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 2966 | FrAug: Frequency Domain Augmentation for Time Series Forecasting | 4.60 | 4.60 | 0.00 | [5, 5, 5, 5, 3]
|
| 2967 | A Hierarchical Hyper-rectangle Mass Model for Fine-grained Entity Typing | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 2968 | Bayesian semi-supervised learning with a principled likelihood from a generative model of data curation | 4.50 | 5.25 | 0.75 | [5, 3, 8, 5]
|
| 2969 | Continual Learning via Adaptive Neuron Selection | 5.00 | 4.25 | -0.75 | [8, 3, 3, 3]
|
| 2970 | Revisiting Fast Adversarial Training | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 2971 | Ti-MAE: Self-Supervised Masked Time Series Autoencoders | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 2972 | E3Bind: An End-to-End Equivariant Network for Protein-Ligand Docking | 5.75 | 5.75 | 0.00 | [6, 6, 6, 5]
|
| 2973 | Deep High-Frequency Extrapolation for Neuronal Spike Restoration | 4.50 | 4.50 | 0.00 | [6, 6, 3, 3]
|
| 2974 | Improving Model Consistency of Decentralized Federated Learning via Sharpness Aware Minimization and Multiple Gossip Approaches | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 2975 | VA-DepthNet: A Variational Approach to Single Image Depth Prediction | 6.00 | 6.50 | 0.50 | [8, 8, 5, 5]
|
| 2976 | Prompt-to-Prompt Image Editing with Cross-Attention Control | 7.50 | 7.50 | 0.00 | [8, 6, 8, 8]
|
| 2977 | ExtraMix: Extrapolatable Data Augmentation for Regression using Generative Models | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 2978 | Exact Group Fairness Regularization via Classwise Robust Optimization | 5.00 | 5.00 | 0.00 | [3, 6, 6, 5]
|
| 2979 | Lightweight Uncertainty for Offline Reinforcement Learning via Bayesian Posterior | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 2980 | DiffEdit: Diffusion-based semantic image editing with mask guidance | 7.75 | 7.75 | 0.00 | [10, 8, 5, 8]
|
| 2981 | Are More Layers Beneficial to Graph Transformers? | 5.25 | 5.25 | 0.00 | [6, 3, 6, 6]
|
| 2982 | Learning Combinatorial Node Labeling Algorithms | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 2983 | Simplicial Hopfield networks | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 2984 | Volumetric Disentanglement for 3D Scene Manipulation | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 2985 | Versatile Neural Processes for Learning Implicit Neural Representations | 6.50 | 6.75 | 0.25 | [8, 6, 5, 8]
|
| 2986 | Supplementing Domain Knowledge to BERT with Semi-structured Information of Documents | 4.25 | 4.25 | 0.00 | [6, 3, 3, 5]
|
| 2987 | Window Projection Features are All You Need for Time Series Anomaly Detection | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 2988 | DEEP ACCURATE SOLVER FOR THE GEODESIC PROBLEM | 4.67 | 4.67 | 0.00 | [3, 8, 3]
|
| 2989 | PBFormer: Capturing Complex Scene Text Shape with Polynomial Band Transformer | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 2990 | Classically Approximating Variational Quantum Machine Learning with Random Fourier Features | 7.00 | 7.00 | 0.00 | [8, 8, 5]
|
| 2991 | Distributional Meta-Gradient Reinforcement Learning | 5.50 | 5.50 | 0.00 | [3, 6, 8, 5]
|
| 2992 | Towards A Unified Policy Abstraction Theory and Representation Learning Approach in Markov Decision Processes | 4.25 | 4.25 | 0.00 | [5, 3, 6, 3]
|
| 2993 | Inapplicable Actions Learning for Knowledge Transfer in Reinforcement Learning | 3.75 | 3.75 | 0.00 | [3, 3, 6, 3]
|
| 2994 | CENTROID-BASED JOINT REPRESENTATION FOR HUMAN POSE ESTIMATION AND INSTANCE SEGMENTATION | 3.00 | 3.00 | 0.00 | [5, 1, 3]
|
| 2995 | Addressing Variable Dependency in GNN-based SAT Solving | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 2996 | Pairwise Confidence Difference on Unlabeled Data is Sufficient for Binary Classification | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 2997 | Emergent Communication with Attention | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 2998 | Discovering Bugs in Vision Models using Off-the-shelf Image Generation and Captioning | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 2999 | MetaFS: An Effective Wrapper Feature Selection via Meta Learning | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 3000 | Same Pre-training Loss, Better Downstream: Implicit Bias Matters for Language Models | 4.75 | 4.75 | 0.00 | [5, 6, 3, 5]
|
| 3001 | Signal to Sequence Attention-Based Multiple Instance Network for Segmentation Free Inference of RNA Modifications | 4.67 | 5.00 | 0.33 | [6, 3, 6, 5]
|
| 3002 | Interval-based Offline Policy Evaluation without Sufficient Exploration or Realizability | 5.50 | 5.50 | 0.00 | [6, 5, 3, 8]
|
| 3003 | A Differential Geometric View and Explainability of GNN on Evolving Graphs | 6.25 | 6.25 | 0.00 | [5, 6, 6, 8]
|
| 3004 | $\rm A^2Q$: Aggregation-Aware Quantization for Graph Neural Networks | 5.40 | 5.40 | 0.00 | [3, 5, 5, 8, 6]
|
| 3005 | Text-Driven Generative Domain Adaptation with Spectral Consistency Regularization | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 3006 | Multi-Prompt Alignment for Multi-source Unsupervised Domain Adaptation | 6.20 | 6.20 | 0.00 | [8, 5, 5, 8, 5]
|
| 3007 | Adversarial Examples Guided Pseudo-label Refinement for Decentralized Domain Adaptation | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 3008 | Clean-image Backdoor: Attacking Multi-label Models with Poisoned Labels Only | 5.25 | 5.25 | 0.00 | [6, 3, 6, 6]
|
| 3009 | Dense Correlation Fields for Motion Modeling in Action Recognition | 5.50 | 5.50 | 0.00 | [5, 6, 3, 8]
|
| 3010 | Variance Reduction is an Antidote to Byzantines: Better Rates, Weaker Assumptions and Communication Compression as a Cherry on the Top | 5.00 | 6.40 | 1.40 | [8, 6, 5, 8, 5]
|
| 3011 | What"s Behind the Mask: Estimating Uncertainty in Image-to-Image Problems | 4.75 | 4.75 | 0.00 | [5, 3, 5, 6]
|
| 3012 | A Time-Consistency Curriculum for Learning from Instance-Dependent Noisy Labels | 4.25 | 4.25 | 0.00 | [3, 5, 6, 3]
|
| 3013 | Black-box Knowledge Distillation | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 3014 | Open Set Recognition by Mitigating Prompt Bias | 5.00 | 5.00 | 0.00 | [3, 5, 6, 6]
|
| 3015 | Efficient Personalized Federated Learning via Sparse Model-Adaptation | 4.80 | 4.80 | 0.00 | [5, 5, 5, 3, 6]
|
| 3016 | Molecule Generation for Target Receptor Binding via Continuous Normalizing Flows | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 3017 | Momentum Tracking: Momentum Acceleration for Decentralized Deep Learning on Heterogeneous Data | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 3018 | Deep Graph-Level Orthogonal Hypersphere Compression for Anomaly Detection | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 3019 | GPR-Net: Multi-view Layout Estimation via a Geometry-aware Panorama Registration Network | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3020 | Gradient Deconfliction via Orthogonal Projections onto Subspaces For Multi-task Learning | 5.00 | 5.00 | 0.00 | [6, 5, 5, 3, 6]
|
| 3021 | Relative Contribution Mechanism: A Unified Paradigm for Disassembling Convolutional Neural Networks | 0.00 | 0.00 | 0.00 | Ratings not available yet
|
| 3022 | Pareto Optimization for Active Learning under Out-of-Distribution Data Scenarios | 4.33 | 5.67 | 1.33 | [6, 3, 8]
|
| 3023 | Self-Consistent Learning: Cooperation between Generators and Discriminators | 4.50 | 4.50 | 0.00 | [6, 6, 5, 1]
|
| 3024 | Learning Dynamical Characteristics with Neural Operators for Data Assimilation | 5.40 | 5.80 | 0.40 | [8, 5, 3, 5, 8]
|
| 3025 | Lost Domain Generalization Is a Natural Consequence of Lack of Training Domains | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 3026 | Graph Neural Networks for Link Prediction with Subgraph Sketching | 8.50 | 8.50 | 0.00 | [10, 8, 8, 8]
|
| 3027 | Leveraging Hard Negative Priors for Automatic Medical Report Generation | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3028 | Multitask Prompt Tuning Enables Parameter-Efficient Transfer Learning | 6.50 | 6.50 | 0.00 | [6, 8, 6, 6]
|
| 3029 | Style Balancing and Test-Time Style Shifting for Domain Generalization | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 3030 | Least Disagree Metric-based Active Learning | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 3031 | Personalized Federated Hypernetworks for Privacy Preservation in Multi-Task Reinforcement Learning | 2.33 | 2.33 | 0.00 | [1, 3, 3]
|
| 3032 | NSCL: Noise-Resistant Soft Contrastive Learning for Universal Domain Adaptation | 4.50 | 4.50 | 0.00 | [6, 3, 6, 3]
|
| 3033 | Global-Local Bayesian Transformer for Semantic Correspondence | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 3034 | Semantic Category Discovery with Vision-language Representations | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3035 | Deep Causal Generative Modeling for Tabular Data Imputation and Intervention | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 3036 | CBLab: Scalable Traffic Simulation with Enriched Data Supporting | 5.50 | 6.50 | 1.00 | [6, 6, 6, 8]
|
| 3037 | Personalized Decentralized Bilevel Optimization over Stochastic and Directed Networks | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 3038 | ContextSpeech: Expressive and Efficient Text-to-Speech for Paragraph Reading | 4.00 | 5.00 | 1.00 | [8, 1, 5, 6]
|
| 3039 | Learning Object Affordance with Contact and Grasp Generation | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 3040 | Deep Graph-Level Clustering Using Pseudo-Label-Guided Mutual Information Maximization Network | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 3041 | Deep Generative Model based Rate-Distortion for Image Downscaling Assessment | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 3042 | Selective Classifier Ensemble | 4.75 | 4.75 | 0.00 | [5, 5, 3, 6]
|
| 3043 | Better Generative Replay for Continual Federated Learning | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 3044 | Unified Probabilistic Modeling of Image Aesthetic Rating Distributions towards Measuring Subjectivity | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 3045 | Enhancing the Transferability of Adversarial Examples via a Few Queries and Fuzzy Domain Eliminating | 3.50 | 3.50 | 0.00 | [5, 3, 5, 1]
|
| 3046 | Analyzing adversarial robustness of vision transformers against spatial and spectral attacks | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 3047 | Label-distribution-agnostic Ensemble Learning on Federated Long-tailed Data | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 3048 | MULTI-VIEW DEEP EVIDENTIAL FUSION NEURAL NETWORK FOR ASSESSMENT OF SCREENING MAMMOGRAMS | 3.00 | 3.00 | 0.00 | [1, 3, 5, 3]
|
| 3049 | Data-Free Continual Graph Learning | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 3050 | Generative Modelling with Inverse Heat Dissipation | 6.25 | 6.25 | 0.00 | [6, 8, 6, 5]
|
| 3051 | Self-supervision through Random Segments with Autoregressive Coding (RandSAC) | 7.00 | 7.00 | 0.00 | [8, 8, 5]
|
| 3052 | Rarity Score : A New Metric to Evaluate the Uncommonness of Synthesized Images | 6.25 | 6.25 | 0.00 | [6, 8, 6, 5]
|
| 3053 | Benchmarking Approximate k-Nearest Neighbour Search for Big High Dimensional Dynamic Data | 4.25 | 4.25 | 0.00 | [3, 5, 6, 3]
|
| 3054 | Semi-Supervised Offline Reinforcement Learning with Action-Free Trajectories | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 3055 | E-Forcing: Improving Autoregressive Models by Treating it as an Energy-Based One | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 3056 | Joint Generator-Ranker Learning for Natural Language Generation | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 3057 | The Progressive Alignment-aware Multimodal Fusion with Easy2hard Strategy for Multimodal Neural Machine Translation | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 3058 | Masked Vector Quantization | 5.33 | 5.33 | 0.00 | [10, 3, 3]
|
| 3059 | On the Importance of the Policy Structure in Offline Reinforcement Learning | 5.00 | 5.50 | 0.50 | [5, 8, 3, 6]
|
| 3060 | Bandit Learning in Many-to-one Matching Markets with Uniqueness Conditions | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 3061 | Can you Trust your Disentanglement? | 4.50 | 4.50 | 0.00 | [1, 3, 6, 8]
|
| 3062 | TRANSFORMER-PATCHER: ONE MISTAKE WORTH ONE NEURON | 6.00 | 6.00 | 0.00 | [8, 5, 6, 5]
|
| 3063 | Corrupted Image Modeling for Self-Supervised Visual Pre-Training | 5.83 | 5.83 | 0.00 | [5, 5, 6, 8, 5, 6]
|
| 3064 | Semi-Implicit Variational Inference via Score Matching | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 3065 | Sharper Bounds for Uniformly Stable Algorithms with Stationary $\varphi$-mixing Process | 6.17 | 6.17 | 0.00 | [6, 6, 8, 5, 6, 6]
|
| 3066 | Few-Shot Anomaly Detection on Industrial Images through Contrastive Fine-Tuning | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 3067 | Rate-Distortion Optimized Post-Training Quantization for Learned Image Compression | 4.83 | 4.83 | 0.00 | [5, 3, 5, 3, 8, 5]
|
| 3068 | On the Edge of Benign Overfitting: Label Noise and Overparameterization Level | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 3069 | Predictive Inference with Feature Conformal Prediction | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 3070 | Measuring Image Complexity as a Discrete Hierarchy using MDL Clustering | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 3071 | Recon: Reducing Conflicting Gradients From the Root For Multi-Task Learning | 6.25 | 6.25 | 0.00 | [3, 8, 6, 8]
|
| 3072 | OCD: Learning to Overfit with Conditional Diffusion Models | 4.00 | 5.50 | 1.50 | [3, 6, 8, 5]
|
| 3073 | Measure the Predictive Heterogeneity | 6.00 | 6.50 | 0.50 | [6, 8, 6, 6]
|
| 3074 | On the robustness of self-supervised models for generative spoken language modeling | 4.75 | 4.75 | 0.00 | [5, 3, 5, 6]
|
| 3075 | Non-equispaced Fourier Neural Solvers for PDEs | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 3076 | Time to augment visual self-supervised learning | 5.50 | 5.50 | 0.00 | [8, 6, 3, 5]
|
| 3077 | Adversarial IV Regression for Demystifying Causal Features on Adversarial Examples | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3078 | Probable Dataset Searching Method with Uncertain Dataset Information in Adjusting Architecture Hyper Parameter | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3079 | Impact of the Last Fully Connected Layer on Out-of-distribution Detection | 3.75 | 3.75 | 0.00 | [3, 3, 6, 3]
|
| 3080 | Towards Lightweight, Model-Agnostic and Diversity-Aware Active Anomaly Detection | 5.50 | 5.50 | 0.00 | [6, 3, 8, 5]
|
| 3081 | Multi-Level Contrastive Learning for Dense Prediction Task | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 3082 | Switching One-Versus-the-Rest Loss to Increase Logit Margins for Adversarial Robustness | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 3083 | Unleashing Vanilla Vision Transformer with Masked Image Modeling for Object Detection | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 3084 | Scaled Neural Multiplicative Model for Tractable Optimization | 3.00 | 3.00 | 0.00 | [3, 5, 1]
|
| 3085 | Quasi-Taylor Samplers for Diffusion Generative Models based on Ideal Derivatives | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 3086 | Group-oriented Cooperation in Multi-Agent Reinforcement Learning | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 3087 | Exploring Temporally Dynamic Data Augmentation for Video Recognition | 7.00 | 7.00 | 0.00 | [8, 8, 6, 6]
|
| 3088 | CacheGNN: Enhancing Graph Neural Networks with Global Information Caching | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 3089 | Towards Information-Theoretic Pattern Mining in Time Series | 3.50 | 3.50 | 0.00 | [3, 5, 5, 1]
|
| 3090 | Agent Prioritization with Interpretable Relation for Trajectory Prediction | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 3091 | $z$-SignFedAvg: A Unified Stochastic Sign-based Compression for Federated Learning | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 3092 | Transfer Learning with Pre-trained Conditional Generative Models | 6.33 | 5.00 | -1.33 | [1, 8, 6, 5]
|
| 3093 | DECN: Evolution Inspired Deep Convolution Network for Black-box Optimization | 4.00 | 4.60 | 0.60 | [3, 3, 6, 5, 6]
|
| 3094 | Q-Pensieve: Boosting Sample Efficiency of Multi-Objective RL Through Memory Sharing of Q-Snapshots | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 3095 | On the Power-Law Hessian Spectra in Deep Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3096 | Optformer: Beyond Transformer for Black-box Optimization | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 3097 | Deformable Graph Transformer | 4.80 | 5.20 | 0.40 | [5, 5, 5, 5, 6]
|
| 3098 | Exact manifold Gaussian Variational Bayes | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 3099 | SuperMarioDomains: Generalizing to Domains with Evolving Graphics | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 3100 | Variance-Aware Sparse Linear Bandits | 6.75 | 6.75 | 0.00 | [8, 6, 8, 5]
|
| 3101 | Multi-Treatment Effect Estimation with Proxy: Contrastive Learning and Rank Weighting | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 3102 | CircNet: Meshing 3D Point Clouds with Circumcenter Detection | 5.75 | 5.75 | 0.00 | [6, 6, 3, 8]
|
| 3103 | In-sample Actor Critic for Offline Reinforcement Learning | 6.00 | 6.00 | 0.00 | [5, 6, 5, 8]
|
| 3104 | Leveraging Future Relationship Reasoning for Vehicle Trajectory Prediction | 5.67 | 5.67 | 0.00 | [8, 3, 6]
|
| 3105 | DeepTime: Deep Time-index Meta-learning for Non-stationary Time-series Forecasting | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 3106 | Non-Parametric State-Space Models: Identifiability, Estimation and Forecasting | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3107 | ETSformer: Exponential Smoothing Transformers for Time-series Forecasting | 5.33 | 4.75 | -0.58 | [3, 5, 6, 5]
|
| 3108 | LMSeg: Language-guided Multi-dataset Segmentation | 5.00 | 5.25 | 0.25 | [6, 6, 3, 6]
|
| 3109 | Horizon-Free Reinforcement Learning for Latent Markov Decision Processes | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 3110 | Learning Invariant Features for Online Continual Learning | 5.50 | 5.50 | 0.00 | [6, 3, 5, 8]
|
| 3111 | RoPAWS: Robust Semi-supervised Representation Learning from Uncurated Data | 6.40 | 6.80 | 0.40 | [5, 8, 8, 5, 8]
|
| 3112 | Treeformer: Dense Gradient Trees for Efficient Attention Computation | 6.33 | 6.33 | 0.00 | [8, 5, 6]
|
| 3113 | Visual Reinforcement Learning with Self-Supervised 3D Representations | 4.50 | 4.50 | 0.00 | [3, 3, 6, 6]
|
| 3114 | ODAM: Gradient-based Instance-Specific Visual Explanations for Object Detection | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 3115 | Understanding Curriculum Learning in Policy Optimization for Online Combinatorial Optimization | 4.75 | 4.75 | 0.00 | [3, 5, 5, 6]
|
| 3116 | Toward Adversarial Training on Contextualized Language Representation | 5.67 | 5.67 | 0.00 | [8, 3, 6]
|
| 3117 | Efficient Method for Bi-level Optimization with Non-smooth Lower-Level Problem | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 3118 | Estimating Riemannian Metric with Noise-Contaminated Intrinsic Distance | 4.67 | 4.67 | 0.00 | [8, 3, 3]
|
| 3119 | In Search of Smooth Minima for Purifying Backdoor in Deep Neural Networks | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3120 | Joint Gaussian Mixture Model for Versatile Deep Visual Model Explanation | 6.00 | 6.00 | 0.00 | [5, 3, 8, 8]
|
| 3121 | Gromov-Wasserstein Autoencoders | 5.75 | 6.25 | 0.50 | [6, 5, 8, 6]
|
| 3122 | Localized Graph Contrastive Learning | 6.00 | 6.00 | 0.00 | [5, 6, 8, 5]
|
| 3123 | OrthoReg: Improving Graph-regularized MLPs via Orthogonality Regularization | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 3124 | Group-Equivariant Transformers Without Positional Encoding | 3.75 | 3.75 | 0.00 | [3, 3, 6, 3]
|
| 3125 | CUSTOMIZING PRE-TRAINED DIFFUSION MODELS FOR YOUR OWN DATA | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 3126 | Optimal Activation Functions for the Random Features Regression Model | 5.75 | 6.00 | 0.25 | [5, 5, 6, 8]
|
| 3127 | Deep Learning-based Source Code Complexity Prediction | 5.00 | 5.00 | 0.00 | [3, 6, 5, 6]
|
| 3128 | Learning to Learn with Generative Models of Neural Network Checkpoints | 5.75 | 5.75 | 0.00 | [5, 5, 8, 5]
|
| 3129 | Improving Explanation Reliability through Group Attribution | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 3130 | SpeechLM: Enhanced Speech Pre-Training with Unpaired Textual Data | 4.75 | 4.75 | 0.00 | [8, 3, 3, 5]
|
| 3131 | Uncertainty Guided Depth Fusion for Spike Camera | 2.33 | 2.33 | 0.00 | [1, 3, 3]
|
| 3132 | Personalized Semantics Excitation for Federated Image Classification | 5.25 | 5.25 | 0.00 | [3, 5, 5, 8]
|
| 3133 | Intrinsic Motivation via Surprise Memory | 5.25 | 5.25 | 0.00 | [5, 5, 3, 8]
|
| 3134 | Dr-Fairness: Dynamic Data Ratio Adjustment for Fair Training on Real and Generated Data | 4.50 | 5.00 | 0.50 | [5, 5, 5, 5]
|
| 3135 | Unsupervised Object-Centric Learning with Bi-level Optimized Query Slot Attention | 5.50 | 5.50 | 0.00 | [5, 3, 6, 8]
|
| 3136 | Set-Level Self-Supervised Learning from Noisily-Labeled Data | 5.71 | 5.71 | 0.00 | [6, 5, 8, 5, 5, 3, 8]
|
| 3137 | Learning an Invertible Output Mapping Can Mitigate Simplicity Bias in Neural Networks | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 3138 | Theoretical generalization bounds for improving the efficiency of deep online training | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3139 | EUCLID: Towards Efficient Unsupervised Reinforcement Learning with Multi-choice Dynamics Model | 5.50 | 5.50 | 0.00 | [5, 6, 6, 5]
|
| 3140 | A General Framework for Sample-Efficient Function Approximation in Reinforcement Learning | 7.33 | 8.00 | 0.67 | [8, 8, 8]
|
| 3141 | FedDM: Iterative Distribution Matching for Communication-Efficient Federated Learning | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3142 | A Representation Bottleneck of Bayesian Neural Networks | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3143 | Maximizing Spatio-Temporal Entropy of Deep 3D CNNs for Efficient Video Recognition | 5.33 | 5.33 | 0.00 | [8, 5, 3]
|
| 3144 | Cycle to Clique (Cy2C) Graph Neural Network: A Sight to See beyond Neighborhood Aggregation | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 3145 | Latent State Marginalization as a Low-cost Approach to Improving Exploration | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 3146 | TensorVAE: A Direct Generative Model for Molecular Conformation Generation driven by Novel Feature Engineering | 5.25 | 5.25 | 0.00 | [5, 8, 5, 3]
|
| 3147 | Smoothed-SGDmax: A Stability-Inspired Algorithm to Improve Adversarial Generalization | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 3148 | Generalizing and Decoupling Neural Collapse via Hyperspherical Uniformity Gap | 5.75 | 6.25 | 0.50 | [6, 8, 3, 8]
|
| 3149 | Bias Mimicking: A Simple Sampling Approach for Bias Mitigation | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 3150 | MaskFusion: Feature Augmentation for Click-Through Rate Prediction via Input-adaptive Mask Fusion | 5.25 | 5.25 | 0.00 | [5, 3, 8, 5]
|
| 3151 | Finite-time Analysis of Single-timescale Actor-Critic on Linear Quadratic Regulator | 5.00 | 4.67 | -0.33 | [3, 5, 6]
|
| 3152 | From Coarse to Fine-grained Concept based Discrimination for Phrase Detection | 4.25 | 4.25 | 0.00 | [5, 3, 6, 3]
|
| 3153 | Scalable 3D Object-centric Learning | 4.75 | 4.75 | 0.00 | [5, 5, 3, 6]
|
| 3154 | Towards Boosting the Open-Domain Chatbot with Human Feedback | 5.00 | 5.00 | 0.00 | [6, 5, 6, 5, 3]
|
| 3155 | Learning to Generate All Feasible Actions | 5.50 | 5.50 | 0.00 | [3, 6, 5, 8]
|
| 3156 | Empirical Study of Pre-training a Backbone for 3D Human Pose and Shape Estimation | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 3157 | Sparsity by Redundancy: Solving $L_1$ with a Simple Reparametrization | 2.75 | 2.75 | 0.00 | [3, 1, 6, 1]
|
| 3158 | Test-Time Adaptation for Visual Document Understanding | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 3159 | Learned Index with Dynamic $\epsilon$ | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 3160 | Breaking the Curse of Dimensionality in Multiagent State Space: A Unified Agent Permutation Framework | 6.25 | 6.25 | 0.00 | [8, 6, 5, 6]
|
| 3161 | LAU: A novel two-parameter learnable Logmoid Activation Unit | 3.00 | 3.00 | 0.00 | [5, 3, 1]
|
| 3162 | 3D Molecular Generation by Virtual Dynamics | 6.33 | 5.67 | -0.67 | [8, 6, 3]
|
| 3163 | N-Student Learning: An Approach to Model Uncertainty and Combat Overfitting | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3164 | Wav2Tok: Deep Sequence Tokenizer for Audio Retrieval | 5.40 | 5.40 | 0.00 | [6, 8, 3, 5, 5]
|
| 3165 | Image to Sphere: Learning Equivariant Features for Efficient Pose Prediction | 6.75 | 6.75 | 0.00 | [8, 5, 8, 6]
|
| 3166 | Better handling unlabeled entity problem using PU-learning and negative sampling | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3167 | PV3D: A 3D Generative Model for Portrait Video Generation | 7.50 | 7.50 | 0.00 | [6, 10, 8, 6]
|
| 3168 | k-Median Clustering via Metric Embedding: Towards Better Initialization with Differential Privacy | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 3169 | Analysis of Error Feedback in Compressed Federated Non-Convex Optimization | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 3170 | Characterizing the Influence of Graph Elements | 6.50 | 6.50 | 0.00 | [6, 8, 6, 6]
|
| 3171 | Adversarially Robust Neural Lyapunov Control | 5.00 | 4.50 | -0.50 | [3, 5, 5, 5]
|
| 3172 | MICN: Multi-scale Local and Global Context Modeling for Long-term Series Forecasting | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 3173 | EMP: Effective Multidimensional Persistence for Graph Representation Learning | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 3174 | Class Prototype-based Cleaner for Label Noise Learning | 5.50 | 5.50 | 0.00 | [8, 8, 3, 3]
|
| 3175 | Improving Vision Attention with Random Walk Graph Kernel | 4.20 | 4.20 | 0.00 | [5, 3, 3, 5, 5]
|
| 3176 | SWIFT: Rapid Decentralized Federated Learning via Wait-Free Model Communication | 5.00 | 5.00 | 0.00 | [6, 3, 6, 5]
|
| 3177 | Hierarchical Sliced Wasserstein Distance | 6.25 | 6.25 | 0.00 | [6, 5, 8, 6]
|
| 3178 | Test-time Adaptation for Better Adversarial Robustness | 5.20 | 5.40 | 0.20 | [6, 5, 5, 5, 6]
|
| 3179 | AutoShot: A Short Video Dataset and State-of-the-Art Shot Boundary Detection | 5.50 | 5.50 | 0.00 | [5, 6, 8, 3]
|
| 3180 | Prototypical Calibration for Few-shot Learning of Language Models | 6.25 | 6.25 | 0.00 | [6, 6, 8, 5]
|
| 3181 | NERDS: A General Framework to Train Camera Denoisers from Single Noisy Images | 5.25 | 5.75 | 0.50 | [6, 6, 8, 3]
|
| 3182 | Communication-Efficient and Drift-Robust Federated Learning via Elastic Net | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3183 | Hierarchical Protein Representations via Complete 3D Graph Networks | 5.75 | 5.75 | 0.00 | [3, 6, 6, 8]
|
| 3184 | Adversarial Attacks on Adversarial Bandits | 6.33 | 6.33 | 0.00 | [6, 5, 8]
|
| 3185 | Multiscale Multimodal Transformer for Multimodal Action Recognition | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3186 | Partition Matters in Learning and Learning-to-Learn Implicit Neural Representations | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3187 | Grounding High Dimensional Representation Similarity by Comparing Decodability and Network Performance | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3188 | Likelihood adjusted semidefinite programs for clustering heterogeneous data | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3189 | RGI: robust GAN-inversion for mask-free image inpainting and unsupervised pixel-wise anomaly detection | 5.20 | 5.20 | 0.00 | [6, 5, 6, 6, 3]
|
| 3190 | Coverage-centric Coreset Selection for High Pruning Rates | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 3191 | AIA: learn to design greedy algorithm for NP-complete problems using neural networks | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 3192 | Self-Adaptive Perturbation Radii for Adversarial Training | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 3193 | Hybrid and Collaborative Passage Reranking | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3194 | GCINT: Dynamic Quantization Algorithm for Training Graph Convolution Neural Networks Using Only Integers | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3195 | ILA-DA: Improving Transferability of Intermediate Level Attack with Data Augmentation | 5.50 | 5.50 | 0.00 | [5, 8, 3, 6]
|
| 3196 | Contrastive Alignment of Vision to Language Through Parameter-Efficient Transfer Learning | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 3197 | 3EF: Class-Incremental Learning via Efficient Energy-Based Expansion and Fusion | 5.00 | 5.00 | 0.00 | [6, 5, 3, 5, 6]
|
| 3198 | Out-of-distribution Representation Learning for Time Series Classification | 5.60 | 5.60 | 0.00 | [5, 5, 5, 8, 5]
|
| 3199 | A Closer Look at the Calibration of Differentially Private Learners | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 3200 | AVT: Audio-Video Transformer for Multimodal Action Recognition | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 3201 | Exploring Transformer Backbones for Heterogeneous Treatment Effect Estimation | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 3202 | Few-Shot Learning with Representative Global Prototype | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3203 | Important Channel Tuning | 5.00 | 5.00 | 0.00 | [6, 6, 3, 5]
|
| 3204 | Feature-Driven Talking Face Generation with StyleGAN2 | 2.00 | 2.00 | 0.00 | [3, 1, 3, 1]
|
| 3205 | Schema Inference for Interpretable Image Classification | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 3206 | Supernet Training for Federated Image Classification Under System Heterogeneity | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 3207 | Domain-Specific Risk Minimization for Out-of-Distribution Generalization | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 3208 | CircuitNet: A Generic Neural Network to Realize Universal Circuit Motif Modeling | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 3209 | Your Contrastive Learning Is Secretly Doing Stochastic Neighbor Embedding | 6.25 | 7.00 | 0.75 | [8, 6, 8, 6]
|
| 3210 | Covariance-Robust Minimax Probability Machines for Algorithmic Recourse | 5.50 | 5.50 | 0.00 | [8, 3, 8, 3]
|
| 3211 | Harnessing Mixed Offline Reinforcement Learning Datasets via Trajectory Weighting | 6.00 | 6.25 | 0.25 | [8, 6, 5, 6]
|
| 3212 | Self-Consistency Improves Chain of Thought Reasoning in Language Models | 6.75 | 6.75 | 0.00 | [10, 6, 6, 5]
|
| 3213 | Ensuring DNN Solution Feasibility for Optimization Problems with Linear Constraints | 6.00 | 6.00 | 0.00 | [5, 6, 8, 5]
|
| 3214 | SpeedAug: A Simple Co-Augmentation Method for Unsupervised Audio-Visual Pre-training | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 3215 | EM-Network: Learning Better Latent Variable for Sequence-to-Sequence Models | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 3216 | AutoFHE: Automated Adaption of CNNs for Efficient Evaluation over FHE | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 3217 | REPRESENTATIVE PROTOTYPE WITH CONSTRASTIVE LEARNING FOR SEMI-SUPENVISED FEW-SHOT CLASSIFICATION | 1.67 | 1.67 | 0.00 | [3, 1, 1]
|
| 3218 | Data-efficient Supervised Learning is Powerful for Neural Combinatorial Optimization | 4.80 | 4.80 | 0.00 | [5, 5, 5, 6, 3]
|
| 3219 | Temporally-Weighted Spike Encoding for Event-based Object Detection and Classification | 4.50 | 4.50 | 0.00 | [6, 6, 3, 3]
|
| 3220 | Spiking Convolutional Neural Networks for Text Classification | 5.50 | 5.50 | 0.00 | [5, 3, 8, 6]
|
| 3221 | Personalized Federated Learning with Feature Alignment and Classifier Collaboration | 6.50 | 6.50 | 0.00 | [8, 5, 5, 8]
|
| 3222 | Distributionally Robust Recourse Action | 6.25 | 6.25 | 0.00 | [6, 5, 6, 8]
|
| 3223 | Randomized Smoothing with Masked Inference for Adversarially Robust NLP Systems | 4.25 | 4.25 | 0.00 | [3, 5, 3, 6]
|
| 3224 | Rethinking the Structure of Stochastic Gradients: Empirical and Statistical Evidence | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3225 | Representing Multi-view Time-series Graph Structures for Multivariate Long-term Time-series Forecasting | 2.50 | 2.50 | 0.00 | [1, 5, 3, 1]
|
| 3226 | Improving Language Model Pretraining with Text Structure Information | 5.50 | 5.50 | 0.00 | [6, 8, 5, 3]
|
| 3227 | Can Language Models Make Fun? A Case Study in Chinese Comical Crosstalk | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 3228 | Chasing Better Deep Image Priors Between Over- and Under-parameterization | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 3229 | Generalizable Person Re-identification Without Demographics | 5.33 | 5.67 | 0.33 | [5, 6, 6]
|
| 3230 | Simple Yet Effective Graph Contrastive Learning for Recommendation | 6.50 | 6.50 | 0.00 | [8, 5, 8, 5]
|
| 3231 | Clustering-Assisted Foreground and Background Separation for Weakly-supervised Temporal Action Localization | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 3232 | MemoNav: Working Memory Model for Visual Navigation | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 3233 | Write and Paint: Generative Vision-Language Models are Unified Modal Learners | 5.67 | 5.75 | 0.08 | [6, 6, 5, 6]
|
| 3234 | Progressive Voronoi Diagram Subdivision Enables Accurate Data-free Class-Incremental Learning | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 3235 | Data Valuation Without Training of a Model | 5.25 | 5.25 | 0.00 | [6, 6, 6, 3]
|
| 3236 | HotProtein: A Novel Framework for Protein Thermostability Prediction and Editing | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 3237 | Agent-Controller Representations: Principled Offline RL with Rich Exogenous Information | 5.40 | 5.40 | 0.00 | [6, 5, 3, 5, 8]
|
| 3238 | RPM: Generalizable Behaviors for Multi-Agent Reinforcement Learning | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 3239 | Behavior Prior Representation learning for Offline Reinforcement Learning | 5.33 | 5.33 | 0.00 | [8, 5, 3]
|
| 3240 | How Does Adaptive Optimization Impact Local Neural Network Geometry? | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 3241 | Substructured Graph Convolution for Non-overlapping Graph Decomposition | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3242 | Concentric Ring Loss for Face Forgery Detection | 5.33 | 5.33 | 0.00 | [5, 3, 8]
|
| 3243 | MaskConver: A Universal Panoptic and Semantic Segmentation Model with Pure Convolutions | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 3244 | On the Neural Tangent Kernel of Equilibrium Models | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 3245 | From Play to Policy: Conditional Behavior Generation from Uncurated Robot Data | 6.00 | 6.00 | 0.00 | [8, 8, 3, 5]
|
| 3246 | Causal Knowledge Transfer from Task Affinity | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 3247 | Beyond Counting Linear Regions of Neural Networks, Simple Linear Regions Dominate! | 4.00 | 3.75 | -0.25 | [3, 3, 6, 3]
|
| 3248 | Recovering Top-Two Answers and Confusion Probability in Multi-Choice Crowdsourcing | 5.75 | 5.75 | 0.00 | [6, 3, 8, 6]
|
| 3249 | SCALE-UP: An Efficient Black-box Input-level Backdoor Detection via Analyzing Scaled Prediction Consistency | 7.33 | 7.33 | 0.00 | [8, 6, 8]
|
| 3250 | On the Perils of Cascading Robust Classifiers | 6.33 | 6.33 | 0.00 | [6, 8, 5]
|
| 3251 | GENERATIVE OF ORIGIN MODEL DISTRIBUTION MASKED WITH EMOTIONS AND TOPICS DISTRIBUTION IN HYBRID METHOD | 2.00 | 2.00 | 0.00 | [3, 1, 1, 3]
|
| 3252 | Visual Classification via Description from Large Language Models | 6.25 | 7.00 | 0.75 | [8, 6, 6, 8]
|
| 3253 | A Data-Based Perspective on Transfer Learning | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 3254 | Contrastive Novelty Learning: Anticipating Outliers with Large Language Models | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 3255 | MIMT: Masked Image Modeling Transformer for Video Compression | 5.20 | 5.60 | 0.40 | [6, 6, 6, 5, 5]
|
| 3256 | Speculative Decoding: Lossless Speedup of Autoregressive Translation | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 3257 | $$CONVOLUTION AND POOLING OPERATION MODULE WITH ADAPTIVE STRIDE PROCESSING EFFEC$$ | 2.33 | 2.33 | 0.00 | [1, 1, 5]
|
| 3258 | Transformer Module Networks for Systematic Generalization in Visual Question Answering | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 3259 | Diving into Unified Data-Model Sparsity for Class-Imbalanced Graph Representation Learning | 6.33 | 6.33 | 0.00 | [8, 8, 3]
|
| 3260 | Cluster and Landmark Attributes Infused Graph Neural Networks for Link prediction | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 3261 | Learning Math Reasoning from Self-Sampled Correct and Partially-Correct Solutions | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 3262 | Adaptive Robust Evidential Optimization For Open Set Detection from Imbalanced Data | 5.75 | 5.75 | 0.00 | [6, 6, 6, 5]
|
| 3263 | The Modality Focusing Hypothesis: Towards Understanding Crossmodal Knowledge Distillation | 5.67 | 6.33 | 0.67 | [6, 5, 8]
|
| 3264 | Representational Task Bias in Zero-shot Recognition at Scale | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 3265 | AxBERT: An Explainable Chinese Spelling Correction Method Driven by Associative Knowledge Network | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 3266 | Hungry Hungry Hippos: Towards Language Modeling with State Space Models | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 3267 | FINE: Future-Aware Inference for Streaming Speech Translation | 6.00 | 6.00 | 0.00 | [6, 5, 5, 8, 6]
|
| 3268 | PATCH-MIX TRANSFORMER FOR UNSUPERVISED DOMAIN ADAPTATION: A GAME PERSPECTIVE | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 3269 | Dual Diffusion Implicit Bridges for Image-to-Image Translation | 6.50 | 6.50 | 0.00 | [6, 10, 5, 5]
|
| 3270 | HYPERPRUNING: EFFICIENT PRUNING THROUGH LYAPUNOV METRIC HYPERSEARCH | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 3271 | Relational Curriculum Learning for Graph Neural Networks | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 3272 | The World is Changing: Improving Fair Training under Correlation Shifts | 6.25 | 6.75 | 0.50 | [8, 6, 5, 8]
|
| 3273 | ACMP: Allen-Cahn Message Passing with Attractive and Repulsive Forces for Graph Neural Networks | 5.33 | 6.00 | 0.67 | [6, 6, 6]
|
| 3274 | Average Sensitivity of Decision Tree Learning | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 3275 | Minimum Curvature Manifold Learning | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 3276 | GeONet: a neural operator for learning the Wasserstein geodesic | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 3277 | Causal Proxy Models For Concept-Based Model Explanations | 4.75 | 4.75 | 0.00 | [5, 6, 3, 5]
|
| 3278 | Offline Reinforcement Learning with Differential Privacy | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 3279 | Relational Attention: Generalizing Transformers for Graph-Structured Tasks | 6.25 | 7.25 | 1.00 | [5, 8, 8, 8]
|
| 3280 | Accelerating Adaptive Federated Optimization with Local Gossip Communications | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 3281 | On the Complexity of Bayesian Generalization | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 3282 | Distilling Model Failures as Directions in Latent Space | 6.25 | 6.75 | 0.50 | [8, 8, 8, 3]
|
| 3283 | Stable Target Field for Reduced Variance Score Estimation | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 3284 | Graph Contrastive Learning Under Heterophily: Utilizing Graph Filters to Generate Graph Views | 4.75 | 4.75 | 0.00 | [3, 8, 3, 5]
|
| 3285 | Countinuous pseudo-labeling from the start | 6.25 | 6.25 | 0.00 | [8, 5, 6, 6]
|
| 3286 | Hybrid Federated Learning for Feature & Sample Heterogeneity: Algorithms and Implementation | 4.33 | 4.50 | 0.17 | [5, 5, 5, 3]
|
| 3287 | SimA: Simple Softmax-free Attention For Vision Transformers | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 3288 | Bridging the Gap Between Cascade and End-to-End Cross-modal Translation Models: A Zero-Shot Approach | 5.50 | 5.50 | 0.00 | [5, 8, 6, 3]
|
| 3289 | Policy Architectures for Compositional Generalization in Control | 5.00 | 5.00 | 0.00 | [3, 6, 8, 3]
|
| 3290 | GNNDelete: A General Unlearning Strategy for Graph Neural Networks | 5.40 | 5.40 | 0.00 | [5, 8, 5, 3, 6]
|
| 3291 | Lower Bounds for Differentially Private ERM: Unconstrained and Non-Euclidean | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3292 | Compound Tokens: Channel Fusion for Vision-Language Representation Learning | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 3293 | The Convergence Rate of SGD"s Final Iterate: Analysis on Dimension Dependence | 4.25 | 4.25 | 0.00 | [3, 5, 6, 3]
|
| 3294 | Multi-Rate VAE: Train Once, Get the Full Rate-Distortion Curve | 7.33 | 8.00 | 0.67 | [8, 8, 8]
|
| 3295 | Are vision transformers more robust than CNNs for Backdoor attacks? | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 3296 | Adaptive Gradient Methods with Local Guarantees | 1.67 | 3.00 | 1.33 | [3, 5, 1]
|
| 3297 | Combinatorial-Probabilistic Trade-Off: P-Values of Community Properties Test in the Stochastic Block Models | 6.75 | 7.50 | 0.75 | [8, 6, 8, 8]
|
| 3298 | RelationCLIP: Training-free Fine-grained Visual and Language Concept Matching | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3299 | Min-Max Zero-Shot Multi-Label Classification | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 3300 | Meta-Learning in Games | 7.00 | 7.00 | 0.00 | [6, 8, 8, 6]
|
| 3301 | GLASU: A Communication-Efficient Algorithm for Federated Learning with Vertically Distributed Graph Data | 3.80 | 3.80 | 0.00 | [5, 3, 3, 5, 3]
|
| 3302 | Dynamic Embeddings of Temporal High-Order Interactions via Neural Diffusion-Reaction Processes | 6.00 | 6.00 | 0.00 | [6, 8, 5, 5]
|
| 3303 | Fair Federated Learning via Bounded Group Loss | 3.50 | 3.75 | 0.25 | [3, 3, 6, 3]
|
| 3304 | DiffDock: Diffusion Steps, Twists, and Turns for Molecular Docking | 6.00 | 6.00 | 0.00 | [3, 10, 8, 3]
|
| 3305 | An Upper Bound for the Distribution Overlap Index and Its Applications | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 3306 | Learning by Distilling Context | 5.50 | 5.50 | 0.00 | [8, 6, 5, 3]
|
| 3307 | Target-Free Ligand Scoring via One-Shot Learning | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 3308 | Inverse Kernel Decomposition | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3309 | Structured Pruning of CNNs at Initialization | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 3310 | Constructive TT-representation of the tensors given as index interaction functions with applications | 5.25 | 5.25 | 0.00 | [3, 6, 6, 6]
|
| 3311 | Thinking Two Moves Ahead: Anticipating Other Users Improves Backdoor Attacks in Federated Learning | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3312 | Continuized Acceleration for Quasar Convex Functions in Non-Convex Optimization | 7.00 | 7.00 | 0.00 | [8, 6, 6, 8]
|
| 3313 | Towards Global Optimality in Cooperative MARL with Sequential Transformation | 2.33 | 2.33 | 0.00 | [3, 3, 1]
|
| 3314 | Sparse tree-based Initialization for Neural Networks | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 3315 | Learning Soft Constraints From Constrained Expert Demonstrations | 5.75 | 6.00 | 0.25 | [8, 5, 5, 6]
|
| 3316 | VoGE: A Differentiable Volume Renderer using Gaussian Ellipsoids for Analysis-by-Synthesis | 5.25 | 5.25 | 0.00 | [5, 3, 8, 5]
|
| 3317 | Unravel Structured Heterogeneity of Tasks in Meta-Reinforcement Learning via Exploratory Clustering | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 3318 | An Investigation of Domain Generalization with Rademacher Complexity | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3319 | Towards Efficient Posterior Sampling in Deep Neural Networks via Symmetry Removal | 4.00 | 4.00 | 0.00 | [3, 3, 8, 3, 3]
|
| 3320 | Local Stochastic Bilevel Optimization with Momentum-Based Variance Reduction | 3.75 | 3.75 | 0.00 | [3, 3, 6, 3]
|
| 3321 | FedDA: Faster Framework of Local Adaptive Gradient Methods via Restarted Dual Averaging | 6.25 | 5.60 | -0.65 | [3, 6, 5, 8, 6]
|
| 3322 | On Emergence of Activation Sparsity in Trained Transformers | 6.40 | 6.40 | 0.00 | [6, 5, 8, 5, 8]
|
| 3323 | Explainable Recommender with Geometric Information Bottleneck | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3324 | Near-optimal Policy Identification in Active Reinforcement Learning | 6.67 | 7.33 | 0.67 | [8, 8, 6]
|
| 3325 | FixEval: Execution-based Evaluation of Program Fixes for Competitive Programming Problems | 3.75 | 3.75 | 0.00 | [3, 3, 6, 3]
|
| 3326 | Algorithmic Determination of the Combinatorial Structure of the Linear Regions of ReLU Neural Networks | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 3327 | Are Neurons Actually Collapsed? On the Fine-Grained Structure in Neural Representations | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 3328 | FoSR: First-order spectral rewiring for addressing oversquashing in GNNs | 6.25 | 7.00 | 0.75 | [6, 8, 8, 6]
|
| 3329 | Early Stopping for Deep Image Prior | 5.60 | 5.60 | 0.00 | [6, 6, 5, 6, 5]
|
| 3330 | ON COMPLEX-DOMAIN CNN REPRESENTATIONS FOR CLASSIFYING REAL/COMPLEX-VALUED DATA | 3.33 | 3.33 | 0.00 | [3, 1, 6]
|
| 3331 | FAME: Fast Adaptive Moment Estimation based on Triple Exponential Moving Average | 4.25 | 4.75 | 0.50 | [3, 5, 8, 3]
|
| 3332 | Progressive Transformation Learning For Leveraging Virtual Images in Training | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3333 | In-Context Policy Iteration | 5.00 | 5.00 | 0.00 | [6, 3, 5, 6]
|
| 3334 | Learning to Grow Pretrained Models for Efficient Transformer Training | 6.50 | 7.00 | 0.50 | [6, 6, 8, 8]
|
| 3335 | Generative Modeling Helps Weak Supervision (and Vice Versa) | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 3336 | What does a platypus look like? Generating customized prompts for zero-shot image classification | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 3337 | Hyperbolic Contrastive Learning for Visual Representations beyond Objects | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 3338 | Provable Memorization Capacity of Transformers | 7.25 | 7.25 | 0.00 | [8, 8, 5, 8]
|
| 3339 | Knowledge-Driven New Drug Recommendation | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 3340 | Beyond Traditional Transfer Learning: Co-finetuning for Action Localisation | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 3341 | Output Distribution over the Entire Input Space: A Novel Perspective to Understand Neural Networks | 4.75 | 5.25 | 0.50 | [5, 5, 6, 5]
|
| 3342 | Learning Control Policies for Region Stabilization in Stochastic Systems | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 3343 | InCoder: A Generative Model for Code Infilling and Synthesis | 7.00 | 7.00 | 0.00 | [8, 8, 6, 6]
|
| 3344 | Bridge the Inference Gaps of Neural Processes via Expectation Maximization | 5.75 | 5.75 | 0.00 | [8, 6, 6, 3]
|
| 3345 | Contrastive Prompt Tuning Improves Generalization in Vision-Language Models | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 3346 | Decentralized Robust V-learning for Solving Markov Games with Model Uncertainty | 4.75 | 4.75 | 0.00 | [5, 3, 6, 5]
|
| 3347 | Generated Graph Detection | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 3348 | Neural Embeddings for Text | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 3349 | Find Your Friends: Personalized Federated Learning with the Right Collaborators | 5.25 | 5.25 | 0.00 | [3, 6, 6, 6]
|
| 3350 | Masked Vision and Language Modeling for Multi-modal Representation Learning | 5.75 | 5.75 | 0.00 | [8, 5, 5, 5]
|
| 3351 | Quantum Fourier Networks for solving Parametric PDEs | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 3352 | Agent-based Graph Neural Networks | 5.60 | 5.60 | 0.00 | [5, 6, 3, 6, 8]
|
| 3353 | Generating Adversarial Examples with Task Oriented Multi-Objective Optimization | 5.50 | 5.50 | 0.00 | [6, 5, 8, 3]
|
| 3354 | On the Performance of Temporal Difference Learning With Neural Networks | 6.33 | 6.25 | -0.08 | [6, 5, 6, 8]
|
| 3355 | Certified Defences Against Adversarial Patch Attacks on Semantic Segmentation | 6.00 | 6.25 | 0.25 | [6, 5, 6, 8]
|
| 3356 | Markup-to-Image Diffusion Models with Scheduled Sampling | 5.75 | 5.75 | 0.00 | [3, 8, 6, 6]
|
| 3357 | ADVERSARIALLY BALANCED REPRESENTATION FOR CONTINUOUS TREATMENT EFFECT ESTIMATION | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 3358 | Efficient Reward Poisoning Attacks on Online Deep Reinforcement Learning | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 3359 | How Much Space Has Been Explored? Measuring the Chemical Space Covered by Databases and Machine-Generated Molecules | 6.00 | 6.25 | 0.25 | [5, 6, 8, 6]
|
| 3360 | Semantic Video Synthesis from Video Scene Graphs | 5.00 | 5.00 | 0.00 | [6, 5, 6, 3]
|
| 3361 | D-CIPHER: Discovery of Closed-form Partial Differential Equations | 4.67 | 4.67 | 0.00 | [8, 3, 3]
|
| 3362 | Towards Identification of Microaggressions in real-life and Scripted conversations, using Context-Aware Machine Learning Techniques. | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 3363 | UNIFIED-IO: A Unified Model for Vision, Language, and Multi-modal Tasks | 7.50 | 7.50 | 0.00 | [8, 8, 6, 8]
|
| 3364 | Benchmarking Offline Reinforcement Learning on Real-Robot Hardware | 7.00 | 7.00 | 0.00 | [6, 6, 8, 8]
|
| 3365 | CUDA: Curriculum of Data Augmentation for Long-tailed Recognition | 5.80 | 6.20 | 0.40 | [6, 5, 8, 6, 6]
|
| 3366 | Understanding new tasks through the lens of training data via exponential tilting | 5.67 | 6.00 | 0.33 | [6, 6, 6]
|
| 3367 | Neighborhood Gradient Clustering: An Efficient Decentralized Learning Method for Non-IID Data Distributions | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3368 | Equilibrium-finding via exploitability descent with learned best-response functions | 5.25 | 5.50 | 0.25 | [3, 6, 8, 5]
|
| 3369 | A Unified Framework for Comparing Learning Algorithms | 4.75 | 5.25 | 0.50 | [5, 3, 8, 5]
|
| 3370 | Neural Network Approximations of PDEs Beyond Linearity: Representational Perspective | 5.50 | 5.75 | 0.25 | [8, 6, 6, 3]
|
| 3371 | Calibrating Sequence likelihood Improves Conditional Language Generation | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 3372 | Masked inverse folding with sequence transfer for protein representation learning | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 3373 | Convolutions are competitive with transformers for protein sequence pretraining | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 3374 | Learning differentiable solvers for systems with hard constraints | 5.00 | 5.00 | 0.00 | [6, 3, 3, 8]
|
| 3375 | FedDAR: Federated Domain-Aware Representation Learning | 5.25 | 5.25 | 0.00 | [3, 6, 6, 6]
|
| 3376 | KL-Entropy-Regularized RL with a Generative Model is Minimax Optimal | 4.75 | 4.75 | 0.00 | [5, 3, 5, 6]
|
| 3377 | Learning to Estimate Shapley Values with Vision Transformers | 6.50 | 6.50 | 0.00 | [5, 8, 8, 5]
|
| 3378 | No Double Descent in PCA: Training and Pre-Training in High Dimensions | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 3379 | Predicting Drug Repurposing Candidates and Their Mechanisms from A Biomedical Knowledge Graph | 4.33 | 4.67 | 0.33 | [3, 5, 6]
|
| 3380 | ProGen2: Exploring the Boundaries of Protein Language Models | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3381 | Interval Bound Interpolation for Few-shot Learning with Few Tasks | 5.25 | 5.50 | 0.25 | [6, 5, 5, 6]
|
| 3382 | A framework for benchmarking Class-out-of-distribution detection and its application to ImageNet | 7.33 | 7.33 | 0.00 | [6, 8, 8]
|
| 3383 | Data Poisoning Attacks Against Multimodal Encoders | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 3384 | SlotFormer: Unsupervised Visual Dynamics Simulation with Object-Centric Models | 6.33 | 7.33 | 1.00 | [8, 8, 6]
|
| 3385 | CEPD: Co-Exploring Pruning and Decomposition for Compact DNN Models | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5, 5]
|
| 3386 | Simplifying Model-based RL: Learning Representations, Latent-space Models, and Policies with One Objective | 6.00 | 6.40 | 0.40 | [6, 6, 8, 6, 6]
|
| 3387 | Tessellated Neural Networks: A Robust Defence against Adversarial Attacks | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 3388 | Retrieval-based Controllable Molecule Generation | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 3389 | ELRT: Towards Efficient Low-Rank Training for Compact Neural Networks | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 3390 | InfoOT: Information Maximizing Optimal Transport | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 3391 | To be robust and to be fair: aligning fairness with robustness | 4.25 | 4.25 | 0.00 | [3, 3, 3, 8]
|
| 3392 | Posterior Sampling Model-based Policy Optimization under Approximate Inference | 5.75 | 5.75 | 0.00 | [6, 6, 8, 3]
|
| 3393 | Causal discovery from conditionally stationary time series | 5.00 | 4.75 | -0.25 | [6, 5, 3, 5]
|
| 3394 | Fair Clustering via Equalized Confidence | 4.25 | 4.25 | 0.00 | [5, 3, 3, 6]
|
| 3395 | Learning for Edge-Weighted Online Bipartite Matching with Robustness Guarantees | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 3396 | Tangential Wasserstein Projections | 5.25 | 5.25 | 0.00 | [6, 6, 6, 3]
|
| 3397 | Data Drift Correction via Time-varying Importance Weight Estimator | 5.33 | 5.00 | -0.33 | [5, 3, 6, 5, 6, 5]
|
| 3398 | Analytical Composition of Differential Privacy via the Edgeworth Accountant | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 3399 | Policy-Induced Self-Supervision Improves Representation Finetuning in Visual RL | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 3400 | Deep Generative Symbolic Regression | 6.25 | 6.25 | 0.00 | [6, 8, 6, 5]
|
| 3401 | What Can we Learn From The Selective Prediction And Uncertainty Estimation Performance Of 523 Imagenet Classifiers? | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 3402 | Solving and Learning non-Markovian Stochastic Control problems in continuous-time with Neural RDEs | 5.33 | 5.00 | -0.33 | [5, 5, 5]
|
| 3403 | Spatio-temporal Self-Attention for Egocentric 3D Pose Estimation | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 3404 | MAE are Secretly Efficient Learners | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 3405 | RNAS-CL: Robust Neural Architecture Search by Cross-Layer Knowledge Distillation | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3406 | Multi-Agent Policy Transfer via Task Relationship Modeling | 5.00 | 5.00 | 0.00 | [6, 3, 6, 5]
|
| 3407 | When does Bias Transfer in Transfer Learning? | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 3408 | Predictor-corrector algorithms for stochastic optimization under gradual distribution shift | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 3409 | AIM: Adapting Image Models for Efficient Video Understanding | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 3410 | Impossibly Good Experts and How to Follow Them | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 3411 | On Convergence of Average-Reward Off-Policy Control Algorithms in Weakly-Communicating MDPs | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 3412 | Distributionally Robust Post-hoc Classifiers under Prior Shifts | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 3413 | Transformer Meets Boundary Value Inverse Problems | 5.75 | 5.75 | 0.00 | [5, 5, 5, 8]
|
| 3414 | Diagnosing and exploiting the computational demands of videos games for deep reinforcement learning | 4.25 | 4.25 | 0.00 | [6, 3, 3, 5]
|
| 3415 | NeuralPCG: Learning Preconditioner for Solving Partial Differential Equations with Graph Neural Network | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3416 | Learning Dynamic Query Combinations for Transformer-based Object Detection and Segmentation | 5.50 | 6.00 | 0.50 | [6, 8, 5, 5]
|
| 3417 | Cross-Quality Few-Shot Transfer for Alloy Yield Strength Prediction: A New Material Science Benchmark and An Integrated Optimization Framework | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 3418 | Parameter-varying neural ordinary differential equations with partition-of-unity networks | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 3419 | Robust Reinforcement Learning with Distributional Risk-averse formulation | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 3420 | Unicom: Universal and Compact Representation Learning for Image Retrieval | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 3421 | The Reward Hypothesis is False | 5.17 | 5.17 | 0.00 | [5, 5, 8, 5, 5, 3]
|
| 3422 | Convergence of Generative Deep Linear Networks Trained with Bures-Wasserstein Loss | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3423 | Diffusion Probabilistic Fields | 6.25 | 6.25 | 0.00 | [6, 8, 5, 6]
|
| 3424 | Improving Information Retention in Large Scale Online Continual Learning | 4.25 | 4.25 | 0.00 | [5, 3, 6, 3]
|
| 3425 | Landscape Learning for Neural Network Inversion | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 3426 | Stochastic Multi-Person 3D Motion Forecasting | 5.75 | 5.75 | 0.00 | [3, 6, 6, 8]
|
| 3427 | ON INJECTING NOISE DURING INFERENCE | 4.25 | 4.25 | 0.00 | [5, 3, 6, 3]
|
| 3428 | LEARNING THE SPECTROGRAM TEMPORAL RESOLUTION FOR AUDIO CLASSIFICATION | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 3429 | Beyond calibration: estimating the grouping loss of modern neural networks | 5.67 | 5.67 | 0.00 | [3, 6, 8]
|
| 3430 | Hybrid RL: Using both offline and online data can make RL efficient | 4.50 | 5.75 | 1.25 | [6, 6, 5, 6]
|
| 3431 | Spotting Expressivity Bottlenecks and Fixing Them Optimally | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3432 | Scalable and Privacy-enhanced Graph Generative Model for Graph Neural Networks | 4.50 | 4.50 | 0.00 | [3, 6, 6, 3]
|
| 3433 | Model ensemble instead of prompt fusion: a sample-specific knowledge transfer method for few-shot prompt tuning | 6.50 | 6.50 | 0.00 | [6, 6, 6, 8]
|
| 3434 | Entropy-Regularized Model-Based Offline Reinforcement Learning | 4.80 | 4.80 | 0.00 | [5, 5, 5, 3, 6]
|
| 3435 | Reward-free Policy Learning through Active Human Involvement | 4.75 | 4.00 | -0.75 | [3, 5, 5, 3]
|
| 3436 | Automaton Distillation: A Neuro-Symbolic Transfer Learning Approach for Deep RL | 2.50 | 2.50 | 0.00 | [3, 3, 3, 1]
|
| 3437 | Sign and Basis Invariant Networks for Spectral Graph Representation Learning | 8.00 | 8.00 | 0.00 | [8, 8, 8, 8]
|
| 3438 | Certification of Attribution Robustness for Euclidean Distance and Cosine Similarity Measure | 3.25 | 3.25 | 0.00 | [3, 6, 3, 1]
|
| 3439 | Diffusing Graph Attention | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3440 | Sequential Latent Variable Models for Few-Shot High-Dimensional Time-Series Forecasting | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 3441 | Code Translation with Compiler Representations | 6.50 | 6.50 | 0.00 | [5, 5, 6, 10]
|
| 3442 | GAIN: On the Generalization of Instructional Action Understanding | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 3443 | Deep Reinforcement learning on Adaptive Pairwise Critic and Asymptotic Actor | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 3444 | Model-based Value Exploration in Actor-critic Deep Reinforcement Learning | 4.00 | 3.00 | -1.00 | [3, 3, 3, 3]
|
| 3445 | Omnigrok: Grokking Beyond Algorithmic Data | 7.50 | 8.00 | 0.50 | [8, 8, 8, 8]
|
| 3446 | ManyDG: Many-domain Generalization for Healthcare Applications | 6.40 | 6.40 | 0.00 | [3, 8, 8, 5, 8]
|
| 3447 | Adversarial Detector for Decision Tree Ensembles Using Representation Learning | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 3448 | Learning with Instance-Dependent Label Noise: Balancing Accuracy and Fairness | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 3449 | Flow Annealed Importance Sampling Bootstrap | 6.60 | 6.50 | -0.10 | [6, 8, 8, 6, 5, 6]
|
| 3450 | Learning with MISELBO: The Mixture Cookbook | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 3451 | DecAF: Joint Decoding of Answers and Logical Forms for Question Answering over Knowledge Bases | 6.00 | 6.00 | 0.00 | [5, 6, 5, 8]
|
| 3452 | NANSY++: Unified Voice Synthesis with Neural Analysis and Synthesis | 6.00 | 6.00 | 0.00 | [6, 8, 5, 5]
|
| 3453 | Robust Attention for Contextual Biased Visual Recognition | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 3454 | A unified optimization framework of ANN-SNN Conversion: towards optimal mapping from activation values to firing rates | 5.50 | 5.50 | 0.00 | [1, 8, 5, 8]
|
| 3455 | Multi-Objective Reinforcement Learning: Convexity, Stationarity and Pareto Optimality | 5.75 | 5.75 | 0.00 | [6, 3, 6, 8]
|
| 3456 | Point-based Molecular Representation Learning from Conformers | 2.50 | 2.50 | 0.00 | [3, 1, 5, 1]
|
| 3457 | Continual Unsupervised Disentangling of Self-Organizing Representations | 5.75 | 6.50 | 0.75 | [6, 6, 8, 6]
|
| 3458 | Inducing Gaussian Process Networks | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3459 | Causal Inference via Nonlinear Variable Decorrelation in Healthcare | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 3460 | Monotonicity and Double Descent in Uncertainty Estimation with Gaussian Processes | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 3461 | Fooling SHAP with Stealthily Biased Sampling | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 3462 | Towards Realtime Distributed Virtual Flow Meter via Compressed Continual Learning | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 3463 | Asynchronous Gradient Play in Zero-Sum Multi-agent Games | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 3464 | Novel View Synthesis with Diffusion Models | 6.25 | 6.25 | 0.00 | [5, 6, 6, 8]
|
| 3465 | DM-NeRF: 3D Scene Geometry Decomposition and Manipulation from 2D Images | 5.00 | 5.00 | 0.00 | [8, 6, 3, 3]
|
| 3466 | Robust Neural ODEs via Contractivity-promoting Regularization | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 3467 | Analyzing the Effects of Classifier Lipschitzness on Explainers | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 3468 | Complex-Target-Guided Open-Domain Conversation based on offline reinforcement learning | 4.75 | 4.75 | 0.00 | [3, 3, 8, 5]
|
| 3469 | Trading Information between Latents in Hierarchical Variational Autoencoders | 5.50 | 5.50 | 0.00 | [3, 6, 5, 8]
|
| 3470 | "Why did the Model Fail?": Attributing Model Performance Changes to Distribution Shifts | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 3471 | VC Theoretical Explanation of Double Descent | 3.75 | 3.75 | 0.00 | [6, 3, 3, 3]
|
| 3472 | Points2NeRF: Generating Neural Radiance Fields from 3D point cloud | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 3473 | Imitation Improvement Learning for Large-scale Capacitated Vehicle Routing Problems | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 3474 | Enhance Local Consistency for Free: A Multi-Step Inertial Momentum Approach | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 3475 | SYNG4ME: Model Evaluation using Synthetic Test Data | 5.25 | 5.50 | 0.25 | [5, 5, 6, 6]
|
| 3476 | Take One Gram of Neural Features, Get Enhanced Group Robustness | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 3477 | LMC: Fast Training of GNNs via Subgraph Sampling with Provable Convergence | 6.25 | 7.50 | 1.25 | [8, 6, 8, 8]
|
| 3478 | DEEPER-GXX: DEEPENING ARBITRARY GNNS | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 3479 | Music-to-Text Synaesthesia: Generating Descriptive Text from Music Recordings | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 3480 | ISAAC Newton: Input-based Approximate Curvature for Newton"s Method | 6.00 | 6.00 | 0.00 | [8, 5, 5]
|
| 3481 | Learning Human-Compatible Representations for Case-Based Decision Support | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 3482 | Long-Tailed Learning Requires Feature Learning | 5.25 | 6.00 | 0.75 | [5, 5, 6, 8]
|
| 3483 | Understanding Hindsight Goal Relabeling Requires Rethinking Divergence Minimization | 4.50 | 4.50 | 0.00 | [5, 6, 6, 1]
|
| 3484 | DoE2Vec: Representation Learning for Exploratory Landscape Analysis | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 3485 | How to Exploit Hyperspherical Embeddings for Out-of-Distribution Detection? | 6.25 | 6.50 | 0.25 | [6, 8, 6, 6]
|
| 3486 | Inferring Causal Relations between Temporal Events | 2.50 | 2.50 | 0.00 | [3, 3, 3, 1]
|
| 3487 | AnyDA: Anytime Domain Adaptation | 6.50 | 6.50 | 0.00 | [6, 8, 6, 6]
|
| 3488 | Improving Deep Regression with Ordinal Entropy | 6.75 | 6.75 | 0.00 | [8, 3, 8, 8]
|
| 3489 | Revisiting Pretraining Objectives for Tabular Deep Learning | 5.25 | 5.75 | 0.50 | [8, 6, 3, 6]
|
| 3490 | OoD-Control: Out-of-Distribution Generalization for Adaptive UAV Flight Control | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3491 | AdaptFSP: Adaptive Fictitious Self Play | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3492 | A Robust Stacking Framework for Training Deep Graph Models with Multifaceted Node Features | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 3493 | VLG: General Video Recognition with Web Textual Knowledge | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3494 | Unified Discrete Diffusion for Simultaneous Vision-Language Generation | 5.75 | 5.75 | 0.00 | [5, 5, 8, 5]
|
| 3495 | Take 5: Interpretable Image Classification with a Handful of Features | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3496 | Uncertainty-based Multi-Task Data Sharing for Offline Reinforcement Learning | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 3497 | On the Fast Convergence of Unstable Reinforcement Learning Problems | 5.33 | 4.67 | -0.67 | [3, 6, 5]
|
| 3498 | Iterative Patch Selection for High-Resolution Image Recognition | 6.00 | 6.00 | 0.00 | [3, 5, 8, 8]
|
| 3499 | HyperMAML: Few-Shot Adaptation of Deep Models with Hypernetworks | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 3500 | Conditional Antibody Design as 3D Equivariant Graph Translation | 8.00 | 8.00 | 0.00 | [8, 8, 8, 8]
|
| 3501 | Robust Constrained Reinforcement Learning | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 3502 | Differentiable Meta-Logical Programming | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 3503 | FaceMAE: Privacy-Preserving Face Recognition via Masked Autoencoders | 5.00 | 5.00 | 0.00 | [6, 3, 5, 6, 5]
|
| 3504 | Fuzzy Alignments in Directed Acyclic Graph for Non-Autoregressive Machine Translation | 6.33 | 6.33 | 0.00 | [8, 5, 6]
|
| 3505 | Efficient Federated Domain Translation | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 3506 | EIT: Enhanced Interactive Transformer for Sequence Generation | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 3507 | Single-Stage Open-world Instance Segmentation with Cross-task Consistency Regularization | 5.25 | 5.25 | 0.00 | [3, 5, 5, 8]
|
| 3508 | What can be learnt with wide convolutional neural networks? | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 3509 | 3D Segmenter: 3D Transformer based Semantic Segmentation via 2D Panoramic Distillation | 6.00 | 6.00 | 0.00 | [8, 5, 6, 5]
|
| 3510 | Towards Skilled Population Curriculum for MARL | 5.50 | 5.75 | 0.25 | [6, 5, 6, 6]
|
| 3511 | Logit Clipping for Robust Learning against Label Noise | 5.00 | 5.00 | 0.00 | [3, 6, 8, 3]
|
| 3512 | Clifford Neural Layers for PDE Modeling | 6.75 | 6.75 | 0.00 | [6, 8, 8, 5]
|
| 3513 | GOOD: Exploring geometric cues for detecting objects in an open world | 6.00 | 6.00 | 0.00 | [5, 5, 8, 6]
|
| 3514 | Enhancing Robustness of Deep Networks Based on a Two-phase Model of Their Training with Noisy Labels | 3.33 | 3.33 | 0.00 | [6, 1, 3]
|
| 3515 | Bringing Saccades and Fixations into Self-supervised Video Representation Learning | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 3516 | Improve learning combining crowdsourced labels by weighting Areas Under the Margin | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 3517 | Distraction is All You Need For Fairness | 3.75 | 3.75 | 0.00 | [3, 3, 6, 3]
|
| 3518 | Learning Diverse and Effective Policies with Non-Markovian Rewards | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 3519 | Emergent world representations: Exploring a sequence model trained on a synthetic task | 6.25 | 6.75 | 0.50 | [8, 8, 3, 8]
|
| 3520 | Programmatically Grounded, Compositionally Generalizable Robotic Manipulation | 6.25 | 6.25 | 0.00 | [3, 8, 8, 6]
|
| 3521 | M$^3$Video: Masked Motion Modeling for Self-Supervised Video Representation Learning | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3522 | ObPose: Leveraging Pose for Object-Centric Scene Inference and Generation in 3D | 4.75 | 4.75 | 0.00 | [5, 5, 3, 6]
|
| 3523 | FedCL: Critical Learning Periods-aware Adaptive Client Selection in Federated Learning | 5.00 | 5.25 | 0.25 | [5, 5, 6, 5]
|
| 3524 | TabCaps: A Capsule Neural Network for Tabular Data Classification with BoW Routing | 6.00 | 6.00 | 0.00 | [8, 5, 5]
|
| 3525 | Learning Instance-Solution Operator For Optimal Control | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 3526 | CorruptEncoder: Data Poisoning Based Backdoor Attacks to Contrastive Learning | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 3527 | Learning Transferable Spatiotemporal Representations from Natural Script Knowledge | 4.25 | 4.25 | 0.00 | [3, 3, 5, 6]
|
| 3528 | Heterogeneous Continual Learning | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 3529 | Decentralized Online Bandit Optimization on Directed Graphs with Regret Bounds | 5.00 | 5.00 | 0.00 | [6, 8, 3, 3]
|
| 3530 | BAMBI: Vertical Federated Bilevel Optimization with Privacy-Preserving and Computation Efficiency | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 3531 | Revitalize Region Feature for Democratizing Video-language Pre-training of Retrieval | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 3532 | Local Attention Layers for Vision Transformers | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 3533 | MESSAGENET: MESSAGE CLASSIFICATION USING NATURAL LANGUAGE PROCESSING AND META-DATA | 2.00 | 2.00 | 0.00 | [3, 1, 3, 1]
|
| 3534 | Koopman neural operator for learning non-linear partial differential equations | 6.00 | 6.00 | 0.00 | [8, 5, 5]
|
| 3535 | Regularizing hard examples improves robustness | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 3536 | Universal approximation and model compression for radial neural networks | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 3537 | Momentum Diminishes the Effect of Spectral Bias in Physics-Informed Neural Networks | 4.50 | 4.50 | 0.00 | [6, 8, 1, 3]
|
| 3538 | MULTILEVEL XAI: VISUAL AND LINGUISTIC BONDED EXPLANATIONS | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 3539 | Efficient Evaluation of Adversarial Robustness for Deep Hashing based Retrieval | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3540 | An Exact Poly-Time Membership-Queries Algorithm for Extracting a Three-Layer ReLU Network | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 3541 | Neural Discrete Reinforcement Learning | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 3542 | CAB: Comprehensive Attention Benchmarking on Long Sequence Modeling | 6.00 | 6.25 | 0.25 | [8, 6, 5, 6]
|
| 3543 | miCSE: Mutual Information Contrastive Learning for Low-shot Sentence Embeddings | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 3544 | Formal Conceptual Views in Neural Networks | 3.75 | 3.75 | 0.00 | [3, 3, 3, 6]
|
| 3545 | Towards Understanding and Mitigating Dimensional Collapse in Heterogeneous Federated Learning | 6.75 | 6.75 | 0.00 | [5, 8, 8, 6]
|
| 3546 | A New Paradigm for Federated Structure Non-IID Subgraph Learning | 4.33 | 4.67 | 0.33 | [6, 3, 5]
|
| 3547 | An Intrinsic Dimension Perspective of Transformers for Sequential Modeling | 3.00 | 3.00 | 0.00 | [5, 3, 3, 1]
|
| 3548 | SketchKnitter: Vectorized Sketch Generation with Diffusion Models | 7.33 | 7.33 | 0.00 | [8, 8, 6]
|
| 3549 | Evidential Uncertainty and Diversity Guided Active Learning for Scene Graph Generation | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 3550 | ErGOT: entropy-regularized graph optimal transport | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3551 | Test-time recalibration of conformal predictors under distribution shift based on unlabeled examples | 3.50 | 4.00 | 0.50 | [3, 5, 3, 5]
|
| 3552 | TabDDPM: Modelling Tabular Data with Diffusion Models | 3.00 | 3.00 | 0.00 | [3, 5, 1, 3]
|
| 3553 | BED: Boundary-Enhanced Decoder for Chinese Word Segmentation | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 3554 | Gradient Inversion via Over-parameterized Convolutional Network in Federated Learning | 0.00 | 0.00 | 0.00 | Ratings not available yet
|
| 3555 | Memory-Augmented Variational Adaptation for Online Few-Shot Segmentation | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 3556 | Tailoring Language Generation Models under Total Variation Distance | 7.33 | 7.33 | 0.00 | [8, 6, 8]
|
| 3557 | SeqSHAP: Subsequence Level Shapley Value Explanations for Sequential Predictions | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 3558 | Newton Losses: Efficiently Including Second-Order Information into Gradient Descent | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 3559 | BPFL: Towards Efficient Byzantine-Robust and Provably Privacy-Preserving Federated Learning | 3.25 | 3.25 | 0.00 | [1, 5, 6, 1]
|
| 3560 | Understanding Masked Image Modeling via Learning Occlusion Invariant Feature | 3.75 | 3.75 | 0.00 | [1, 1, 8, 5]
|
| 3561 | Anisotropic Message Passing: Graph Neural Networks with Directional and Long-Range Interactions | 6.25 | 6.25 | 0.00 | [5, 8, 6, 6]
|
| 3562 | Learn Low-dimensional Shortest-path Representation of Large-scale and Complex Graphs | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 3563 | SYNC: SAFETY-AWARE NEURAL CONTROL FOR STABILIZING STOCHASTIC DELAY-DIFFERENTIAL EQUATIONS | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3564 | Byzantine-robust Decentralized Learning via ClippedGossip | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 3565 | From Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 3566 | A Model or 603 Exemplars: Towards Memory-Efficient Class-Incremental Learning | 6.75 | 7.50 | 0.75 | [8, 8, 8, 6]
|
| 3567 | Reinforcement learning for instance segmentation with high-level priors | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3568 | Differentiable Mathematical Programming for Object-Centric Representation Learning | 6.50 | 6.50 | 0.00 | [5, 8, 5, 8]
|
| 3569 | Transformers are Sample-Efficient World Models | 7.00 | 7.00 | 0.00 | [8, 6, 6, 8]
|
| 3570 | Considering Layerwise Importance in the Lottery Ticket Hypothesis | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3571 | Generalized Sum Pooling for Metric Learning | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 3572 | SAAL: Sharpness-Aware Active Learning | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 3573 | Scalable Subset Sampling with Neural Conditional Poisson Networks | 7.00 | 7.00 | 0.00 | [8, 6, 6, 8]
|
| 3574 | High probability error bounds of SGD in unbounded domain | 4.25 | 4.25 | 0.00 | [5, 3, 3, 6]
|
| 3575 | Improved Convergence of Differential Private SGD with Gradient Clipping | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 3576 | Learning Inductive Object-Centric Slot Initialization via Clustering | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 3577 | Group-level Brain Decoding with Deep Learning | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 3578 | QUANTILE-LSTM: A ROBUST LSTM FOR ANOMALY DETECTION | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 3579 | Mutual Information-guided Knowledge Transfer for Open-World Semi-Supervised Learning | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 3580 | RegQ: Convergent Q-Learning with Linear Function Approximation using Regularization | 3.75 | 3.75 | 0.00 | [6, 5, 1, 3]
|
| 3581 | Neural Field Discovery Disentangles Equivariance in Interacting Dynamical Systems | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 3582 | DIMENSION-REDUCED ADAPTIVE GRADIENT METHOD | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 3583 | Learning to Estimate Single-View Volumetric Flow Motions without 3D Supervision | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 3584 | Towards the Out-of-Distribution Generalization of Contrastive Self-Supervised Learning | 4.67 | 5.67 | 1.00 | [6, 6, 5]
|
| 3585 | Online Policy Optimization for Robust MDP | 5.00 | 5.00 | 0.00 | [6, 5, 6, 3]
|
| 3586 | Toeplitz Neural Network for Sequence Modeling | 6.00 | 6.00 | 0.00 | [8, 5, 8, 3]
|
| 3587 | An Adaptive Entropy-Regularization Framework for Multi-Agent Reinforcement Learning | 5.67 | 5.67 | 0.00 | [6, 8, 3]
|
| 3588 | Relative Positional Encoding Family via Unitary Transformation | 5.25 | 5.25 | 0.00 | [6, 6, 6, 3]
|
| 3589 | Revisiting Feature Acquisition Bias for Few-Shot Fine-Grained Image Classification | 5.00 | 5.00 | 0.00 | [6, 5, 6, 3]
|
| 3590 | ColoristaNet for Photorealistic Video Style Transfer | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 3591 | Auto-Encoding Adversarial Imitation Learning | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 3592 | $\Delta$-PINNs: physics-informed neural networks on complex geometries | 5.33 | 5.33 | 0.00 | [3, 5, 8]
|
| 3593 | On the Nonconvex Convergence of SGD | 2.50 | 2.50 | 0.00 | [3, 3, 1, 3]
|
| 3594 | BiTAT: Neural Network Binarization with Task-Dependent Aggregated Transformation | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 3595 | Dynamic Loss for Learning with Label Noise | 3.25 | 3.25 | 0.00 | [3, 1, 3, 6]
|
| 3596 | Memory of Unimaginable Outcomes in Experience Replay | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3597 | Temperature Schedules for self-supervised contrastive methods on long-tail data | 5.33 | 6.33 | 1.00 | [8, 5, 6]
|
| 3598 | Deep Learning on Implicit Neural Representations of Shapes | 6.00 | 6.00 | 0.00 | [5, 6, 5, 8]
|
| 3599 | Continual Vision-Language Representaion Learning with Off-Diagonal Information | 5.25 | 5.25 | 0.00 | [8, 3, 5, 5]
|
| 3600 | Learning Counterfactually Invariant Predictors | 6.00 | 6.00 | 0.00 | [5, 6, 5, 8]
|
| 3601 | Deep Reinforcement Learning for Cryptocurrency Trading: Practical Approach to Address Backtest Overfitting | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3602 | ImaginaryNet: Learning Object Detectors without Real Images and Annotations | 6.00 | 6.00 | 0.00 | [5, 6, 8, 5]
|
| 3603 | Don"t Throw Your Old Policies Away: Knowledge-based Policy Recycling Protects Against Adversarial Attacks | 4.75 | 4.75 | 0.00 | [5, 3, 3, 8]
|
| 3604 | NÜWA-LIP: Language-guided Image Inpainting with Defect-free VQGAN | 4.75 | 4.75 | 0.00 | [5, 6, 3, 5]
|
| 3605 | Contextual bandits with concave rewards, and an application to fair ranking | 6.75 | 6.75 | 0.00 | [8, 5, 6, 8]
|
| 3606 | Contrastive Adversarial Loss for Point Cloud Reconstruction | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 3607 | Low-complexity Deep Video Compression with A Distributed Coding Architecture | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 3608 | When Few-shot Meets Cross-domain Object Detection: Learning Instance-level Class Prototypes for Knowledge Transfer | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 3609 | Gradient Boosting Performs Gaussian Process Inference | 5.67 | 6.00 | 0.33 | [6, 6, 6]
|
| 3610 | Constrained Reinforcement Learning for Safety-Critical Tasks via Scenario-Based Programming | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 3611 | TGP: Explainable Temporal Graph Neural Networks for Personalized Recommendation | 3.00 | 3.00 | 0.00 | [3, 5, 3, 1]
|
| 3612 | When is Adversarial Robustness Transferable? | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 3613 | COFS: COntrollable Furniture layout Synthesis | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 3614 | Distribution Shift Detection for Deep Neural Networks | 5.67 | 5.75 | 0.08 | [6, 6, 5, 6]
|
| 3615 | Learning Zero-Shot Cooperation with Humans, Assuming Humans Are Biased | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 3616 | SUG: Single-dataset Unified Generalization for 3D Point Cloud Classification | 5.33 | 5.33 | 0.00 | [5, 8, 3]
|
| 3617 | Efficient Policy Space Response Oracles | 3.00 | 3.00 | 0.00 | [1, 5, 3]
|
| 3618 | An Optimal Transport Perspective on Unpaired Image Super-Resolution | 5.50 | 5.50 | 0.00 | [3, 5, 6, 8]
|
| 3619 | A Functional Perspective on Multi-Layer Out-of-Distribution Detection | 5.25 | 5.50 | 0.25 | [5, 5, 6, 6]
|
| 3620 | The Continuous CNN: from Task-Specific to Unified CNN Architecture | 4.50 | 4.50 | 0.00 | [6, 6, 3, 3]
|
| 3621 | Ahead-of-Time P-Tuning | 4.75 | 4.75 | 0.00 | [5, 5, 3, 6]
|
| 3622 | MAXENT LOSS: CONSTRAINED MAXIMUM ENTROPY FOR CALIBRATING DEEP NEURAL NETWORKS | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 3623 | Unsupervised Threshold Learning with "$L$"-trend Prior For Visual Anomaly Detection | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 3624 | Planckian Jitter: countering the color-crippling effects of color jitter on self-supervised training | 6.25 | 6.25 | 0.00 | [8, 6, 8, 3]
|
| 3625 | Efficient and Stealthy Backdoor Attack Triggers are Close at Hand | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 3626 | SimST: A GNN-Free Spatio-Temporal Learning Framework for Traffic Forecasting | 4.75 | 4.75 | 0.00 | [3, 5, 5, 6]
|
| 3627 | Property Inference Attacks Against t-SNE Plots | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 3628 | Physically Plausible and Conservative Solutions to Navier-Stokes Equations Using Physics-Informed CNNs | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 3629 | GAMR: A Guided Attention Model for (visual) Reasoning | 6.25 | 6.25 | 0.00 | [5, 8, 6, 6]
|
| 3630 | On the Connection between Fisher"s Criterion and Shannon"s Capacity: Theoretical Concepts and Implementation | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 3631 | Pixel-Aligned Non-parametric Hand Mesh Reconstruction | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 3632 | Voint Cloud: Multi-View Point Cloud Representation for 3D Understanding | 6.50 | 6.50 | 0.00 | [6, 6, 6, 8]
|
| 3633 | Is the Deep Model Representation Sparse and Symbolic with Causal Patterns? | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 3634 | Learning QUBO Forms in Quantum Annealing | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 3635 | Understanding Gradient Regularization in Deep Learning: Efficient Finite-Difference Computation and Implicit Bias | 5.00 | 5.00 | 0.00 | [3, 6, 6, 5]
|
| 3636 | Approximate Nearest Neighbor Search through Modern Error-Correcting Codes | 5.75 | 5.75 | 0.00 | [3, 6, 8, 6]
|
| 3637 | Social and environmental impact of recent developments in machine learning on biology and chemistry research | 4.75 | 5.25 | 0.50 | [5, 8, 3, 5]
|
| 3638 | TransformMix: Learning Transformation and Mixing Strategies for Sample-mixing Data Augmentation | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 3639 | When to Make and Break Commitments? | 6.33 | 7.00 | 0.67 | [8, 8, 8, 6, 5]
|
| 3640 | Generalization bounds and algorithms for estimating the effect of multiple treatments and dosage | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 3641 | DENSE RGB SLAM WITH NEURAL IMPLICIT MAPS | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 3642 | Monocular Scene Reconstruction with 3D SDF Transformers | 6.25 | 6.00 | -0.25 | [6, 5, 8, 5]
|
| 3643 | Learning Heterogeneous Interaction Strengths by Trajectory Prediction with Graph Neural Network | 5.50 | 5.75 | 0.25 | [6, 6, 5, 6]
|
| 3644 | From $t$-SNE to UMAP with contrastive learning | 6.00 | 6.00 | 0.00 | [6, 3, 8, 5, 8]
|
| 3645 | On the optimal precision of GANs | 5.00 | 5.00 | 0.00 | [6, 6, 5, 5, 3]
|
| 3646 | Disentangled Knowledge Transfer: A New Perspective for Personalized Federated Learning | 4.50 | 4.75 | 0.25 | [5, 6, 5, 3]
|
| 3647 | D4AM: A General Denoising Framework for Downstream Acoustic Models | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 3648 | Fully Continuous Gated Recurrent Units For processing Time Series | 3.60 | 3.60 | 0.00 | [3, 1, 5, 6, 3]
|
| 3649 | Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning | 6.00 | 6.33 | 0.33 | [6, 5, 8, 6, 5, 8]
|
| 3650 | On Intriguing Layer-Wise Properties of Robust Overfitting in Adversarial Training | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 3651 | Does Federated Learning Really Need Backpropagation? | 4.00 | 5.33 | 1.33 | [3, 5, 8]
|
| 3652 | Teaching Others is Teaching Yourself Regularization For Controllable Language Models | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 3653 | Prompt Generation Networks for Efficient Adaptation of Frozen Vision Transformers | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 3654 | Saliency-guided Vision Transformer for Few-shot Keypoint Detection | 4.67 | 4.33 | -0.33 | [3, 5, 5]
|
| 3655 | Active Learning with Partial Labels | 5.25 | 5.25 | 0.00 | [5, 3, 8, 5]
|
| 3656 | Specialization of Sub-paths for Adaptive Depth Networks | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 3657 | Towards Effective and Interpretable Human-Agent Collaboration in MOBA Games: A Communication Perspective | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 3658 | Fine-Grained Image Retrieval with Neighbor-Attention Label Correction | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3659 | How Normalization and Weight Decay Can Affect SGD? Insights from a Simple Normalized Model | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 3660 | Closing the Performance Gap between Cumbersome and Lightweight Contrastive Models | 4.00 | 4.00 | 0.00 | [3, 5, 6, 3, 3]
|
| 3661 | DCAPS: Dual Cross-Attention Coupled with Stabilizer for Few-Shot Common Action Localization | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 3662 | Generalize Learned Heuristics to Solve Large-scale Vehicle Routing Problems in Real-time | 6.00 | 6.00 | 0.00 | [5, 8, 5, 6]
|
| 3663 | MUTUAL EXCLUSIVE MODULATOR FOR LONG-TAILED RECOGNITION | 4.40 | 4.40 | 0.00 | [5, 3, 3, 5, 6]
|
| 3664 | RetinexUTV: ROBUST RETINEX MODEL WITH UNFOLDING TOTAL VARIATION | 3.00 | 3.00 | 0.00 | [5, 3, 1, 3]
|
| 3665 | Adapting Pre-trained Language Models for Quantum Natural Language Processing | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3666 | Towards the Generalization of Contrastive Self-Supervised Learning | 6.00 | 6.00 | 0.00 | [6, 10, 6, 3, 5]
|
| 3667 | Towards Controllable Policy through Goal-Masked Transformers | 2.33 | 2.33 | 0.00 | [1, 3, 3]
|
| 3668 | Fed-CBS: Heterogeneity-Aware Client Sampling Mechanism for Federated Learning via Class-Imbalance Reduction | 5.25 | 4.80 | -0.45 | [3, 3, 5, 8, 5]
|
| 3669 | Comparative Analysis between Vision Transformers and CNNs from the view of Neuroscience | 2.50 | 2.50 | 0.00 | [3, 3, 1, 3]
|
| 3670 | Uncertainty-Aware Meta-Learning for Multimodal Task Distributions | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 3671 | Neural Operator Variational Inference based on Regularized Stein Discrepancy for Deep Gaussian Processes | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 3672 | On the complexity of nonsmooth automatic differentiation | 6.33 | 6.67 | 0.33 | [8, 6, 6]
|
| 3673 | CO3: Cooperative Unsupervised 3D Representation Learning for Autonomous Driving | 5.00 | 5.00 | 0.00 | [3, 6, 3, 8]
|
| 3674 | Bag of Tricks for Unsupervised Text-to-Speech | 7.33 | 7.33 | 0.00 | [6, 8, 8]
|
| 3675 | FedSpeed: Larger Local Interval, Less Communication Round, and Higher Generalization Accuracy | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 3676 | Holistically Explainable Vision Transformers | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 3677 | Delving into Discrete Normalizing Flows on SO(3) Manifold for Probabilistic Rotation Modeling | 5.25 | 5.25 | 0.00 | [5, 8, 3, 5]
|
| 3678 | Neural Volumetric Mesh Generator | 5.50 | 5.50 | 0.00 | [5, 8, 3, 6]
|
| 3679 | PathFusion: Path-consistent Lidar-Camera Deep Feature Fusion | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3680 | DADAO: Decoupled Accelerated Decentralized Asynchronous Optimization | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 3681 | Enabling Probabilistic Inference on Large-Scale Spiking Neural Networks | 5.25 | 5.25 | 0.00 | [5, 3, 5, 8]
|
| 3682 | Less is More: Identifying the Cherry on the Cake for Dynamic Networks | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 3683 | Advancing Radiograph Representation Learning with Masked Record Modeling | 6.75 | 7.00 | 0.25 | [8, 6, 6, 8]
|
| 3684 | Instance-wise Batch Label Restoration via Gradients in Federated Learning | 4.67 | 5.33 | 0.67 | [5, 8, 3]
|
| 3685 | Self Check-in: Tight Privacy Amplification for Practical Distributed Learning | 3.50 | 3.50 | 0.00 | [3, 5, 5, 1]
|
| 3686 | Re-parameterizing Your Optimizers rather than Architectures | 6.25 | 6.25 | 0.00 | [6, 8, 8, 3]
|
| 3687 | Protein Representation Learning via Knowledge Enhanced Primary Structure Reasoning | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 3688 | Provable Unsupervised Data Sharing for Offline Reinforcement Learning | 4.33 | 5.67 | 1.33 | [3, 6, 8]
|
| 3689 | Federated Learning for Inference at Anytime and Anywhere | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 3690 | Modeling Sequential Sentence Relation to Improve Cross-lingual Dense Retrieval | 5.75 | 5.75 | 0.00 | [3, 8, 6, 6]
|
| 3691 | Boosting Discriminative Visual Representation Learning with Scenario-Agnostic Mixup | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3692 | A Robustly and Effectively Optimized Pretraining Approach for Masked Autoencoder | 2.50 | 2.50 | 0.00 | [3, 3, 3, 1]
|
| 3693 | Diffusion Posterior Sampling for General Noisy Inverse Problems | 7.00 | 7.00 | 0.00 | [8, 6, 8, 6]
|
| 3694 | Low-Rank Graph Neural Networks Inspired by the Weak-balance Theory in Social Networks | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 3695 | Do We Need Neural Collapse? Learning Diverse Features for Fine-grained and Long-tail Classification | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 3696 | Node-Level Membership Inference Attacks Against Graph Neural Networks | 4.25 | 4.25 | 0.00 | [3, 5, 6, 3]
|
| 3697 | HRBP: Hardware-friendly Regrouping towards Block-wise Pruning for Sparse Training | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 3698 | MAGA: Modeling a Group Action | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 3699 | Learning in Compressed Domain via Knowledge Transfer | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3700 | DepthFL : Depthwise Federated Learning for Heterogeneous Clients | 6.00 | 6.00 | 0.00 | [8, 5, 6, 5]
|
| 3701 | Masked Image Modeling with Denoising Contrast | 6.33 | 6.33 | 0.00 | [6, 5, 8]
|
| 3702 | Holding Monotonic Improvement and Generality for Multi-Agent Proximal Policy Optimization | 4.25 | 4.25 | 0.00 | [3, 8, 3, 3]
|
| 3703 | Monkeypox with Cross Infection Hypothesis via Epidemiological Mode | 2.33 | 2.33 | 0.00 | [1, 3, 3]
|
| 3704 | LPMARL: Linear Programming based Implicit Task Assignment for Hierarchical Multi-agent Reinforcement Learning | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 3705 | Transmission Dynamics of Hepatitis B: Analysis and Control | 2.50 | 2.50 | 0.00 | [3, 1, 3, 3]
|
| 3706 | Mass-Editing Memory in a Transformer | 6.50 | 6.50 | 0.00 | [8, 6, 6, 6]
|
| 3707 | Enhancement and Numerical Assessment of Novel SARS-CoV-2 Virus Transmission Model | 2.50 | 2.50 | 0.00 | [3, 1, 3, 3]
|
| 3708 | GoBigger: A Scalable Platform for Cooperative-Competitive Multi-Agent Interactive Simulation | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 3709 | Masked Unsupervised Self-training for Label-free Image Classification | 7.17 | 7.50 | 0.33 | [8, 5, 8, 8, 8, 8]
|
| 3710 | Recursion of Thought: Divide and Conquer Reasoning with Language Models | 4.00 | 4.00 | 0.00 | [3, 1, 8]
|
| 3711 | GeneFace: Generalized and High-Fidelity Audio-Driven 3D Talking Face Synthesis | 5.60 | 6.20 | 0.60 | [6, 6, 8, 6, 5]
|
| 3712 | Environment Partitioning For Invariant Learning By Decorrelation | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 3713 | Learning the Positions in CountSketch | 7.00 | 7.50 | 0.50 | [8, 8, 6, 8]
|
| 3714 | Towards the gradient adjustment by loss status for Neural Network Optimization | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 3715 | On the Necessity of Disentangled Representations for Downstream Tasks | 5.20 | 5.20 | 0.00 | [3, 6, 6, 5, 6]
|
| 3716 | Grouped self-attention mechanism for a memory-efficient Transformer | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 3717 | Linear Video Transformer with Feature Fixation | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 3718 | Neural Frailty Machine: Beyond proportional hazard assumption in neural survival regressions | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 3719 | A Closer Look at Dual Batch Normalization and Two-domain Hypothesis In Adversarial Training With Hybrid Samples | 4.75 | 5.25 | 0.50 | [6, 5, 5, 5]
|
| 3720 | Generative Recorrupted-to-Recorrupted: An Unsupervised Image Denoising Network for Arbitrary Noise Distribution | 3.00 | 3.00 | 0.00 | [3, 5, 1, 3]
|
| 3721 | Provably Learning Diverse Features in Multi-View Data with Midpoint Mixup | 5.33 | 5.33 | 0.00 | [5, 3, 8]
|
| 3722 | Understanding Catastrophic Overfitting in Fast Adversarial Training From a Non-robust Feature Perspective | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 3723 | AutoDisc: Automatic Distillation Schedule for Large Language Model Compression | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3724 | Lifting the Curse of Capacity Gap in Distilling Large Language Models | 4.20 | 4.20 | 0.00 | [5, 3, 5, 5, 3]
|
| 3725 | BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers | 6.00 | 6.00 | 0.00 | [5, 8, 5, 6]
|
| 3726 | Geo-NN: An End-to-End Framework for Geodesic Mean Estimation on the Manifold of Symmetric Positive Definite Matrices | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 3727 | HIVE: HIerarchical Volume Encoding for Neural Implicit Surface Reconstruction | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 3728 | Progressive Image Synthesis from Semantics to Details with Denoising Diffusion GAN | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 3729 | Communication-Efficient Federated Learning with Accelerated Client Gradient | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 3730 | DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection | 7.00 | 7.00 | 0.00 | [6, 8, 5, 8, 8]
|
| 3731 | Ranking-Enhanced Unsupervised Sentence Representation Learning | 5.25 | 5.25 | 0.00 | [5, 8, 5, 3]
|
| 3732 | Simultaneously Learning Stochastic and Adversarial Markov Decision Process with Linear Function Approximation | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 3733 | Statistical Efficiency of Score Matching: The View from Isoperimetry | 7.33 | 7.33 | 0.00 | [8, 8, 6]
|
| 3734 | Quadratic models for understanding neural network dynamics | 6.75 | 6.75 | 0.00 | [5, 6, 8, 8]
|
| 3735 | Improving Adversarial Transferability with Worst-case Aware Attacks | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 3736 | TCFimt: Temporal Counterfactual Forecasting from Individual Multiple Treatment Perspective | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 3737 | Curved Representation Space of Vision Transformers | 5.00 | 5.00 | 0.00 | [3, 6, 6, 5]
|
| 3738 | Revisiting Graph Adversarial Attack and Defense From a Data Distribution Perspective | 5.25 | 5.75 | 0.50 | [5, 8, 5, 5]
|
| 3739 | Gated Domain Units for Multi-source Domain Generalization | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 3740 | CooPredict : Cooperative Differential Games For Time Series Prediction | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 3741 | Learning large-scale Kernel Networks | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 3742 | Self-Architectural Knowledge Distillation for Spiking Neural Networks | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 3743 | Provable Sim-to-real Transfer in Continuous Domain with Partial Observations | 7.00 | 7.33 | 0.33 | [8, 6, 8]
|
| 3744 | Local Coefficient Optimization in Federated Learning | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 3745 | Outcome-directed Reinforcement Learning by Uncertainty \& Temporal Distance-Aware Curriculum Goal Generation | 7.00 | 7.00 | 0.00 | [5, 8, 8]
|
| 3746 | E$^2$: Entropy Discrimination and Energy Optimization for Source-free Universal Domain Adaptation | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3747 | Protective Label Enhancement for Label Privacy | 3.00 | 3.00 | 0.00 | [5, 3, 1]
|
| 3748 | Synergistic Neuromorphic Federated Learning with ANN-SNN Conversion For Privacy Protection | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 3749 | On Fairness Measurement for Generative Models | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 3750 | Federated Semi-supervised Learning with Dual Regulator | 5.00 | 5.67 | 0.67 | [6, 6, 5]
|
| 3751 | Path Regularization: A Convexity and Sparsity Inducing Regularization for Parallel ReLU Networks | 4.00 | 5.00 | 1.00 | [5, 3, 6, 6]
|
| 3752 | Globally Optimal Training of Neural Networks with Threshold Activation Functions | 5.67 | 6.33 | 0.67 | [6, 8, 5]
|
| 3753 | Robust Learning with Decoupled Meta Label Purifier | 5.50 | 5.50 | 0.00 | [8, 5, 3, 6]
|
| 3754 | Molecule Generation For Target Protein Binding with Structural Motifs | 6.00 | 6.50 | 0.50 | [8, 5, 5, 8]
|
| 3755 | Bag of Tricks for FGSM Adversarial Training | 4.67 | 4.75 | 0.08 | [5, 6, 5, 3]
|
| 3756 | Exploring interactions between modalities for deepfake detection | 4.67 | 4.67 | 0.00 | [3, 5, 3, 6, 6, 5]
|
| 3757 | Towards Robustness Certification Against Universal Perturbations | 6.00 | 6.00 | 0.00 | [3, 5, 8, 8]
|
| 3758 | Deep Generative Modeling on Limited Data with Regularization by Nontransferable Pre-trained Models | 6.25 | 6.25 | 0.00 | [6, 5, 6, 8]
|
| 3759 | MAT: Mixed-Strategy Game of Adversarial Training in Fine-tuning | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 3760 | Defense against Backdoor Attacks via Identifying and Purifying Bad Neurons | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 3761 | Basic Binary Convolution Unit for Binarized Image Restoration Network | 5.50 | 5.50 | 0.00 | [6, 3, 8, 5]
|
| 3762 | DSP: Dynamic Semantic Prototype for Generative Zero-Shot Learning | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 3763 | Analyzing the Latent Space of GAN through Local Dimension Estimation | 5.25 | 5.25 | 0.00 | [6, 6, 6, 3]
|
| 3764 | MAFormer: A Transformer Network with Multi-scale Attention Fusion for Visual Recognition | 3.67 | 4.00 | 0.33 | [5, 3, 5, 3]
|
| 3765 | A Causal Approach to Detecting Multivariate Time-series Anomalies and Root Causes | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 3766 | Quark: A Gradient-Free Quantum Learning Framework for Classification Tasks | 3.25 | 3.25 | 0.00 | [3, 1, 6, 3]
|
| 3767 | Cross-modal Graph Contrastive Learning with Cellular Images | 5.00 | 5.00 | 0.00 | [6, 8, 3, 3]
|
| 3768 | A Closer Look at Self-supervised Lightweight Vision Transformers | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 3769 | MANDERA: Malicious Node Detection in Federated Learning via Ranking | 2.33 | 2.33 | 0.00 | [3, 1, 3]
|
| 3770 | MQSP: Micro-Query Sequence Parallelism for Linearly Scaling Long Sequence Transformer | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 3771 | HagSeg: Hardness-adaptive Guidance for Semi-supervised Semantic Segmentation | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 3772 | DSPNet: Towards Slimmable Pretrained Networks based on Discriminative Self-supervised Learning | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 3773 | Generative Multi-Flow Networks: Centralized, Independent and Conservation | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 3774 | A Laplace-inspired Distribution on SO(3) for Probabilistic Rotation Estimation | 5.67 | 5.67 | 0.00 | [8, 3, 6]
|
| 3775 | Why pseudo-label based algorithm is effective? --from the perspective of pseudo-labeled data | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 3776 | Distributionally Robust Model-Based Offline Reinforcement Learning with Near-Optimal Sample Complexity | 4.60 | 4.60 | 0.00 | [5, 6, 3, 6, 3]
|
| 3777 | ContraGen: Effective Contrastive Learning For Causal Language Model | 5.00 | 4.60 | -0.40 | [3, 6, 6, 3, 5]
|
| 3778 | Fast 6D Object Pose Refinement via Implicit Surface Representation Driven Optimization | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 3779 | Benchmarking Encoder-Decoder Architectures for Biplanar X-ray to 3D Bone Shape Reconstruction | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 3780 | Time Series Anomaly Detection via Hypothesis Testing for Dynamical Systems | 3.67 | 4.00 | 0.33 | [6, 1, 5]
|
| 3781 | Exploring the Generalizability of CNNs via Activated Representational Substitution | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 3782 | Schrödinger"s FP: Training Neural Networks with Dynamic Floating-Point Containers | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 3783 | Measuring and Narrowing the Compositionality Gap in Language Models | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 3784 | FedFA: Federated Learning with Feature Alignment for Heterogeneous Data | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 3785 | HiViT: A Simpler and More Efficient Design of Hierarchical Vision Transformer | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 3786 | Style Spectroscope: Improve Interpretability and Controllability through Fourier Analysis | 4.75 | 4.75 | 0.00 | [3, 3, 5, 8]
|
| 3787 | Multimodal Federated Learning via Contrastive Representation Ensemble | 6.00 | 6.00 | 0.00 | [6, 5, 8, 5]
|
| 3788 | Eva: Practical Second-order Optimization with Kronecker-vectorized Approximation | 6.25 | 6.25 | 0.00 | [6, 8, 6, 5]
|
| 3789 | Identifying Weight-Variant Latent Causal Models | 5.33 | 5.33 | 0.00 | [5, 6, 3, 8, 5, 5]
|
| 3790 | Beyond Single Path Integrated Gradients for Reliable Input Attribution via Randomized Path Sampling | 5.00 | 5.50 | 0.50 | [6, 6, 5, 5]
|
| 3791 | Sweet Gradient Matters: Designing Consistent and Efficient Estimator for Zero-Shot Neural Architecture Search | 5.50 | 5.50 | 0.00 | [5, 6, 6, 5]
|
| 3792 | Bridging attack and prompting: An Enhanced Visual Prompting at the pixel level | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 3793 | Neural Collaborative Filtering Bandits via Meta Learning | 5.25 | 5.25 | 0.00 | [3, 5, 5, 8]
|
| 3794 | MABA-Net: Masked Additive Binary Activation Network | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 3795 | Cascaded Teaching Transformers with Data Reweighting for Long Sequence Time-series Forecasting | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 3796 | Decoupled and Patch-based Contrastive Learning for Long-tailed Visual Recognition | 5.00 | 5.00 | 0.00 | [3, 5, 6, 5, 6]
|
| 3797 | Can CNNs Be More Robust Than Transformers? | 5.33 | 5.33 | 0.00 | [3, 5, 8]
|
| 3798 | motifNet: Functional motif interactions discovered in mRNA sequences with implicit neural representation learning | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 3799 | Decoupled Mixup for Data-efficient Learning | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 3800 | FAIRER: Fairness as Decision Rationale Alignment | 5.25 | 5.50 | 0.25 | [6, 5, 5, 6]
|
| 3801 | Rethinking Data Augmentation for Improving Transferable Targeted Attacks | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 3802 | A Deep Dive into the Stability-Plasticity Dilemma in Class-Incremental Learning | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 3803 | KITE: A Kernel-based Improved Transferability Estimation Method | 4.80 | 4.80 | 0.00 | [5, 3, 5, 6, 5]
|
| 3804 | Risk-Aware Reinforcement Learning with Coherent Risk Measures and Non-linear Function Approximation | 6.33 | 6.33 | 0.00 | [5, 8, 6]
|
| 3805 | A Minimalist Dataset for Systematic Generalization of Perception, Syntax, and Semantics | 7.50 | 7.50 | 0.00 | [6, 8, 8, 8]
|
| 3806 | Bi-level Physics-Informed Neural Networks for PDE Constrained Optimization using Broyden"s Hypergradients | 5.25 | 5.50 | 0.25 | [6, 5, 6, 5]
|
| 3807 | Learning Continuous Grasping Function with a Dexterous Hand from Human Demonstrations | 5.25 | 5.25 | 0.00 | [3, 5, 8, 5]
|
| 3808 | Hazard Gradient Penalty for Survival Analysis | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 3809 | Model-Agnostic Meta-Attack: Towards Reliable Evaluation of Adversarial Robustness | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 3810 | Rethink Depth Separation with Intra-layer Links | 5.00 | 5.25 | 0.25 | [6, 3, 6, 6]
|
| 3811 | Reach the Remote Neighbors: Dual-Encoding Transformer for Graphs | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 3812 | The Geometry of Self-supervised Learning Models and its Impact on Transfer Learning | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 3813 | Only For You: Deep Neural Anti-Forwarding Watermark Preserves Image Privacy | 4.75 | 4.75 | 0.00 | [5, 3, 6, 5]
|
| 3814 | When Do Models Generalize? A Perspective From Data-Algorithm Compatibility | 5.25 | 5.75 | 0.50 | [6, 6, 6, 5]
|
| 3815 | On the Saturation Effect of Kernel Ridge Regression | 6.50 | 6.50 | 0.00 | [6, 8, 6, 6]
|
| 3816 | Adversarial perturbation based latent reconstruction for domain-agnostic self-supervised learning | 6.00 | 6.00 | 0.00 | [5, 8, 6, 5]
|
| 3817 | Unsupervised Model Selection for Time Series Anomaly Detection | 5.00 | 5.00 | 0.00 | [6, 6, 3, 5]
|
| 3818 | Constrained Hierarchical Deep Reinforcement Learning with Differentiable Formal Specifications | 5.50 | 5.50 | 0.00 | [8, 6, 5, 3]
|
| 3819 | Topic Aware Transformer: Domain Shift for Unconditional Text Generation Model | 4.50 | 4.50 | 0.00 | [3, 3, 6, 6]
|
| 3820 | PromptCast: A New Prompt-based Learning Paradigm for Time Series Forecasting | 4.75 | 4.75 | 0.00 | [3, 5, 3, 8]
|
| 3821 | Protein Representation Learning by Geometric Structure Pretraining | 6.00 | 6.00 | 0.00 | [6, 5, 8, 5]
|
| 3822 | Conditional Invariances for Conformer Invariant Protein Representations | 4.40 | 4.40 | 0.00 | [5, 3, 5, 6, 3]
|
| 3823 | Learning PDE Solution Operator for Continuous Modeling of Time-Series | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 3824 | Quantum-Inspired Tensorized Embedding with Application to Node Representation Learning | 4.67 | 4.67 | 0.00 | [3, 8, 3]
|
| 3825 | Identifying Latent Causal Content for Multi-Source Domain Adaptation | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 3826 | Robust Self-Supervised Image Denoising with Cyclic Shift and Noise-Intensity-Aware Uncertainty | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3827 | Trainable Weight Averaging: Efficient Training by Optimizing Historical Solutions | 5.25 | 5.25 | 0.00 | [8, 5, 5, 3]
|
| 3828 | Revealing Single Frame Bias for Video-and-Language Learning | 4.75 | 4.75 | 0.00 | [5, 3, 6, 5]
|
| 3829 | Deep Declarative Dynamic Time Warping for End-to-End Learning of Alignment Paths | 5.75 | 6.50 | 0.75 | [6, 8, 6, 6]
|
| 3830 | DEEAPR: Controllable Depth Enhancement via Adaptive Parametric Feature Rotation | 2.50 | 2.50 | 0.00 | [1, 3, 3, 3]
|
| 3831 | Deep Active Anomaly Detection With Diverse Queries | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 3832 | MODULAR FEDERATED CONTRASTIVE LEARNING WITH PEER NORMALIZATION | 3.80 | 3.80 | 0.00 | [5, 5, 3, 3, 3]
|
| 3833 | Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning | 7.00 | 7.00 | 0.00 | [6, 8, 8, 6]
|
| 3834 | NetBooster: Empowering Tiny Deep Learning By Standing on the Shoulders of Deep Giants | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 3835 | Understanding Edge-of-Stability Training Dynamics with a Minimalist Example | 6.80 | 6.80 | 0.00 | [8, 8, 5, 5, 8]
|
| 3836 | Learning Proximal Operators to Discover Multiple Optima | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 3837 | Guiding continuous operator learning through Physics-based boundary constraints | 5.67 | 5.67 | 0.00 | [3, 8, 6]
|
| 3838 | AdaWAC: Adaptively Weighted Augmentation Consistency Regularization for Volumetric Medical Image Segmentation | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3839 | Limitations of the NTK for Understanding Generalization in Deep Learning | 5.50 | 5.50 | 0.00 | [5, 3, 8, 6]
|
| 3840 | Federated Learning of Large Models at the Edge via Principal Sub-Model Training | 4.67 | 5.00 | 0.33 | [3, 6, 6]
|
| 3841 | Low-Entropy Features Hurt Out-of-Distribution Performance | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3842 | Implicit Offline Reinforcement Learning via Supervised Learning | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 3843 | A Unimodal, Uncertainty-Aware Deep Learning Approach for Ordinal Regression | 4.60 | 4.60 | 0.00 | [5, 5, 3, 5, 5]
|
| 3844 | Augmentation Backdoors | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3845 | Neural Radiance Field Codebooks | 5.25 | 6.00 | 0.75 | [6, 8, 5, 5]
|
| 3846 | Scalable Estimation of Nonparametric Markov Networks with Mixed-Type Data | 5.50 | 7.00 | 1.50 | [8, 6, 8, 6]
|
| 3847 | Determinant regularization for Deep Metric Learning | 3.00 | 3.00 | 0.00 | [5, 3, 1, 3]
|
| 3848 | Data-Efficient and Interpretable Tabular Anomaly Detection | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 3849 | Extracting Expert"s Goals by What-if Interpretable Modeling | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 3850 | FiT: Parameter Efficient Few-shot Transfer Learning for Personalized and Federated Image Classification | 6.60 | 6.60 | 0.00 | [8, 5, 8, 6, 6]
|
| 3851 | A Critical Analysis of Out-of-Distribution Detection for Document Understanding | 5.33 | 5.33 | 0.00 | [3, 8, 5]
|
| 3852 | Learnable Visual Words for Interpreting Image Recognition Models | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3853 | Compact Bilinear Pooling via General Bilinear Projection | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 3854 | AANG : Automating Auxiliary Learning | 6.50 | 6.50 | 0.00 | [5, 5, 8, 8]
|
| 3855 | Discrete Contrastive Diffusion for Cross-Modal Music and Image Generation | 6.00 | 6.25 | 0.25 | [5, 6, 8, 6]
|
| 3856 | Diffusion Probabilistic Modeling of Protein Backbones in 3D for the motif-scaffolding problem | 5.50 | 5.50 | 0.00 | [5, 6, 6, 5]
|
| 3857 | NeRF-SOS: Any-View Self-supervised Object Segmentation on Complex Scenes | 6.25 | 7.00 | 0.75 | [8, 8, 6, 6]
|
| 3858 | RbX: Region-based explanations of prediction models | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 3859 | Rethinking Graph Lottery Tickets: Graph Sparsity Matters | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 3860 | The Impact of Approximation Errors on Warm-Start Reinforcement Learning: A Finite-time Analysis | 5.25 | 5.25 | 0.00 | [6, 3, 6, 6]
|
| 3861 | NeRN: Learning Neural Representations for Neural Networks | 7.00 | 7.00 | 0.00 | [8, 6, 6, 8]
|
| 3862 | Private Federated Learning Without a Trusted Server: Optimal Algorithms for Convex Losses | 6.50 | 6.50 | 0.00 | [8, 6, 6, 6]
|
| 3863 | 3D-Aware Video Generation | 5.25 | 5.25 | 0.00 | [5, 8, 3, 5]
|
| 3864 | Joint rotational invariance and adversarial training of a dual-stream Transformer yields state of the art Brain-Score for Area V4 | 5.50 | 5.50 | 0.00 | [3, 6, 8, 5]
|
| 3865 | AutoSparse: Towards Automated Sparse Training | 4.50 | 4.50 | 0.00 | [6, 5, 3, 3, 5, 5]
|
| 3866 | Improving Molecular Pretraining with Complementary Featurizations | 4.50 | 4.50 | 0.00 | [3, 6, 3, 6]
|
| 3867 | Learning to Communicate using Contrastive Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3868 | Cheap Talk Discovery and Utilization in Multi-Agent Reinforcement Learning | 6.00 | 6.00 | 0.00 | [5, 5, 6, 8]
|
| 3869 | Motif-induced Graph Normalization | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 3870 | Stochastic Gradient Methods with Preconditioned Updates | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3871 | Reversible Column Networks | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 3872 | Flexible Relation Preserving for Adversarial Training | 3.00 | 3.00 | 0.00 | [5, 1, 3]
|
| 3873 | Formal Mathematics Statement Curriculum Learning | 6.33 | 6.33 | 0.00 | [8, 3, 8]
|
| 3874 | A Unified Causal View of Domain Invariant Representation Learning | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 3875 | PIPS: Path Integral Stochastic Optimal Control for Path Sampling in Molecular Dynamics | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3876 | ID and OOD Performance Are Sometimes Inversely Correlated on Real-world Datasets | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 3877 | Continual Learning with Group-wise Neuron Normalization | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 3878 | Zemi: Learning Zero-Shot Semi-Parametric Language Models from Multiple Tasks | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 3879 | Visual Transformation Telling | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3880 | PRUDEX-Compass: Towards Systematic Evaluation of Reinforcement Learning in Financial Markets | 4.50 | 4.50 | 0.00 | [6, 8, 3, 1]
|
| 3881 | Joint Spatiotemporal Attention for Mortality Prediction of Patients with Long COVID | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3882 | Predicting Antimicrobial MICs for Nontyphoidal Salmonella Using Multitask Representations Learning | 1.67 | 1.67 | 0.00 | [1, 3, 1]
|
| 3883 | Bootstrap Motion Forecasting With Self-Consistent Constraints | 4.50 | 5.25 | 0.75 | [5, 5, 3, 8]
|
| 3884 | Sparse Hyperbolic Representation Learning | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 3885 | Fair Multi-exit Framework for Facial Attribute Classification | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3886 | Learning to Split for Automatic Bias Detection | 4.50 | 5.00 | 0.50 | [6, 3, 8, 3]
|
| 3887 | Union Subgraph Neural Networks | 4.75 | 4.75 | 0.00 | [3, 5, 5, 6]
|
| 3888 | Modeling Multimodal Aleatoric Uncertainty in Segmentation with Mixture of Stochastic Experts | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 3889 | Frame Adaptive Network | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 3890 | On the Robustness of Safe Reinforcement Learning under Observational Perturbations | 5.50 | 5.50 | 0.00 | [6, 5, 6, 5]
|
| 3891 | Rethinking Saliency in Data-free Class Incremental Learning | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 3892 | Rethinking the Training Shot Number in Robust Model-Agnostic Meta-Learning | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3893 | Behind the Scenes of Gradient Descent: A Trajectory Analysis via Basis Function Decomposition | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 3894 | What Is Missing in IRM Training and Evaluation? Challenges and Solutions | 6.00 | 6.67 | 0.67 | [6, 8, 6]
|
| 3895 | Neural Decoding of Visual Imagery via Hierarchical Variational Autoencoders | 5.00 | 5.00 | 0.00 | [10, 1, 6, 3]
|
| 3896 | Cooperative Adversarial Learning via Closed-Loop Transcription | 3.40 | 3.40 | 0.00 | [5, 3, 3, 1, 5]
|
| 3897 | Multi-task Self-supervised Graph Neural Networks Enable Stronger Task Generalization | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 3898 | Analyzing Tree Architectures in Ensembles via Neural Tangent Kernel | 6.25 | 6.25 | 0.00 | [6, 5, 6, 8]
|
| 3899 | Learn Appropriate Precise Distributions for Binary Neural Networks | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3900 | Correcting Data Distribution Mismatch in Offline Meta-Reinforcement Learning with Few-Shot Online Adaptation | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 3901 | Sharper Rates and Flexible Framework for Nonconvex SGD with Client and Data Sampling | 4.67 | 4.25 | -0.42 | [3, 5, 6, 3]
|
| 3902 | Universal embodied intelligence: learning from crowd, recognizing the world, and reinforced with experience | 4.00 | 4.00 | 0.00 | [3, 6, 6, 1]
|
| 3903 | Exploring The Role of Mean Teachers in Self-supervised Masked Auto-Encoders | 5.00 | 5.00 | 0.00 | [6, 3, 6, 5]
|
| 3904 | Multifactor Sequential Disentanglement via Structured Koopman Autoencoders | 7.33 | 7.33 | 0.00 | [8, 6, 8]
|
| 3905 | Sub-Task Decomposition Enables Learning in Sequence to Sequence Tasks | 6.60 | 6.60 | 0.00 | [6, 6, 8, 8, 5]
|
| 3906 | T2D: Spatiotemporal Feature Learning Based on Triple 2D Decomposition | 5.50 | 5.50 | 0.00 | [6, 8, 5, 3]
|
| 3907 | Online Placebos for Class-incremental Learning | 5.25 | 5.25 | 0.00 | [5, 5, 3, 8]
|
| 3908 | Evaluating Long-Term Memory in 3D Mazes | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 3909 | Packed Ensembles for efficient uncertainty estimation | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 3910 | Proactive Multi-Camera Collaboration for 3D Human Pose Estimation | 6.25 | 6.25 | 0.00 | [6, 6, 8, 5]
|
| 3911 | OpenFE: Automated Feature Generation beyond Expert-level Performance | 4.33 | 4.67 | 0.33 | [5, 6, 3]
|
| 3912 | Physics-empowered Molecular Representation Learning | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 3913 | On the Difficulties of Video Summarization: Structure and Subjectivity | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 3914 | CCMLN: Combinatorial Correction for Multi-Label Classification with Noisy Labels | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 3915 | Revisiting Domain Randomization Via Relaxed State-Adversarial Policy Optimization | 5.00 | 5.50 | 0.50 | [5, 5, 6, 6]
|
| 3916 | Consistent Targets Provide Better Supervision in Semi-supervised Object Detection | 5.00 | 5.00 | 0.00 | [3, 6, 5, 6]
|
| 3917 | Become a Proficient Player with Limited Data through Watching Pure Videos | 6.25 | 6.25 | 0.00 | [6, 6, 5, 8]
|
| 3918 | Evaluation of Attribution Explanations without Ground Truth | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 3919 | Human MotionFormer: Transferring Human Motions with Vision Transformers | 5.67 | 5.75 | 0.08 | [6, 6, 3, 8]
|
| 3920 | Entity Divider with Language Grounding in Multi-Agent Reinforcement Learning | 5.25 | 5.25 | 0.00 | [3, 6, 6, 6]
|
| 3921 | Multi-Agent Sequential Decision-Making via Communication | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 3922 | LAMDA: Latent mapping for domain adaption of image generators | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 3923 | Hierarchies of Reward Machines | 6.00 | 6.00 | 0.00 | [5, 5, 8]
|
| 3924 | EfficientTTS 2: Variational End-to-End Text-to-Speech Synthesis and Voice Conversion | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3925 | LatentAugment: Dynamically Optimized Latent Probabilities of Data Augmentation | 6.00 | 6.00 | 0.00 | [6, 5, 8, 5]
|
| 3926 | Cali-NCE: Boosting Cross-modal Video Representation Learning with Calibrated Alignment | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 3927 | Novel Class Discovery under Unreliable Sampling | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 3928 | NEW TRAINING FRAMEWORK FOR SPEECH ENHANCEMENT USING REAL NOISY SPEECH | 4.75 | 4.75 | 0.00 | [8, 3, 3, 5]
|
| 3929 | PA-LoFTR: Local Feature Matching with 3D Position-Aware Transformer | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3930 | Policy Contrastive Imitation Learning | 6.00 | 6.00 | 0.00 | [8, 5, 5]
|
| 3931 | Backstepping Temporal Difference Learning | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 3932 | Hidden Markov Transformer for Simultaneous Machine Translation | 6.75 | 6.75 | 0.00 | [8, 5, 6, 8]
|
| 3933 | Rank Preserving Framework for Asymmetric Image Retrieval | 7.00 | 7.00 | 0.00 | [6, 8, 8, 6]
|
| 3934 | MINI: Mining Implicit Novel Instances for Few-Shot Object Detection | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 3935 | D3C2-Net: Dual-Domain Deep Convolutional Coding Network for Compressive Sensing | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3936 | Single-level Adversarial Data Synthesis based on Neural Tangent Kernels | 5.00 | 5.00 | 0.00 | [6, 8, 3, 3]
|
| 3937 | Learning to Count Everything: Transformer-based Trackers are Strong Baselines for Class Agnostic Counting | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 3938 | Unified Algorithms for RL with Decision-Estimation Coefficients: No-Regret, PAC, and Reward-Free Learning | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 3939 | Strength-Adaptive Adversarial Training | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 3940 | Teach me how to Interpolate a Myriad of Embeddings | 4.00 | 4.67 | 0.67 | [6, 3, 5]
|
| 3941 | Exploring Parameter-Efficient Fine-tuning for Improving Communication Efficiency in Federated Learning | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 3942 | Mega: Moving Average Equipped Gated Attention | 7.25 | 7.25 | 0.00 | [8, 8, 5, 8]
|
| 3943 | Going Deeper with Spiking Neurons: Towards Binary Outputs of Deep Logic Spiking Neural Network | 4.25 | 4.25 | 0.00 | [3, 5, 8, 1]
|
| 3944 | IEDR: A Context-aware Intrinsic and Extrinsic Disentangled Recommender System | 5.25 | 5.25 | 0.00 | [6, 3, 6, 6]
|
| 3945 | Correcting Three Existing Beliefs on Mutual Information in Contrastive Learning | 4.25 | 4.00 | -0.25 | [3, 3, 3, 6, 5]
|
| 3946 | Deep Deformation Based on Feature-Constraint for 3D Human Mesh Correspondence | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 3947 | Explaining Representation Bottlenecks of Convolutional Decoder Networks | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 3948 | Batch Normalization Is Blind to the First and Second Derivatives of the Loss w.r.t. Features | 4.25 | 4.25 | 0.00 | [5, 6, 1, 5]
|
| 3949 | Dual Ensembled Multiagent Q-Learning with Hypernet Regularizer | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 3950 | Exploring Chemical Space with Score-based Out-of-distribution Generation | 5.25 | 5.25 | 0.00 | [5, 5, 3, 8]
|
| 3951 | Divide and conquer policy for efficient GAN training | 3.00 | 3.00 | 0.00 | [1, 5, 3, 3]
|
| 3952 | Node Number Awareness Representation for Graph Similarity Learning | 4.25 | 4.50 | 0.25 | [3, 6, 6, 3]
|
| 3953 | Evaluating Fairness Without Sensitive Attributes: A Framework Using Only Auxiliary Models | 5.00 | 5.00 | 0.00 | [3, 5, 6, 6]
|
| 3954 | Dataset Condensation with Latent Space Knowledge Factorization and Sharing | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 3955 | Optimal Neural Network Approximation of Wasserstein Gradient Direction via Convex Optimization | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3956 | Parallel Deep Neural Networks Have Zero Duality Gap | 5.00 | 5.75 | 0.75 | [3, 6, 8, 6]
|
| 3957 | Causal RL Agents for Out-of-distribution Generalization | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 3958 | Multi-domain image generation and translation with identifiability guarantees | 6.25 | 6.25 | 0.00 | [6, 8, 6, 5]
|
| 3959 | Interventional Rationalization | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 3960 | Information-Theoretic Analysis of Unsupervised Domain Adaptation | 6.25 | 6.25 | 0.00 | [3, 8, 8, 6]
|
| 3961 | Pessimism in the Face of Confounders: Provably Efficient Offline Reinforcement Learning in Partially Observable Markov Decision Processes | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 3962 | DELVING INTO THE HIERARCHICAL STRUCTURE FOR EFFICIENT LARGE-SCALE BI-LEVEL LEARNING | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 3963 | Can GNNs Learn Heuristic Information for Link Prediction? | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 3964 | Understanding Zero-shot Adversarial Robustness for Large-Scale Models | 6.25 | 6.25 | 0.00 | [6, 8, 3, 8]
|
| 3965 | HOYER REGULARIZER IS ALL YOU NEED FOR EXTREMELY SPARSE SPIKING NEURAL NETWORKS | 4.40 | 5.20 | 0.80 | [5, 5, 3, 8, 5]
|
| 3966 | Controllable Evaluation and Generation of Physical Adversarial Patch on Face Recognition | 5.75 | 5.75 | 0.00 | [5, 5, 8, 5]
|
| 3967 | Why Adversarial Training of ReLU Networks Is Difficult? | 3.60 | 3.60 | 0.00 | [6, 1, 5, 3, 3]
|
| 3968 | Rademacher Complexity Over $\mathcal{H} \Delta \mathcal{H}$ Class for Adversarially Robust Domain Adaptation | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 3969 | Continual evaluation for lifelong learning: Identifying the stability gap | 6.25 | 6.25 | 0.00 | [6, 6, 8, 5]
|
| 3970 | On the Universal Approximation Property of Deep Fully Convolutional Neural Networks | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 3971 | Can We Faithfully Represent Absence States to Compute Shapley Values on a DNN? | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 3972 | FedGSNR: Accelerating Federated Learning on Non-IID Data via Maximum Gradient Signal to Noise Ratio | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 3973 | Dataless Knowledge Fusion by Merging Weights of Language Models | 6.00 | 6.50 | 0.50 | [5, 8, 8, 5]
|
| 3974 | Domain-Indexing Variational Bayes for Domain Adaptation | 7.25 | 7.50 | 0.25 | [8, 6, 8, 8]
|
| 3975 | Improving the Transferability of Adversarial Attacks through Experienced Precise Nesterov Momentum | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 3976 | TaylorNet: A Taylor-Driven Generic Neural Architecture | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 3977 | Semi-supervised learning of partial differential operators and dynamical flows | 4.20 | 4.20 | 0.00 | [5, 3, 5, 5, 3]
|
| 3978 | View Synthesis with Sculpted Neural Points | 7.33 | 7.33 | 0.00 | [8, 6, 8]
|
| 3979 | Universal Vision-Language Dense Retrieval: Learning A Unified Representation Space for Multi-Modal Retrieval | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 3980 | Continual Pre-trainer is an Incremental Model Generalizer | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 3981 | DFlow: Learning to Synthesize Better Optical Flow Datasets via a Differentiable Pipeline | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 3982 | FS-DETR: Few-Shot DEtection TRansformer with prompting and without re-training | 4.80 | 4.80 | 0.00 | [6, 3, 5, 5, 5]
|
| 3983 | One-Pixel Shortcut: On the Learning Preference of Deep Neural Networks | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 3984 | An Improved Baseline for Masked Contrastive Learning | 3.50 | 3.50 | 0.00 | [3, 5, 5, 1]
|
| 3985 | Make Memory Buffer Stronger in Continual Learning: A Continuous Neural Transformation Approach | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 3986 | Sparse Random Networks for Communication-Efficient Federated Learning | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 3987 | WaveMix-Lite: A Resource-efficient Neural Network for Image Analysis | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 3988 | On the Impact of Adversarially Robust Models on Algorithmic Recourse | 3.25 | 3.75 | 0.50 | [3, 6, 3, 3]
|
| 3989 | Learning to acquire novel cognitive tasks with evolution, plasticity and meta-meta-learning | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 3990 | Breaking Beyond COCO Object Detection | 4.40 | 4.40 | 0.00 | [5, 6, 3, 5, 3]
|
| 3991 | BinaryVQA: A Versatile Dataset to Push the Limits of VQA Models | 2.50 | 2.50 | 0.00 | [3, 3, 1, 3]
|
| 3992 | NormSoftmax: Normalize the Input of Softmax to Accelerate and Stabilize Training | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 3993 | Diverse, Difficult, and Odd Instances (D2O): A New Test Set for Object Classification | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 3994 | Differentially Private Dataset Condensation | 4.67 | 5.67 | 1.00 | [5, 6, 6]
|
| 3995 | Variation-based Cause Effect Identification | 3.75 | 3.75 | 0.00 | [3, 3, 3, 6]
|
| 3996 | A General Framework For Proving The Equivariant Strong Lottery Ticket Hypothesis | 6.25 | 7.00 | 0.75 | [8, 6, 8, 6]
|
| 3997 | TimelyFL: Heterogeneity-aware Asynchronous Federated Learning with Adaptive Partial Training | 5.25 | 5.25 | 0.00 | [6, 3, 6, 6]
|
| 3998 | Robust Fair Clustering: A Novel Fairness Attack and Defense Framework | 6.50 | 6.50 | 0.00 | [6, 6, 8, 6]
|
| 3999 | Learning to Jointly Share and Prune Weights for Grounding Based Vision and Language Models | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 4000 | Coupling Semi-supervised Learning with Reinforcement Learning for Better Decision Making -- An application to Cryo-EM Data Collection | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 4001 | Spatial Attention Kinetic Networks with E(n)-Equivariance | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 4002 | Training Recipe for N:M Structured Sparsity with Decaying Pruning Mask | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 4003 | Light-weight probing of unsupervised representations for Reinforcement Learning | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 4004 | Understanding Rare Spurious Correlations in Neural Networks | 5.75 | 5.75 | 0.00 | [5, 5, 8, 5]
|
| 4005 | Graph Domain Adaptation via Theory-Grounded Spectral Regularization | 5.25 | 5.75 | 0.50 | [6, 5, 6, 6]
|
| 4006 | Effective dimension of machine learning models | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 4007 | CLARE: Conservative Model-Based Reward Learning for Offline Inverse Reinforcement Learning | 6.25 | 6.25 | 0.00 | [3, 8, 8, 6]
|
| 4008 | Data-Free One-Shot Federated Learning Under Very High Statistical Heterogeneity | 5.50 | 5.75 | 0.25 | [6, 5, 6, 6]
|
| 4009 | Personalized Subgraph Federated Learning | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 4010 | Domain-Adjusted Regression or: ERM May Already Learn Features Sufficient for Out-of-Distribution Generalization | 5.20 | 6.80 | 1.60 | [8, 6, 6, 8, 6]
|
| 4011 | Initial Value Problem Enhanced Sampling for Closed-Loop Optimal Control Design with Deep Neural Networks | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 4012 | Human Pose Estimation in the Dark | 4.75 | 4.75 | 0.00 | [5, 3, 6, 5]
|
| 4013 | Tackling the Retrieval Trilemma with Cross-Modal Indexing | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 4014 | C3PO: Learning to Achieve Arbitrary Goals via Massively Entropic Pretraining | 2.33 | 3.00 | 0.67 | [3, 3, 3]
|
| 4015 | ProtoVAE: Using Prototypical Networks for Unsupervised Disentanglement | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 4016 | Neural Diffusion Processes | 5.75 | 5.75 | 0.00 | [6, 3, 8, 6]
|
| 4017 | Global Context Vision Transformers | 5.00 | 5.25 | 0.25 | [6, 3, 6, 6]
|
| 4018 | Adversarial Learned Fair Representations using Dampening and Stacking | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 4019 | Watch What You Pretrain For: Targeted, Transferable Adversarial Examples on Self-Supervised Speech Recognition models | 4.50 | 4.50 | 0.00 | [3, 6, 6, 3]
|
| 4020 | Imposing conservation properties in deep dynamics modeling via contrastive learning | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 4021 | Language Models Can See: Plugging Visual Controls in Text Generation | 4.20 | 4.20 | 0.00 | [6, 6, 3, 3, 3]
|
| 4022 | GReTo: Remedying dynamic graph topology-task discordance via target homophily | 6.00 | 6.80 | 0.80 | [6, 6, 8, 8, 6]
|
| 4023 | Towards predicting dynamic stability of power grids with Graph Neural Networks | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 4024 | Pareto-Optimal Diagnostic Policy Learning in Clinical Applications via Semi-Model-Based Deep Reinforcement Learning | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 4025 | Closing the gap: Exact maximum likelihood training of generative autoencoders using invertible layers | 7.00 | 7.50 | 0.50 | [8, 8, 8, 6]
|
| 4026 | ACAT: Adversarial Counterfactual Attention for Classification and Detection in Medical Imaging | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 4027 | Dynamics-inspired Neuromorphic Representation Learning | 4.67 | 4.67 | 0.00 | [8, 3, 3]
|
| 4028 | Abstract Visual Reasoning by Self-supervised Contrastive Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 4029 | POPGym: Benchmarking Partially Observable Reinforcement Learning | 6.33 | 6.33 | 0.00 | [3, 8, 8]
|
| 4030 | ETAD: A Sampling-Based Approach for Efficient Temporal Action Detection | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 4031 | HierBatching: Locality-Aware Out-of-Core Training of Graph Neural Networks | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 4032 | Everybody Needs Good Neighbours: An Unsupervised Locality-based Method for Bias Mitigation | 6.25 | 6.25 | 0.00 | [5, 6, 8, 6]
|
| 4033 | Continual Learning In Low-coherence Subspace: A Strategy To Mitigate Learning Capacity Degradation | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 4034 | Particle-based Variational Inference with Preconditioned Functional Gradient Flow | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 4035 | An Efficient Mean-field Approach to High-Order Markov Logic | 5.50 | 5.50 | 0.00 | [8, 5, 6, 3]
|
| 4036 | A theory of representation learning in neural networks gives a deep generalisation of kernel methods | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 4037 | A spatiotemporal graph neural network with multi granularity for air quality prediction | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 4038 | Highway Reinforcement Learning | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 4039 | Learning Locality and Isotropy in Dialogue Modeling | 5.75 | 5.75 | 0.00 | [8, 3, 6, 6]
|
| 4040 | Dynamic Historical Adaptation for Continual Image-Text Modeling | 6.50 | 6.50 | 0.00 | [5, 8, 5, 8]
|
| 4041 | AutoGT: Automated Graph Transformer Architecture Search | 7.33 | 8.00 | 0.67 | [8, 8, 8]
|
| 4042 | Rememory-Based SimSiam for Unsupervised Continual Learning | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 4043 | OPERA: Omni-Supervised Representation Learning with Hierarchical Supervisions | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 4044 | i-MAE: Are Latent Representations in Masked Autoencoders Linearly Separable? | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 4045 | Logit Margin Matters: Improving Transferable Targeted Adversarial Attack by Logit Calibration | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 4046 | GSCA: Global Spatial Correlation Attention | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 4047 | Cross Modal Domain Generalization for Query-based Video Segmentation | 5.25 | 5.25 | 0.00 | [5, 5, 8, 3]
|
| 4048 | Accumulative Poisoning Defense with Memorization Discrepancy | 4.25 | 4.25 | 0.00 | [3, 3, 6, 5]
|
| 4049 | Combating Exacerbated Heterogeneity for Robust Decentralized Models | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 4050 | Shot Retrieval and Assembly with Text Script for Video Montage Generation | 4.50 | 4.50 | 0.00 | [6, 3, 6, 3]
|
| 4051 | Pruning with Output Error Minimization for Producing Efficient Neural Networks | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 4052 | Orientation-Aware Graph Neural Networks for Protein Structure Representation Learning | 5.50 | 5.50 | 0.00 | [3, 5, 8, 6]
|
| 4053 | Adaptive Update Direction Rectification for Unsupervised Continual Learning | 5.75 | 6.00 | 0.25 | [6, 6, 6, 6]
|
| 4054 | Language Model Pre-training with Linguistically Motivated Curriculum Learning | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 4055 | Towards Generalized Combinatorial Solvers via Reward Adjustment Policy Optimization | 3.50 | 3.50 | 0.00 | [5, 5, 3, 1]
|
| 4056 | Offline Reinforcement Learning with Closed-Form Policy Improvement Operators | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 4057 | Sensitivity-aware Visual Parameter-efficient Tuning | 4.80 | 4.80 | 0.00 | [5, 3, 6, 5, 5]
|
| 4058 | Towards Robust Object Detection Invariant to Real-World Domain Shifts | 6.25 | 6.25 | 0.00 | [5, 6, 6, 8]
|
| 4059 | Light Sampling Field and BRDF Representation for Physically-based Neural Rendering | 6.25 | 6.25 | 0.00 | [3, 8, 8, 6]
|
| 4060 | Margin-based Neural Network Watermarking | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 4061 | Your Denoising Implicit Model is a Sub-optimal Ensemble of Denoising Predictions | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 4062 | DREAM: Domain-free Reverse Engineering Attributes of Black-box Model | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 4063 | Structural Generalization of Visual Imitation Learning with Position-Invariant Regularization | 4.33 | 4.67 | 0.33 | [3, 6, 5]
|
| 4064 | Dealing with missing data using attention and latent space regularization | 3.40 | 3.40 | 0.00 | [3, 3, 3, 5, 3]
|
| 4065 | Revisiting Global Pooling through the Lens of Optimal Transport | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 4066 | On the Importance of Pretrained Knowledge Distillation for 3D Object Detection | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 4067 | Bidirectional Propagation for Cross-Modal 3D Object Detection | 6.25 | 6.25 | 0.00 | [6, 8, 6, 5]
|
| 4068 | Policy Pre-training for Autonomous Driving via Self-supervised Geometric Modeling | 6.25 | 6.25 | 0.00 | [6, 8, 5, 6]
|
| 4069 | Towards Expressive Graph Representations for Graph Neural Networks | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 4070 | EurNet: Efficient Multi-Range Relational Modeling of Spatial Multi-Relational Data | 6.25 | 6.25 | 0.00 | [8, 6, 5, 6]
|
| 4071 | TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 4072 | Learning without Prejudices: Continual Unbiased Learning via Benign and Malignant Forgetting | 6.50 | 6.50 | 0.00 | [5, 5, 8, 8]
|
| 4073 | FINDE: Neural Differential Equations for Finding and Preserving Invariant Quantities | 6.25 | 6.25 | 0.00 | [8, 3, 6, 8]
|
| 4074 | Approximate Vanishing Ideal Computations at Scale | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 4075 | How you start matters for generalization | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 4076 | Understanding Incremental Learning of Gradient Descent: A Fine-grained analysis of Matrix Sensing | 5.33 | 5.33 | 0.00 | [8, 5, 3]
|
| 4077 | Selective Annotation Makes Language Models Better Few-Shot Learners | 6.00 | 6.00 | 0.00 | [8, 6, 5, 5]
|
| 4078 | Switch-NeRF: Learning Scene Decomposition with Mixture of Experts for Large-scale Neural Radiance Fields | 7.00 | 7.00 | 0.00 | [8, 6, 6, 8]
|
| 4079 | Efficient, Stable, and Analytic Differentiation of the Sinkhorn Loss | 4.50 | 4.50 | 0.00 | [3, 6, 6, 3]
|
| 4080 | A Holistic View of Noise Transition Matrix in Deep Learning and Beyond | 7.20 | 7.20 | 0.00 | [8, 6, 8, 6, 8]
|
| 4081 | Active Learning in Bayesian Neural Networks with Balanced Entropy Learning Principle | 6.67 | 7.33 | 0.67 | [8, 8, 6]
|
| 4082 | Near-Optimal Adversarial Reinforcement Learning with Switching Costs | 6.25 | 6.25 | 0.00 | [3, 6, 8, 8]
|
| 4083 | Bias Mitigation Framework for Intersectional Subgroups in Neural Networks | 4.75 | 4.75 | 0.00 | [3, 3, 5, 8]
|
| 4084 | NORM: Knowledge Distillation via N-to-One Representation Matching | 5.75 | 5.75 | 0.00 | [8, 5, 5, 5]
|
| 4085 | Downstream Datasets Make Surprisingly Good Pretraining Corpora | 5.50 | 6.00 | 0.50 | [8, 5, 6, 5]
|
| 4086 | Revisiting Embeddings for Graph Neural Networks | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 4087 | NOAH: A New Head Structure To Improve Deep Neural Networks For Image Classification | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 4088 | Empirical analysis of representation learning and exploration in neural kernel bandits | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 4089 | S^2-Transformer for Mask-Aware Hyperspectral Image Reconstruction | 4.25 | 4.25 | 0.00 | [5, 3, 3, 6]
|
| 4090 | Exploiting Spatial Separability for Deep Learning Multichannel Speech Enhancement with an Align-and-Filter Network | 5.00 | 5.00 | 0.00 | [6, 3, 5, 6]
|
| 4091 | A deep top-down approach to hierarchically coherent probabilistic forecasting | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 4092 | CroMA: Cross-Modality Adaptation for Monocular BEV Perception | 5.75 | 5.75 | 0.00 | [8, 5, 5, 5]
|
| 4093 | CausalAgents: A Robustness Benchmark for Motion Forecasting Using Causal Relationships | 5.00 | 5.00 | 0.00 | [6, 5, 6, 3, 5]
|
| 4094 | Adaptive Client Sampling in Federated Learning via Online Learning with Bandit Feedback | 6.00 | 6.00 | 0.00 | [8, 6, 5, 5]
|
| 4095 | Dynamical Isometry for Residual Networks | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 4096 | How Erdös and Rényi Win the Lottery | 3.33 | 3.33 | 0.00 | [1, 3, 6]
|
| 4097 | PVT++: A Simple End-to-End Latency-Aware Visual Tracking Framework | 4.00 | 4.00 | 0.00 | [3, 3, 5, 5]
|
| 4098 | GPViT: A High Resolution Non-Hierarchical Vision Transformer with Group Propagation | 7.67 | 7.67 | 0.00 | [10, 5, 8]
|
| 4099 | Variational Imbalanced Regression | 4.80 | 4.80 | 0.00 | [1, 6, 6, 6, 5]
|
| 4100 | EMO: Episodic Memory Optimization for Few-Shot Meta-Learning | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 4101 | Critic Sequential Monte Carlo | 5.00 | 4.75 | -0.25 | [6, 1, 6, 6]
|
| 4102 | Radial Spike and Slab Bayesian Neural Networks for Sparse Data in Ransomware Attacks | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 4103 | Autoencoders as Cross-Modal Teachers: Can Pretrained 2D Image Transformers Help 3D Representation Learning? | 7.25 | 7.25 | 0.00 | [5, 10, 6, 8]
|
| 4104 | Explainability of deep reinforcement learning algorithms in robotic domains by using Layer-wise Relevance Propagation | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 4105 | High Dimensional Bayesian Optimization with Reinforced Transformer Deep Kernels | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 4106 | Learning to Take a Break: Sustainable Optimization of Long-Term User Engagement | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 4107 | Laziness, Barren Plateau, and Noises in Machine Learning | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 4108 | HyperQuery: A Framework for Higher Order Link Prediction | 4.75 | 4.75 | 0.00 | [3, 5, 5, 6]
|
| 4109 | Generative Model Based Noise Robust Training for Unsupervised Domain Adaptation | 4.33 | 4.75 | 0.42 | [6, 5, 5, 3]
|
| 4110 | Deep Learning meets Nonparametric Regression: Are Weight-Decayed DNNs Locally Adaptive? | 4.50 | 5.75 | 1.25 | [6, 6, 6, 5]
|
| 4111 | Sparse Token Transformer with Attention Back Tracking | 6.25 | 6.25 | 0.00 | [8, 6, 6, 5]
|
| 4112 | A Deep Conjugate Direction Method for Iteratively Solving Linear Systems | 4.40 | 4.40 | 0.00 | [8, 3, 5, 3, 3]
|
| 4113 | MixMask: Revisiting Masked Siamese Self-supervised Learning in Asymmetric Distance | 4.40 | 4.40 | 0.00 | [5, 6, 3, 5, 3]
|
| 4114 | Smart Multi-tenant Federated Learning | 4.25 | 4.25 | 0.00 | [3, 3, 8, 3]
|
| 4115 | Robust Active Distillation | 6.67 | 6.67 | 0.00 | [6, 8, 6]
|
| 4116 | Controllable Image Generation via Collage Representations | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 4117 | Robust Multi-Agent Reinforcement Learning with State Uncertainties | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 4118 | Tiny Adapters for Vision Transformers | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 4119 | Accelerating Inverse Reinforcement Learning with Expert Bootstrapping | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 4120 | Kernel Neural Optimal Transport | 6.25 | 6.25 | 0.00 | [6, 6, 5, 8]
|
| 4121 | Neural Optimal Transport | 7.33 | 7.33 | 0.00 | [8, 8, 6]
|
| 4122 | SeaFormer: Squeeze-enhanced Axial Transformer for Mobile Semantic Segmentation | 6.00 | 6.00 | 0.00 | [5, 8, 3, 8]
|
| 4123 | Joint Edge-Model Sparse Learning is Provably Efficient for Graph Neural Networks | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 4124 | Harnessing spectral representations for subgraph alignment | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 4125 | MotifExplainer: a Motif-based Graph Neural Network Explainer | 4.80 | 5.00 | 0.20 | [6, 5, 3, 6, 5]
|
| 4126 | Receding Neuron Importances for Structured Pruning | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 4127 | Learning Sparse and Low-Rank Priors for Image Recovery via Iterative Reweighted Least Squares Minimization | 6.33 | 6.67 | 0.33 | [8, 6, 6]
|
| 4128 | Unifying Diffusion Models" Latent Space, with Applications to CycleDiffusion and Guidance | 4.83 | 5.17 | 0.33 | [6, 8, 5, 3, 6, 3]
|
| 4129 | Proximal Curriculum for Reinforcement Learning Agents | 4.75 | 4.25 | -0.50 | [6, 3, 3, 5]
|
| 4130 | Spherical Sliced-Wasserstein | 6.50 | 6.50 | 0.00 | [6, 6, 8, 6]
|
| 4131 | Intepreting & Improving Pretrained Language Models: A Probabilistic Conceptual Approach | 4.25 | 4.25 | 0.00 | [3, 3, 3, 8]
|
| 4132 | Neural Optimal Transport with General Cost Functionals | 5.75 | 5.75 | 0.00 | [8, 6, 3, 6]
|
| 4133 | Does Dataset Lottery Ticket Hypothesis Exist? | 4.60 | 4.60 | 0.00 | [5, 6, 6, 3, 3]
|
| 4134 | Random Weight Factorization improves the training of Continuous Neural Representations | 4.75 | 4.75 | 0.00 | [3, 3, 5, 8]
|
| 4135 | Triangle Inequality for Inverse Optimal Control | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 4136 | InPL: Pseudo-labeling the Inliers First for Imbalanced Semi-supervised Learning | 5.25 | 5.25 | 0.00 | [6, 6, 3, 6]
|
| 4137 | Mixed-Precision Inference Quantization: Problem Resetting, Mapping math concept and Branch\&bound methods | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 4138 | Latent Offline Distributional Actor-Critic | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 4139 | Mixed-Precision Inference Quantization: Radically Towards Faster inference speed, Lower Storage requirement, and Lower Loss | 3.00 | 3.00 | 0.00 | [5, 3, 1]
|
| 4140 | Leveraging Double Descent for Scientific Data Analysis: Face-Based Social Behavior as a Case Study | 3.00 | 3.00 | 0.00 | [5, 3, 1, 3]
|
| 4141 | Fusion of Deep Transfer Learning with Mixed convolution network | 1.50 | 1.50 | 0.00 | [1, 1, 3, 1]
|
| 4142 | CONTINUAL MODEL EVOLVEMENT WITH INNER-PRODUCT RESTRICTION | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 4143 | Maximizing Communication Efficiency for Large-scale Training via 0/1 Adam | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 4144 | PREF: Phasorial Embedding Fields for Compact Neural Representations | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 4145 | Truthful Self-Play | 6.33 | 6.33 | 0.00 | [6, 5, 8]
|
| 4146 | Iterative $\alpha$-(de)Blending: Learning a Deterministic Mapping Between Arbitrary Densities | 6.25 | 5.75 | -0.50 | [6, 3, 6, 8]
|
| 4147 | Strategic Classification on Graphs | 5.75 | 5.75 | 0.00 | [6, 8, 6, 3]
|
| 4148 | Causal Information Bottleneck Boosts Adversarial Robustness of Deep Neural Network | 2.50 | 2.50 | 0.00 | [5, 1, 3, 1]
|
| 4149 | Continual Transformers: Redundancy-Free Attention for Online Inference | 6.33 | 6.33 | 0.00 | [8, 5, 6]
|
| 4150 | FedPSE: Personalized Sparsification with Element-wise Aggregation for Federated Learning | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 4151 | Towards Online Real-Time Memory-based Video Inpainting Transformers | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 4152 | Dimensionality-Varying Diffusion Process | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 4153 | Edge-Varying Fourier Graph Network for Multivariate Time Series Forecasting | 5.20 | 5.20 | 0.00 | [5, 5, 6, 5, 5]
|
| 4154 | Learning Symbolic Models for Graph-structured Physical Mechanism | 6.00 | 6.00 | 0.00 | [8, 5, 5]
|
| 4155 | Leveraging variational autoencoders for multiple data imputation | 3.50 | 3.50 | 0.00 | [5, 3, 1, 5]
|
| 4156 | Unleashing Mask: Explore the Intrinsic Out-of-distribution Detection Capability | 5.50 | 5.50 | 0.00 | [3, 5, 8, 6]
|
| 4157 | Dirichlet-based Uncertainty Calibration for Active Domain Adaptation | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 4158 | Accurate Image Restoration with Attention Retractable Transformer | 7.50 | 7.50 | 0.00 | [6, 8, 8, 8]
|
| 4159 | Adan: Adaptive Nesterov Momentum Algorithm for Faster Optimizing Deep Models | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 4160 | Imitate Your Own Refinement: Knowledge Distillation Sheds Light on Efficient Image-to-Image Translation | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 4161 | Efficient Trojan Injection: 90% Attack Success Rate Using 0.04% Poisoned Samples | 4.25 | 4.25 | 0.00 | [6, 3, 3, 5]
|
| 4162 | Priors, Hierarchy, and Information Asymmetry for Skill Transfer in Reinforcement Learning | 5.75 | 6.25 | 0.50 | [6, 6, 5, 8]
|
| 4163 | Self-Supervised Set Representation Learning for Unsupervised Meta-Learning | 5.25 | 5.25 | 0.00 | [5, 5, 6, 5]
|
| 4164 | Neural Episodic Control with State Abstraction | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 4165 | Minibatch Stochastic Three Points Method for Unconstrained Smooth Minimization | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 4166 | Multigraph Topology Design for Cross-Silo Federated Learning | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 4167 | Universal Speech Enhancement with Score-based Diffusion | 5.50 | 5.50 | 0.00 | [5, 6, 6, 5]
|
| 4168 | Partial Advantage Estimator for Proximal Policy Optimization | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 4169 | Critical Sampling for Robust Evolution Behavior Learning of Unknown Dynamical Systems | 5.33 | 5.33 | 0.00 | [5, 8, 3]
|
| 4170 | Causal Representation Learning for Instantaneous and Temporal Effects | 6.50 | 6.50 | 0.00 | [5, 5, 8, 8]
|
| 4171 | Visual Imitation Learning with Patch Rewards | 5.75 | 5.75 | 0.00 | [6, 8, 6, 3]
|
| 4172 | Planning Immediate Landmarks of Targets for Model-Free Skill Transfer across Agents | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 4173 | Gated Class-Attention with Cascaded Feature Drift Compensation for Exemplar-free Continual Learning of Vision Transformers | 5.00 | 5.00 | 0.00 | [3, 6, 6, 5]
|
| 4174 | AdaDQH Optimizer: Evolving from Stochastic to Adaptive by Auto Switch of Precondition Matrix | 6.00 | 6.00 | 0.00 | [5, 5, 8]
|
| 4175 | CodeT: Code Generation with Generated Tests | 5.50 | 6.00 | 0.50 | [8, 5, 3, 8]
|
| 4176 | Learning Specialized Activation Functions for Physics-informed Neural Networks | 5.25 | 6.25 | 1.00 | [6, 8, 8, 3]
|
| 4177 | Dateformer: Transformer Extends Look-back Horizon to Predict Longer-term Time Series | 5.25 | 5.25 | 0.00 | [6, 3, 6, 6]
|
| 4178 | CAMVR: Context-Adaptive Multi-View Representation Learning for Dense Retrieval | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 4179 | BIL: Bandit Inference Learning for Online Representational Similarity Test | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 4180 | Adam Accumulation to Reduce Memory Footprints of both Activations and Gradients for Large-scale DNN Training | 5.00 | 4.50 | -0.50 | [3, 6, 3, 6]
|
| 4181 | Learning to Generate Columns with Application to Vertex Coloring | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 4182 | On Storage Neural Network Augmented Approximate Nearest Neighbor Search | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 4183 | TPC-NAS: Sub-Five-Minute Neural Architecture Search for Image Classification, Object-Detection, and Super-Resolution | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 4184 | The Role of ImageNet Classes in Fréchet Inception Distance | 6.50 | 6.50 | 0.00 | [8, 5, 5, 8]
|
| 4185 | Diffusion Models Already Have A Semantic Latent Space | 6.25 | 6.50 | 0.25 | [6, 6, 8, 6]
|
| 4186 | Improving group robustness under noisy labels using predictive uncertainty | 4.75 | 4.75 | 0.00 | [5, 6, 3, 5]
|
| 4187 | Mutual Information Regularized Offline Reinforcement Learning | 5.00 | 5.00 | 0.00 | [6, 6, 5, 3]
|
| 4188 | Towards Real-Time Neural Image Compression With Mask Decay | 6.25 | 6.25 | 0.00 | [8, 8, 3, 6]
|
| 4189 | Zero-Shot Image Restoration Using Denoising Diffusion Null-Space Model | 6.75 | 6.75 | 0.00 | [8, 6, 8, 5]
|
| 4190 | Rethinking Learning Dynamics in RL using Adversarial Networks | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 4191 | Predicting Cellular Responses with Variational Causal Inference and Refined Relational Information | 6.25 | 6.25 | 0.00 | [6, 8, 6, 5]
|
| 4192 | Exploit Unlabeled Data on the Server! Federated Learning via Uncertainty-aware Ensemble Distillation and Self-Supervision | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 4193 | Sample Importance in SGD Training | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 4194 | ResAct: Reinforcing Long-term Engagement in Sequential Recommendation with Residual Actor | 7.25 | 7.25 | 0.00 | [5, 8, 8, 8]
|
| 4195 | Dataset Pruning: Reducing Training Data by Examining Generalization Influence | 6.00 | 6.40 | 0.40 | [8, 5, 6, 8, 5]
|
| 4196 | Visual Timing For Sound Source Depth Estimation in the Wild | 5.00 | 5.00 | 0.00 | [5, 6, 3, 6]
|
| 4197 | Masked Visual-Textual Prediction for Document Image Representation Pretraining | 6.75 | 6.75 | 0.00 | [5, 6, 8, 8]
|
| 4198 | Physics-Regularized Stereo Matching for Depth Estimation | 3.75 | 3.75 | 0.00 | [3, 3, 8, 1]
|
| 4199 | Learning Robust �Goal Space with Hypothetical Analogy-Making | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 4200 | Link Prediction without Graph Neural Networks | 3.25 | 3.25 | 0.00 | [3, 3, 6, 1]
|
| 4201 | AdaStride: Using Adaptive Strides in Sequential Data for Effective Downsampling | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 4202 | SAE: Estimation for Transition Matrix in Annotation Algorithms | 2.33 | 2.33 | 0.00 | [3, 1, 3]
|
| 4203 | Subclass-balancing Contrastive Learning for Long-tailed Recognition | 5.00 | 5.50 | 0.50 | [6, 5, 5, 6]
|
| 4204 | Effective Cross-instance Positive Relations for Generalized Category Discovery | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 4205 | Learning Symbolic Rules for Reasoning in Quasi-Natural Language | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 4206 | Parallel Federated Learning over Heterogeneous Devices | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 4207 | Deep Duplex Learning for Weak Supervision | 3.00 | 3.00 | 0.00 | [5, 3, 1, 3]
|
| 4208 | Plateau in Monotonic Linear Interpolation --- A "Biased" View of Loss Landscape for Deep Networks | 7.00 | 7.00 | 0.00 | [6, 8, 8, 6]
|
| 4209 | Expected Gradients of Maxout Networks and Consequences to Parameter Initialization | 6.00 | 6.20 | 0.20 | [6, 5, 6, 6, 8]
|
| 4210 | The KFIoU Loss for Rotated Object Detection | 5.60 | 5.60 | 0.00 | [3, 5, 6, 6, 8]
|
| 4211 | Crossformer: Transformer Utilizing Cross-Dimension Dependency for Multivariate Time Series Forecasting | 6.75 | 7.25 | 0.50 | [8, 5, 8, 8]
|
| 4212 | Focusing on what to decode and what to train: Efficient Training with HOI Split Decoders and Split Target Guided DeNoising | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 4213 | Go-Explore with a guide: Speeding up search in sparse reward settings with goal-directed intrinsic rewards | 2.50 | 2.50 | 0.00 | [3, 3, 3, 1]
|
| 4214 | Mugs: A Multi-Granular Self-Supervised Learning Framework | 4.67 | 4.67 | 0.00 | [3, 8, 3]
|
| 4215 | Is Stochastic Gradient Descent Near Optimal? | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 4216 | BrainBERT: Self-supervised representation learning for Intracranial Electrodes | 6.25 | 6.25 | 0.00 | [6, 8, 6, 5]
|
| 4217 | Logic-aware Pre-training of Language Models | 4.20 | 4.20 | 0.00 | [5, 5, 5, 5, 1]
|
| 4218 | Individual Fairness of Data Provider Regarding Privacy Risk and Gain | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 4219 | Critical Learning Periods Augmented Model Poisoning Attacks to Byzantine-Robust Federated Learning | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 4220 | Semi-connected Joint Entity Recognition and Relation Extraction of Contextual Entities in Family History Records | 2.00 | 2.00 | 0.00 | [1, 3, 3, 1]
|
| 4221 | Semi-supervised Node Classification with Imbalanced Receptive Field | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 4222 | On the Universality of Langevin Diffusion for Private Euclidean (Convex) Optimization | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 4223 | Fast Test-Time Adaptation Using Hints | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 4224 | Multi-Dataset Multi-Task Framework for Learning Molecules and Protein-target Interactions Properties | 4.25 | 4.25 | 0.00 | [5, 3, 3, 6]
|
| 4225 | General Neural Gauge Fields | 5.40 | 5.40 | 0.00 | [5, 6, 5, 6, 5]
|
| 4226 | Learning Disentanglement in Autoencoders through Euler Encoding | 5.00 | 5.00 | 0.00 | [6, 5, 6, 3]
|
| 4227 | Nonlinear Reconstruction for Operator Learning of PDEs with Discontinuities | 6.25 | 6.75 | 0.50 | [8, 8, 3, 8]
|
| 4228 | Grafting Vision Transformers | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 4229 | Generate rather than Retrieve: Large Language Models are Strong Context Generators | 8.00 | 8.00 | 0.00 | [6, 8, 10, 8]
|
| 4230 | Online Continual Learning for Progressive Distribution Shift (OCL-PDS): A Practitioner"s Perspective | 6.00 | 6.00 | 0.00 | [6, 10, 3, 5]
|
| 4231 | Discovering Informative and Robust Positives for Video Domain Adaptation | 5.75 | 5.75 | 0.00 | [6, 6, 6, 5]
|
| 4232 | Understanding Why Generalized Reweighting Does Not Improve Over ERM | 6.00 | 6.00 | 0.00 | [8, 5, 5, 6]
|
| 4233 | Betty: An Automatic Differentiation Library for Multilevel Optimization | 8.00 | 8.00 | 0.00 | [8, 10, 6, 8]
|
| 4234 | PatchBlender: A Motion Prior for Video Transformers | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 4235 | Linear Connectivity Reveals Generalization Strategies | 6.75 | 6.75 | 0.00 | [6, 8, 5, 8]
|
| 4236 | CEREAL: Few-Sample Clustering Evaluation | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 4237 | MonoDETR: Depth-guided Transformer for Monocular 3D Object Detection | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 4238 | Gradient-Guided Importance Sampling for Learning Binary Energy-Based Models | 5.75 | 6.25 | 0.50 | [6, 6, 8, 5]
|
| 4239 | Your Neighbors Are Communicating: Towards Powerful and Scalable Graph Neural Networks | 4.75 | 4.75 | 0.00 | [3, 5, 5, 6]
|
| 4240 | PATCorrect: Non-autoregressive Phoneme-augmented Transformer for ASR Error Correction | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 4241 | Composing Ensembles of Pre-trained Models via Iterative Consensus | 6.00 | 6.00 | 0.00 | [5, 5, 8, 6]
|
| 4242 | Automated Data Augmentations for Graph Classification | 7.00 | 7.33 | 0.33 | [8, 8, 6]
|
| 4243 | Learning Label Encodings for Deep Regression | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 4244 | Riemannian Metric Learning via Optimal Transport | 6.00 | 6.00 | 0.00 | [8, 5, 6, 5]
|
| 4245 | CLR-GAM: Contrastive Point Cloud Learning with Guided Augmentation and Feature Mapping | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 4246 | Computational-Unidentifiability in Representation for Fair Downstream Tasks | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 4247 | Reliability of CKA as a Similarity Measure in Deep Learning | 5.25 | 5.25 | 0.00 | [3, 8, 5, 5]
|
| 4248 | Gradient Properties of Hard Thresholding Operator | 3.00 | 3.00 | 0.00 | [5, 3, 3, 1]
|
| 4249 | Fair Attribute Completion on Graph with Missing Attributes | 4.75 | 5.75 | 1.00 | [5, 6, 6, 6]
|
| 4250 | Comfort Zone: A Vicinal Distribution for Regression Problems | 5.25 | 5.25 | 0.00 | [6, 6, 6, 3]
|
| 4251 | Implicit Neural Spatial Representations for Time-dependent PDEs | 4.83 | 5.17 | 0.33 | [5, 6, 3, 6, 5, 6]
|
| 4252 | Deep Ranking Ensembles for Hyperparameter Optimization | 7.33 | 7.33 | 0.00 | [6, 8, 8]
|
| 4253 | Multi-skill Mobile Manipulation for Object Rearrangement | 7.25 | 7.25 | 0.00 | [5, 6, 10, 8]
|
| 4254 | Robustness to corruption in pre-trained Bayesian neural networks | 6.33 | 6.67 | 0.33 | [8, 6, 6]
|
| 4255 | Accelerating Federated Learning Convergence via Opportunistic Mobile Relaying | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 4256 | What Knowledge gets Distilled in Knowledge Distillation? | 5.50 | 5.50 | 0.00 | [3, 5, 8, 6]
|
| 4257 | Single-shot General Hyper-parameter Optimization for Federated Learning | 5.75 | 5.75 | 0.00 | [8, 6, 3, 6]
|
| 4258 | Spatially constrained Adversarial Attack Detection and Localization in the Representation Space of Optical Flow Networks | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 4259 | Weakly-supervised HOI Detection via Prior-guided Bi-level Representation Learning | 5.60 | 6.00 | 0.40 | [8, 3, 8, 5, 6]
|
| 4260 | Meta-learning Adaptive Deep Kernel Gaussian Processes for Molecular Property Prediction | 6.33 | 7.33 | 1.00 | [6, 8, 8]
|
| 4261 | ERL-Re$^2$: Efficient Evolutionary Reinforcement Learning with Shared State Representation and Individual Policy Representation | 5.75 | 6.25 | 0.50 | [5, 6, 6, 8]
|
| 4262 | $\mathrm{R}^2$-VOS: Robust Referring Video Object Segmentation via Relational Cycle Consistency | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 4263 | Least-to-Most Prompting Enables Complex Reasoning in Large Language Models | 4.50 | 6.25 | 1.75 | [5, 6, 8, 6]
|
| 4264 | Deep Ensembles for Graphs with Higher-order Dependencies | 4.25 | 4.25 | 0.00 | [3, 5, 3, 6]
|
| 4265 | Simplicial Embeddings in Self-Supervised Learning and Downstream Classification | 5.50 | 7.00 | 1.50 | [8, 6, 8, 6]
|
| 4266 | Lossless Filter Pruning via Adaptive Clustering for Convolutional Neural Networks | 4.50 | 5.00 | 0.50 | [5, 5, 5, 5]
|
| 4267 | ViT-Adapter: Exploring Plain Vision Transformer for Accurate Dense Predictions | 6.75 | 6.75 | 0.00 | [8, 8, 5, 6]
|
| 4268 | Towards Understanding Why Mask Reconstruction Pretraining Helps in Downstream Tasks | 6.50 | 6.50 | 0.00 | [6, 6, 8, 6]
|
| 4269 | Similarity and Generalization: from Noise to Corruption | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 4270 | On Trace of PGD-Like Adversarial Attacks | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 4271 | MEGAN: Multi Explanation Graph Attention Network | 4.25 | 3.75 | -0.50 | [3, 3, 6, 3]
|
| 4272 | Learning Control Lyapunov Functions For High-dimensional Unknown Systems using Guided Iterative State Space Exploration | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 4273 | Practical Approaches for Fair Learning with Multitype and Multivariate Sensitive Attributes | 4.25 | 4.25 | 0.00 | [5, 6, 5, 1]
|
| 4274 | Self-Supervised Category-Level Articulated Object Pose Estimation with Part-Level SE(3) Equivariance | 7.00 | 7.00 | 0.00 | [6, 6, 6, 10]
|
| 4275 | Universal Mini-Batch Consistency for Set Encoding Functions | 4.00 | 4.50 | 0.50 | [5, 3, 5, 5]
|
| 4276 | Learn the Time to Learn: Replay Scheduling in Continual Learning | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 4277 | Divide to Adapt: Mitigating Confirmation Bias for Domain Adaptation of Black-Box Predictors | 5.00 | 6.20 | 1.20 | [3, 8, 6, 8, 6]
|
| 4278 | Thalamus: a brain-inspired algorithm for biologically-plausible continual learning and disentangled representations | 5.50 | 6.00 | 0.50 | [8, 6, 5, 5]
|
| 4279 | A Generalized EigenGame With Extensions to Deep Multiview Representation Learning | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 4280 | Deep Variational Implicit Processes | 6.00 | 6.00 | 0.00 | [8, 5, 6, 5]
|
| 4281 | Denoising Masked Autoencoders are Certifiable Robust Vision Learners | 5.00 | 6.00 | 1.00 | [5, 5, 8, 6]
|
| 4282 | Estimating individual treatment effects under unobserved confounding using binary instruments | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 4283 | Approximate Bayesian Inference with Stein Functional Variational Gradient Descent | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 4284 | Soundness and Completeness: An Algorithmic Perspective on Evaluation of Feature Attribution | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 4285 | SCoMoE: Efficient Mixtures of Experts with Structured Communication | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 4286 | Locally Invariant Explanations: Towards Stable and Unidirectional Explanations through Local Invariant Learning | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 4287 | Uncertainty-Aware Self-Supervised Learning with Independent Sub-networks | 5.75 | 5.75 | 0.00 | [5, 5, 5, 8]
|
| 4288 | Prompt Learning with Optimal Transport for Vision-Language Models | 6.50 | 6.50 | 0.00 | [8, 6, 6, 6]
|
| 4289 | An Additive Instance-Wise Approach to Multi-class Model Interpretation | 5.67 | 5.67 | 0.00 | [3, 6, 8]
|
| 4290 | Knowledge-Consistent Dialogue Generation with Language Models and Knowledge Graphs | 5.67 | 5.67 | 0.00 | [3, 8, 8, 3, 6, 6]
|
| 4291 | Offline Model-Based Reinforcement Learning with Causal Structure | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 4292 | Towards Semi-Supervised Learning with Non-Random Missing Labels | 5.67 | 5.75 | 0.08 | [6, 6, 6, 5]
|
| 4293 | Improving Generalization with Domain Convex Game | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 4294 | Elastic Mean-Teacher Distillation Mitigates the Continual Learning Stability Gap | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 4295 | Neural Prompt Search | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 4296 | It Takes Two: Masked Appearance-Motion Modeling for Self-Supervised Video Transformer Pre-Training | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 4297 | DASHA: Distributed Nonconvex Optimization with Communication Compression and Optimal Oracle Complexity | 6.50 | 6.50 | 0.00 | [6, 8, 6, 6]
|
| 4298 | LDMIC: Learning-based Distributed Multi-view Image Coding | 6.50 | 6.50 | 0.00 | [8, 6, 6, 6]
|
| 4299 | Improving Differentially-Private Deep Learning with Gradients Index Pruning | 4.00 | 4.00 | 0.00 | [3, 3, 6, 5, 3]
|
| 4300 | Additive Poisson Process: Learning Intensity of Higher-Order Interaction in Poisson Processes | 3.75 | 3.75 | 0.00 | [3, 3, 3, 6]
|
| 4301 | Sound Randomized Smoothing in Floating-Point Arithmetic | 6.25 | 6.25 | 0.00 | [5, 8, 6, 6]
|
| 4302 | Shuffle Gaussian Mechanism for Differential Privacy | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 4303 | Assessing Model Out-of-distribution Generalization with Softmax Prediction Probability Baselines and A Correlation Method | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 4304 | In-the-wild Pretrained Models Are Good Feature Extractors for Video Quality Assessment | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 4305 | Collaborative Pure Exploration in Kernel Bandit | 6.75 | 6.75 | 0.00 | [5, 6, 8, 8]
|
| 4306 | Provably Efficient Risk-Sensitive Reinforcement Learning: Iterated CVaR and Worst Path | 6.25 | 6.25 | 0.00 | [8, 8, 3, 6]
|
| 4307 | FedREP: A Byzantine-Robust, Communication-Efficient and Privacy-Preserving Framework for Federated Learning | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 4308 | Few-Shot Transferable Robust Representation Learning via Bilevel Attacks | 5.00 | 5.00 | 0.00 | [6, 3, 6, 5]
|
| 4309 | Targeted Adversarial Self-Supervised Learning | 4.25 | 4.25 | 0.00 | [5, 3, 6, 3]
|
| 4310 | Accurate and Efficient Soma Reconstruction in a Full Adult Fly Brain | 3.00 | 3.00 | 0.00 | [3, 1, 5]
|
| 4311 | NIERT: Accurate Numerical Interpolation through Unifying Scattered Data Representations using Transformer Encoder | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 4312 | Triplet Similarity Learning on Concordance Constraint | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 4313 | Temporal Label Smoothing for Early Prediction of Adverse Events | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 4314 | Test-Time Robust Personalization for Federated Learning | 6.25 | 6.75 | 0.50 | [8, 5, 6, 8]
|
| 4315 | What"s Wrong with the Robustness of Object Detectors? | 3.67 | 3.67 | 0.00 | [5, 1, 5]
|
| 4316 | LAVA: Data Valuation without Pre-Specified Learning Algorithms | 6.75 | 8.00 | 1.25 | [8, 8, 8, 8]
|
| 4317 | FONDUE: an Algorithm to Find the Optimal Dimensionality of the Latent Representations of Variational Autoencoders | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 4318 | Distortion-Aware Network Pruning and Feature Reuse for Real-time Video Segmentation | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 4319 | An Encryption Framework for Pre-Trained Neural Networks | 3.00 | 3.00 | 0.00 | [5, 3, 1]
|
| 4320 | How do Variational Autoencoders Learn? Insights from Representational Similarity | 5.20 | 5.20 | 0.00 | [5, 5, 5, 3, 8]
|
| 4321 | Meta-prediction Model for Distillation-Aware NAS on Unseen Datasets | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 4322 | Manifold Characteristics That Predict Downstream Task Performance | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 4323 | Context Autoencoder for Self-Supervised Representation Learning | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 4324 | Learning to Linearize Deep Neural Networks for Secure and Efficient Private Inference | 5.00 | 6.67 | 1.67 | [6, 6, 8]
|
| 4325 | Mitigating Forgetting in Online Continual Learning via Contrasting Semantically Distinct Augmentations | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 4326 | Wasserstein Fair Autoencoders | 3.00 | 3.00 | 0.00 | [1, 5, 3]
|
| 4327 | Denoising Diffusion Error Correction Codes | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 4328 | Low-Rank Winograd Transformation for 3D Convolutional Neural Networks | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 4329 | Progressive Purification for Instance-Dependent Partial Label Learning | 5.50 | 5.50 | 0.00 | [6, 5, 8, 3]
|
| 4330 | Meta Knowledge Condensation for Federated Learning | 5.67 | 5.67 | 0.00 | [8, 6, 3]
|
| 4331 | Improved Fully Quantized Training via Rectifying Batch Normalization | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 4332 | Video-based 3D Object Detection with Learnable Object-Centric Global Optimization | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 4333 | Edge Wasserstein Distance Loss for Oriented Object Detection | 4.75 | 4.75 | 0.00 | [3, 5, 5, 6]
|
| 4334 | StyleGenes: Discrete and Efficient Latent Distributions for GANs | 4.75 | 4.75 | 0.00 | [8, 3, 3, 5]
|
| 4335 | Scratching Visual Transformer"s Back with Uniform Attention | 4.40 | 4.40 | 0.00 | [5, 3, 6, 5, 3]
|
| 4336 | Exploring Active 3D Object Detection from a Generalization Perspective | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 4337 | Masked Frequency Modeling for Self-Supervised Visual Pre-Training | 5.75 | 5.75 | 0.00 | [8, 5, 5, 5]
|
| 4338 | Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning | 6.20 | 6.20 | 0.00 | [6, 6, 8, 6, 5]
|
| 4339 | Lottery Aware Sparsity Hunting: Enabling Federated Learning on Resource-Limited Edge | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 4340 | Self-Organizing Pathway Expansion for Non-Exemplar Incremental Learning | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 4341 | Corruption Depth: Analysis of DNN depth for Misclassification | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 4342 | MixMIM: Mixed and Masked Image Modeling for Efficient Visual Representation Learning | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 4343 | Neuro-Symbolic Procedural Planning with Commonsense Prompting | 6.40 | 6.80 | 0.40 | [8, 5, 8, 5, 8]
|
| 4344 | ZERO: A Large-scale Chinese Cross-modal Benchmark with a New Vision-Language Framework | 4.75 | 4.75 | 0.00 | [8, 3, 3, 5]
|
| 4345 | Learning Object-Language Alignments for Open-Vocabulary Object Detection | 6.00 | 6.00 | 0.00 | [5, 6, 8, 5]
|
| 4346 | Phase transition for detecting a small community in a large network | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 4347 | On the Word Boundaries of Emergent Languages Based on Harris"s Articulation Scheme | 5.60 | 5.60 | 0.00 | [8, 5, 6, 3, 6]
|
| 4348 | Zipper: Decoupling the tradeoff Between Robustness and Accuracy | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 4349 | TempCLR: Temporal Alignment Representation with Contrastive Learning | 5.00 | 5.00 | 0.00 | [6, 6, 5, 3]
|
| 4350 | Generative Augmented Flow Networks | 6.75 | 7.00 | 0.25 | [8, 8, 6, 6]
|
| 4351 | Inferring Fluid Dynamics via Inverse Rendering | 6.00 | 6.00 | 0.00 | [5, 5, 8]
|
| 4352 | How Does Value Distribution in Distributional Reinforcement Learning Help Optimization? | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 4353 | Bort: Towards Explainable Neural Networks with Bounded Orthogonal Constraint | 6.33 | 6.67 | 0.33 | [8, 6, 6]
|
| 4354 | Coordinate and Generalize: A Unified Framework for Audio-Visual Zero-Shot Learning | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 4355 | Interpreting Distributional Reinforcement Learning: A Regularization Perspective | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 4356 | The Power of Regularization in Solving Extensive-Form Games | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 4357 | Neural Topic Modeling with Embedding Clustering Regularization | 5.00 | 5.00 | 0.00 | [6, 6, 5, 3]
|
| 4358 | Distributional Reinforcement Learning via Sinkhorn Iterations | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 4359 | Contextual Symbolic Policy For Meta-Reinforcement Learning | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 4360 | Do We Really Achieve Fairness with Explicit Sensitive Attributes? | 2.33 | 2.33 | 0.00 | [3, 3, 1]
|
| 4361 | MLPInit: Embarrassingly Simple GNN Training Acceleration with MLP Initialization | 5.00 | 5.00 | 0.00 | [3, 3, 6, 8]
|
| 4362 | SinGRAV: Learning a Generative Radiance Volume from a Single Natural Scene | 4.75 | 4.75 | 0.00 | [3, 8, 5, 3]
|
| 4363 | Progressive Compressed Auto-Encoder for Self-supervised Representation Learning | 5.33 | 5.83 | 0.50 | [5, 6, 6, 6, 6, 6]
|
| 4364 | ConBaT: Control Barrier Transformer for Safety-Critical Policy Learning | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 4365 | Robust Transfer Learning Based on Minimax Principle | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 4366 | Interpreting Neural Networks Through the Lens of Heat Flow | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 4367 | Efficient Surrogate Gradients for Training Spiking Neural Networks | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 4368 | DCE: Offline Reinforcement Learning With Double Conservative Estimates | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 4369 | The Trade-off between Universality and Label Efficiency of Representations from Contrastive Learning | 6.25 | 7.00 | 0.75 | [6, 8, 8, 6]
|
| 4370 | S-NeRF: Neural Radiance Fields for Street Views | 5.75 | 5.75 | 0.00 | [3, 8, 6, 6]
|
| 4371 | Generalized structure-aware missing view completion network for incomplete multi-view clustering | 7.50 | 7.50 | 0.00 | [8, 6, 8, 8]
|
| 4372 | Learning Visual Representation with Synthetic Images and Topologically-defined Labels | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 4373 | Cycle-consistent Masked AutoEncoder for Unsupervised Domain Generalization | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 4374 | CFlowNets: Continuous control with Generative Flow Networks | 5.50 | 6.00 | 0.50 | [6, 5, 5, 8]
|
| 4375 | Global Hardest Example Mining with Prototype-based Triplet Loss | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 4376 | Differentiable Gaussianization Layers for Inverse Problems Regularized by Deep Generative Models | 5.75 | 5.75 | 0.00 | [6, 6, 8, 3]
|
| 4377 | Extreme Masking for Learning Instance and Distributed Visual Representations | 4.25 | 4.25 | 0.00 | [1, 5, 8, 3]
|
| 4378 | Quality Matters: Embracing Quality Clues for Robust 3D Multi-Object Tracking | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 4379 | MGMA: Mesh Graph Masked Autoencoders for Self-supervised Learning on 3D Shape | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 4380 | DBQ-SSD: Dynamic Ball Query for Efficient 3D Object Detection | 5.25 | 5.25 | 0.00 | [6, 1, 6, 8]
|
| 4381 | Exploring Low-Rank Property in Multiple Instance Learning for Whole Slide Image Classification | 6.00 | 6.00 | 0.00 | [5, 5, 6, 8]
|
| 4382 | Evaluating and Inducing Personality in Pre-trained Language Models | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 4383 | MLM with Global Co-occurrence | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 4384 | Node Classification Beyond Homophily: Towards a General Solution | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 4385 | Leveraging Hierarchical Structure for Multi-Domain Active Learning with Theoretical Guarantees | 4.25 | 4.25 | 0.00 | [3, 5, 3, 6]
|
| 4386 | Causal Balancing for Domain Generalization | 6.50 | 6.50 | 0.00 | [8, 6, 6, 6]
|
| 4387 | Elastic Aggregation for Federated Optimization | 4.75 | 4.75 | 0.00 | [5, 5, 3, 6]
|
| 4388 | Decouple Graph Neural Networks: Train Multiple Simple GNNs Simultaneously Instead of One | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 4389 | Reinforced Sample Reweighting Policy for Semi-supervised Learning | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 4390 | Neural Radiance Fields with Geometric Consistency for Few-Shot Novel View Synthesis | 5.50 | 6.00 | 0.50 | [8, 5, 3, 8]
|
| 4391 | Towards Addressing Label Skews in One-shot Federated Learning | 5.67 | 6.00 | 0.33 | [6, 6, 6]
|
| 4392 | Breaking Correlation Shift via Conditional Invariant Regularizer | 4.00 | 4.75 | 0.75 | [3, 3, 5, 8]
|
| 4393 | CROM: Continuous Reduced-Order Modeling of PDEs Using Implicit Neural Representations | 7.60 | 7.60 | 0.00 | [8, 8, 8, 6, 8]
|
| 4394 | Relaxed Combinatorial Optimization Networks with Self-Supervision: Theoretical and Empirical Notes on the Cardinality-Constrained Case | 5.67 | 6.00 | 0.33 | [6, 6, 6]
|
| 4395 | Block and Subword-Scaling Floating-Point (BSFP) : An Efficient Non-Uniform Quantization For Low Precision Inference | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 4396 | Exploring The Capacity Mismatch Problem in Knowledge Distillation from the View of Soft Labels | 4.60 | 4.60 | 0.00 | [5, 5, 5, 3, 5]
|
| 4397 | Rethinking the Effect of Data Augmentation in Adversarial Contrastive Learning | 5.67 | 6.67 | 1.00 | [8, 6, 6]
|
| 4398 | FeatER: An Efficient Network for Human Reconstruction Feature map-based TransformER | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 4399 | Pareto Automatic Multi-Task Graph Representation Learning | 5.25 | 5.25 | 0.00 | [3, 5, 8, 5]
|
| 4400 | Semi-supervised Community Detection via Structural Similarity Metrics | 5.50 | 6.50 | 1.00 | [6, 6, 6, 8]
|
| 4401 | DDM$^2$: Self-Supervised Diffusion MRI Denoising with Generative Diffusion Models | 5.25 | 5.25 | 0.00 | [8, 6, 6, 1]
|
| 4402 | Multivariate Time-series Imputation with Disentangled Temporal Representations | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 4403 | Knowledge-driven Scene Priors for Semantic Audio-Visual Embodied Navigation | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 4404 | Promoting Semantic Connectivity: Dual Nearest Neighbors Contrastive Learning for Unsupervised Domain Generalization | 5.00 | 5.00 | 0.00 | [6, 6, 5, 3]
|
| 4405 | Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language | 6.75 | 6.75 | 0.00 | [8, 5, 6, 8]
|
| 4406 | CAST: Concurrent Recognition and Segmentation with Adaptive Segment Tokens | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 4407 | Improving the Latent Space of Image Style Transfer | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 4408 | Multi-lingual Evaluation of Code Generation Models | 6.50 | 7.00 | 0.50 | [8, 6, 6, 8]
|
| 4409 | GRACE-C: Generalized Rate Agnostic Causal Estimation via Constraints | 6.20 | 6.20 | 0.00 | [6, 6, 8, 6, 5]
|
| 4410 | How Powerful is Implicit Denoising in Graph Neural Networks | 4.00 | 4.50 | 0.50 | [6, 3, 3, 6]
|
| 4411 | Unified Detoxifying and Debiasing in Language Generation via Inference-time Adaptive Optimization | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 4412 | Distribution Aware Metrics for Conditional Natural Language Generation | 5.33 | 5.67 | 0.33 | [6, 6, 5]
|
| 4413 | GOAT: A Global Transformer on Large-scale Graphs | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 4414 | An Empirical Study on Anomaly detection Using Density Based and Representative Based Clustering algorithms | 2.00 | 2.00 | 0.00 | [1, 1, 3, 3]
|
| 4415 | Recommender Transformers with Behavior Pathways | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 4416 | Outlier Robust Adversarial Training | 5.25 | 5.25 | 0.00 | [5, 3, 5, 8]
|
| 4417 | Towards Discovering Neural Architectures from Scratch | 4.20 | 4.20 | 0.00 | [3, 3, 6, 3, 6]
|
| 4418 | Equiformer: Equivariant Graph Attention Transformer for 3D Atomistic Graphs | 6.00 | 6.25 | 0.25 | [8, 6, 6, 5]
|
| 4419 | Multiple Instance Learning via Iterative Self-Paced Supervised Contrastive Learning | 4.75 | 4.75 | 0.00 | [5, 6, 3, 5]
|
| 4420 | Automating Nearest Neighbor Search Configuration with Constrained Optimization | 6.75 | 6.75 | 0.00 | [5, 6, 8, 8]
|
| 4421 | A prototype-oriented clustering for domain shift with source privacy | 4.67 | 4.67 | 0.00 | [3, 6, 5]
|
| 4422 | On the Effectiveness of Adapting Pre-trained Transformer Models via Adversarial Noise | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 4423 | Sparse Tokens for Dense Prediction - The Medical Image Segmentation Case | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 4424 | Truncated Diffusion Probabilistic Models and Diffusion-based Adversarial Auto-Encoders | 6.75 | 6.75 | 0.00 | [6, 5, 8, 8]
|
| 4425 | NTK-SAP: Improving neural network pruning by aligning training dynamics | 5.25 | 5.25 | 0.00 | [6, 6, 3, 6]
|
| 4426 | One Ring to Bring Them All: Model Adaptation under Domain and Category Shift | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 4427 | Towards Equivariant Graph Contrastive Learning via Cross-Graph Augmentation | 5.00 | 5.00 | 0.00 | [3, 6, 8, 3]
|
| 4428 | Configuring Mixed-Integer Linear Programming Solvers with Deep Metric Learning | 4.25 | 4.25 | 0.00 | [3, 3, 3, 8]
|
| 4429 | Effective Self-supervised Pre-training on Low-compute networks without Distillation | 5.75 | 6.50 | 0.75 | [8, 5, 5, 8]
|
| 4430 | Graph Neural Bandits | 4.25 | 4.25 | 0.00 | [3, 5, 6, 3]
|
| 4431 | CoRTX: Contrastive Framework for Real-time Explanation | 5.75 | 5.75 | 0.00 | [5, 5, 5, 8]
|
| 4432 | MPCFORMER: FAST, PERFORMANT AND PRIVATE TRANSFORMER INFERENCE WITH MPC | 6.25 | 6.75 | 0.50 | [5, 6, 8, 8]
|
| 4433 | Discovering Distinctive ``Semantics"" in Super-Resolution Networks | 5.25 | 5.25 | 0.00 | [5, 3, 8, 5]
|
| 4434 | Networks are Slacking Off: Understanding Generalization Problem in Image Deraining | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 4435 | Disparate Impact in Differential Privacy from Gradient Misalignment | 6.25 | 6.50 | 0.25 | [8, 6, 6, 6]
|
| 4436 | IDP: Iterative Differentiable Pruning based on Attention for Deep Neural Networks | 6.00 | 6.00 | 0.00 | [5, 6, 5, 8]
|
| 4437 | Language-Guided Artistic Style Transfer Using the Latent Space of DALL-E | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 4438 | FADE: Enabling Large-Scale Federated Adversarial Training on Resource-Constrained Edge Devices | 4.67 | 5.33 | 0.67 | [5, 6, 5]
|
| 4439 | Temporal Relevance Analysis for Video Action Models | 4.67 | 4.67 | 0.00 | [6, 5, 3]
|
| 4440 | HNeRV: A Hybrid Neural Representation for Videos | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 4441 | DeepPipe: Deep, Modular and Extendable Representations of Machine Learning Pipelines | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 4442 | OTOv2: Automatic, Generic, User-Friendly | 6.00 | 6.00 | 0.00 | [8, 5, 5]
|
| 4443 | TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second | 4.75 | 5.50 | 0.75 | [8, 5, 3, 6]
|
| 4444 | On the Importance of Architectures and Hyperparameters for Fairness in Face Recognition | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 4445 | Evaluating natural language processing models with generalization metrics that do not need access to any training or testing data | 5.00 | 5.00 | 0.00 | [3, 5, 6, 6]
|
| 4446 | Human Motion Diffusion Model | 7.00 | 7.00 | 0.00 | [6, 8, 8, 6]
|
| 4447 | Federated Learning in Non-IID Settings Aided by Differentially Private Synthetic Data | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 4448 | Structure-based Drug Design with Equivariant Diffusion Models | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 4449 | Deep reinforced active learning for multi-class image classification | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 4450 | HeatDETR: Hardware-Efficient DETR with Device-Adaptive Thinning | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 4451 | ChemSpacE: Interpretable and Interactive Chemical Space Exploration | 4.00 | 4.00 | 0.00 | [3, 5, 3, 5]
|
| 4452 | A UNIFIED VIEW OF FINDING AND TRANSFORMING WINNING LOTTERY TICKETS | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 4453 | The Effects of Nonlinearity on Approximation Capacity of Recurrent Neural Networks | 5.00 | 5.00 | 0.00 | [6, 1, 8, 5]
|
| 4454 | Friends to Help: Saving Federated Learning from Client Dropout | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 4455 | Filter-Recovery Network for Multi-Speaker Audio-Visual Speech Separation | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 4456 | Probing into the Fine-grained Manifestation in Multi-modal Image Synthesis | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 4457 | Can discrete information extraction prompts generalize across language models? | 6.75 | 6.75 | 0.00 | [5, 6, 8, 8]
|
| 4458 | Deep Power Laws for Hyperparameter Optimization | 4.25 | 4.25 | 0.00 | [5, 3, 6, 3]
|
| 4459 | A view of mini-batch SGD via generating functions: conditions of convergence, phase transitions, benefit from negative momenta. | 6.33 | 6.33 | 0.00 | [6, 5, 8]
|
| 4460 | Curiosity-Driven Unsupervised Data Collection for Offline Reinforcement Learning | 5.00 | 5.00 | 0.00 | [3, 6, 5, 6]
|
| 4461 | Understanding and Bridging the Modality Gap for Speech Translation | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 4462 | Big Learning: A Universal Machine Learning Paradigm? | 3.00 | 3.00 | 0.00 | [3, 1, 5]
|
| 4463 | Spike Calibration: Bridging the Gap between ANNs and SNNs in ANN-SNN Conversion | 5.00 | 5.50 | 0.50 | [1, 8, 8, 5]
|
| 4464 | MIA: A Framework for Certified Robustness of Time-Series Classification and Forecasting Against Temporally-Localized Perturbations | 5.00 | 5.33 | 0.33 | [5, 5, 6]
|
| 4465 | Sparse Q-Learning: Offline Reinforcement Learning with Implicit Value Regularization | 6.00 | 6.33 | 0.33 | [8, 5, 6]
|
| 4466 | Eliminating Catastrophic Overfitting Via Abnormal Adversarial Examples Regularization | 4.00 | 4.25 | 0.25 | [6, 5, 3, 3]
|
| 4467 | TIB: Detecting Unknown Objects via Two-Stream Information Bottleneck | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 4468 | Revisiting Residual Networks for Adversarial Robustness | 4.60 | 4.60 | 0.00 | [5, 5, 5, 3, 5]
|
| 4469 | Win: Weight-Decay-Integrated Nesterov Acceleration for Adaptive Gradient Algorithms | 7.33 | 8.00 | 0.67 | [8, 8, 8]
|
| 4470 | A Quasi-Bayesian Nonparametric Density Estimator via Autoregressive Predictive Updates | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 4471 | Towards Understanding Convergence and Generalization of AdamW | 4.67 | 4.67 | 0.00 | [6, 3, 5]
|
| 4472 | GeoVeX: Geospatial Vectors with Hexagonal Convolutional Autoencoders | 4.25 | 4.25 | 0.00 | [3, 5, 6, 3]
|
| 4473 | Prompt-Matched Semantic Segmentation | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 4474 | Split and Merge Proxy: pre-training protein-protein contact prediction by mining rich information from monomer data | 5.00 | 5.50 | 0.50 | [5, 6, 5, 6]
|
| 4475 | ESD: Expected Squared Difference as a Tuning-Free Trainable Calibration Measure | 6.50 | 6.50 | 0.00 | [6, 6, 6, 8]
|
| 4476 | Interactive Portrait Harmonization | 6.25 | 6.25 | 0.00 | [6, 6, 5, 8]
|
| 4477 | Self-Distillation for Further Pre-training of Transformers | 6.80 | 6.80 | 0.00 | [8, 6, 6, 8, 6]
|
| 4478 | Iterative Relaxing Gradient Projection for Continual Learning | 4.33 | 5.67 | 1.33 | [5, 6, 6]
|
| 4479 | Adversarial Counterfactual Environment Model Learning | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 4480 | Admeta: A Novel Double Exponential Moving Average to Adaptive and Non-adaptive Momentum Optimizers with Bidirectional Looking | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 4481 | Learning from Interval-valued Data | 4.67 | 4.67 | 0.00 | [8, 3, 3]
|
| 4482 | Feature Synchronization in Backdoor Attacks | 4.25 | 4.25 | 0.00 | [5, 3, 3, 6]
|
| 4483 | Efficient Hyperdimensional Computing | 4.67 | 5.67 | 1.00 | [6, 6, 5]
|
| 4484 | Contextual Convolutional Networks | 6.75 | 7.00 | 0.25 | [6, 8, 6, 8]
|
| 4485 | Factor Learning Portfolio Optimization Informed by Continuous-Time Finance Models | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 4486 | An Incremental Learning Approach for Sustainable Regional Isolation and Integration | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 4487 | GraphPNAS: Learning Distribution of Good Neural Architectures via Deep Graph Generative Models | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 4488 | Private GANs, Revisited | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 4489 | Hidden Poison: Machine unlearning enables camouflaged poisoning attacks | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 4490 | FEW-SHOT NODE PROMPT TUNING | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 4491 | Statistical Inference for Fisher Market Equilibrium | 6.00 | 7.33 | 1.33 | [8, 6, 8]
|
| 4492 | Auxiliary task discovery through generate and test | 4.67 | 6.00 | 1.33 | [8, 5, 5]
|
| 4493 | MMTSA: Multi-Modal Temporal Segment Attention Network for Efficient Human Activity Recognition | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 4494 | Scenario-based Question Answering with Interacting Contextual Properties | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 4495 | Easy Differentially Private Linear Regression | 6.75 | 6.75 | 0.00 | [5, 8, 8, 6]
|
| 4496 | PointDP: Diffusion-driven Purification against 3D Adversarial Point Clouds | 5.00 | 5.00 | 0.00 | [6, 6, 5, 3]
|
| 4497 | Deep Physics-based Deformable Models for Efficient Shape Abstractions | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 4498 | Benchmarking and Improving Robustness of 3D Point Cloud Recognition against Common Corruptions | 4.83 | 4.83 | 0.00 | [3, 3, 5, 8, 5, 5]
|
| 4499 | Visual Recognition with Deep Nearest Centroids | 6.00 | 6.00 | 0.00 | [5, 8, 6, 5]
|
| 4500 | Closing the Gap Between SVRG and TD-SVRG with Gradient Splitting | 4.00 | 4.00 | 0.00 | [5, 5, 1, 5]
|
| 4501 | Rethinking Backdoor Data Poisoning Attacks in the Context of Semi-Supervised Learning | 2.33 | 2.33 | 0.00 | [3, 3, 1]
|
| 4502 | Categorial Grammar Induction as a Compositionality Measure for Emergent Languages in Signaling Games | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 4503 | LPT: Long-tailed Prompt Tuning for Image Classification | 5.50 | 5.50 | 0.00 | [5, 6, 5, 6]
|
| 4504 | Interpretable Out-of-Distribution Detection using Pattern Identification | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 4505 | TopoZero: Digging into Topology Alignment on Zero-Shot Learning | 5.50 | 5.50 | 0.00 | [5, 8, 6, 3]
|
| 4506 | Digging into Backbone Design on Face Detection | 6.50 | 6.50 | 0.00 | [6, 6, 6, 8]
|
| 4507 | Towards Stable Test-time Adaptation in Dynamic Wild World | 6.75 | 6.75 | 0.00 | [3, 8, 8, 8]
|
| 4508 | Exploring Over-smoothing in Graph Attention Networks from the Markov Chain Perspective | 2.50 | 2.50 | 0.00 | [3, 1, 3, 3]
|
| 4509 | Sorted eigenvalue comparison $d_{\mathsf{Eig}}$: A simple alternative to $d_{\mathsf{FID}}$ | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 4510 | Towards Smooth Video Composition | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 4511 | Deep Dynamic AutoEncoder for Vision BERT Pretraining | 5.40 | 5.60 | 0.20 | [6, 5, 6, 6, 5]
|
| 4512 | Continuous PDE Dynamics Forecasting with Implicit Neural Representations | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 4513 | Adversarial Collaborative Learning on Non-IID Features | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 4514 | DiffMimic: Efficient Motion Mimicking with Differentiable Physics | 5.40 | 5.40 | 0.00 | [6, 6, 6, 6, 3]
|
| 4515 | Towards Inferential Reproducibility of Machine Learning Research | 6.00 | 6.00 | 0.00 | [5, 5, 8]
|
| 4516 | Knowledge Distillation based Degradation Estimation for Blind Super-Resolution | 5.50 | 5.75 | 0.25 | [6, 6, 6, 5]
|
| 4517 | Very Large Scale Multi-Agent Reinforcement Learning with Graph Attention Mean Field | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 4518 | Graph Contrastive Learning for Skeleton-based Action Recognition | 6.00 | 6.00 | 0.00 | [8, 3, 8, 5]
|
| 4519 | Explicit Box Detection Unifies End-to-End Multi-Person Pose Estimation | 6.00 | 6.20 | 0.20 | [5, 6, 6, 6, 8]
|
| 4520 | Expected Perturbation Scores for Adversarial Detection | 7.00 | 7.00 | 0.00 | [5, 8, 8]
|
| 4521 | Look Back When Surprised: Stabilizing Reverse Experience Replay for Neural Approximation | 4.25 | 4.25 | 0.00 | [1, 8, 5, 3]
|
| 4522 | BQ-NCO: Bisimulation Quotienting for Generalizable Neural Combinatorial Optimization | 5.25 | 5.25 | 0.00 | [8, 5, 5, 3]
|
| 4523 | CoGANs: Collaborative Generative Adversarial Networks | 2.33 | 2.33 | 0.00 | [1, 3, 3]
|
| 4524 | Multiscale Neural Operator: Learning Fast and Grid-independent PDE Solvers | 4.25 | 4.25 | 0.00 | [3, 5, 6, 3]
|
| 4525 | NASiam: Efficient Representation Learning using Neural Architecture Search for Siamese Networks | 3.00 | 3.00 | 0.00 | [5, 3, 3, 1]
|
| 4526 | Out-of-distribution Detection with Diffusion-based Neighborhood | 3.50 | 3.50 | 0.00 | [5, 3, 3, 3]
|
| 4527 | A Massively Parallel Benchmark for Safe Dexterous Manipulation | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 4528 | Never Revisit: Continuous Exploration in Multi-Agent Reinforcement Learning | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 4529 | Do Not Train It: A Linear Neural Architecture Search of Graph Neural Networks | 5.40 | 5.40 | 0.00 | [5, 6, 6, 5, 5]
|
| 4530 | Rethinking the Explanation of Graph Neural Network via Non-parametric Subgraph Matching | 4.25 | 4.25 | 0.00 | [3, 3, 8, 3]
|
| 4531 | Spikformer: When Spiking Neural Network Meets Transformer | 6.00 | 6.00 | 0.00 | [6, 3, 10, 5]
|
| 4532 | Representation Mutual Learning for End-to-End Weakly-Supervised Semantic Segmentation | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 4533 | DeSCo: Towards Scalable Deep Subgraph Counting | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 4534 | On a Built-in Conflict between Deep Learning and Systematic Generalization | 3.00 | 3.00 | 0.00 | [3, 3, 1, 5]
|
| 4535 | SepRep-Net: Multi-source Free Domain Adaptation via Model Separation and Reparameterization | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 4536 | Consistent and Truthful Interpretation with Fourier Analysis | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 4537 | D2Match: Leveraging Deep Learning and Degeneracy for Subgraph Matching | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 4538 | Multimodal Analogical Reasoning over Knowledge Graphs | 6.00 | 6.00 | 0.00 | [8, 5, 5]
|
| 4539 | QFuture: Learning Future Expectations in Multi-Agent Reinforcement Learning | 4.60 | 4.60 | 0.00 | [5, 3, 6, 3, 6]
|
| 4540 | MMCAP: LEARNING TO BROAD-SIGHT NEURAL NETWORKS BY CLASS ATTENTION POOLING | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 4541 | GAIN: Enhancing Byzantine Robustness in Federated Learning with Gradient Decomposition | 5.75 | 6.25 | 0.50 | [8, 3, 6, 8]
|
| 4542 | Temporary feature collapse phenomenon in early learning of MLPs | 5.50 | 5.50 | 0.00 | [3, 5, 8, 6]
|
| 4543 | MECTA: Memory-Economic Continual Test-Time Model Adaptation | 7.25 | 7.25 | 0.00 | [5, 8, 8, 8]
|
| 4544 | MocoSFL: enabling cross-client collaborative self-supervised learning | 7.25 | 7.25 | 0.00 | [5, 8, 8, 8]
|
| 4545 | Block-level Stiffness Analysis of Residual Networks | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 4546 | Q-Match: Self-Supervised Learning For Tabular Data by Matching Distributions Induced by a Queue | 4.25 | 4.25 | 0.00 | [5, 6, 3, 3]
|
| 4547 | Supervised Contrastive Regression | 5.00 | 5.00 | 0.00 | [3, 6, 5, 6]
|
| 4548 | SELF-SUPERVISED PRETRAINING FOR DIFFERENTIALLY PRIVATE LEARNING | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 4549 | Explainable Artificial Intelligence: Reaping the Fruits of Decision Trees | 3.00 | 3.00 | 0.00 | [3, 3, 1, 5]
|
| 4550 | Meta-Evolve: Continuous Robot Evolution for One-to-many Policy Transfer | 5.50 | 5.50 | 0.00 | [3, 6, 5, 8]
|
| 4551 | Interpretability with full complexity by constraining feature information | 4.75 | 5.00 | 0.25 | [5, 3, 6, 6]
|
| 4552 | Revisiting Group Robustness: Class-specific Scaling is All You Need | 4.50 | 4.50 | 0.00 | [6, 6, 3, 3]
|
| 4553 | Provable Benefits of Representational Transfer in Reinforcement Learning | 5.00 | 5.00 | 0.00 | [6, 3, 6]
|
| 4554 | Set Discrimination Contrastive Learning | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 4555 | What shapes the loss landscape of self supervised learning? | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 4556 | Hard Regularization to Prevent Collapse in Online Deep Clustering without Data Augmentation | 3.00 | 3.00 | 0.00 | [5, 1, 3, 3]
|
| 4557 | Learning Lightweight Object Detectors via Progressive Knowledge Distillation | 5.50 | 6.20 | 0.70 | [5, 8, 5, 5, 8]
|
| 4558 | Topologically faithful image segmentation via induced matching of persistence barcodes | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 4559 | Generalizability of Adversarial Robustness Under Distribution Shifts | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 4560 | Uncertainty-Driven Active Vision for Implicit Scene Reconstruction | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 4561 | No Reason for No Supervision: Improved Generalization in Supervised Models | 5.75 | 6.25 | 0.50 | [6, 6, 5, 8]
|
| 4562 | Linear Convergence of Natural Policy Gradient Methods with Log-Linear Policies | 5.33 | 6.00 | 0.67 | [8, 5, 5, 6]
|
| 4563 | Active Learning with Controllable Augmentation Induced Acquisition | 5.33 | 5.33 | 0.00 | [3, 8, 5]
|
| 4564 | Learning Axis-Aligned Decision Trees with Gradient Descent | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 4565 | DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 4566 | A Class-Aware Representation Refinement Framework for Graph Classification | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 4567 | EVA3D: Compositional 3D Human Generation from 2D Image Collections | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 4568 | Spurious Local Minima Provably Exist for Deep Convolutional Neural Networks | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 4569 | Nearly Minimax Optimal Offline Reinforcement Learning with Linear Function Approximation: Single-Agent MDP and Markov Game | 5.33 | 5.67 | 0.33 | [6, 5, 6]
|
| 4570 | Semi-Supervised Semantic Segmentation via Boosting Uncertainty on Unlabeled Data | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 4571 | Clustering Structure Identification With Ordering Graph | 5.75 | 6.25 | 0.50 | [6, 6, 5, 8]
|
| 4572 | Benchmarking Deformable Object Manipulation with Differentiable Physics | 8.00 | 8.00 | 0.00 | [8, 8, 8]
|
| 4573 | Voxurf: Voxel-based Efficient and Accurate Neural Surface Reconstruction | 6.25 | 6.25 | 0.00 | [6, 8, 6, 5]
|
| 4574 | Graph Contrastive Learning with Personalized Augmentation | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 4575 | Tree Structure LSTM for Chinese Named Entity Recognition | 2.00 | 2.00 | 0.00 | [3, 3, 1, 1]
|
| 4576 | Unfixed Bias Iterator: A New Iterative Format | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 4577 | Conditional Positional Encodings for Vision Transformers | 6.00 | 6.00 | 0.00 | [5, 5, 8, 6]
|
| 4578 | Variational Reparametrized Policy Learning with Differentiable Physics | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 4579 | A Fairness Analysis on Differentially Private Aggregation of Teacher Ensembles | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 4580 | GENERALIZED MATRIX LOCAL LOW RANK REPRESENTATION BY RANDOM PROJECTION AND SUBMATRIX PROPAGATION | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 4581 | Stable, Efficient, and Flexible Monotone Operator Implicit Graph Neural Networks | 4.00 | 4.25 | 0.25 | [5, 3, 3, 6]
|
| 4582 | ManiSkill2: A Unified Benchmark for Generalizable Manipulation Skills | 6.33 | 6.67 | 0.33 | [6, 8, 6]
|
| 4583 | LSAP: Rethinking Inversion Fidelity, Perception and Editability in GAN Latent Space | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 4584 | Neural Sorting Networks with Error-Free Differentiable Swap Functions | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 4585 | Twofer: Tackling Continual Domain Shift with Simultaneous Domain Generalization and Adaptation | 5.50 | 6.00 | 0.50 | [8, 3, 5, 8]
|
| 4586 | ModelAngelo: Automated Model Building for Cryo-EM Maps | 5.40 | 5.80 | 0.40 | [5, 8, 5, 5, 6]
|
| 4587 | Stealing and Defending Transformer-based Encoders | 4.75 | 4.75 | 0.00 | [5, 5, 6, 3]
|
| 4588 | On the Lower Bound of Minimizing Polyak-Łojasiewicz functions | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 4589 | VectorMapNet: End-to-end Vectorized HD Map Learning | 5.50 | 5.50 | 0.00 | [6, 5, 8, 3]
|
| 4590 | An information-theoretic approach to unsupervised keypoint representation learning | 5.00 | 5.00 | 0.00 | [6, 3, 5, 6]
|
| 4591 | Distilling Cognitive Backdoor within an Image | 5.25 | 5.50 | 0.25 | [5, 3, 6, 8]
|
| 4592 | Formulating and Proving the Trend of DNNs Learning Simple Concepts | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 4593 | Curriculum Reinforcement Learning via Morphology-Environment Co-Evolution | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 4594 | Domain Generalization with Small Data | 5.50 | 6.00 | 0.50 | [6, 5, 5, 8]
|
| 4595 | 3D generation on ImageNet | 5.25 | 5.75 | 0.50 | [6, 8, 3, 6]
|
| 4596 | Revocable Deep Reinforcement Learning with Affinity Regularization for Outlier-Robust Graph Matching | 6.33 | 6.33 | 0.00 | [5, 6, 8]
|
| 4597 | Hierarchical Prompting Improves Visual Recognition On Accuracy, Data Efficiency and Explainability | 5.50 | 5.50 | 0.00 | [5, 5, 6, 6]
|
| 4598 | Convergence of the mini-batch SIHT algorithm | 1.67 | 1.67 | 0.00 | [3, 1, 1]
|
| 4599 | Decomposing Texture and Semantics for Out-of-distribution Detection | 5.50 | 5.50 | 0.00 | [6, 5, 5, 6]
|
| 4600 | Selective Classification Via Neural Network Training Dynamics | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 4601 | Rethinking the Expressive Power of GNNs via Graph Biconnectivity | 8.67 | 8.67 | 0.00 | [8, 8, 10]
|
| 4602 | One Transformer Can Understand Both 2D & 3D Molecular Data | 5.50 | 6.25 | 0.75 | [6, 5, 8, 6]
|
| 4603 | Hyperbolic Binary Neural Network | 3.75 | 3.75 | 0.00 | [3, 5, 1, 6]
|
| 4604 | Generating Diverse Cooperative Agents by Learning Incompatible Policies | 8.00 | 8.00 | 0.00 | [8, 8, 8, 8]
|
| 4605 | Mind the Gap: Offline Policy Optimizaiton for Imperfect Rewards | 5.33 | 5.33 | 0.00 | [3, 5, 8]
|
| 4606 | Time Series are Images: Vision Transformer for Irregularly Sampled Time Series | 5.33 | 5.33 | 0.00 | [3, 5, 8]
|
| 4607 | Gamma Sampling: Fine-grained Controlling Language Models without Training | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 4608 | Token-Label Alignment for Vision Transformers | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 4609 | 3D-Scene-Entities: Using Phrase-to-3D-Object Correspondences for Richer Visio-Linguistic Models in 3D Scenes | 3.50 | 3.00 | -0.50 | [3, 3, 3, 3]
|
| 4610 | Label Distribution Learning via Implicit Distribution Representation | 6.00 | 5.80 | -0.20 | [5, 5, 6, 5, 8]
|
| 4611 | MultiWave: Multiresolution Deep Architectures through Wavelet Decomposition for Multivariate Timeseries Forecasting and Prediction | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 4612 | Learning to Compose Soft Prompts for Compositional Zero-Shot Learning | 6.00 | 6.00 | 0.00 | [5, 5, 6, 8]
|
| 4613 | SQA3D: Situated Question Answering in 3D Scenes | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 4614 | The Benefits of Model-Based Generalization in Reinforcement Learning | 6.00 | 6.00 | 0.00 | [8, 6, 5, 5]
|
| 4615 | Revisiting Higher-Order Gradient Methods for Multi-Agent Reinforcement Learning | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 4616 | SWORD: Demystify the Secrets of Open-world Instance Recognition | 4.00 | 4.25 | 0.25 | [5, 3, 3, 6]
|
| 4617 | Efficient Covariance Estimation for Sparsified Functional Data | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 4618 | Sparse Mixture-of-Experts are Domain Generalizable Learners | 6.50 | 6.50 | 0.00 | [5, 8, 5, 8]
|
| 4619 | Structure-Sensitive Graph Dictionary Embedding for Graph Classification | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 4620 | FlexPose: Pose Distribution Adaptation with Few-shot Guidance | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 4621 | PEER: A Collaborative Language Model | 7.50 | 7.50 | 0.00 | [8, 8, 8, 6]
|
| 4622 | Guide Detectors in Pixel Space with Global Positioning and Abductive Matching | 5.00 | 5.00 | 0.00 | [5, 6, 8, 1]
|
| 4623 | A simple but effective and efficient global modeling paradigm for image restoration | 5.00 | 5.00 | 0.00 | [3, 3, 8, 6]
|
| 4624 | Contrastive Continuity on Augmentation Stability Rehearsal for Continual Self-Supervised Learning | 4.50 | 4.50 | 0.00 | [6, 3, 3, 6]
|
| 4625 | Empowering Networks With Scale and Rotation Equivariance Using A Similarity Convolution | 7.50 | 7.50 | 0.00 | [8, 6, 8, 8]
|
| 4626 | Uncertainty Calibration via Knowledge Flow under Long-tailed Distribution | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 4627 | $1\times1$ Convolution is All You Need for Image Super-Resolution | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 4628 | ISS: Image as Stepping Stone for Text-Guided 3D Shape Generation | 5.00 | 5.00 | 0.00 | [5, 3, 6, 6]
|
| 4629 | Robust and Controllable Object-Centric Learning through Energy-based Models | 5.75 | 5.75 | 0.00 | [6, 8, 6, 3]
|
| 4630 | Learning Antidote Data to Individual Unfairness | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 4631 | Does Continual Learning Equally Forget All Parameters? | 4.75 | 4.75 | 0.00 | [6, 6, 1, 6]
|
| 4632 | Voting from Nearest Tasks: Meta-Vote Pruning of Pretrained Models for Downstream Tasks | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 4633 | STREET: A MULTI-TASK STRUCTURED REASONING AND EXPLANATION BENCHMARK | 6.50 | 6.50 | 0.00 | [5, 8, 5, 8]
|
| 4634 | Topology-aware robust optimization | 4.40 | 4.60 | 0.20 | [6, 3, 6, 5, 3]
|
| 4635 | Exploring Neural Network Representational Similarity using Filter Subspaces | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 4636 | A Close Look at Token Mixer: From Attention to Convolution | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 4637 | EAGLE: Large-scale Learning of Turbulent Fluid Dynamics with Mesh Transformers | 4.75 | 4.75 | 0.00 | [6, 5, 5, 3]
|
| 4638 | Momentum in Momentum for Adaptive Optimization | 4.25 | 4.25 | 0.00 | [3, 3, 3, 8]
|
| 4639 | Limitless Stability for Graph Convolutional Networks | 5.75 | 5.75 | 0.00 | [6, 6, 3, 8]
|
| 4640 | MiSAL: Active Learning for Every Budget | 5.00 | 5.00 | 0.00 | [3, 6, 3, 8]
|
| 4641 | SOM-CPC: Unsupervised Contrastive Learning with Self-Organizing Maps for Structured Representations of High-Rate Time Series | 5.00 | 5.00 | 0.00 | [6, 6, 3]
|
| 4642 | DIVISION: Memory Efficient Training via Dual Activation Precision | 5.25 | 5.25 | 0.00 | [5, 8, 5, 3]
|
| 4643 | Lossless Dataset Compression Via Dataset Quantization | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 4644 | CLIP-PAE: Projection-Augmentation Embedding to Extract Relevant Features for a Disentangled, Interpretable and Controllable Text-Guided Image Manipulation | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 4645 | NICO++: Towards Better Benchmarking for Domain Generalization | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 4646 | Gradient Norm Regularizer Seeks Flat Minima and Improves Generalization | 4.25 | 4.25 | 0.00 | [6, 5, 3, 3]
|
| 4647 | Token Merging: Your ViT But Faster | 7.50 | 7.50 | 0.00 | [8, 8, 8, 6]
|
| 4648 | TiDAL: Learning Training Dynamics for Active Learning | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 4649 | CompletionFormer: Depth Completion with Convolutions and Vision Transformers | 4.00 | 4.00 | 0.00 | [6, 6, 3, 1]
|
| 4650 | Provable Adaptivity in Adam | 5.25 | 5.25 | 0.00 | [8, 5, 3, 5]
|
| 4651 | MS3: A Multimodal Supervised Pretrained Model for Semantic Segmentation | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 4652 | An Analysis of Information Bottlenecks | 5.50 | 5.50 | 0.00 | [5, 3, 6, 8]
|
| 4653 | De Novo Molecular Generation via Connection-aware Motif Mining | 5.25 | 5.50 | 0.25 | [8, 5, 3, 6]
|
| 4654 | Multiplane NeRF-Supervised Disentanglement of Depth and Camera Pose from Videos | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 4655 | Shared Knowledge Lifelong Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 4656 | GANet: Graph-Aware Network for Point Cloud Completion with Displacement-Aware Point Augmentor | 6.33 | 6.33 | 0.00 | [3, 6, 10]
|
| 4657 | Multiple output samples for each input in a single-output Gaussian process | 2.50 | 2.50 | 0.00 | [1, 3, 3, 3]
|
| 4658 | Demystifying the Optimization and Generalization of Deep PAC-Bayesian Learning | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 4659 | WeightRelay: Efficient Heterogenous Federated Learning on Time Series | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 4660 | Revisiting the Entropy Semiring for Neural Speech Recognition | 8.50 | 8.50 | 0.00 | [10, 6, 8, 10]
|
| 4661 | Rethinking skip connection model as a learnable Markov chain | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 4662 | Activation Function: Absolute Function,One Function Behaves more Individualized | 1.00 | 1.00 | 0.00 | [1, 1, 1, 1]
|
| 4663 | ImageNet-E: Benchmarking Neural Network Robustness via Attribute Editing | 4.50 | 5.25 | 0.75 | [6, 5, 5, 5]
|
| 4664 | Measuring axiomatic identifiability of counterfactual image models | 7.33 | 7.33 | 0.00 | [6, 8, 8]
|
| 4665 | Alternating Differentiation for Optimization Layers | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 4666 | Cross-Domain Autonomous Driving Perception using Contrastive Appearance Adaptation | 4.75 | 4.75 | 0.00 | [6, 5, 3, 5]
|
| 4667 | Out-of-distribution Detection with Implicit Outlier Transformation | 6.33 | 6.33 | 0.00 | [8, 5, 6]
|
| 4668 | Parameter Averaging for Feature Ranking | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 4669 | Gradient Estimation for Unseen Domain Risk Minimization with Pre-Trained Models | 5.25 | 5.00 | -0.25 | [5, 5, 5, 5]
|
| 4670 | Nearing or Surpassing: Overall Evaluation of Human-Machine Dynamic Vision Ability | 4.00 | 4.00 | 0.00 | [6, 3, 3]
|
| 4671 | Re-balancing Adversarial Training Over Unbalanced Datasets | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 4672 | Extracting Robust Models with Uncertain Examples | 6.00 | 6.00 | 0.00 | [8, 6, 5, 5]
|
| 4673 | Neural Groundplans: Persistent Neural Scene Representations from a Single Image | 5.75 | 5.75 | 0.00 | [6, 6, 5, 6]
|
| 4674 | Unified Vision and Language Prompt Learning | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 4675 | Semi-supervised Counting via Pixel-by-pixel Density Distribution Modelling | 5.25 | 5.25 | 0.00 | [6, 3, 6, 6]
|
| 4676 | Calibrating Multimodal Learning | 4.25 | 4.25 | 0.00 | [3, 6, 3, 5]
|
| 4677 | Understanding Self-Supervised Pretraining with Part-Aware Representation Learning | 5.33 | 5.33 | 0.00 | [5, 5, 6]
|
| 4678 | E-CRF: Embedded Conditional Random Field for Boundary-caused Class Weights Confusion in Semantic Segmentation | 5.25 | 5.25 | 0.00 | [5, 6, 5, 5]
|
| 4679 | Sample Complexity of Nonparametric Off-Policy Evaluation on Low-Dimensional Manifolds using Deep Networks | 6.00 | 6.00 | 0.00 | [5, 8, 5, 6]
|
| 4680 | Stochastic Differentially Private and Fair Learning | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 4681 | CLIP-FLOW: CONTRASTIVE LEARNING WITH ITERATIVE PSEUDO LABELING FOR OPTICAL FLOW | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 4682 | Smooth-Reduce: Leveraging Patches for Improved Certified Robustness | 4.50 | 4.50 | 0.00 | [3, 6, 3, 6]
|
| 4683 | CAN: A simple, efficient and scalable contrastive masked autoencoder framework for learning visual representations | 5.25 | 5.75 | 0.50 | [5, 8, 5, 5]
|
| 4684 | On The Inadequacy of Optimizing Alignment and Uniformity in Contrastive Learning of Sentence Representations | 4.75 | 5.50 | 0.75 | [6, 5, 6, 5]
|
| 4685 | Self-supervised Video Representation Learning with Motion-Aware Masked Autoencoders | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 4686 | Bidirectional Learning for Offline Model-based Biological Sequence Design | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 4687 | Neural Collapse Inspired Feature-Classifier Alignment for Few-Shot Class-Incremental Learning | 6.25 | 6.25 | 0.00 | [6, 6, 8, 5]
|
| 4688 | Self-conditioned Embedding Diffusion for Text Generation | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 4689 | Decoupling Concept Bottleneck Model | 4.40 | 4.80 | 0.40 | [8, 3, 5, 5, 3]
|
| 4690 | AQUILA: Communication Efficient Federated Learning with Adaptive Quantization of Lazily-Aggregated Gradients | 5.00 | 5.00 | 0.00 | [5, 6, 6, 3]
|
| 4691 | Token Turing Machines | 4.25 | 4.25 | 0.00 | [3, 6, 5, 3]
|
| 4692 | Generaling Multimodal Variational Methods to Sets | 3.00 | 3.00 | 0.00 | [5, 3, 3, 1]
|
| 4693 | Towards a Unified View on Visual Parameter-Efficient Transfer Learning | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 4694 | Everyone"s Preference Changes Differently: Weighted Multi-Interest Retrieval Model | 5.50 | 5.50 | 0.00 | [3, 8, 5, 6]
|
| 4695 | Variational Autoencoders with Decremental Information Bottleneck for Disentanglement | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 4696 | Volumetric Optimal Transportation by Fast Fourier Transform | 5.33 | 5.33 | 0.00 | [5, 8, 3]
|
| 4697 | GFlowNets and variational inference | 7.33 | 7.33 | 0.00 | [6, 6, 10]
|
| 4698 | Neural Networks and the Chomsky Hierarchy | 6.80 | 7.20 | 0.40 | [6, 8, 8, 8, 6]
|
| 4699 | DeepSAT: An EDA-Driven Learning Framework for SAT | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 4700 | Neural ePDOs: Spatially Adaptive Equivariant Partial Differential Operator Based Networks | 6.75 | 6.75 | 0.00 | [8, 6, 8, 5]
|
| 4701 | An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion | 6.75 | 6.75 | 0.00 | [8, 5, 8, 6]
|
| 4702 | Cutting Long Gradient Flows: Decoupling End-to-End Backpropagation Based on Supervised Contrastive Learning | 4.25 | 4.25 | 0.00 | [6, 3, 5, 3]
|
| 4703 | Hierarchical Relational Learning for Few-Shot Knowledge Graph Completion | 5.50 | 5.50 | 0.00 | [6, 8, 5, 3]
|
| 4704 | Learn to Know Unknowns: A Bionic Memory Network for Unsupervised Anomaly Detection | 4.00 | 4.00 | 0.00 | [5, 3, 5, 3]
|
| 4705 | Function-Consistent Feature Distillation | 5.50 | 5.50 | 0.00 | [5, 8, 3, 6]
|
| 4706 | Multi-User Reinforcement Learning with Low Rank Rewards | 5.00 | 5.60 | 0.60 | [6, 6, 5, 5, 6]
|
| 4707 | Domain Specific Denoising Diffusion Probabilistic Models for Brain Dynamics | 3.50 | 3.50 | 0.00 | [1, 5, 5, 3]
|
| 4708 | The Devil is in the Wrongly-classified Samples: Towards Unified Open-set Recognition | 5.50 | 5.50 | 0.00 | [3, 5, 6, 8]
|
| 4709 | Approximated Anomalous Diffusion: Gaussian Mixture Score-based Generative Models | 4.75 | 4.75 | 0.00 | [8, 3, 5, 3]
|
| 4710 | MCAL: Minimum Cost Human-Machine Active Labeling | 6.33 | 6.33 | 0.00 | [8, 6, 5]
|
| 4711 | BoxTeacher: Exploring High-Quality Pseudo Labels for Weakly Supervised Instance Segmentation | 5.25 | 5.25 | 0.00 | [6, 5, 5, 5]
|
| 4712 | A Simple and Provable Method to Adapt Pre-trained Model across Domains with Few Samples | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 4713 | CD-Depth: Unsupervised Domain Adaptation for Depth Estimation via Cross Domain Integration | 4.00 | 4.00 | 0.00 | [3, 5, 5, 3]
|
| 4714 | SegNeRF: 3D Part Segmentation with Neural Radiance Fields | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 4715 | EyeDAS: Securing Perception of Autonomous Cars Against the Stereoblindness Syndrome | 3.50 | 3.50 | 0.00 | [3, 5, 1, 5]
|
| 4716 | Learnable Topological Features For Phylogenetic Inference via Graph Neural Networks | 6.33 | 6.33 | 0.00 | [8, 8, 3]
|
| 4717 | Double dynamic sparse training for GANs | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 4718 | Bayesian Robust Graph Contrastive Learning | 5.00 | 5.00 | 0.00 | [5, 5, 5, 5]
|
| 4719 | Hardware-restriction-aware training (HRAT) for memristor neural networks | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 4720 | FreeSeg: Free Mask from Interpretable Contrastive Language-Image Pretraining for Semantic Segmentation | 3.67 | 3.67 | 0.00 | [5, 3, 3]
|
| 4721 | DifFace: Blind Face Restoration with Diffused Error Contraction | 6.00 | 6.00 | 0.00 | [5, 8, 5, 6]
|
| 4722 | ViTKD: Practical Guidelines for ViT Feature Knowledge Distillation | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 4723 | Fairness-aware Contrastive Learning with Partially Annotated Sensitive Attributes | 6.50 | 6.50 | 0.00 | [5, 8, 8, 5]
|
| 4724 | Training Instability and Disharmony Between ReLU and Batch Normalization | 3.75 | 3.75 | 0.00 | [6, 3, 3, 3]
|
| 4725 | Rotamer Density Estimators are Unsupervised Learners of the Effect of Mutations on Protein-Protein Interaction | 5.67 | 5.67 | 0.00 | [6, 6, 5]
|
| 4726 | Faster Neural Architecture "Search" for Deep Image Prior | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 4727 | Dilated convolution with learnable spacings | 5.20 | 5.20 | 0.00 | [6, 5, 3, 6, 6]
|
| 4728 | PatchDCT: Patch Refinement for High Quality Instance Segmentation | 6.75 | 7.25 | 0.50 | [8, 8, 5, 8]
|
| 4729 | Global Prototype Encoding for Incremental Video Highlights Detection | 5.75 | 5.75 | 0.00 | [6, 6, 3, 8]
|
| 4730 | WaGI: Wavelet-based GAN Inversion for Preserving High-Frequency Image Details | 6.25 | 6.25 | 0.00 | [6, 5, 6, 8]
|
| 4731 | Neural-Symbolic Recursive Machine for Systematic Generalization | 6.00 | 5.75 | -0.25 | [5, 6, 6, 6]
|
| 4732 | ChiroDiff: Modelling chirographic data with Diffusion Models | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 4733 | Object Localization helps Action Recognition Models Adapt to New Environments | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 4734 | Active Topological Mapping by Metric-Free Exploration via Task and Motion Imitation | 4.40 | 4.40 | 0.00 | [6, 5, 5, 3, 3]
|
| 4735 | SoundCount: Sound Counting from Raw Audio with Dyadic Decomposition Neural Network | 5.60 | 5.60 | 0.00 | [8, 5, 3, 6, 6]
|
| 4736 | SoundNeRirF: Receiver-to-Receiver Sound Neural Room Impulse Response Field | 5.00 | 5.25 | 0.25 | [6, 3, 6, 6]
|
| 4737 | Towards Sustainable Self-supervised Learning | 5.25 | 5.25 | 0.00 | [5, 5, 5, 6]
|
| 4738 | Real-Time Image Demoir$\acute{e}$ing on Mobile Devices | 6.00 | 6.75 | 0.75 | [8, 6, 8, 5]
|
| 4739 | Domain Generalization via Independent Regularization from Early-branching Networks | 5.50 | 5.50 | 0.00 | [5, 3, 6, 8]
|
| 4740 | AutoSKDBERT: Learn to Stochastically Distill BERT | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 4741 | QCRS: Improve Randomized Smoothing using Quasi-Concave Optimization | 4.80 | 4.80 | 0.00 | [5, 5, 3, 6, 5]
|
| 4742 | Training A Multi-stage Deep Classifier with Feedback Signals | 3.00 | 3.00 | 0.00 | [3, 5, 1]
|
| 4743 | Is Self-Supervised Contrastive Learning More Robust Than Supervised Learning? | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 4744 | An Empirical Study of Metrics to Measure Representational Harms in Pre-Trained Language Models | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 4745 | Unsupervised Learning of Causal Relationships from Unstructured Data | 4.75 | 3.75 | -1.00 | [3, 1, 3, 8]
|
| 4746 | The Biased Artist: Exploiting Cultural Biases via Homoglyphs in Text-Guided Image Generation Models | 3.75 | 3.75 | 0.00 | [6, 1, 3, 5]
|
| 4747 | Parameterized projected Bellman operator | 4.75 | 4.75 | 0.00 | [6, 3, 5, 5]
|
| 4748 | Module-wise Training of Residual Networks via the Minimizing Movement Scheme | 4.33 | 4.33 | 0.00 | [3, 5, 5]
|
| 4749 | Cross-Level Distillation and Feature Denoising for Cross-Domain Few-Shot Classification | 5.67 | 5.67 | 0.00 | [3, 6, 8]
|
| 4750 | kaBEDONN: posthoc eXplainable Artificial Intelligence with Data Ordered Neural Network | 2.00 | 2.00 | 0.00 | [1, 3]
|
| 4751 | DELTA: DEBIASED FULLY TEST-TIME ADAPTATION | 5.50 | 5.75 | 0.25 | [6, 5, 6, 6]
|
| 4752 | Bit-Pruning: A Sparse Multiplication-Less Dot-Product | 5.50 | 6.25 | 0.75 | [6, 8, 5, 6]
|
| 4753 | Abstract-to-Executable Trajectory Translation for One-Shot Task Generalization | 5.00 | 5.00 | 0.00 | [3, 5, 6, 6]
|
| 4754 | Unveiling The Mask of Position-Information Pattern Through the Mist of Image Features | 5.25 | 5.25 | 0.00 | [5, 8, 3, 5]
|
| 4755 | KNN-Diffusion: Image Generation via Large-Scale Retrieval | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 4756 | Steering Prototypes with Prompt Tuning for Rehearsal-free Continual Learning | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 4757 | Normalized Activation Function: Toward Better Convergence | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 4758 | IS SYNTHETIC DATA FROM GENERATIVE MODELS READY FOR IMAGE RECOGNITION? | 5.50 | 5.50 | 0.00 | [6, 6, 5, 5]
|
| 4759 | Learnable Behavior Control: Breaking Atari Human World Records via Sample-Efficient Behavior Selection | 6.33 | 8.67 | 2.33 | [8, 8, 10]
|
| 4760 | Decompose to Generalize: Species-Generalized Animal Pose Estimation | 6.00 | 6.00 | 0.00 | [6, 8, 5, 5]
|
| 4761 | Correcting the Sub-optimal Bit Allocation | 4.50 | 4.50 | 0.00 | [3, 6, 1, 8]
|
| 4762 | IDEAL: Query-Efficient Data-Free Learning from Black-Box Models | 5.50 | 5.50 | 0.00 | [3, 6, 5, 8]
|
| 4763 | MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 4764 | (LA)YER-NEIGH(BOR) SAMPLING: DEFUSING NEIGHBORHOOD EXPLOSION | 3.67 | 3.67 | 0.00 | [3, 3, 5]
|
| 4765 | Probing into Overfitting for Video Recognition | 4.67 | 5.00 | 0.33 | [6, 3, 6]
|
| 4766 | Image as Set of Points | 7.50 | 8.00 | 0.50 | [8, 6, 8, 10]
|
| 4767 | Examining the Value of Neural Filter Pruning -- Retrospect and Prospect | 4.75 | 4.75 | 0.00 | [3, 5, 5, 6]
|
| 4768 | Sparse Misinformation Detector | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 4769 | Hybrid Neuro-Symbolic Reasoning based on Multimodal Fusion | 3.00 | 3.00 | 0.00 | [3, 5, 1, 3]
|
| 4770 | Distilling Text-Image Foundation Models | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 4771 | Trainability Preserving Neural Pruning | 5.00 | 5.00 | 0.00 | [6, 5, 3, 6]
|
| 4772 | Rotation Invariant Quantization for Model Compression | 1.00 | 1.00 | 0.00 | [1, 1, 1]
|
| 4773 | Robustness Exploration of Semantic Information in Adversarial Training | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 4774 | Learning Implicit Scale Conditioned Memory Compensation for Talking Head Generation | 6.00 | 6.00 | 0.00 | [6, 6, 6]
|
| 4775 | On the Dynamics under the Averaged Sample Margin Loss and Beyond | 4.33 | 4.33 | 0.00 | [6, 6, 1]
|
| 4776 | DrML: Diagnosing and Rectifying Vision Models using Language | 5.75 | 5.75 | 0.00 | [6, 5, 6, 6]
|
| 4777 | Semantic Grouping Network for Audio Source Separation | 3.75 | 3.75 | 0.00 | [3, 6, 1, 5]
|
| 4778 | Neural Shape Compiler: A Unified Framework for Transforming between Text, Point Cloud, and Program | 4.75 | 4.75 | 0.00 | [3, 6, 5, 5]
|
| 4779 | Improving Corruption Robustness with Adversarial Feature Alignment Transformers | 4.00 | 4.00 | 0.00 | [3, 6, 3]
|
| 4780 | Sharpness-aware Quantization for Deep Neural Networks | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 4781 | Harnessing Out-Of-Distribution Examples via Augmenting Content and Style | 5.00 | 5.00 | 0.00 | [6, 3, 6, 5]
|
| 4782 | On Stability and Generalization of Bilevel Optimization Problems | 3.75 | 3.75 | 0.00 | [5, 3, 6, 1]
|
| 4783 | Learning GFlowNets from partial episodes for improved convergence and stability | 5.33 | 5.00 | -0.33 | [5, 5, 5]
|
| 4784 | DropIT: Dropping Intermediate Tensors for Memory-Efficient DNN Training | 4.75 | 5.50 | 0.75 | [5, 5, 6, 6]
|
| 4785 | Self-attentive Rationalization for Graph Contrastive Learning | 4.80 | 4.80 | 0.00 | [5, 5, 3, 6, 5]
|
| 4786 | A Unified Framework of Soft Threshold Pruning | 5.00 | 5.00 | 0.00 | [3, 6, 6]
|
| 4787 | Efficient Automatic Machine Learning via Design Graphs | 5.25 | 5.25 | 0.00 | [3, 8, 5, 5]
|
| 4788 | TaskPrompter: Spatial-Channel Multi-Task Prompting for Dense Scene Understanding | 6.20 | 6.20 | 0.00 | [8, 6, 8, 3, 6]
|
| 4789 | Measuring Asymmetric Gradient Discrepancy in Parallel Continual Learning | 4.75 | 5.00 | 0.25 | [6, 3, 6, 5]
|
| 4790 | Individual Privacy Accounting for Differentially Private Stochastic Gradient Descent | 5.67 | 5.67 | 0.00 | [6, 3, 8]
|
| 4791 | CI-VAE: a Class-Informed Deep Variational Autoencoder for Enhanced Class-Specific Data Interpolation | 2.25 | 2.25 | 0.00 | [1, 6, 1, 1]
|
| 4792 | Attention De-sparsification Matters: Inducing Diversity in Digital Pathology Representation Learning | 5.67 | 6.00 | 0.33 | [6, 6, 6]
|
| 4793 | Learning Domain-Agnostic Representation for Disease Diagnosis | 6.67 | 6.67 | 0.00 | [6, 6, 8]
|
| 4794 | DOTIN: Dropping Out Task-Irrelevant Nodes for GNNs | 3.50 | 3.50 | 0.00 | [3, 3, 3, 5]
|
| 4795 | Boosting Out-of-Distribution Detection with Multiple Pre-trained Models | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 4796 | Minimax Optimal Kernel Operator Learning via Multilevel Training | 7.40 | 8.80 | 1.40 | [10, 8, 8, 8, 10]
|
| 4797 | STViT: Semantic Tokens for Efficient Global and Local Vision Transformers | 5.00 | 5.00 | 0.00 | [6, 5, 6, 3]
|
| 4798 | Learning a 3D-Aware Encoder for Style-based Generative Radiance Field | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 4799 | MixQuant: A Quantization Bit-width Search that Can Optimize the Performance of your Quantization Method | 2.00 | 2.00 | 0.00 | [1, 1, 3, 3]
|
| 4800 | Logical Entity Representation in Knowledge-Graphs for Differentiable Rule Learning | 6.00 | 6.00 | 0.00 | [5, 6, 5, 8]
|
| 4801 | S-SOLVER: Numerically Stable Adaptive Step Size Solver for Neural ODEs | 2.33 | 2.33 | 0.00 | [5, 1, 1]
|
| 4802 | TT-NF: Tensor Train Neural Fields | 4.33 | 4.33 | 0.00 | [5, 3, 5]
|
| 4803 | Partial transportability for domain generalization | 4.50 | 4.50 | 0.00 | [6, 6, 3, 3]
|
| 4804 | Feint in Multi-Player Games | 3.67 | 3.67 | 0.00 | [1, 5, 5]
|
| 4805 | Succinct Compression: Lossless Compression for Fast and Memory-Efficient Deep Neural Network Inference | 5.50 | 5.50 | 0.00 | [8, 3, 8, 3]
|
| 4806 | BEVDistill: Cross-Modal BEV Distillation for Multi-View 3D Object Detection | 5.50 | 5.75 | 0.25 | [6, 6, 6, 5]
|
| 4807 | Expanding Datasets With Guided Imagination | 5.00 | 5.00 | 0.00 | [3, 8, 6, 3]
|
| 4808 | ThinkSum: Probabilistic reasoning over sets using large language models | 4.25 | 4.25 | 0.00 | [3, 3, 3, 8]
|
| 4809 | Universal Unlearnable Examples: Cluster-wise Perturbations without Label-consistency | 4.67 | 4.67 | 0.00 | [3, 5, 6]
|
| 4810 | Confidence and Dispersity Speak: Characterising Prediction Matrix for Unsupervised Accuracy Estimation | 5.33 | 5.33 | 0.00 | [8, 5, 3]
|
| 4811 | On the Calibration Set Difficulty and Out-of-distribution Calibration | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 4812 | Design of the topology for contrastive visual-textual alignment | 4.75 | 4.75 | 0.00 | [5, 6, 5, 3]
|
| 4813 | Slimmable Networks for Contrastive Self-supervised Learning | 4.00 | 4.00 | 0.00 | [5, 5, 3, 3]
|
| 4814 | Interpretable Single/Multi-label Text Classification with Unsupervised Constituent-label alignments | 4.67 | 4.67 | 0.00 | [5, 6, 3]
|
| 4815 | Suppressing the Heterogeneity: A Strong Feature Extractor for Few-shot Segmentation | 6.00 | 6.00 | 0.00 | [8, 5, 5, 6]
|
| 4816 | Defactorization Transformer: Modeling Long Range Dependency with Local Window Cost | 4.75 | 4.75 | 0.00 | [3, 5, 6, 5]
|
| 4817 | MaPLe: Multi-modal Prompt Learning | 5.50 | 5.50 | 0.00 | [3, 8, 6, 5]
|
| 4818 | Communication Efficient Fair Federated Recommender System | 5.00 | 5.00 | 0.00 | [6, 6, 3, 5]
|
| 4819 | Grassmannian Class Representation in Deep Learning | 5.20 | 5.20 | 0.00 | [6, 6, 5, 6, 3]
|
| 4820 | Refining Visual Representation for Generalized Zero-Shot Recognition through Implicit-Semantics-Guided Metric Learning | 3.00 | 3.00 | 0.00 | [3, 3, 3, 3]
|
| 4821 | Reward Learning with Trees: Methods and Evaluation | 4.33 | 4.67 | 0.33 | [5, 6, 3]
|
| 4822 | Achieve the Minimum Width of Neural Networks for Universal Approximation | 5.50 | 5.50 | 0.00 | [8, 5, 3, 6]
|
| 4823 | H2RBox: Horizonal Box Annotation is All You Need for Oriented Object Detection | 7.50 | 7.50 | 0.00 | [10, 6, 6, 8]
|
| 4824 | Sparse and Hierarchical Masked Modeling for Convolutional Representation Learning | 6.00 | 6.00 | 0.00 | [5, 8, 5]
|
| 4825 | Functional Relation Field: A Model-Agnostic Framework for Multivariate Time Series Forecasting | 4.67 | 5.00 | 0.33 | [6, 3, 6, 5]
|
| 4826 | Motion-inductive Self-supervised Object Discovery in Videos | 5.25 | 5.25 | 0.00 | [8, 5, 5, 3]
|
| 4827 | Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment | 5.00 | 5.00 | 0.00 | [5, 5, 5]
|
| 4828 | Transcendental Idealism of Planner: Evaluating Perception from Planning Perspective for Autonomous Driving | 5.67 | 5.67 | 0.00 | [5, 6, 6]
|
| 4829 | Pushing the Limits of Fewshot Anomaly Detection in Industry Vision: Graphcore | 7.50 | 7.50 | 0.00 | [6, 8, 8, 8]
|
| 4830 | Evaluating Weakly Supervised Object Localization Methods Right? A Study on Heatmap-based XAI and Neural Backed Decision Tree | 1.50 | 1.50 | 0.00 | [3, 1, 1, 1]
|
| 4831 | HyperFeel: An Efficient Federated Learning Framework Using Hyperdimensional Computing | 4.33 | 4.33 | 0.00 | [5, 5, 3]
|
| 4832 | TEAS: Exploiting Spiking Activity for Temporal-wise Adaptive Spiking Neural Networks | 4.00 | 4.00 | 0.00 | [5, 3, 3, 5]
|
| 4833 | Quasi-Conservative Score-based Generative Models | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 4834 | Multi-Modal Few-Shot Temporal Action Detection | 4.75 | 4.75 | 0.00 | [5, 3, 6, 5]
|
| 4835 | Representation Learning for Low-rank General-sum Markov Games | 6.75 | 7.00 | 0.25 | [8, 8, 6, 6]
|
| 4836 | Multi-Domain Long-Tailed Learning by Augmenting Disentangled Representations | 5.00 | 5.00 | 0.00 | [3, 6, 5, 6]
|
| 4837 | Surgical Fine-Tuning Improves Adaptation to Distribution Shifts | 6.33 | 7.33 | 1.00 | [6, 8, 8]
|
| 4838 | Diversify and Disambiguate: Out-of-Distribution Robustness via Disagreement | 7.25 | 7.50 | 0.25 | [6, 8, 8, 8]
|
| 4839 | MaSS: Multi-attribute Selective Suppression | 5.75 | 5.75 | 0.00 | [5, 6, 6, 6]
|
| 4840 | Mimic before Reconstruct: Enhance Masked Autoencoders with Feature Mimicking | 4.50 | 4.50 | 0.00 | [5, 5, 5, 3]
|
| 4841 | Neural Attention Memory | 4.50 | 4.50 | 0.00 | [3, 3, 6, 6]
|
| 4842 | Meta Optimal Transport | 4.50 | 4.50 | 0.00 | [5, 5, 3, 5]
|
| 4843 | On amortizing convex conjugates for optimal transport | 6.00 | 6.00 | 0.00 | [6, 6, 6, 6]
|
| 4844 | Exploring Visual Interpretability for Contrastive Language-Image Pretraining | 3.50 | 4.00 | 0.50 | [6, 3, 5, 3, 3]
|
| 4845 | Example-based Planning via Dual Gradient Fields | 5.50 | 5.50 | 0.00 | [6, 5, 8, 3]
|
| 4846 | DualAfford: Learning Collaborative Visual Affordance for Dual-gripper Manipulation | 6.33 | 6.33 | 0.00 | [6, 8, 5]
|
| 4847 | GraphCG: Unsupervised Discovery of Steerable Factors in Graphs | 3.50 | 3.50 | 0.00 | [3, 3, 5, 3]
|
| 4848 | Molecular Geometry Pretraining with SE(3)-Invariant Denoising Distance Matching | 5.33 | 5.67 | 0.33 | [6, 5, 6]
|
| 4849 | SIMPLE: Specialized Model-Sample Matching for Domain Generalization | 5.25 | 5.75 | 0.50 | [5, 5, 5, 8]
|
| 4850 | The Augmented Image Prior: Distilling 1000 Classes by Extrapolating from a Single Image | 5.67 | 6.33 | 0.67 | [8, 5, 6]
|
| 4851 | Trust-consistent Visual Semantic Embedding for Image-Text Matching | 5.75 | 5.75 | 0.00 | [6, 6, 3, 8]
|
| 4852 | Rethinking Knowledge Distillation via Cross-Entropy | 3.50 | 3.50 | 0.00 | [3, 5, 3, 3]
|
| 4853 | Protein structure generation via folding diffusion | 5.50 | 5.50 | 0.00 | [6, 5, 3, 8]
|
| 4854 | Backpropagation Path Search On Adversarial Transferability | 4.50 | 4.50 | 0.00 | [5, 3, 5, 5]
|
| 4855 | Delving into Semantic Scale Imbalance | 5.75 | 5.75 | 0.00 | [8, 5, 5, 5]
|
| 4856 | Do Spiking Neural Networks Learn Similar Representation with Artificial Neural Networks? A Pilot Study on SNN Representation | 3.75 | 3.75 | 0.00 | [3, 6, 3, 3]
|
| 4857 | DAG Matters! GFlowNets Enhanced Explainer for Graph Neural Networks | 5.75 | 5.75 | 0.00 | [5, 5, 5, 8]
|
| 4858 | Generalized Category Discovery via Adaptive GMMs without Knowing the Class Number | 4.67 | 4.67 | 0.00 | [5, 3, 6]
|
| 4859 | A MULTI-SCALE STRUCTURE-PRESERVING HETEROLOGOUS IMAGE TRANSFORMATION ALGORITHM BASED ON CONDITIONAL ADVERSARIAL NETWORK LEARNING | 3.00 | 3.00 | 0.00 | [3, 3, 3]
|
| 4860 | Metro: Memory-Enhanced Transformer for Retrosynthetic Planning via Reaction Tree | 3.67 | 3.50 | -0.17 | [3, 5, 3, 3]
|
| 4861 | In the ZONE: Measuring difficulty and progression in curriculum generation | 4.75 | 5.25 | 0.50 | [6, 5, 5, 5]
|
| 4862 | Object Tracking by Hierarchical Part-Whole Attention | 6.67 | 6.67 | 0.00 | [8, 6, 6]
|
| 4863 | Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking | 5.33 | 5.33 | 0.00 | [5, 6, 5]
|
| 4864 | scFormer: a universal representation learning approach for single-cell data using transformers | 3.25 | 3.25 | 0.00 | [3, 1, 6, 3]
|
| 4865 | Understanding the Training Dynamics in Federated Deep Learning via Aggregation Weight Optimization | 5.33 | 5.33 | 0.00 | [6, 5, 5]
|
| 4866 | BiBench: Benchmarking and Analyzing Network Binarization | 4.00 | 4.00 | 0.00 | [3, 3, 6]
|
| 4867 | Contextual Image Masking Modeling via Synergized Contrasting without View Augmentation for Faster and Better Visual Pretraining | 5.67 | 5.67 | 0.00 | [6, 5, 6]
|
| 4868 | Patch-Level Contrasting without Patch Correspondence for Accurate and Dense Contrastive Representation Learning | 6.50 | 6.50 | 0.00 | [6, 8, 6, 6]
|
| 4869 | Continuous-Discrete Convolution for (3+1)D Geometry-Sequence Modeling in Proteins | 6.25 | 6.00 | -0.25 | [6, 6, 6, 6]
|
| 4870 | ELODI: Ensemble Logit Difference Inhibition for Positive-Congruent Training | 6.00 | 6.00 | 0.00 | [5, 5, 6, 8]
|
| 4871 | Model-agnostic Measure of Generalization Difficulty | 4.25 | 4.25 | 0.00 | [8, 3, 3, 3]
|
| 4872 | Efficient Multi-Task Reinforcement Learning via Selective Behavior Sharing | 3.67 | 3.67 | 0.00 | [3, 5, 3]
|
| 4873 | Efficient Exploration via Fragmentation and Recall | 4.50 | 4.50 | 0.00 | [3, 5, 5, 5]
|
| 4874 | Hedge Your Actions: Flexible Reinforcement Learning for Complex Action Spaces | 4.25 | 4.25 | 0.00 | [8, 5, 3, 1]
|
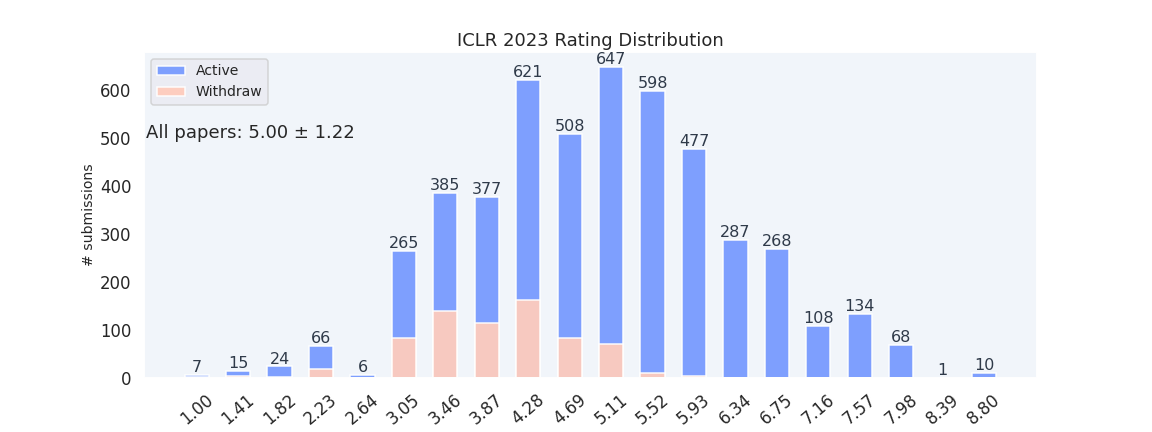
 /
/ ) to get submission info quickly
) to get submission info quickly